自己动手写docker1
目录:
docker使用的基础技术
Namespace
详细介绍参见namespace的6项隔离技术
里边的内容是C编写的,书中是用Go完成的
UTS namespace
用于隔离nodename和domainname标识
package main
import (
"os/exec"
"syscall"
"os"
"log"
)
func main() {
cmd := exec.Command("sh")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil{
log.Fatal(err)
}
}
在go run main.go新启动的shell中
$ hostname -b test
$ hostname
test
和在原来机器
$ hostname
why
通过echo $$获取当前shell的pid
$ readlink /proc/31803/ns/uts
uts:[4026531838]
$ readlink /proc/31850/ns/uts
uts:[4026532420]
可以看到这两个shell已经不在一个在UTS上已经不是一个namespace,但是其他的namespace还是在一起的
$ readlink /proc/31850/ns/pid
pid:[4026531836]
$ readlink /proc/31803/ns/pid
pid:[4026531836]
IPC namespace
也是在Cloneflags中加入syscall.CLONE_NEWIPC
...
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWIPC,
}
...
测试也是使用ipcmk -Q和ipcs -q来完成
PID namespace
加入syscall.CLONE_NEWPID,通过echo $$就能看到pid为1了
Mount namespace
加入syscall.CLONE_NEWNS
可以通过挂载proc的方式完成测试
$ ls /proc/
1 1437 1465 1768 18 1943 2031 2134 2311 26 2843 3167 32112 3417 3940 590 8098 cgroups execdomains kcore meminfo schedstat sysvipc
10 1455 15 1769 1837 1944 2045 2135 232 260 28893 31987 32113 348 40 591 8147 cmdline fb keys misc scsi timer_list
1105 1456 16 1770 1858 1945 2125 2136 233 2614 3 32036 32160 358 431 596 837 consoles filesystems key-users modules self timer_stats
1114 1457 17 1771 1871 1946 2126 2171 234 2615 3000 32062 32181 36 5 611 9 cpuinfo fs kmsg mounts slabinfo tty
12 1460 17520 1772 19 1947 2129 2187 235 2616 30449 32080 32184 3755 510 612 91 crypto interrupts kpagecount mtrr softirqs uptime
1282 1461 1755 1773 1911 1948 2130 2223 238 2631 31252 32085 32188 38 575 7 9652 devices iomem kpageflags net stat version
13 1462 1757 1774 1938 1949 2131 2236 249 27 31286 32087 329 39 579 757 acpi diskstats ioports loadavg pagetypeinfo swaps vmallocinfo
14 1463 1762 1775 1939 1984 2132 224 25 2716 31293 32088 3415 3902 580 8 buddyinfo dma irq locks partitions sys vmstat
1433 1464 1767 1776 1942 2 2133 2301 259 28 31298 32111 3416 3904 59 8000 bus driver kallsyms mdstat sched_debug sysrq-trigger zoneinfo
$ mount -t proc proc /proc
$ ls /proc/
1 bus cpuinfo dma filesystems ioports keys kpageflags meminfo mtrr sched_debug slabinfo sys timer_stats vmallocinfo
6 cgroups crypto driver fs irq key-users loadavg misc net schedstat softirqs sysrq-trigger tty vmstat
acpi cmdline devices execdomains interrupts kallsyms kmsg locks modules pagetypeinfo scsi stat sysvipc uptime zoneinfo
buddyinfo consoles diskstats fb iomem kcore kpagecount mdstat mounts partitions self swaps timer_list version
User namespace
加入syscall.CLONE_NEWNSUSER
package main
import (
"os/exec"
"syscall"
"os"
"log"
)
func main() {
cmd := exec.Command("sh")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWIPC | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS | syscall.CLONE_NEWUSER,
}
cmd.SysProcAttr.Credential = &syscall.Credential{Uid: uint32(1), Gid: uint32(1)}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil{
log.Fatal(err)
}
}
id看到为65534
Network namespace
加入syscall.CLONE_NEWNET
通过inconfig查看网卡
Cgourp
Cgroup提供了一组进程以及将来的子进程的资源限制、控制和统计能力,包括CPU,内存,存储和网络等。
Cgroup包括三个组件
- cgroup,进程分组的机制,一个cgroup包括一组进程,可以在其上添加subsystem的各种参数
- subsystem是一组资源控制模块
- hierarchy是将cgroup串成树状结构,通过树状结构完成cgroup的继承
三个组件的关系
- 一个subsystem只能附加到一个hierarchy
- 一个hierarchy可以附加多个subsystem
- 一个进程可以属于多个cgroup,但是这些cgroup必须在不同的hierarchy
- 一个fork的进程可以继承父进程的cgroup,也可以移动到其他的cgroup
subsystem包含
- blkio对块设备的输入输出访问控制
- cpu设置cpu的调度策略
- cpuacct统计进程占用cpu
- cpuset在多核架构进程可使用的CPU和内存
- devices对设备的访问控制
- freezer对进程的挂起和恢复’
- memory控制进程的内存占用
- net_cls将数据包分类,并可以对数据包限流和监控
- net_prio进程产生流量的优先级控制
- ns用于fork时可以进入新的namespace
可以通过"lssubsys -a"查看内核支持的subsystem
创建hierarchy
创建一个hierarchy
$ mkdir cgroup-test
$ sudo mount -t cgroup -o none,name=cgroup-test cgroup-test ./cgroup-test
$ ls ./cgroup-test
cgroup.clone_children cgroup.event_control cgroup.procs cgroup.sane_behavior notify_on_release release_agent tasks
- cgroup.clone_children cpuset的subsystem会读取这个配置,如果是1继承父cgroup的cpuset
- cgroup.procs 当前节点的cgroup中的进程组ID
- notify_on_release 当前节点的cgroup最后一个退出的时候执行release_agent
- release_agent 一个路径,用作进程退出之后自动清理掉不再使用的cgroup
- tasks 标识cgroup下面进程ID,如果将一个进程ID写入tasks文件,也会将进程加入对应的cgroup
$ mkdir cgourp-test1
$ mkdir cgourp-test2
$ tree .
.
├── cgourp-test1
│ ├── cgroup.clone_children
│ ├── cgroup.event_control
│ ├── cgroup.procs
│ ├── notify_on_release
│ └── tasks
├── cgourp-test2
│ ├── cgroup.clone_children
│ ├── cgroup.event_control
│ ├── cgroup.procs
│ ├── notify_on_release
│ └── tasks
├── cgroup.clone_children
├── cgroup.event_control
├── cgroup.procs
├── cgroup.sane_behavior
├── notify_on_release
├── release_agent
└── tasks
2 directories, 17 files
将进程加入cgroup组
$ sh -c 'echo $$ >> cgourp-test1/tasks'
$ cat /proc/$$/cgroup
14:name=cgroup-test:/cgourp-test1
11:hugetlb:/
10:blkio:/user.slice
9:memory:/user.slice
8:devices:/user.slice
7:perf_event:/
6:pids:/
5:freezer:/
4:net_prio,net_cls:/
3:cpuacct,cpu:/user.slice
2:cpuset:/
1:name=systemd:/user.slice/user-1001.slice/session-24730.scope
这里heirarchy并没有绑定subsystem,测试一下memory
$ mount | grep memory
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cd /sys/fs/cgroup/memory
stress --vm-bytes 200m --vm-keep -m 1
mkdir test-limit-memory
cd !$
echo "100m" > memory.limit_in_bytes
echo $$ > tasks
stress --vm-bytes 200m --vm-keep -m 1
go实现cgroup
package main
import (
"fmt"
"os/exec"
"syscall"
"os"
"log"
"path"
"io/ioutil"
"strconv"
)
const cgroupMemoryHierarchyMount = "/sys/fs/cgroup/memory"
func main() {
// fork之后执行
if os.Args[0] == "/proc/self/exe" {
fmt.Printf("current pid %d", syscall.Getpid())
fmt.Println()
cmd := exec.Command("sh", "-c", `stress --vm-bytes 200m --vm-keep -m 1`)
cmd.SysProcAttr = &syscall.SysProcAttr{}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil{
log.Fatal(err)
}
}
cmd := exec.Command("/proc/self/exe")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Start(); err != nil{
fmt.Println("ERROR", err)
os.Exit(1)
}else{
fmt.Printf("%v", cmd.Process.Pid)
os.Mkdir(path.Join(cgroupMemoryHierarchyMount, "test-memory-limit"), 0755)
ioutil.WriteFile(path.Join(cgroupMemoryHierarchyMount, "test-memory-limit", "tasks"), []byte(strconv.Itoa(cmd.Process.Pid)), 0644)
ioutil.WriteFile(path.Join(cgroupMemoryHierarchyMount, "test-memory-limit", "memory.limit_in_bytes"), []byte("100m"), 0644)
}
cmd.Process.Wait()
}
这里
- Run为子进程使用,会自行进行Wait()
- Start为父进程使用,需要自行Wait()
Union File System
简称为UnionFS,文件系统将很多文件和目录进行透明覆盖,形成一个单一的文件系统,提供挂载功能
这些文件提供read-only和read-write属性,联合文件系统写入的时候实际是写到了一个新的文件中,这个技术为写时复制
AUFS重写了早期的UnionFS1.x,目前docker仍使用aufs为第一种第一种存储驱动
docker的存储目录
/var/lib/docker/aufs/diff下存储的image layer/var/lib/docker/aufs/layer下存储的堆栈layer的metadata/var/lib/docker/aufs/mnt为当前启动容器的readonly的init layer,和一个read-write的layer/var/lib/docker/containers/<container-id>存放的container的metadata和配置文件
可以通过命令完成aufs的挂载
创建文件
mkdir ./container-layer
mkdir ./image-layer1
mkdir ./image-layer2
mkdir ./image-layer3
mkdir ./image-layer4
echo '1' > ./image-layer1/image-layer1.txt
echo '2' > ./image-layer2/image-layer2.txt
echo '3' > ./image-layer3/image-layer3.txt
echo '4' > ./image-layer4/image-layer4.txt
进行挂载
mount -t aufs -o dirs=./container-layer:./image-layer4:./image-layer3:./image-layer2:./image-layer1 none /mnt
这里只有第一个目录为read-write,其他的为read-only,也可以在/sys/fs/aufs/目录看到aufs的挂载情况
进行mnt文件的修改测试会发现image-layer中的文件没有变化,而是在container-layer生成了新文件
aufs的安装
# 进入repo目录
cd /etc/yum.repo.d
# 下载文件
wget https://yum.spaceduck.org/kernel-ml-aufs/kernel-ml-aufs.repo
# 安装
yum install kernel-ml-aufs
vi /etc/default/grub
# 修改参数, 表示启动时选择第一个内核
###################################
GRUB_DEFAULT=0
###################################
# 重新生成grub.cfg
grub2-mkconfig -o /boot/grub2/grub.cfg
# 重启计算机
reboot
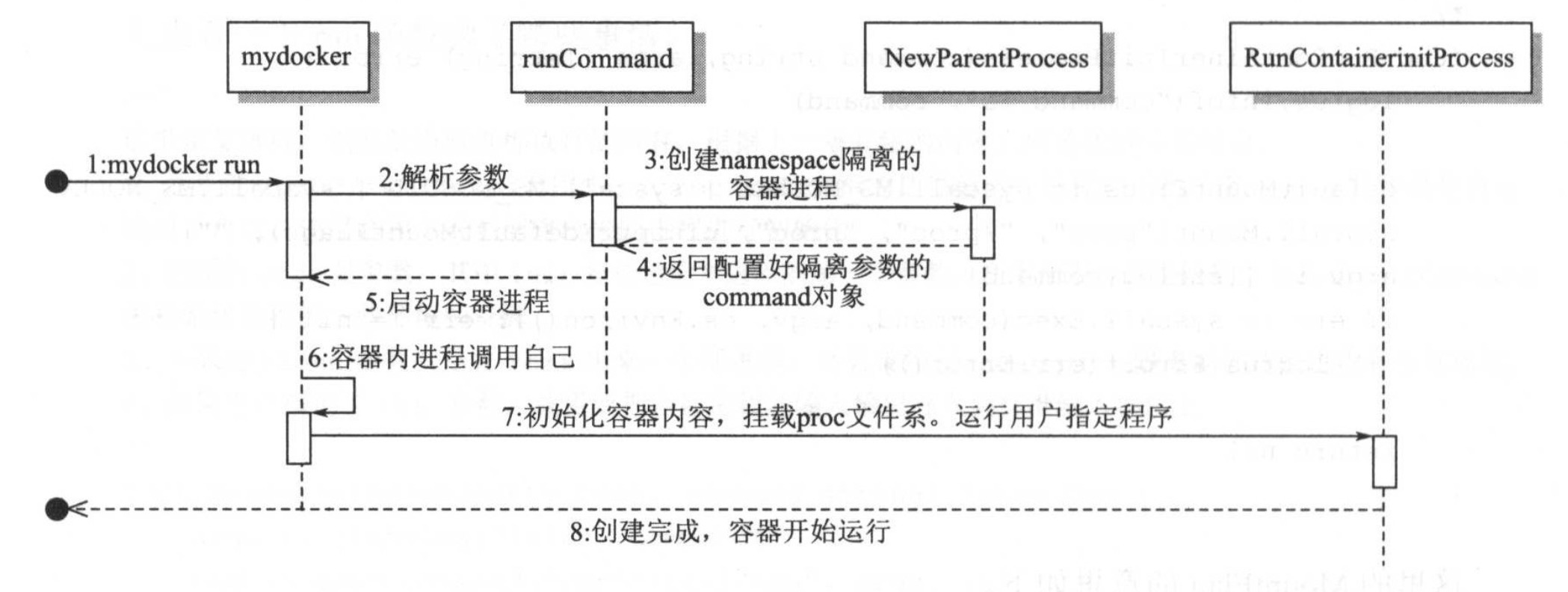
构造容器
run命令版本容器
proc文件介绍
- /proc/N/cmdline 启动命令
- /proc/N/cwd 链接到进程的工作目录
- /proc/N/environ 进程环境变量列表
- /proc/N/exe 链接到进程执行命令文件
- /proc/N/fd 进程包含的所有文件描述符
- /proc/N/maps 与进程相关的内存映射信息
- /proc/N/mem 进程持有的内存,不可读
- /proc/N/root 链接到进程的根目录
- /proc/N/stat 进程的状态
- /proc/N/statm 进程使用内存的状态
- /proc/N/status 进程状态信息,比以上两个有可读性
- /proc/self/ 链接到当前运行的进程
功能类似docker run -ti [command]
详见github.com/xianlubird/mydocker的code-3.1
main.go
package main
import (
log "github.com/Sirupsen/logrus"
"github.com/urfave/cli"
"os"
)
const usage = `mydocker is a simple container runtime implementation.
The purpose of this project is to learn how docker works and how to write a docker by ourselves
Enjoy it, just for fun.`
func main() {
app := cli.NewApp()
app.Name = "mydocker"
app.Usage = usage
app.Commands = []cli.Command{
initCommand,
runCommand,
}
app.Before = func(context *cli.Context) error {
// Log as JSON instead of the default ASCII formatter.
log.SetFormatter(&log.JSONFormatter{})
log.SetOutput(os.Stdout)
return nil
}
if err := app.Run(os.Args); err != nil {
log.Fatal(err)
}
}
包括了initCommand和runCommand
runCommand判断是否是使用run -ti参数,并且获取后边的cmd
var runCommand = cli.Command{
Name: "run",
Usage: `Create a container with namespace and cgroups limit
mydocker run -ti [command]`,
Flags: []cli.Flag{
cli.BoolFlag{
Name: "ti",
Usage: "enable tty",
},
},
Action: func(context *cli.Context) error {
if len(context.Args()) < 1 {
return fmt.Errorf("Missing container command")
}
cmd := context.Args().Get(0)
tty := context.Bool("ti")
Run(tty, cmd)
return nil
},
}
run调用创建container进程,parent.Start()启动进程
func Run(tty bool, command string) {
parent := container.NewParentProcess(tty, command)
if err := parent.Start(); err != nil {
log.Error(err)
}
parent.Wait()
os.Exit(-1)
}
NewParentProcess调用当前命令,构建"/proc/self/exe init command"子进程,添加namespaces,重新执行该命令,子进程走initCommand逻辑
func NewParentProcess(tty bool, command string) *exec.Cmd {
args := []string{"init", command}
cmd := exec.Command("/proc/self/exe", args...)
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS |
syscall.CLONE_NEWNET | syscall.CLONE_NEWIPC,
}
if tty {
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
}
return cmd
}
而initCommand是执行的逻辑,判断是否是使用init
var initCommand = cli.Command{
Name: "init",
Usage: "Init container process run user's process in container. Do not call it outside",
Action: func(context *cli.Context) error {
log.Infof("init come on")
cmd := context.Args().Get(0)
log.Infof("command %s", cmd)
err := container.RunContainerInitProcess(cmd, nil)
return err
},
}
先挂载proc文件系统
func RunContainerInitProcess(command string, args []string) error {
logrus.Infof("command %s", command)
defaultMountFlags := syscall.MS_NOEXEC | syscall.MS_NOSUID | syscall.MS_NODEV
syscall.Mount("proc", "/proc", "proc", uintptr(defaultMountFlags), "")
argv := []string{command}
if err := syscall.Exec(command, argv, os.Environ()); err != nil {
logrus.Errorf(err.Error())
}
return nil
}
- syscall.MS_NOEXEC 在本文件系统不允许运行其他程序
- syscall.MS_NOSUID 系统运行时不允许set-user-id或set-group-id
- syscall.MS_NODEV Linux2.4之后mount的默认参数
容器创建的时候,第一个进程并不是当前的进程,而是init初始化进程
syscall.Exec最终调用的kernel的int execve(const char *filename, char *const args[], char *const envp[]);,作用为执行当前文件对应的程序,并覆盖当前进程的镜像,数据和堆栈等信息,包含Pid。这样才能在容器创建之后,保证用户进程的pid为1
构建并启动
$ go build .
$ ./mydocker run -ti /bin/sh
增加资源限制
进行资源限制的
package subsystems
// 资源限制的结构体
type ResourceConfig struct {
MemoryLimit string
CpuShare string
CpuSet string
}
// 定义subsystem可以执行的方法,cgroup被抽象为path
type Subsystem interface {
Name() string
Set(path string, res *ResourceConfig) error
Apply(path string, pid int) error
Remove(path string) error
}
示例memory.go
package subsystems
import(
"fmt"
"io/ioutil"
"os"
"path"
"strconv"
)
// memory subsystem实现
type MemorySubSystem struct {
}
// 设置内存资源限制
func (s *MemorySubSystem) Set(cgroupPath string, res *ResourceConfig) error {
// GetCgroupPath获取当前subsystem在虚拟文件系统的路径
if subsysCgroupPath, err := GetCgroupPath(s.Name(), cgroupPath, true); err == nil {
if res.MemoryLimit != "" {
// 写入memory.limit_in_bytes
if err := ioutil.WriteFile(path.Join(subsysCgroupPath, "memory.limit_in_bytes"), []byte(res.MemoryLimit), 0644); err != nil {
return fmt.Errorf("set cgroup memory fail %v", err)
}
}
return nil
} else {
return err
}
}
// 删除内存资源限制,就是把cgroup对应的目录删除
func (s *MemorySubSystem) Remove(cgroupPath string) error {
if subsysCgroupPath, err := GetCgroupPath(s.Name(), cgroupPath, false); err == nil {
return os.RemoveAll(subsysCgroupPath)
} else {
return err
}
}
// 将进程加入cgroup
func (s *MemorySubSystem) Apply(cgroupPath string, pid int) error {
if subsysCgroupPath, err := GetCgroupPath(s.Name(), cgroupPath, false); err == nil {
// pid写入tasks文件
if err := ioutil.WriteFile(path.Join(subsysCgroupPath, "tasks"), []byte(strconv.Itoa(pid)), 0644); err != nil {
return fmt.Errorf("set cgroup proc fail %v", err)
}
return nil
} else {
return fmt.Errorf("get cgroup %s error: %v", cgroupPath, err)
}
}
func (s *MemorySubSystem) Name() string {
return "memory"
}
挂载了subsystem的hierarchy,memory相关可以通过cat /proc/<pid>/mountinfo,也可以是cat /proc/self/mountinfo
$ cat /proc/self/mountinfo
...
35 24 0:31 / /sys/fs/cgroup/memory rw,nosuid,nodev,noexec,relatime shared:18 - cgroup cgroup rw,memory
通过代码就是
func FindCgroupMountpoint(subsystem string) string {
f, err := os.Open("/proc/self/mountinfo")
if err != nil {
return ""
}
defer f.Close()
scanner := bufio.NewScanner(f)
for scanner.Scan() {
txt := scanner.Text()
fields := strings.Split(txt, " ")
for _, opt := range strings.Split(fields[len(fields)-1], ",") {
if opt == subsystem {
return fields[4]
}
}
}
if err := scanner.Err(); err != nil {
return ""
}
return ""
}
获取到CgroupRoot,然后获取这些挂载点的绝对路径,如果不存在就创建
func GetCgroupPath(subsystem string, cgroupPath string, autoCreate bool) (string, error) {
cgroupRoot := FindCgroupMountpoint(subsystem)
if _, err := os.Stat(path.Join(cgroupRoot, cgroupPath)); err == nil || (autoCreate && os.IsNotExist(err)) {
if os.IsNotExist(err) {
if err := os.Mkdir(path.Join(cgroupRoot, cgroupPath), 0755); err == nil {
} else {
return "", fmt.Errorf("error create cgroup %v", err)
}
}
return path.Join(cgroupRoot, cgroupPath), nil
} else {
return "", fmt.Errorf("cgroup path error %v", err)
}
}
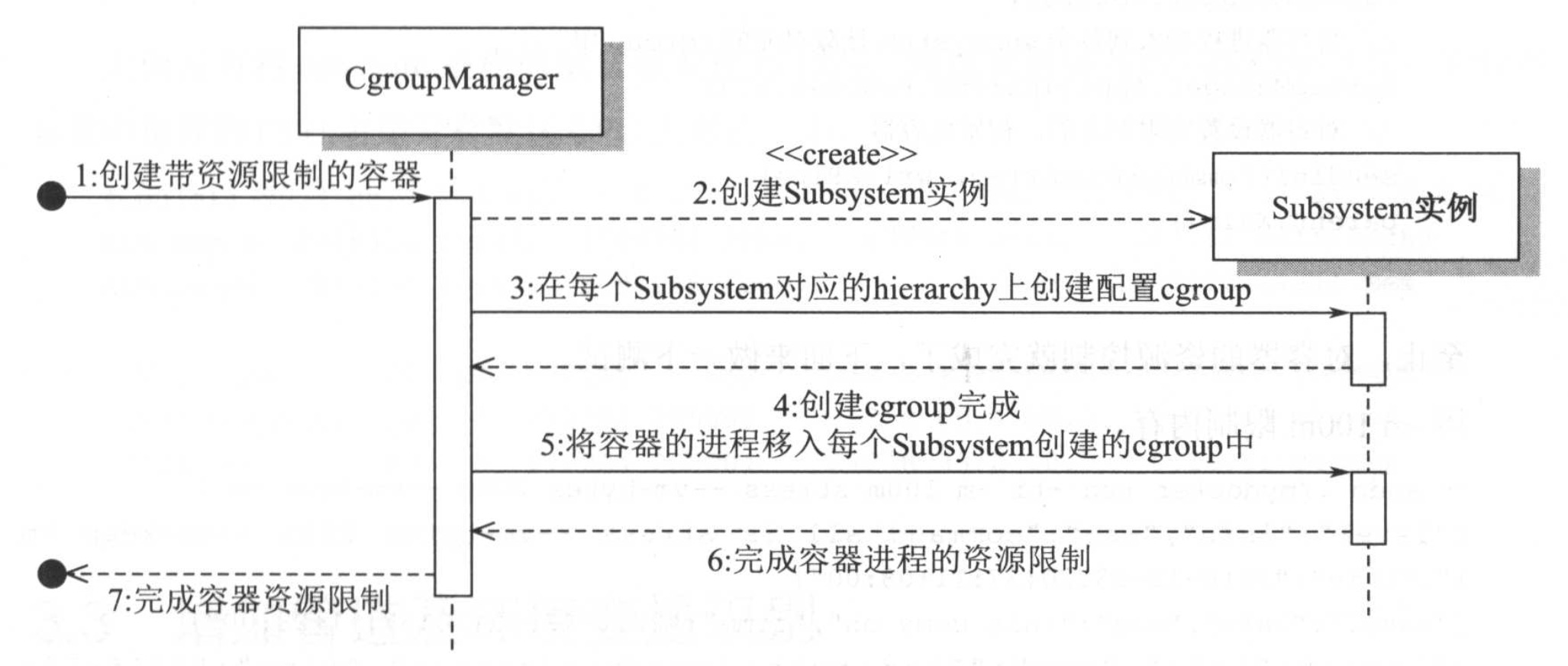
最后将subsystem与cgroup关联起来
type CgroupManager struct {
// cgroup在hierarchy中的路径 相当于创建的cgroup目录相对于root cgroup目录的路径
Path string
// 资源配置
Resource *subsystems.ResourceConfig
}
func NewCgroupManager(path string) *CgroupManager {
return &CgroupManager{
Path: path,
}
}
// 设置cgroup资源限制
func (c *CgroupManager) Set(res *subsystems.ResourceConfig) error {
for _, subSysIns := range(subsystems.SubsystemsIns) {
subSysIns.Set(c.Path, res)
}
return nil
}
//释放cgroup
func (c *CgroupManager) Destroy() error {
for _, subSysIns := range(subsystems.SubsystemsIns) {
if err := subSysIns.Remove(c.Path); err != nil {
logrus.Warnf("remove cgroup fail %v", err)
}
}
return nil
}
启动就变为了
func Run(tty bool, comArray []string, res *subsystems.ResourceConfig) {
parent, writePipe := container.NewParentProcess(tty)
if parent == nil {
log.Errorf("New parent process error")
return
}
if err := parent.Start(); err != nil {
log.Error(err)
}
// use mydocker-cgroup as cgroup name
cgroupManager := cgroups.NewCgroupManager("mydocker-cgroup")
defer cgroupManager.Destroy()
cgroupManager.Set(res)
cgroupManager.Apply(parent.Process.Pid)
sendInitCommand(comArray, writePipe)
parent.Wait()
}
在fork完成后
- 在各个限制资源的cgrouproot下创建对应的路径
- 将资源限制写入对应的文件
- 将fork获取到的子进程pid加入到对应的task文件
可以测试stress --vm-bytes 200m --vm-keep -m 1命令
./mydocker run -ti -m 100m stress --vm-bytes 200m --vm-keep -m 1
测试时间片使用-cpushare参数,默认为1024
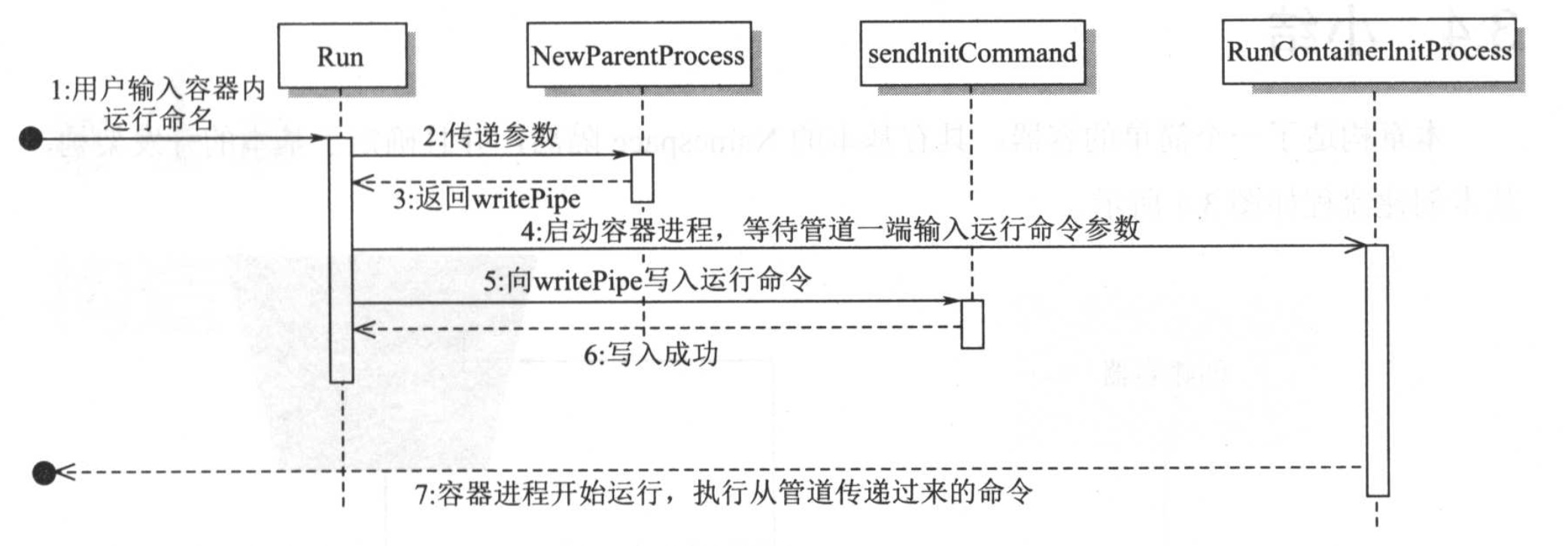
增加管道和环境变量
Linux创建两个进程的时候,一般进程之间通信都是通过管道完成的,管道是IPC的一种方式,为半双工的,同时只能有一端写入,一端读取
管道分两类
- 无名管道 用于有亲缘性进程
- 有名管道,又称FIFO管道,存在于文件系统的管道,可以在任何没有亲缘关系的进程进行访问,通过mkfifo()创建
管道有一个固定大小的缓冲区,一般为4KB,当管道写满,写进程就会被堵塞,直到读进程将数据读取,如果管道为空会堵塞读进程
之前实现的容器命令是通过/proc/self/exec init arg完成,再由init进程去解析,如果参数很长,或者特殊字符的存在就可能失败,所以采用管道的方式实现父子进程的通信
通过pipe方法生成匿名管道
func NewPipe() (*os.File, *os.File, error) {
read, write, err := os.Pipe()
if err != nil {
return nil, nil, err
}
return read, write, nil
}
创建容器进程的时候初始化管道,
func NewParentProcess(tty bool) (*exec.Cmd, *os.File) {
readPipe, writePipe, err := NewPipe()
if err != nil {
log.Errorf("New pipe error %v", err)
return nil, nil
}
cmd := exec.Command("/proc/self/exe", "init")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS |
syscall.CLONE_NEWNET | syscall.CLONE_NEWIPC,
}
if tty {
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
}
cmd.ExtraFiles = []*os.File{readPipe}
return cmd, writePipe
}
ExtraFiles指定新进程要继承的其他打开的文件。它不包括标准输入、标准输出或标准错误,所以加入的文件描述符i将成为子进程的文件描述符3+i,这就只添加了管道的读端,在子进程中文件描述符为4
在docker容器中也可以看到
$ ls /proc/self/fd -l
total 0
lrwx------ 1 work work 64 Jan 5 21:20 0 -> /dev/pts/0
lrwx------ 1 work work 64 Jan 5 21:20 1 -> /dev/pts/0
lrwx------ 1 work work 64 Jan 5 21:20 2 -> /dev/pts/0
lr-x------ 1 work work 64 Jan 5 21:20 3 -> /proc/87809/fd
然后将命令写入到管道
func sendInitCommand(comArray []string, writePipe *os.File) {
command := strings.Join(comArray, " ")
log.Infof("command all is %s", command)
writePipe.WriteString(command)
writePipe.Close()
}
启动子进程之前先去读取到启动的参数,读取不到的时候会阻塞
func RunContainerInitProcess() error {
cmdArray := readUserCommand()
if cmdArray == nil || len(cmdArray) == 0 {
return fmt.Errorf("Run container get user command error, cmdArray is nil")
}
defaultMountFlags := syscall.MS_NOEXEC | syscall.MS_NOSUID | syscall.MS_NODEV
syscall.Mount("proc", "/proc", "proc", uintptr(defaultMountFlags), "")
//获取命令的绝对路径
path, err := exec.LookPath(cmdArray[0])
if err != nil {
log.Errorf("Exec loop path error %v", err)
return err
}
log.Infof("Find path %s", path)
if err := syscall.Exec(path, cmdArray[0:], os.Environ()); err != nil {
log.Errorf(err.Error())
}
return nil
}
从管道获取启动参数的方式
func readUserCommand() []string {
pipe := os.NewFile(uintptr(3), "pipe")
msg, err := ioutil.ReadAll(pipe)
if err != nil {
log.Errorf("init read pipe error %v", err)
return nil
}
msgStr := string(msg)
return strings.Split(msgStr, " ")
}
整体流程