

极客时间:网络排查案例课
目录:
网络排查案例课
网络为什么要分层
如果不分层的话,就需要应用程序包办一切
- 程序把应用层的数据,按某种编码转化为二进制数据,然后程序去操控网卡,把二进制数据发送到网络上。这期间,通信的连接方式、传输的可靠性、速度和效率的保证等等,都需要这个程序去实现。然后下次开发另外一个应用的时候,就把上面这些活,再干一遍
而应用程序、操作系统、网络设备等环节各自分工
- 应用程序只负责实现应用层的业务逻辑,操作系统负责连接的建立、处理网络拥塞和丢包乱序、优化网络读写速度等等,然后把数据交给网卡,后者和交换机等设备做好联动,负责二进制数据在物理线路上的传送和接收。
TCP流,为英文的TCP Stream,有"连续的事件"这样一个含义,所以它是有前后、有顺序的,这也正对应了TCP的特性
和Stream相对的一个词是Datagram,它是指没有前后关系的数据单元,比如UDP和IP都属于Datagram
在Linux网络编程里面,TCP对应的socket类型是SOCK_STREAM,而UDP对应的,就是SOCK_DGRAM
在具体的网络报文层面,一个TCP流,对应的就是一个五元组
- 传输协议类型
- 源IP
- 源端口
- 目的IP
- 目的端口
其他的一些概念
- 报文在每个层都可以用
- 数据包在每个层都可以用
- 帧frame是二层数据链路层的概念,代表二层报文,包括帧头,载荷和帧尾
- 分组是IP层报文
- 段特指TCP segment,也就是TCP报文,当报文超过传输层数据单元的限制,就会划分为多个segment
查看是否存在丢包的情况
watch --diff netstat -s
对链路的多次探测
$ mtr www.baidu.com -r -c 10
Start: 2022-01-07T04:05:02+0000
HOST: victorebpf Loss% Snt Last Avg Best Wrst StDev
1.|-- _gateway 0.0% 10 0.3 0.4 0.2 1.2 0.3
2.|-- 192.168.1.1 0.0% 10 1.6 1.8 1.4 3.2 0.5
3.|-- 100.65.0.1 0.0% 10 3.8 7.0 3.8 10.3 2.0
4.|-- 61.152.54.125 0.0% 10 4.0 4.3 3.6 5.1 0.5
5.|-- 61.152.25.110 30.0% 10 5.0 6.8 4.4 18.9 5.4
6.|-- 202.97.101.30 20.0% 10 7.8 6.6 5.4 7.8 0.8
7.|-- 58.213.95.110 80.0% 10 10.0 9.8 9.6 10.0 0.3
8.|-- ??? 100.0 10 0.0 0.0 0.0 0.0 0.0
9.|-- 58.213.96.74 0.0% 10 10.5 12.7 9.9 24.7 4.9
10.|-- ??? 100.0 10 0.0 0.0 0.0 0.0 0.0
11.|-- ??? 100.0 10 0.0 0.0 0.0 0.0 0.0
12.|-- ??? 100.0 10 0.0 0.0 0.0 0.0 0.0
13.|-- 180.101.49.12 0.0% 10 9.4 9.1 8.3 9.7 0.5
排查链路层,基于网卡驱动会到内核中注册ethtool回调函数
# ethtool -S enp0s3
NIC statistics:
rx_packets: 45897
tx_packets: 9457
rx_bytes: 59125524
tx_bytes: 834625
rx_broadcast: 0
tx_broadcast: 17
rx_multicast: 0
tx_multicast: 59
rx_errors: 0
tx_errors: 0
tx_dropped: 0
traceroute获取
原理就是发送包的TTL由1递增,进行探测返回的IP地址
默认使用UDP,但是可以指定ICMP,获取的数据可能可以互相补全
抓包工具Tcpdump和Wireshark
tcpdump
tcpdump基于bpf
文件格式有多种
- pcap是libpcap的格式,也是tcpdump和wireshark等工具默认支持的文件格式
- cap包含libpcap的格式和libpcap标准之外的数据格式
- pcapng为为了解决libpcap不支持的多网卡
tcpdump常用参数
-w文件名,可以把报文保存到文件-c数量,可以抓取固定数量的报文,可以避免抓取过多报文-s长度,可以只抓取每个报文的一定长度-n不做地址转换(比如IP 地址转换为主机名,port 80 转换为 http)-v/-vv/-vvv,可以打印更加详细的报文信息-e,可以打印二层信息,特别是MAC地址-p,关闭混杂模式。所谓混杂模式,也就是嗅探(Sniffering),就是把目的地址不是本机地址的网络报文也抓取下来-X打印详细报文
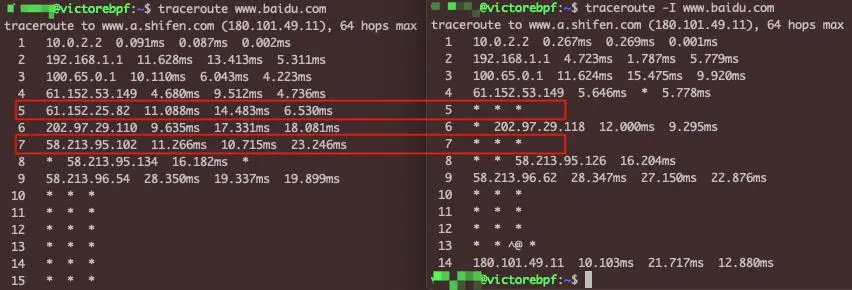
示例过滤TLS握手的报文
tcpdump -w file.pcap 'dst port 443 && tcp[20]==22 && tcp[25]==1'
dst port 443抓取从客户端发过来的访问HTTPS的报文tcp[20]==22这是提取了TCP的第21个字节,由于TCP头部占20字节,TLS又是TCP的载荷,那么TLS的第1个字节就是TCP的第21个字节,也就是 TCP[20],这个位置的值如果是22(十进制),那么就表明这个是TLS 握手报文tcp[25]==1这是提取了TCP的第26个字节,如果它等于1,那么就表明这个是Client Hello类型的TLS握手报文
记录的数据是十六进制的16,转换为十进制就是22了
读取tcpdump文件
tcpdump -r file.pcap 'tcp[tcpflags] & (tcp-rst) != 0'
读取tcpdump文件过滤并转存
tcpdump -r file.pcap 'tcp[tcpflags] & (tcp-rst) != 0' -w rst.pcap
避免无效的数据
一般来说,帧头是14字节,IP头是20字节,TCP头是20~40字节。如果你明确地知道这次抓包的重点是传输层,那么理论上,对于每一个报文,你只要抓取到传输层头部即可,也就是前14+20+40字节(即前74字节)
tcpdump -s 74 -w file.pcap
对于IP数据包
tcpdump -i eth0 -s 34
或者
tcpdump -i any -s 36
长度不一致是因为tcpdump在做-i any时,把以太网头部模拟为这个linux cooked capture的特定格式了,它占用了16个字节,而普通以太网头部是14字节
抓取TCP SYN包的过滤表达式
# 通过偏移量方法抓取SYN包
tcpdump -i any 'tcp[13]&2 !=0'
# 通过标志位方法抓取SYN包
tcpdump -i any 'tcp[tcpflags]&tcp-syn !=0'
# 当我们只想过滤仅有SYN标志的包时,第14个字节的二进制是00000010,十进制是2
tcpdump -i eth1 'tcp[13] = 2'
# 匹配SYN+ACK包时(二进制是00010010或是十进制18)
tcpdump -i eth1 'tcp[13] = 18'
# 匹配SYN或是SYN+ACK的数据时
tcpdump -i eth1 'tcp[13] & 2 = 2'
详细的TCP数据包
tcptrace也可以分析数据包
$ tcptrace -b test.pcap
1 arg remaining, starting with 'test.pcap'
Ostermann's tcptrace -- version 6.6.7 -- Thu Nov 4, 2004
145 packets seen, 145 TCP packets traced
elapsed wallclock time: 0:00:00.028527, 5082 pkts/sec analyzed
trace file elapsed time: 0:00:04.534695
TCP connection info:
1: victorebpf:51952 - 180.101.49.12:443 (a2b) 15> 15< (complete) (reset)
2: victorebpf:56794 - 180.101.49.58:443 (c2d) 56> 59< (complete) (reset)
Wireshark
判断是client端进行抓包还是server端进行抓包,一般client发出的IP包的TTL都是默认值,64,128和255中的某一个,经过若干网络跳数server端一般会比64,128和255小
乱序一定会有问题吗,一般乱序报文达10%以上就是传输质量的问题了
TCP的连接都是用TCP协议沟通的吗
三次握手
TCP连接是标准的TCP三次握手完成的
- Client端发送SYN
- Server端收到SYN后,回复SYN+ACK
- Client端收到SYN+ACK后,回复ACK
但是Server端不接收握手,会怎么做呢
- 不响应这次连接
- 响应,给予拒绝的回复
第一种情况,只需要丢弃即可,但是Client端无法分辨是什么情况,一直处于SYN_SENT
- 数据包在网络上丢失,Server端没有收到
- Server端收到了,但是没有回复
- Server端收到了,但是也没有回复
可以直接测试
# server端
iptables -I INPUT -p tcp --dport 80 -j DROP
# client抓包
tcpdump -i any -w telnet-80.pcap port 80
# client测试
telnet ServerIP 80
telnet会挂起,抓包可以看到重试间隔1,1,2,4,8,16s,一共发送了7次,基于的指数退避
由内核参数控制
$ sudo sysctl net.ipv4.tcp_syn_retries
net.ipv4.tcp_syn_retries = 6
如果改为
iptables -I INPUT -p tcp --dport 80 -j REJECT
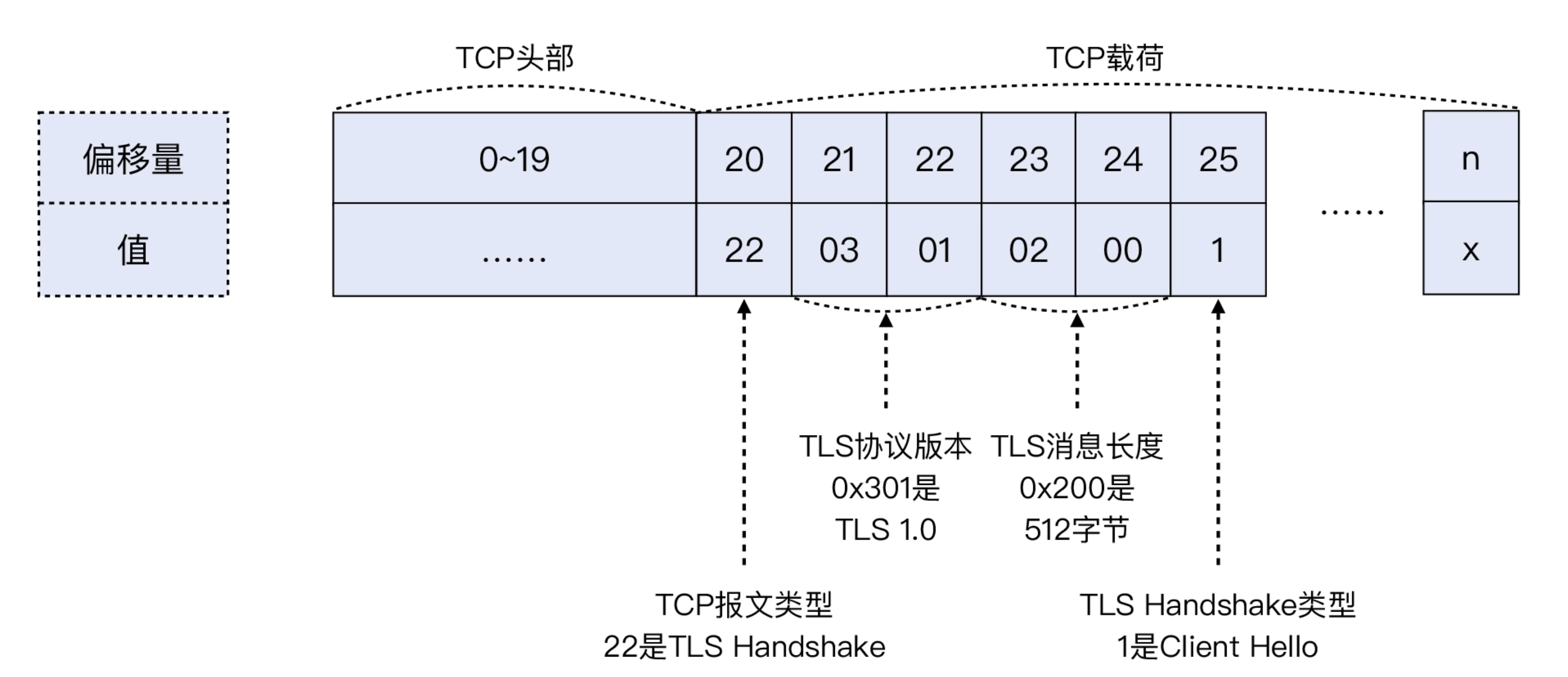
telnet会直接退出,但是抓包是没有抓到TCP RST
这时候抓包去掉tcp协议,就会收到一个icmp协议的消息
Destination unreachable (Port unreachable)
这里是因为iptables设置的时候默认添加了--reject-with icmp-port-unreachable,如果设置为–reject-with tcp-reset就能获取到RST
Window Scale
TCP在80年代的时候,用两个字节的长度代表65535的窗口,随着网络带宽的增大,窗口不够用,就在TCP的Options扩展
原来的Window大小不变,增加Window Scale,表示原始Window的左移位数,最高可以左移14位
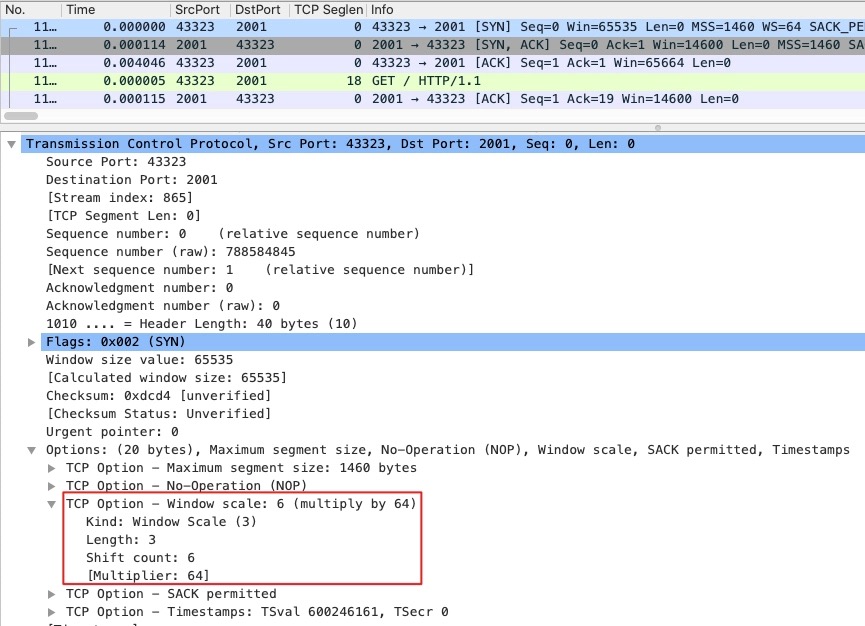
- Kind:TCP Option编号,3代表这是Window Scale类型
- Length:3 字节,含Kind、Length、Shift count
- Shift count:6,也就是窗口将要被右移的位数,2的6次方就是64
另外需要注意的
- SYN包里的Window是不会被Scale放大的,只有握手后的报文才会
- Window Scale只出现在TCP握手里面
UDP握手
TCP是有握手的概念的,而UDP的握手是因为nc命令会返回port [udp/*] succeeded!
是因为UDP不是面向连接的,没有一个确定的UDP协议层面的答复,需要UDP程序自行实现,而nc的成功是因为对端没有返回ICMP port unreachable,所以nc的逻辑
- 对于UDP来说,除非明确拒绝,否则可视为连通
- 对于TCP来说,除非明确接受,否则视为不连通
同时握手
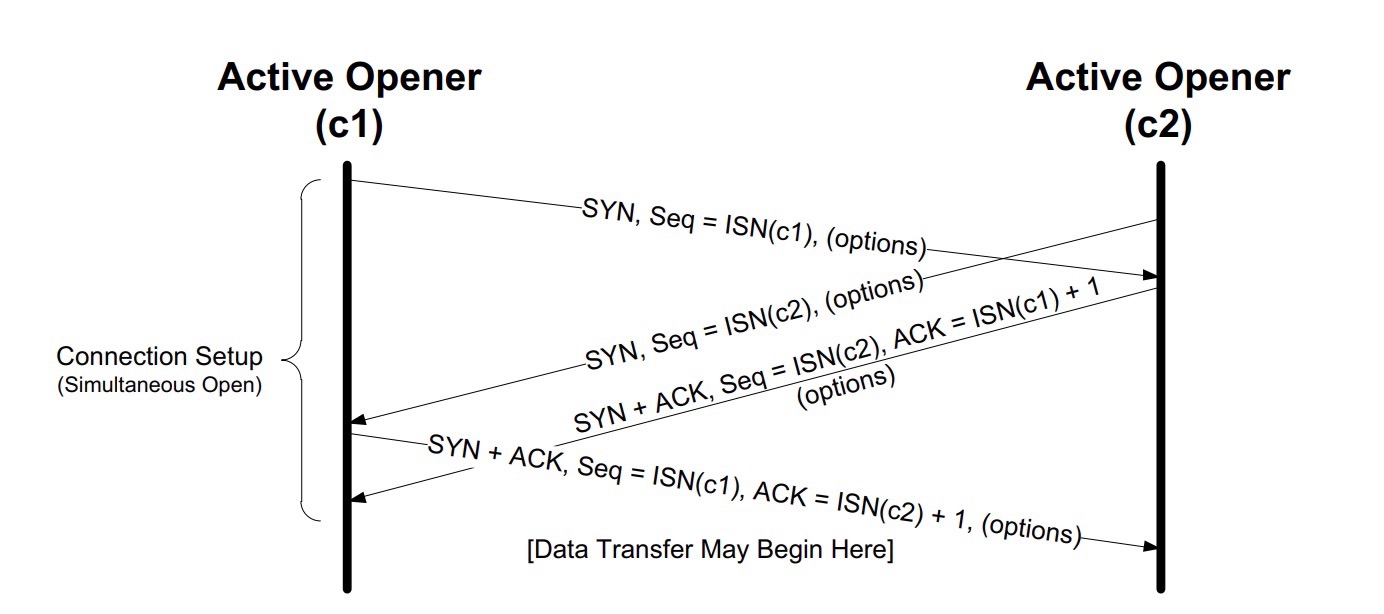
nginx的connection reset by peer含义
网络问题的排查需要将应用层的信息,翻译为传输层和网络层的信息
应用层的信息包括
- 应用层日志,包括成功日志、报错日志等等
- 应用层性能数据,比如RPS(每秒请求数),transaction time(处理时间)等
- 应用层载荷,比如HTTP请求和响应的header、body等
传输层的信息包括
- TCP 序列号(Sequence Number)
- 确认号(Acknowledge Number)
- MSS
- 接收窗口(Receive Window)
- 拥塞窗口(Congestion Window)
- 时延(Latency)
- 重复确认(DupAck)
- 选择性确认(Selective Ack)
- 重传(Retransmission)
- 丢包(Packet loss)
网络层的信息包括
- TTL
- MTU
- 跳数(hops)
- 路由表
connection reset by peer
nginx的错误日志
2015/12/01 15:49:48 [info] 20521#0: *55077498 recv() failed (104: Connection reset by peer) while sending to client, client: 10.255.252.31, server: manager.example.com, request: "POST /WebPageAlipay/weixin/notify_url.htm HTTP/1.1", upstream: "http:/10.4.36.207:8080/WebPageAlipay/weixin/notify_url.htm", host: "manager.example.com"
2015/12/01 15:49:54 [info] 20523#0: *55077722 recv() failed (104: Connection reset by peer) while sending to client, client: 10.255.252.31, server: manager.example.com, request: "POST /WebPageAlipay/app/notify_url.htm HTTP/1.1", upstream: "http:/10.4.36.207:8080/WebPageAlipay/app/notify_url.htm", host: "manager.example.com"
2015/12/01 15:49:54 [info] 20523#0: *55077710 recv() failed (104: Connection reset by peer) while sending to client, client: 10.255.252.31, server: manager.example.com, request: "POST /WebPageAlipay/app/notify_url.htm HTTP/1.1", upstream: "http:/10.4.36.207:8080/WebPageAlipay/app/notify_url.htm", host: "manager.example.com"
2015/12/01 15:49:58 [info] 20522#0: *55077946 recv() failed (104: Connection reset by peer) while sending to client, client: 10.255.252.31, server: manager.example.com, request: "POST /WebPageAlipay/app/notify_url.htm HTTP/1.1", upstream: "http:/10.4.36.207:8080/WebPageAlipay/app/notify_url.htm", host: "manager.example.com"
2015/12/01 15:49:58 [info] 20522#0: *55077965 recv() failed (104: Connection reset by peer) while sending to client, client: 10.255.252.31, server: manager.example.com, request: "POST /WebPageAlipay/app/notify_url.htm HTTP/1.1", upstream: "http:/10.4.36.207:8080/WebPageAlipay/app/notify_url.htm", host: "manager.example.com"
- recv() failed:这里的recv()是一个系统调用,就是用来接收数据的。可以直接man recv,看到这个系统调用的详细信息,也包括它的各种异常状态码
- 104:这个数字也是跟系统调用有关的,它就是recv()调用出现异常时的一个状态码,这是操作系统给出的。在Linux系统里,104对应的是ECONNRESET,也正是一个TCP连接被RST报文异常关闭的情况
在client抓包,使用wireshark分析
# 过滤出源IP或者目的IP为my_ip的报文
ip.addr eq my_ip
# 过滤出源IP为my_ip的报文
ip.src eq my_ip
# 过滤出目的IP为my_ip的报文
ip.dst eq my_ip
# RST报文
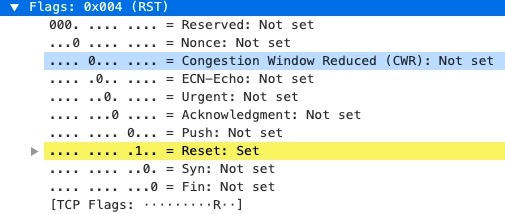
tcp.flags.reset eq 1
# 合并过滤条件
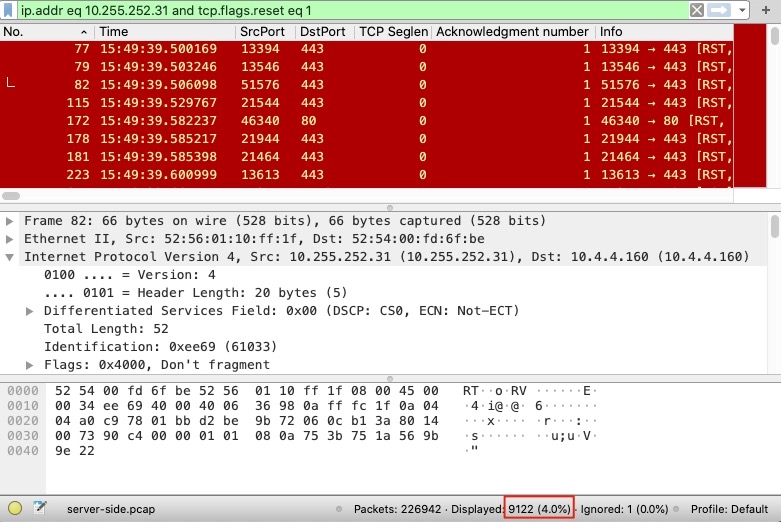
ip.addr eq 10.255.252.31 and tcp.flags.reset eq 1
过滤到的包可以看到flags中reset
可以看到reset的报文,占比为4%
右击报文,选择Follow->TCP Stream可以查看整个TCP流

可以看到RST处于握手阶段,不是正常第三次握手需要的ACK,而是RST+ACK
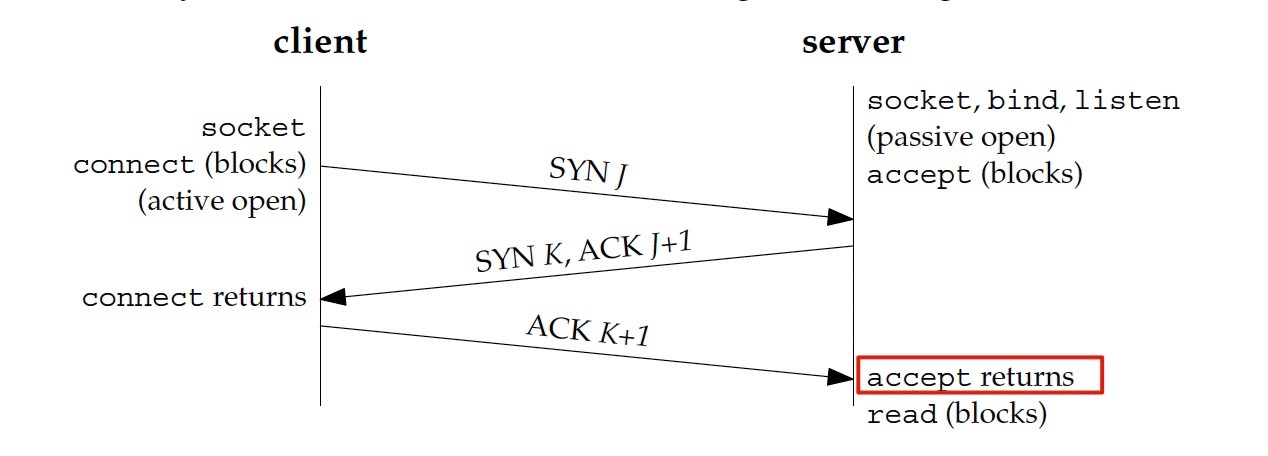
Client端发送连接的系统调用
- socket()
- connect()
Server端接收连接的系统调用
- socket()
- bind()
- listen()
- accept()
Server端的用户空间要获取TCP连接,需要获取accept()的返回,RST+ACK报文并不能生成一次有效连接,这种情况Nginx是不能感知这次失败的握手的
Client端调用的connect(),失败会返回ECONNRESET的返回码,可以记录错误
这种情况不是连接建立后的Reset
排除刚出现的报文
ip.addr eq 10.255.252.31 and tcp.flags.reset eq 1 and !(tcp.seq eq 1 and tcp.ack eq 1)
过滤到的报文
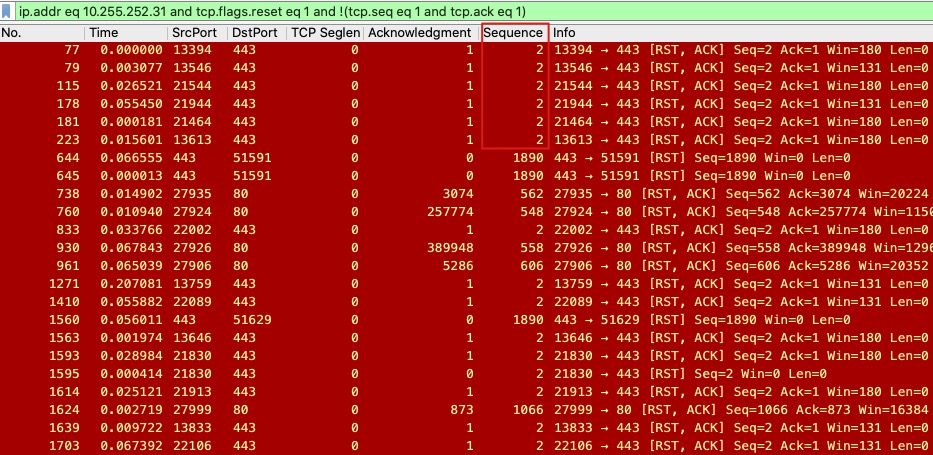
Follow TCP Stream可以有挥手的报文,可以指定tcp.stream eq xxx

排除刚出现的报文(seq=1)
ip.addr eq 10.255.252.31 and tcp.flags.reset eq 1 and !(tcp.seq eq 1 or tcp.ack eq 1)
依然剩下很多报文
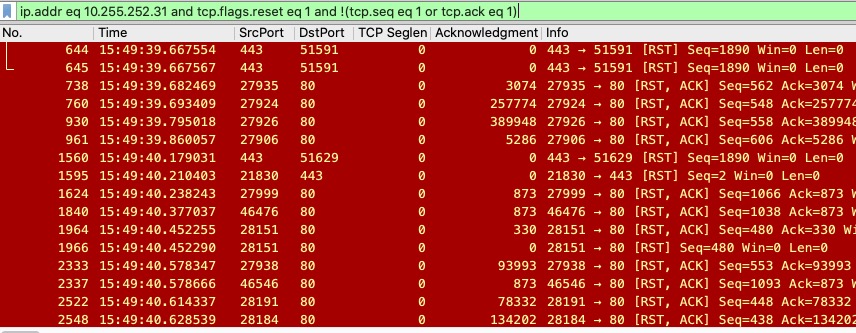
可以基于数据或者时间再次过滤
# 日志
2015/12/01 15:49:48 [info] 20521#0: *55077498 recv() failed (104: Connection reset by peer) while sending to client, client: 10.255.252.31, server: manager.example.com, request: "POST /WebPageAlipay/weixin/notify_url.htm HTTP/1.1", upstream: "http:/10.4.36.207:8080/WebPageAlipay/weixin/notify_url.htm", host: "manager.example.com"
# 条件
frame.time >="dec 01, 2015 15:49:48" and frame.time <="dec 01, 2015 15:49:49" and ip.addr eq 10.255.252.31 and tcp.flags.reset eq 1 and !(tcp.seq eq 1 or tcp.ack eq 1)
查询到的报文

报错的报文带着weixin,查找TCP Stream中包含weixin的
这就是想要的报文了,因为
- 时间吻合
- RST行为吻合
- URL路径吻合
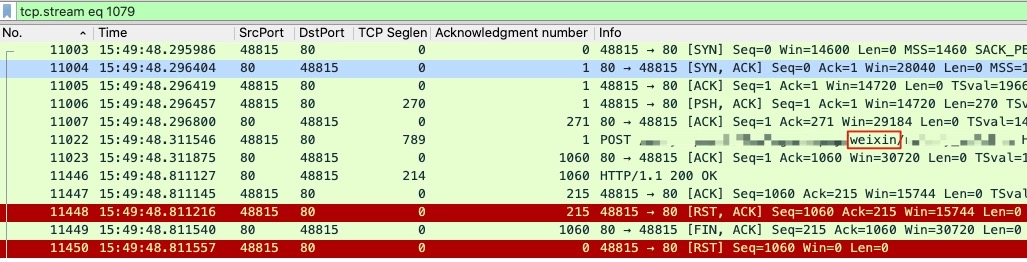
分析一下就是
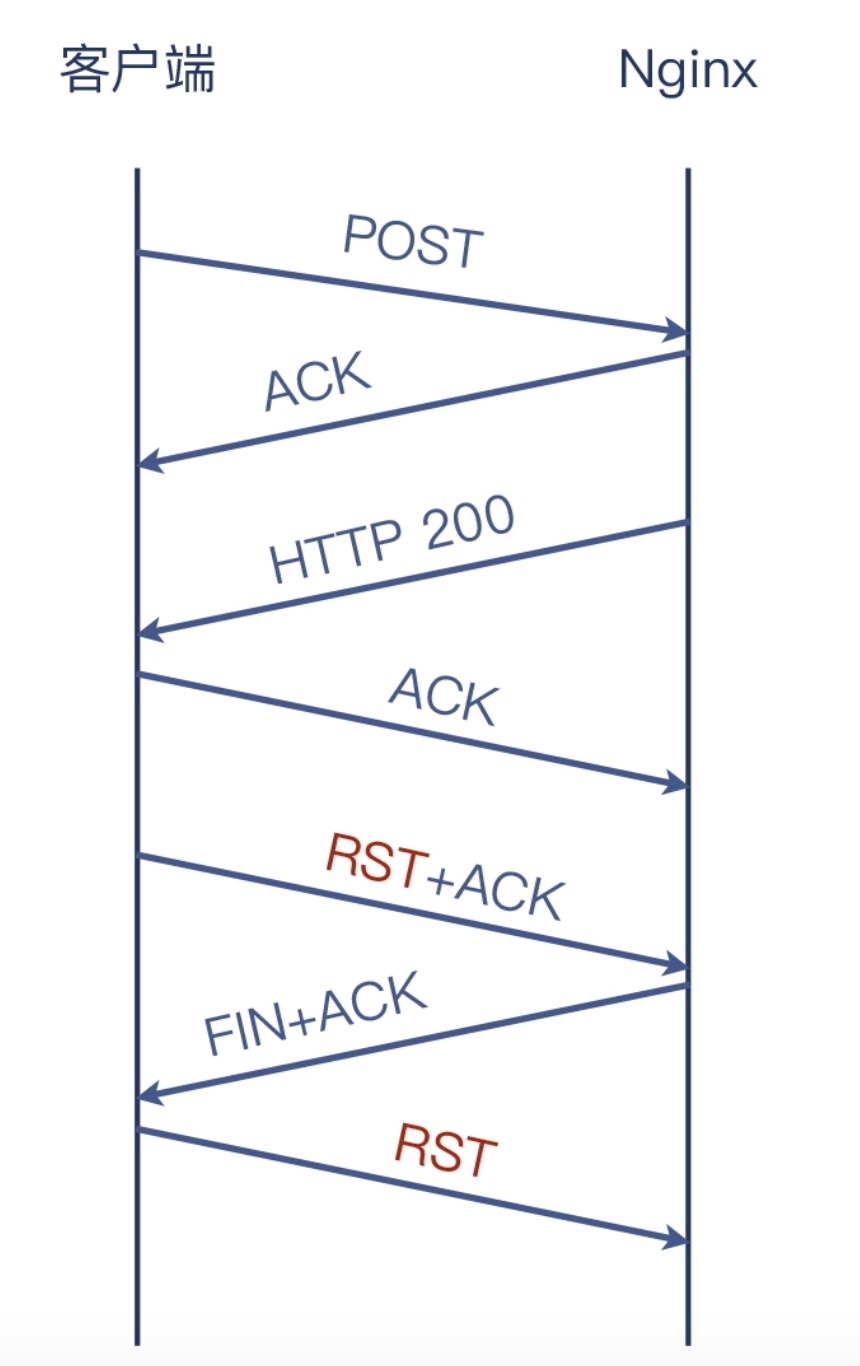
握手和POST的请求和响应都正常,但是Client端对HTTP的响应发送ACK之后,没有通过正常的发送FIN断开连接,而是发送了RST和ACK,导致了Server端的Nginx的recv()调用收到了ECONNRESET的报错
具体Client是否获取到数据,因为有对HTTP的响应的ACK,就应该是发送到Client端的Receive Buffer,但是断开连接应该调用的close(),走到tcp_close(),会判断buffer是否有未读的数据,如果有未读则调用tcp_send_active_reset(),发出RST,直接变为CLOSE状态,不进入TIME_WAIT状态
所以要查为什么没有拿走buffer中的数据
FIN完成挥手
正常的四次挥手流程
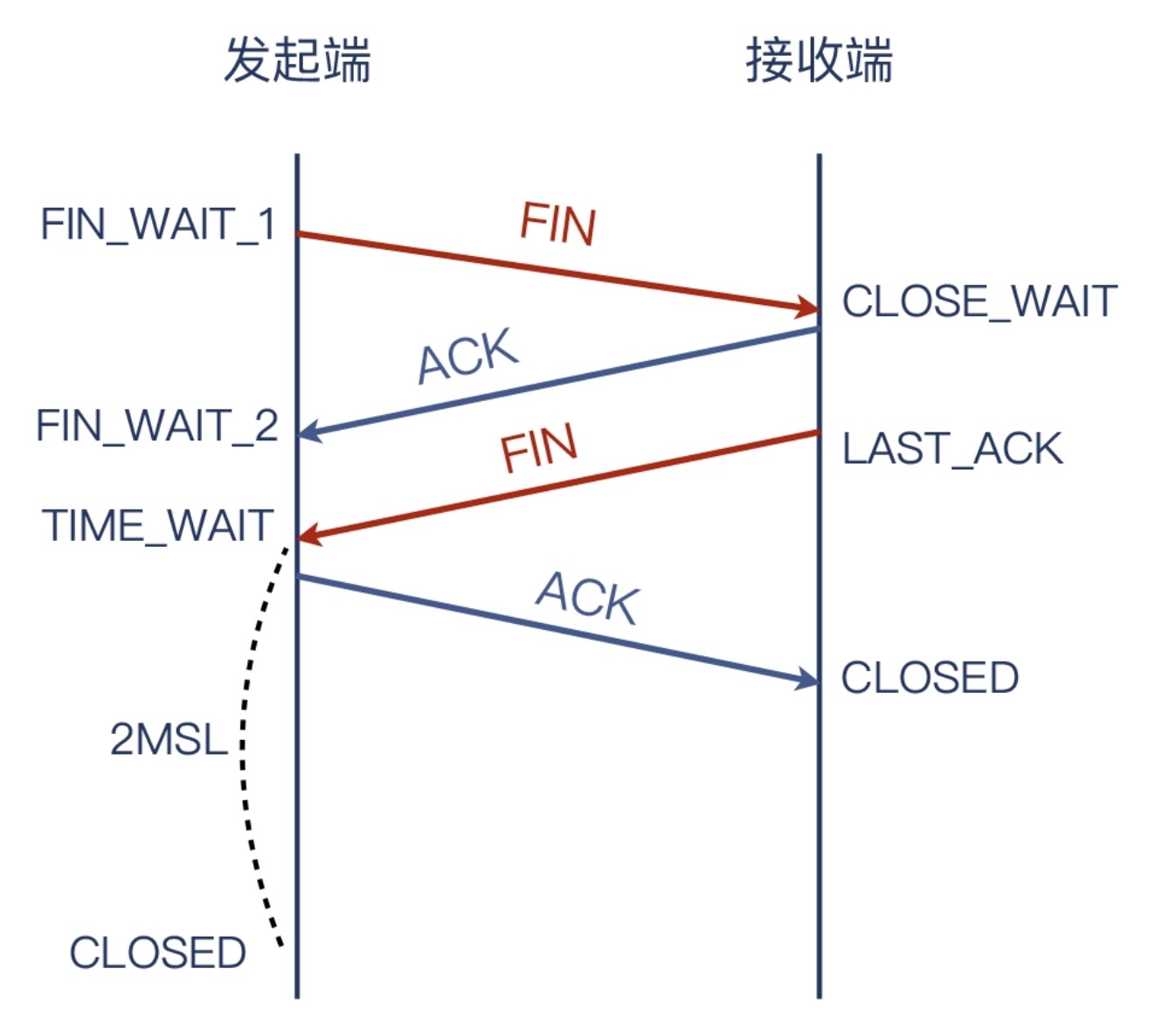
TCP的挥手可以在任意一方进行发送
就会各有一次FIN和一次ACK
但是有抓到的数据包不是这样

可以看到只有一个FIN的数据包,这是因为TCP的报文可以搭另一个报文的顺风车,类似
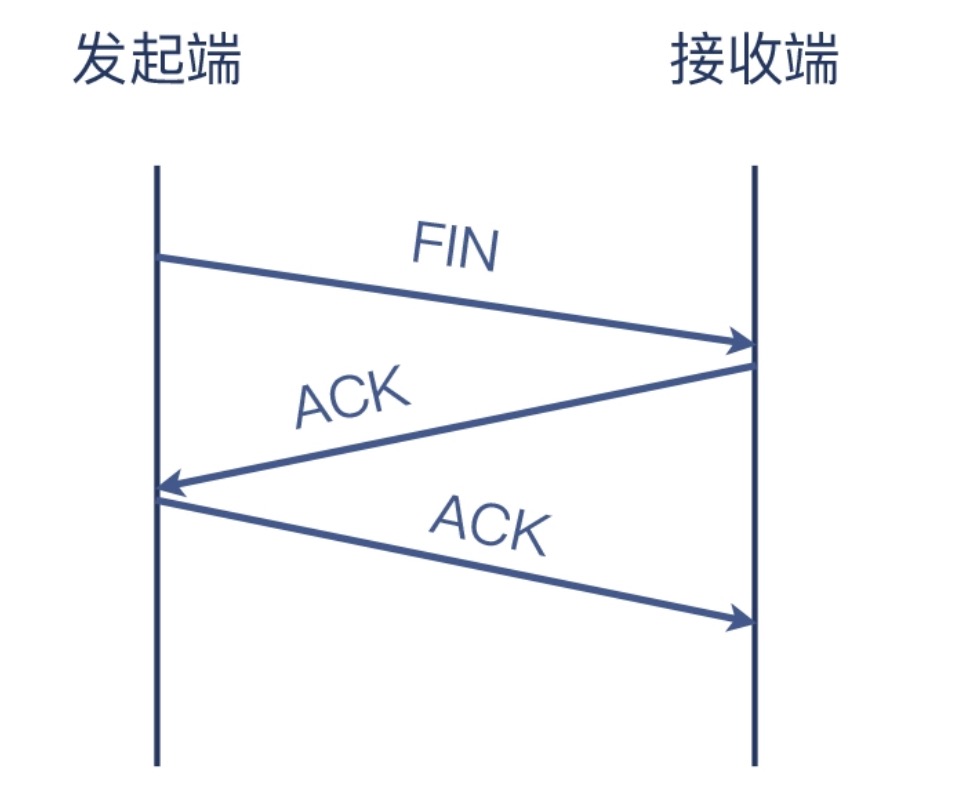
看Wireshark以为是Server端发起的FIN,是因为Wireshark在显示应用层信息的时候,TCP层面的控制信息就显示不全了,可以点开看
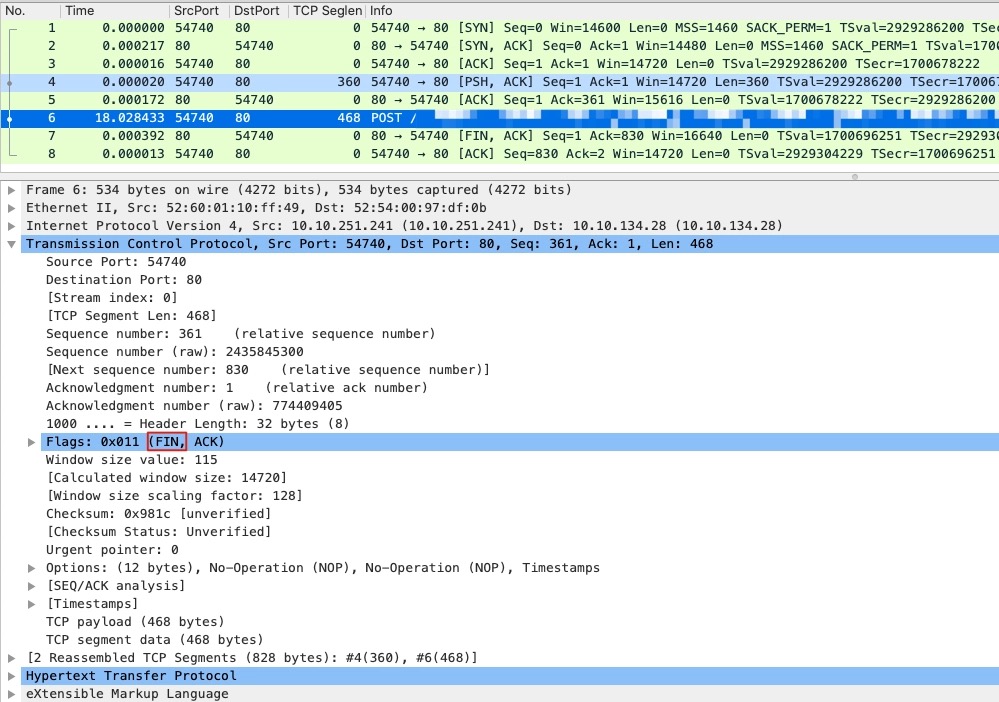
所以实际情况是
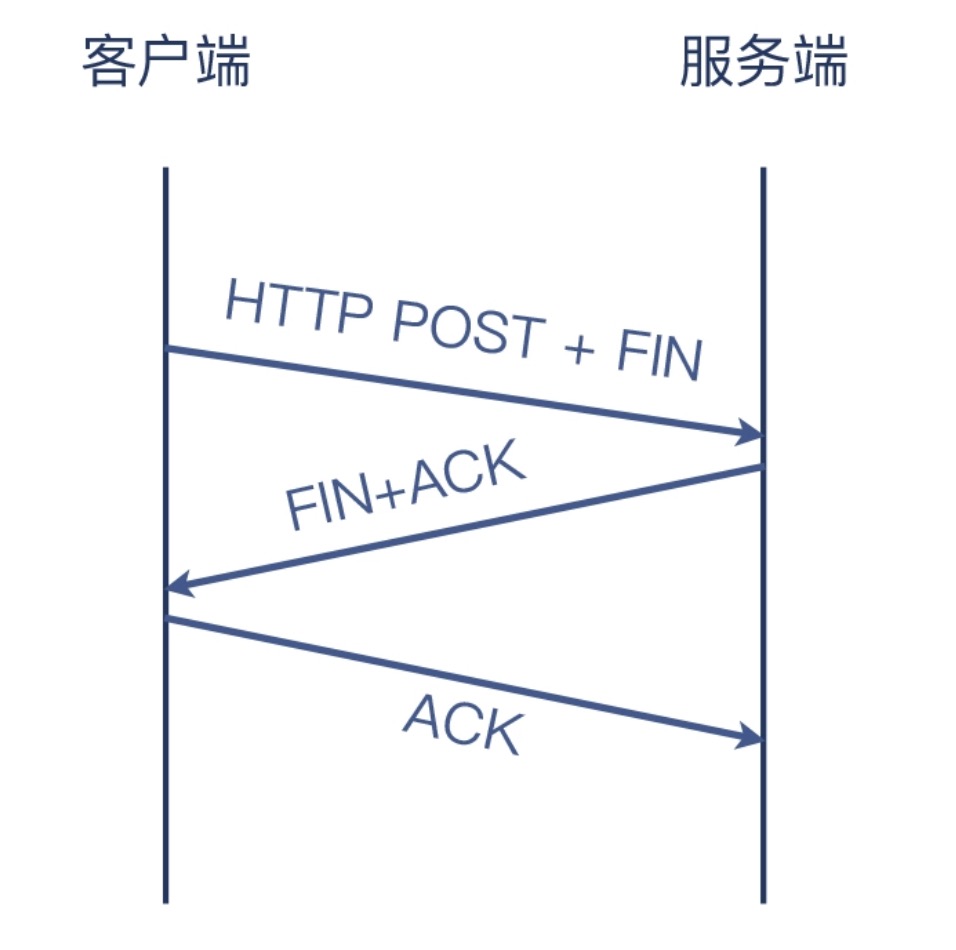
同时挥手
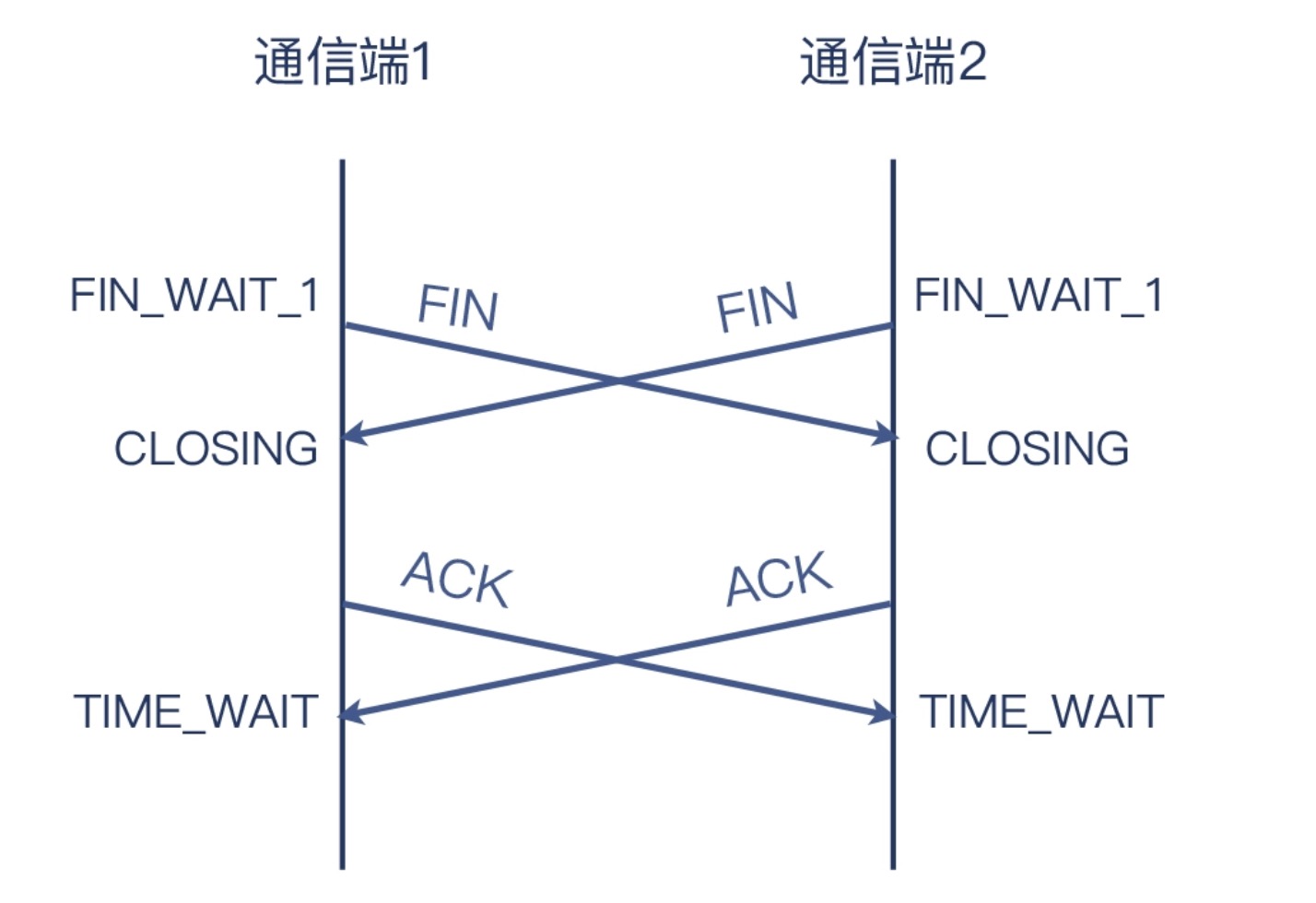
- 双方同时发起关闭后,也同时进入了
FIN_WAIT_1状态 - 然后也因为收到了对方的FIN,也都进入了
CLOSING状态 - 当双方都收到对方的ACK后,最终都进入了
TIME_WAIT状态
但是也意味两边都要等2MSL,才能复用这个五元组TCP连接
挥手不意味着双方都停止发送数据
一方发送FIN,意味着这个连接要开始关闭了,但是只是FIN的发送方不发送数据了,还可以接收数据并响应ACK,进入半关闭状态
对端仍然可以发送数据,会对FIN响应ACK,当发送完数据,就可以也发送FIN进行连接的关闭
定位防火墙:传输层的对比分析
防火墙需要结合传输层和应用层进行分析
示例应用A通过LB访问应用B,经常耗时过长,甚至事务无法在限定时间内完成,并且都出现在HTTPS
这时候不能光看A,也要看B,进行双向抓包
双向抓包需要注意的是
- 各端的抓包过滤条件一般以对端IP作为条件,比如
tcpdump dst host {对端IP} - 两端的抓包应该差不多在同时开始和结束
- 边重现,边抓包
查看抓包文件的流程
- 查看Expert Information
- 查看可疑报文
- 查找故障与网络现象的关系
- 对比两侧抓包
查看Expert Information
查看方式:
1:Analyze->Expert Information 2:左下角的黄色圆点
可以看到整体的网络传输状况
- Warning:条目的底色是黄色,意味着可能有问题,应重点关注
- Note:条目的底色是浅蓝色,是在允许范围内的小问题,也要关注,例如TCP本身就是容许一定程度的重传的,那么这些重传报文,就属于允许范围内
- Chat:条目的底色是正常蓝色,属于TCP/UDP的正常行为,可以了解通信里TCP握手和挥手分别有多少次等
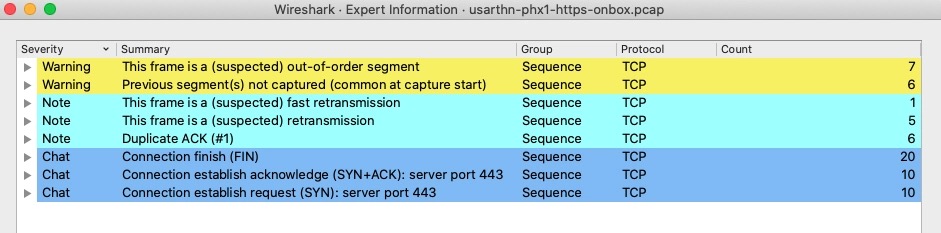
示例
- Warning:有7个乱序(Out-of-Order)的TCP报文,6个未抓到的报文(如果是在抓包开始阶段,这种未抓到报文的情况也属正常)
- Note:有1个怀疑是快速重传,5个是重传(一般是超时重传),6个重复确认
- Chat:有TCP挥手阶段的20个FIN包,握手阶段的10个SYN包和10个SYN+ACK包
乱序的出现,可能是中间设备发生了问题
关注问题报文
可以点开Warning前边的小箭头,展开乱序报文,尽量选择后边的报文,因为TCP Stream相对更完整,然后Follow即可
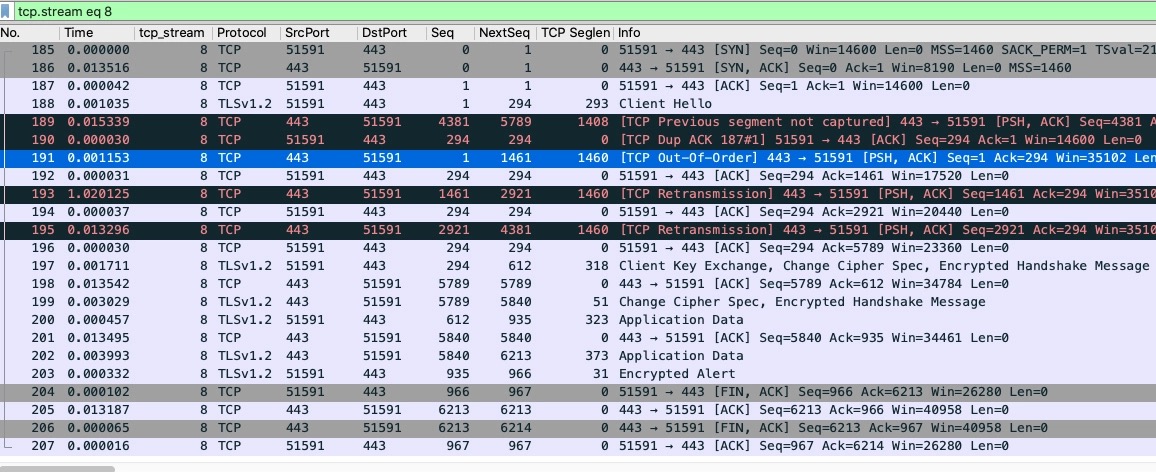
Seq、NextSeq、TCP Seglen都是自定义添加的,目的就是便于分析
这里红色报文需要重点关注
- 189:服务端(HTTPS)回复给客户端的报文,TCP previous segment not captured意思是,它之前的报文没有在应该出现的位置上被抓到(并不排除这些报文在之后被抓到)
- 190:客户端回复给服务端的重复确认报文(DupAck),可能(DupAck 报文数量多的话)会引起重传
- 191:服务端(HTTPS)给客户端的报文,是TCP Out-of-Order,即乱序报文
- 193:服务端(HTTPS)给客户端的 TCP Retransmission,即重传报文
- 195:也是服务端(HTTPS)给客户端的重传报文
可以看到192和193报文之间有1.020215s的间隔
结合应用层分析
为什么有一个1s的重试
对比两侧的抓包文件,使用TCP序号
TCP需要在Client的TCP Stream中选择SYN包的序列号4022234701
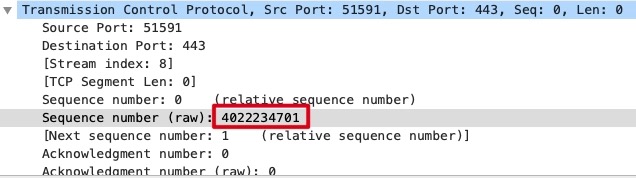
注意是Raw Sequence Number,而不是Wireshark处理过的Sequence Number
需要设置Wireshark->Preference->Protocols->TCP->Relative sequence numbers勾选
然后就可以通过过滤器过滤了
tcp.seq_raw eq 4022234701
在两端都找到对应的包进行Follow即可,左侧是Server抓包,右侧是Client抓包
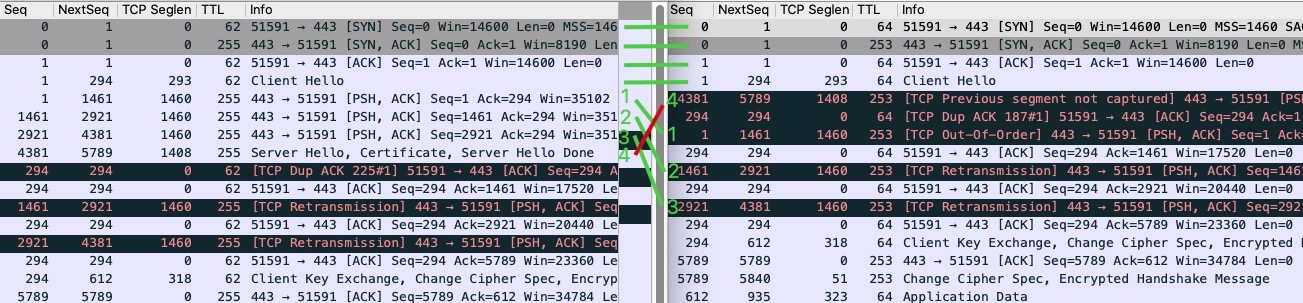
当时提示的
- Out-of-Order:包1、2、3
- TCP previous segment not captured:包4
在Server端分析
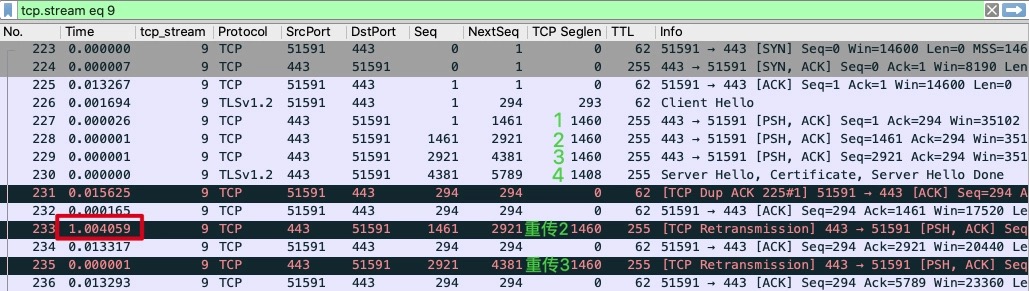
在Server端发送的4个报文,真正乱序的只有4,就是没有足够乱,没能触发3个重复确认进而快速重传,所以Server端进行超时重传,1s的超时是硬件的LB时间,Linux默认为200ms
内网环境常见的
- 丢包率在万分之一上下
- 乱序率大概在百分之一以下到千分之一左右都属正常
是因为两侧防火墙通过隧道进行解包和封包,IPIP协议会在IP头部再添加IP头部,消耗系统资源和代码层面bug就可能导致乱序
为什么HTTP的没有问题呢?
是因为TCP载荷只有200~300字节,远小于MSS的1460字节,而隧道会增大报文的长度,例如MTU为1500字节的IP报文,做了IPIP隧道就会到1520字节,所以主机的MTU都需要改小来适配隧道
如果网络没有启用Jumbo Frame,就会被拆分两个报文,而到了对端,就需要合并报文,出问题的概率就会增大
在Linux如果使用IPIP隧道会自动将接口MTU设置为1480,而防火墙的MTU逻辑不同
所以在大包的情况,就会引入两次额外开销
- IPIP本身的隧道头的封包和拆包
- IP层因为超过MTU而引发的报文分片和合片
出现问题可以是防火墙,路由器或者交换机等等
对于这种过中间层的一定要尽可能两侧抓包
可以使用的对两侧抓包进行关联的在每一层都有,例如TCP的头部
# TCP确认号
tcp.ack_raw == 754313633
而计算乱序报文的百分比:
- 计算全部报文数量:
capinfos file.pcap | grep packets - 计算乱序报文数量:
tshark -n -q -r file.pcap -z "io,stat,0,tcp.analysis.out_of_order" - 两者相除,或者肉眼也能看出来比例大概在什么数量级了
定位防火墙:网络层精准打击
基于TTL
过滤可以看到对端直接reset导致无法访问
ip.addr eq 253.61.239.103 and tcp.flags.reset eq 1

对于有中间层的情况,无法判断是中间层,还是后端Server进行了reset
这时候可以通过TTL来解决
不过TTL不是默认的展示列,可以选中报文中Internet Protocol Version->Time to live,右击选择Apply as column
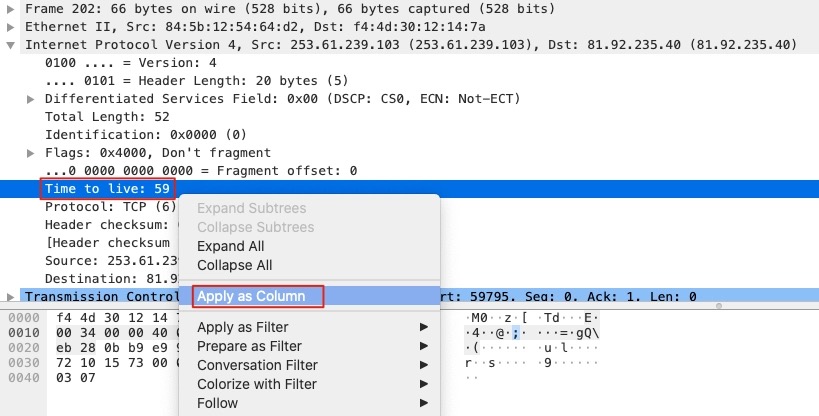
就能看到TTL列

可以看到在三次握手的时候SYN+ACK包的时候,TTL还是59,但是RST的时候TTL为64,证明这个RST包不是握手的Server端发出
排查路由器果然有一条异常策略
为什么握手成功了呢,因为异常策略是针对HTTP
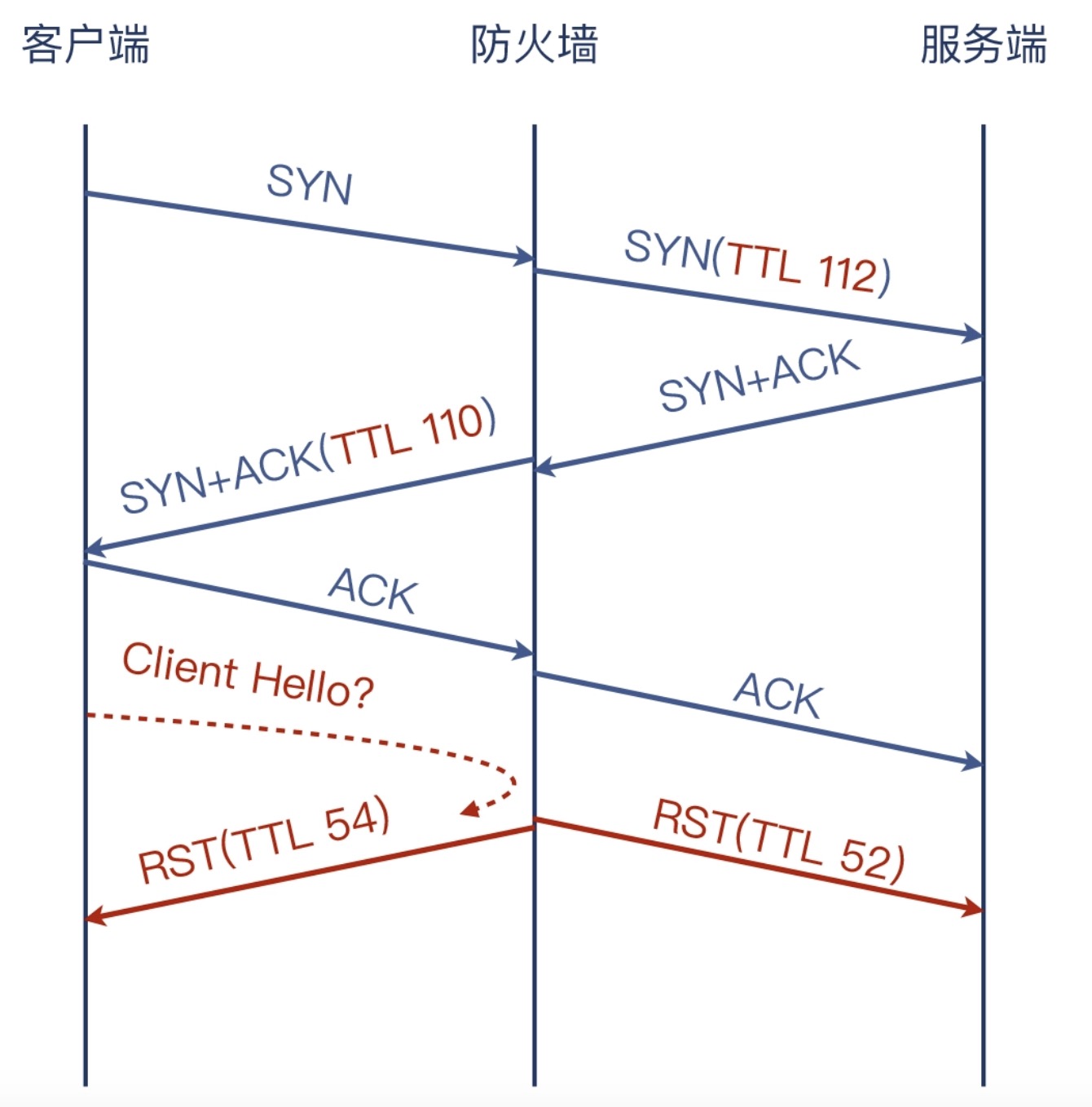
LDAPS服务报connection reset by peer
在两侧抓包
Client端

Server端

可以看到Client端发送了Client Hello,而Server端没有收到
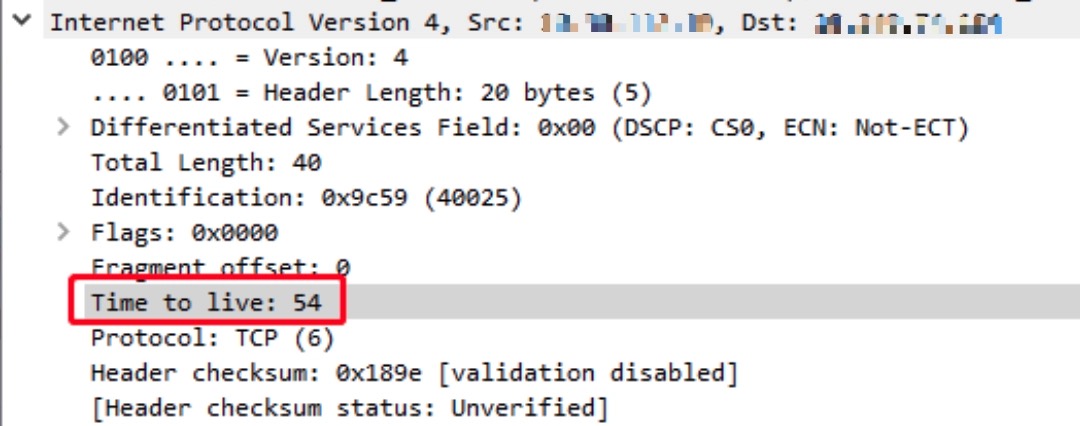
可以检查一下TTL
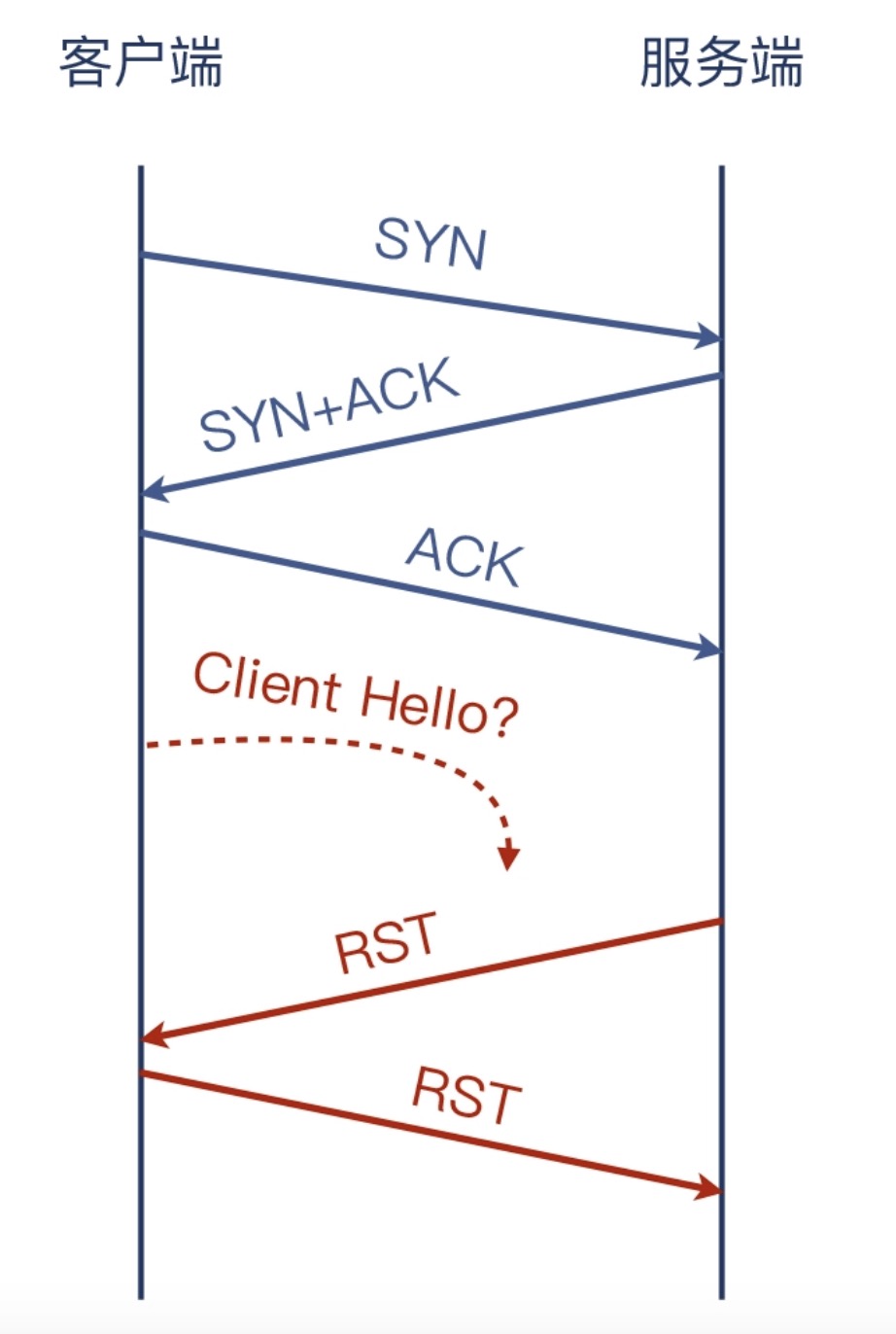
在Server端的SYN包的TTL为112
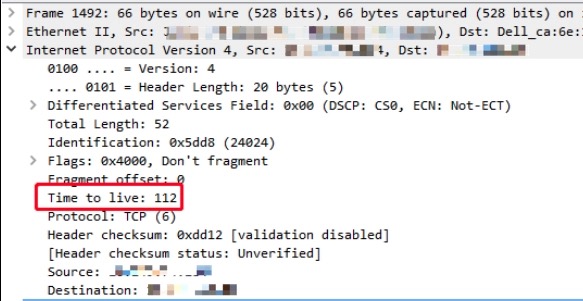
在Server端的RST包的TTL为55
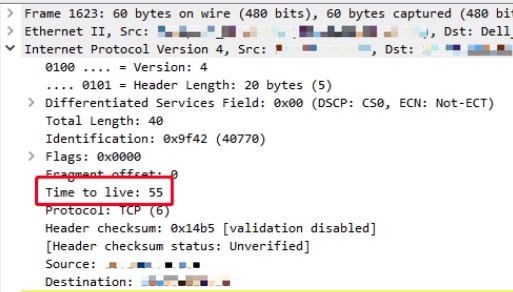
在Client端的SYN+ACK包的TTL为110
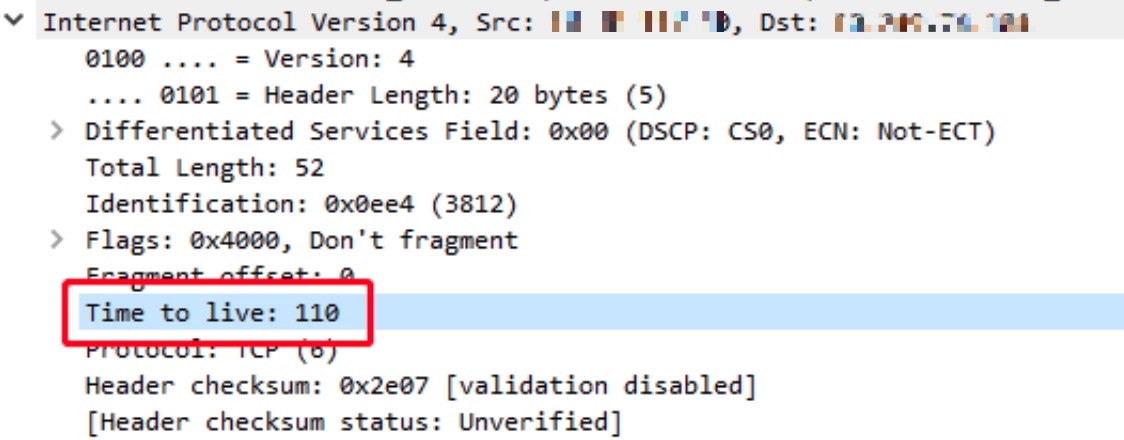
在Client端的RST包的TTL为54
所以Client Hello的包就是防火墙丢弃的,防火墙进行了双向的拦截,整体的链路就是
应对中间设备双向发送RST
被动的处理可以丢弃RST包
整体的报文的处理为
PREROUTING -> INPUT -> 本地处理 -> OUTPUT -> POSTROUTING
配置方式
iptables -I INPUT -s 110.242.68.0/24 -p tcp --sport 443 -m tcp --tcp-flags RST RST -m ttl --ttl-eq 64 -j DROP
配置tcp-flags的解释
# 第一个SYN是表示要检查SYN位,第二个SYN是表示这个位必须是1。可以参考man iptables-extensions的说明:
[!] --tcp-flags mask comp
Match when the TCP flags are as specified. The first argument mask is the flags which we should examine, written as a comma-separated
list, and the second argument comp is a comma-separated list of flags which must be set. Flags are: SYN ACK FIN RST URG PSH ALL NONE.
Hence the command
iptables -A FORWARD -p tcp --tcp-flags SYN,ACK,FIN,RST SYN
will only match packets with the SYN flag set, and the ACK, FIN and RST flags unset.
因为防火墙针对的是应用层,所以TCP连接是可以正常建立的
基于MAC地址
防火墙的MAC地址是不变的,也可以基于这个
主动的处理可以利用IPSec
比如IPv6默认启用了IPsec就获得了在第三层加密的能力
因为就连IP报文本身都是加密的,那么即使防火墙要插入报文,因为它不具备密钥,所以这个报文会被接收端认为非法而被丢弃。这样就有希望真正摆脱防火墙对传输层(TCP/UDP)的这种控制
GRE隧道
主机1添加路由项,使得本地去往第三方站点的流量,都走这条路由,也就是通过隧道到达主机2
ip tun add tun0 mode gre remote 172.17.158.46 local 172.17.158.48 ttl 64
ip link set tun0 up
ip addr add 100.64.0.1 peer 100.64.0.2 dev tun0
主机2添加对等隧道配置
ip tun add tun0 mode gre remote 172.17.158.48 local 172.17.158.46 ttl 64
ip link set tun0 up
ip addr add 100.64.0.2 peer 100.64.0.1 dev tun0
并且主机2开启ip_forward
sysctl net.ipv4.ip_forward=1
此时服务从主机2出去的时候IP还是主机1的100.64.0.1,所以要做一下SNAT
iptables -t nat -A POSTROUTING -d 110.242.68.0/24 -j MASQUERADE
可以在主机2模拟刚才的防火墙
# 全程干扰
iptables -I FORWARD -p tcp -m tcp --tcp-flags SYN SYN -j REJECT --reject-with tcp-reset
# 5s解除干扰
iptables -I FORWARD -p tcp -m tcp --tcp-flags SYN SYN -j REJECT --reject-with tcp-reset;sleep 5;iptables -D FORWARD -p tcp -m tcp --tcp-flags SYN SYN -j REJECT --reject-with tcp-reset
保活机制:心跳包异常导致应用重启
TCP长连接为何总是中断(这个案例并不好)
Client与Server保持长链一般会间隔一段时间发送一次心跳包
- 心跳保活
- 健康检查
而在发送的心跳包之后应用重启了
抓包的总览

可疑报文有
- 80个Error级别的Malformed Packet(格式错误)报文
- 2个RST报文
这80个报文被认为是SIGCOMP协议的(SIP 的信令压缩协议),但是Client端发送的并非SIP,是因为只有被公开广泛支持的数据格式和协议才能在Wireshark中正确展示,所以是被匹配了认为格式错误
随便追踪一个Error报文

可以看到是成对出现的
- 前一个报文的TCP载荷数据是01(十六进制)
- 后一个报文的TCP载荷数据是41(十六进制)
可能就是心跳的报文了,过滤载荷数据成都为1的
tcp.len eq 1

每对的报文间隔都是45s,和心跳包的机制也可以对上
TCP断开只会因为两种情况,FIN和RST报文
# FIN过滤,没有过滤到数据
tcp.flags.fin eq 1
# RST过滤
tcp.flags.reset eq 1

Follow一个报文,看到是没有什么规律,再将范围缩小到心跳包
tcp.stream eq 0 and tcp.payload eq 01

可以看到有一个心跳包间隔为58s,去掉tcp.payload eq 01查看这个包
- 572号报文(客户端发出)是心跳探测包
- 573号报文(服务端发出)是心跳回复包
- 574号报文(客户端发出)是客户端对573号报文的确认
- 575号报文(客户端发出)是一个RST 报文,它跟客户端日志报错有直接的关系
这里时间显示17s,是因为Time列的类型导致的,这里使用的Delta time displayed,和前一个报文的间隔时间,可以选择其他的时间类型

去掉无用的报文
tcp.stream eq 0 and (tcp.len == 1 or tcp.flags.reset == 1)

这个58s间隔发送数据包的正是重启的时间,说明Client没有遵循45s发送一次心跳探活导致的连接断开

TCP keep-alive
TCP的Socket默认不启用Keep-alive,不过大部分程序都支持,原理是通过setsockopt()系统调用对socket进行配置,启用Keep-alive
Linux内核也有3个相关的配置,详见man tcp
- 间隔时间:
net.ipv4.tcp_keepalive_time,其值默认为7200s - 最大探测次数:
net.ipv4.tcp_keepalive_probes,在探测无响应的情况下,可以发送的最多连续探测次数,其默认值为9 - 最长间隔:
net.ipv4.tcp_keepalive_intvl,在探测无响应的情况下,连续探测之间的最长间隔,其值默认为75s
如果启用了keep-alive没有自定义数值,就会使用默认值,当连接闲置(没有数据交互)达到7200s(2h)时发送心跳包,每次心跳包超时时间为75s,最多重试9次,也就是2小时11分钟
TCP自身的keep-alive报文的序列号
- 确认报文为上一个报文的序列号减1,载荷为0
- 回复报文的确认号为收到的序列号加1,载荷为0
Wireshark的抓包

链路为

TCP是双工的,两端都可以设置keep-alive,发送心跳的时候对端必须响应,如果两端都设置了,一端发送了,这样另一端的空闲时间也刷新为0了,所以只会看到空闲时间小的
HTTP Keep-alive
HTTP的Keep-alive,使用Connection的header来实现的
Connection: Keep-alive
目前你主流的HTTP/1.1和HTTP/2.0都默认是长连接,声明的主要目的是为了
- 兼容低版本
- 优雅关闭长连接
在HTTP/1.1使用Connection: Close的header,而HTTP/2.0使用的其他机制实现
针对长连接的流量迁移的时候,可以在rewrite policy中添加一定比例的返回Connection: Close,从而使Client重新进行DNS解析发起连接
TCP和HTTP的keep-alive两者的区别是
- 分别在四层和七层
- HTTP的keep-alive目的是复用TCP连接,快速传输大量数据,减少挥手带来的消耗和延迟
- HTTP的keep-alive的内部实现不依赖TCP的keep-alive
其他课后
TCP包中包含数据
tcp.payload contains "abc"
# 方法1:
frame contains abc
# 方法2:
ip contains abc
# 方法3:
tcp contains abc
# 方法4:
http contains abc
# 方法5:
tcp.payload contains 61-62-63
分段:MTU
MTU案例
通过LB的压测,设置1s超时,遇到了大量超时问题,而不通过LB则正常
在不通过LB的情况抓包,因为发生在HTTP层,可以直接通过http进行过滤

在通过LB的情况抓包,全局预览

有50个RST,Follow查看一个

可以看到有
- 54和55号报文,重复确认
- 154和410号报文,重传
- 568号报文,client端发起FIN
- 575号报文,Client端发起RST
握手完成之后,Client端就发送了POST请求,Server端响应了两个数据包
但是出现了(DupAck)重复确认,但是这两个DupAck的报文确认号为1,这个确认号1是握手阶段完成的时候确认号,也就是说Client发送POST请求的之后,没有收到响应的第一个数据报文,如果收到应该是1388+1
然后在收到第二个和第三个报文的时候,进行了DupAck报文的发送,进而Server端进行了重传,重传的大小也是1388,为响应的第一个数据报文的大小
整体流程就是

所以问题就是,为什么重传了两次都没有成功呢,参考没有通过LB的抓包对比

第一个数据包差了40字节
是因为过LB的时候,经过了两次Tunnel

而Tunnel1的封装比Tunnel2大,导致了Server使用了Tunnel2对应包大小,也就是1388,导致了Tunnel1封装后不能正常通过
对于只重传了2次,是因为Client设置了1s超时进行了挥手断开链接的操作
一般对策
查看MTU
$ ip addr
1: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:09:92:f9 brd ff:ff:ff:ff:ff:ff
inet 192.168.2.29/24 brd 192.168.2.255 scope global dynamic enp0s3
valid_lft 82555sec preferred_lft 82555sec
inet6 fe80::a00:27ff:fe09:92f9/64 scope link
valid_lft forever preferred_lft forever
调整为较小的MTU
$ sudo ip link set enp0s3 mtu 1460
其他对策
MTU是三层的概念,在四层对应的为MSS,就是TCP载荷的最大长度,算法为
MTU-IP头(20字节)-TCP头(20字节)
在握手的时候,SYN包里有Client的MSS,而在SYN+ACK包里有Server的MSS
对于MTU需要在主机端进行设置,而MSS的数据包可以被iptable修改
iptables -A FORWARD -p tcp --tcp-flags SYN SYN -j TCPMSS --set-mss 1400
整体流程

TSO
操作系统会对TCP做分段,但是这样会浪费CPU性能,所以网卡厂商提供了特性,将分段从内核下沉到网卡完成,就是TCP Segmentation Offload
在TSO启用之后,发送出去的报文就有可能超过MSS
在报文的接收方向,可以启用GRO(Generic Receive Offload),接收端网卡会对小报文进行拼接

查看是否开启特性可以
$ ethtool -k enp0s3 | grep offload
tcp-segmentation-offload: on
generic-segmentation-offload: on
generic-receive-offload: on
large-receive-offload: off [fixed]
rx-vlan-offload: on
tx-vlan-offload: on [fixed]
l2-fwd-offload: off [fixed]
hw-tc-offload: off [fixed]
esp-hw-offload: off [fixed]
esp-tx-csum-hw-offload: off [fixed]
rx-udp_tunnel-port-offload: off [fixed]
tls-hw-tx-offload: off [fixed]
tls-hw-rx-offload: off [fixed]
如果需要调整可以使用
$ sudo ethtool -K enp0s3 tso off
$ sudo ethtool -k enp0s3 | grep offload
tcp-segmentation-offload: off
IP分片
IP分片和TCP分段是在两个层的分包机制
理论上行IP分片比TCP分段要大40字节,但是如果不是的话,示例发往3000字节的
首先要进行的就是TCP分段

然后在IP分片的时候,可以看到不是每个IP包都有TCP头部的

实际上主机一般不会出现这种情况,MSS默认就是MTU-40,但是中间的网络设备的MTU就不一定了
DF(Don’t Fragment)位,不能分片,MTU又变小的就会被抛弃
1000字节(960+20+20)和一个520字节(500+20),对于1000字节的IP报文,会有MF(More Fragment)位为1,代表后续还有更多分片,而520字节的IP报文的MF字段为0
接收端在收到第一个IP报文的时候,发现MF为1,就会等待第二个IP报文的到达,因为MF为0,就会结合报文的fragment offset,将两个报文组合为一个完整的IP报文,进入正常处理流程,上报给TCP
而在显示的场景里,IP分片是尽量避免的
因为后续报文没有TCP头,防火墙不知道报文的传输层协议,就可能认为是有害报文进而丢弃
所以在Linux默认设置中,发出的IP层报文都设置了DF位
长肥管道
传输速度是网络性能中非常重要的部分,直接影响了性能
服务器网卡从多年前的1Gbps到10Gbps,而负载均衡和网络设备从10Gbps到40bps,甚至100Gbps
在这种背景下,仍然有数据传输400KB/s
传输速度分析工具
对这种情况进行抓包,在wireshark的工具中,有
- I/O Graph: 统计的是二层的数据包,在"Statistics"->"I/O Graph"
- TCP Stream Graph: 统计的是四层的数据包,在"Statistics"->"TCP Stream Graph"->"Time sequence(Stevens)"
对于I/O Graph,Wireshark会弹出一个趋势图,X轴是时间,Y轴是性能指标

针对网络性能,我们关注网络传输速度,所以选择All Bytes作为Y轴,并修改计量单位为Bytes

这样就能看到分时的速度了,经过慢启动,在7s的时候差不多在480KB/s

对于TCP Stream Graph,Wireshark会弹出一个趋势图,X轴为时间、Y轴为TCP序列号

网络传输知识点
一个报文的传输成功经历了
(开始)发送端 >> 数据报文 >> 接收端 >> ACK报文 >> 发送端(结束)
一来一回都是传输的耗时
在操作系统层面,收到ACK报文才算完成,这部分数据才能在发送缓存中删除

当数据在两个服务器之间传输的时候,就是在途数据,被称为Bytes in flight,在TCP详情页的SEQ/ACK analysis可以看到,在途的时间就是RTT
对于带宽很大,但是RTT也很大的网络,就被称为长肥网络(Long Fat Network),在长肥网络上的TCP连接为长肥管道(Long Fat Pipeline)
带宽跟往返时延RTT相乘,就是在途数据的最大数量了,即带宽时延积(Bandwidth Delay Product)
但是实际情况还需要考虑窗口的问题,包括三个窗口
- 接收窗口:它代表的是接收端当前最多能接收的字节数。通过TCP报文头部的Window字段,通信双方能互相了解到对方的接收窗口
- 拥塞窗口:发送端根据实际传输的拥塞情况计算出来的可发送字节数,但不公开在报文中。各自暗地里各维护各的,互相不知道,也不需要知道
- 发送窗口:对方的接收窗口和自身的拥塞窗口两者中,值较小者,实际发送的在途字节数不会大于这个值
解题
ping的时候使用icmp包,不会双方很多额外的处理时间,适合获取相对纯粹的网络往返时间,为134ms
TCP通信的时候,因为涉及到解包、缓冲、socket处理,判断依赖TCP详情的SEQ/ACK analysis的iRTT,为141ms

带宽时延积为0.134×10Gb/8=168MB,这个显然不是限制的原因
对于每一个TCP报文的头部都有window字段,为2^16,为64KB,在之后引进了Window Scale,说就到了2^30,即1GB
可以在wireshark中操作
- 将Calculated window size设置为自定义列,操作方式:右击TCP报文,在详情里找到Calculated window size右击,在弹出菜单中点击Apply as Column
- 过滤器输入框设置
tcp.srcport eq 22过滤对应的数据包

可以看到接收窗口在64KB附近浮动
可以看一下发送窗口,在TCP报文的[SEQ/ACK analysis]->[Bytes in flight],在弹出菜单中点击Apply as Column,发送窗口也在64KB
是因为Window Scale不支持吗

这里TCP Option-Windows scale: 6就是表示窗口系数(Scale Factor)为6,即 2^6 次方,真正的接收窗口值,是Window字段的值乘以64
所以传输速度就只有
window/RTT = 64KB/134ms = 478KB/s
结论就是调大接收端的接收窗口即可,linux有相关参数,比如mem_rmax、rmin这些,都会影响接受窗口
本地为什么没有发现这个问题呢?因为速度还取决于往返的时延,本地内网10ms以内,速度提高了十多倍
其他
tc tool使用的不是控制窗口,而是调整qdisc发送缓存队列,超出队列的数据就丢弃,进而达到速度限制的效果
窗口:TCP Window Full会影响传输效率吗
在上一个案例,接收窗口满了,但是没有收到TCP Window Full的提示
在一次传输比较慢的时候

TCP Window specified by the receiver is now completely Full的含义
- TCP Window一般没有特别指明就是接收窗口
- specified by the receiver明确是接收窗口
- is now completely Full表示在途数据的大小等于接收窗口
可以Follow一个报文看下

这里TCP Window Full是Wireshark自己解读出来的,会用方括号括起来
接收窗口是通过Server端返回ACK数据的时候会携带

这个报文的接收窗口就是112000
发送端发送的在途数据Bytes in flight就是112000,发送端的接收窗口用于接收确认的数据,为19200

目前传输的示意图就是

整个过程就是
- B发送了报文222给A,其中带有B自己的接收窗口 112000 字节,由于这是一个纯的确认报文,所以没有TCP载荷,也没有在途数据
- 报文抵达A端,进入A的接收缓冲区。A从222号报文中得知,B现在的接收窗口是112000字节,由于发送缓冲区有足够多的待发的数据,A选择用满这个接收窗口,也就是连续发送112000字节
- A把这112000字节的数据发送出来,成为报文224,其中还带有A自己的接收窗口值19200字节(由于这次主要是A向B传送数据,所以B发给A的基本都是纯确认报文,这些报文的载荷都是0。极端情况下,即使A的接收窗口为0,只要 B回复的报文没有载荷,它们也是可以持续通信的)
- 224报文抵达B端,正好填满B的接收窗口112000字节。Wireshark分别从222报文中读取到B的接收窗口值,从224报文中读取到在途字节数,由于两者相等,所以Wiresahrk提示TCP Window Full。而这个信息是被 Wiresahrk 展示在 224 报文中的。

