

极客时间——Linux内核技术实战课:内核态CPU飙高问题
目录:
CPU如何执行任务
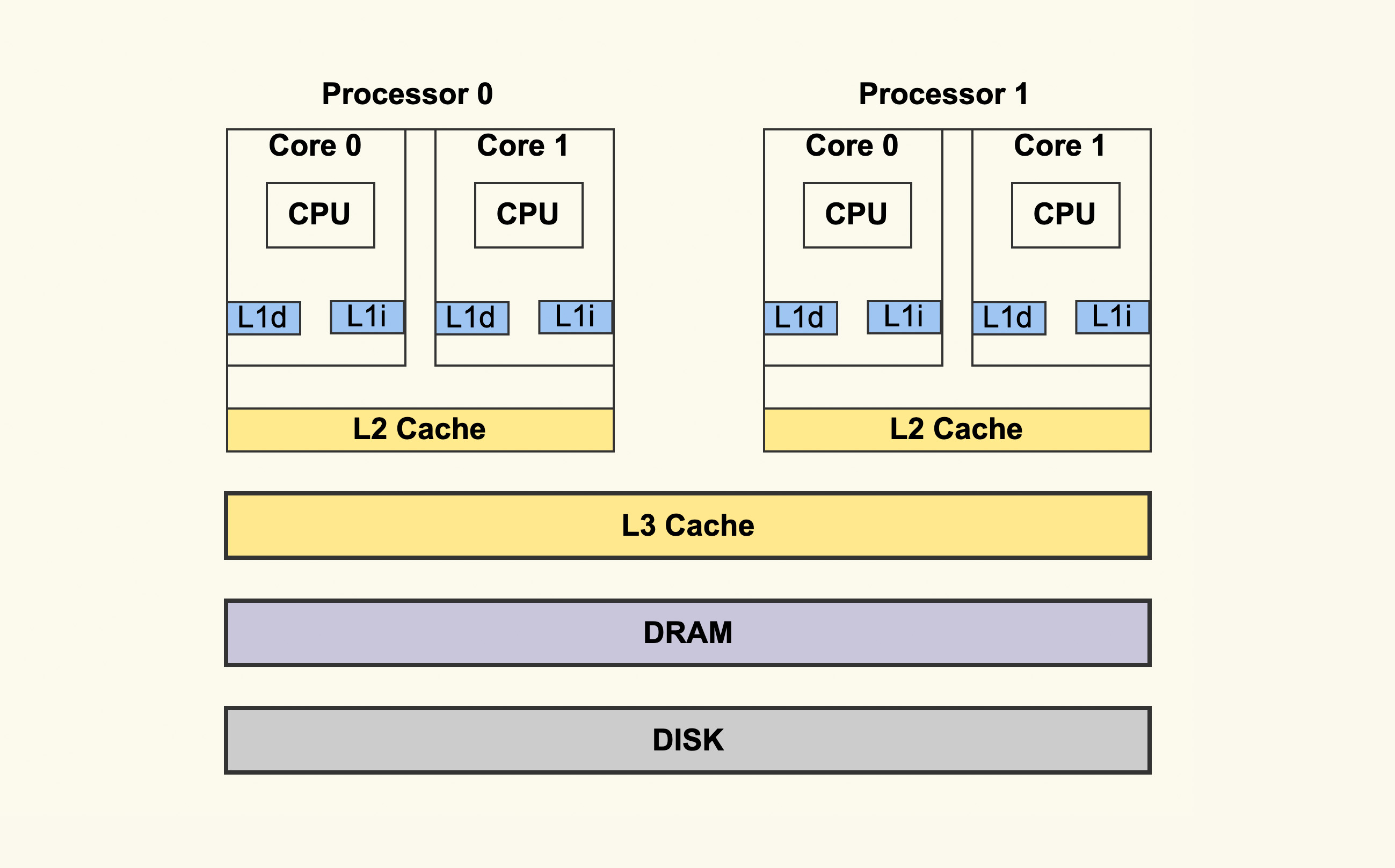
- 一个实体CPU一般有两个逻辑线程,分别有各自的一级缓存
- 二级缓存是CPU共享的
L1访问延迟0.5ns,L2为10ns,而内存为100ns
cache伪共享问题
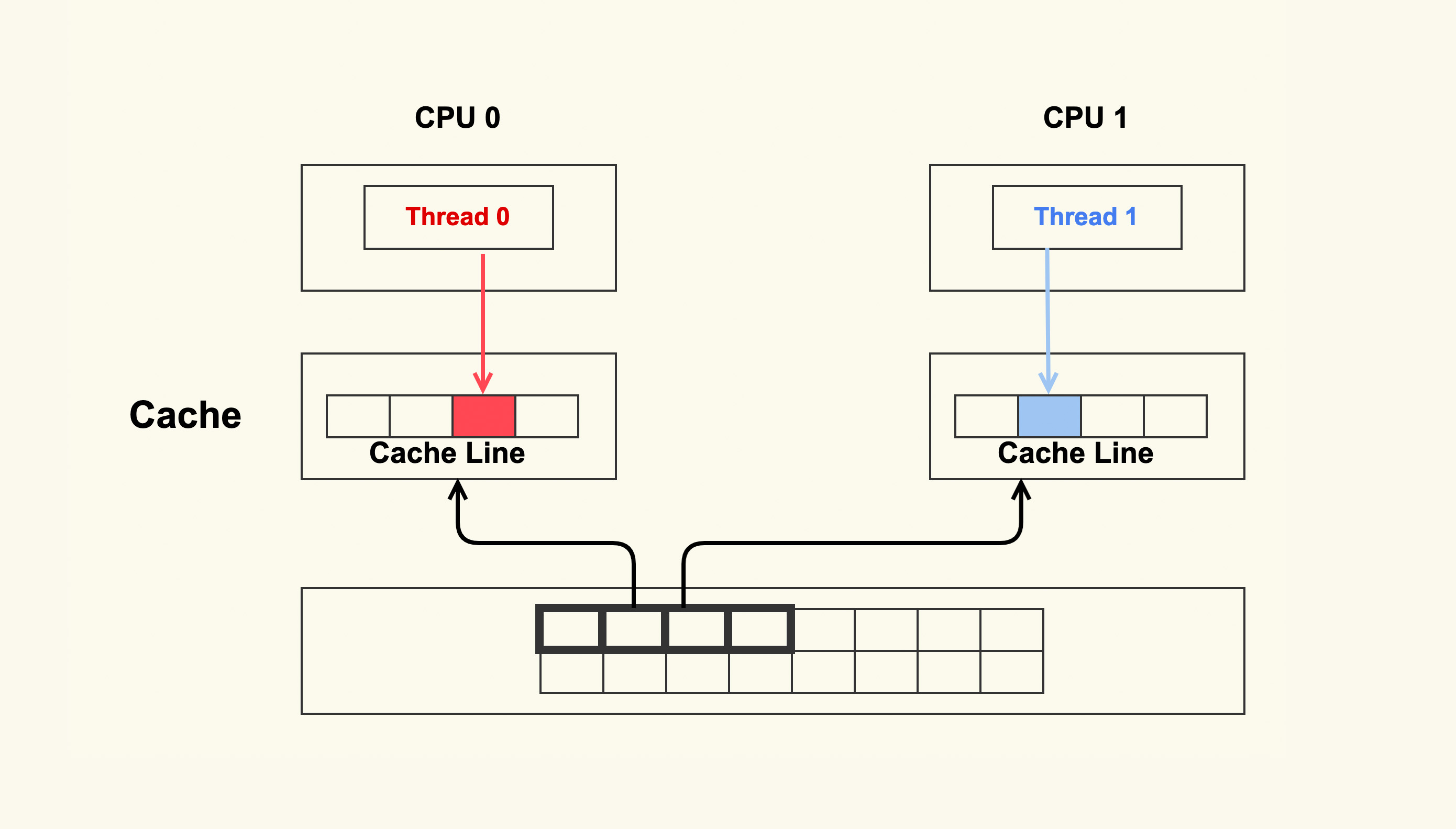
两个CPU运行着不同的线程,同时从内存中读取不同的数据,但是数据是连续的,在同一个cacheline,CPU从内存读取到各自的cache,然后这两个线程分别改写着不同的数据,改写cache的时候会使cacheline失效,所以在一个改写的时候,另一个cpu中的cacheline会失效,另一个内存就会发生cachemiss了,然后就去读取内存,大大降低了性能
perf-c2c可以观察伪共享问题
struct foo {
int a;
int b;
};
a和b在内存上是连续的,就可能为位于一个cacheline
struct foo {
int a;
int b ____cacheline_aligned;
};
a和b强制cacheline对齐
struct foo {
int a:1;
int b:1;
};
定义了两个位域,a和b的地址是一样的,属于地址的不同bit,在两个同时写a和b,后写的会覆盖掉先写的,就需要同步原语,例如atomic操作
每个cpu都有自己的运行队列,linux内核选择任务的时候,按照队列顺序进行选择
任务对延迟比较高的,可以设置为实时任务
$ chrt -f -p 1 1327
进程执行时间由nice值控制
业务是否要使用透明大页
开启sysrq
$ sysctl -w kernel.sysrq = 1
保存快照,可以保存到内存缓冲区
$ echo t > /proc/sysrq-trigger
查看任务快照
$ dmesg
抓取瞬时问题的脚本
#!/bin/sh
while [ 1 ]; do
top -bn2 | grep "Cpu(s)" | tail -1 | awk '{
# $2 is usr, $4 is sys.
if ($2 < 30.0 && $4 > 15.0) {
# save the current usr and sys into a tmp file
while ("date" | getline date) {
split(date, str, " ");
prefix=sprintf("%s_%s_%s_%s", str[2],str[3], str[4], str[5]);
}
sys_usr_file=sprintf("/tmp/%s_info.highsys", prefix);
print $2 > sys_usr_file;
print $4 >> sys_usr_file;
# run sysrq
system("echo t > /proc/sysrq-trigger");
}
}'
sleep 1m
done
调用do_huge_pmd_anonymous_page申请THP的时候,因为没有连续的2M内存空间,触发了direct compaction内存规整
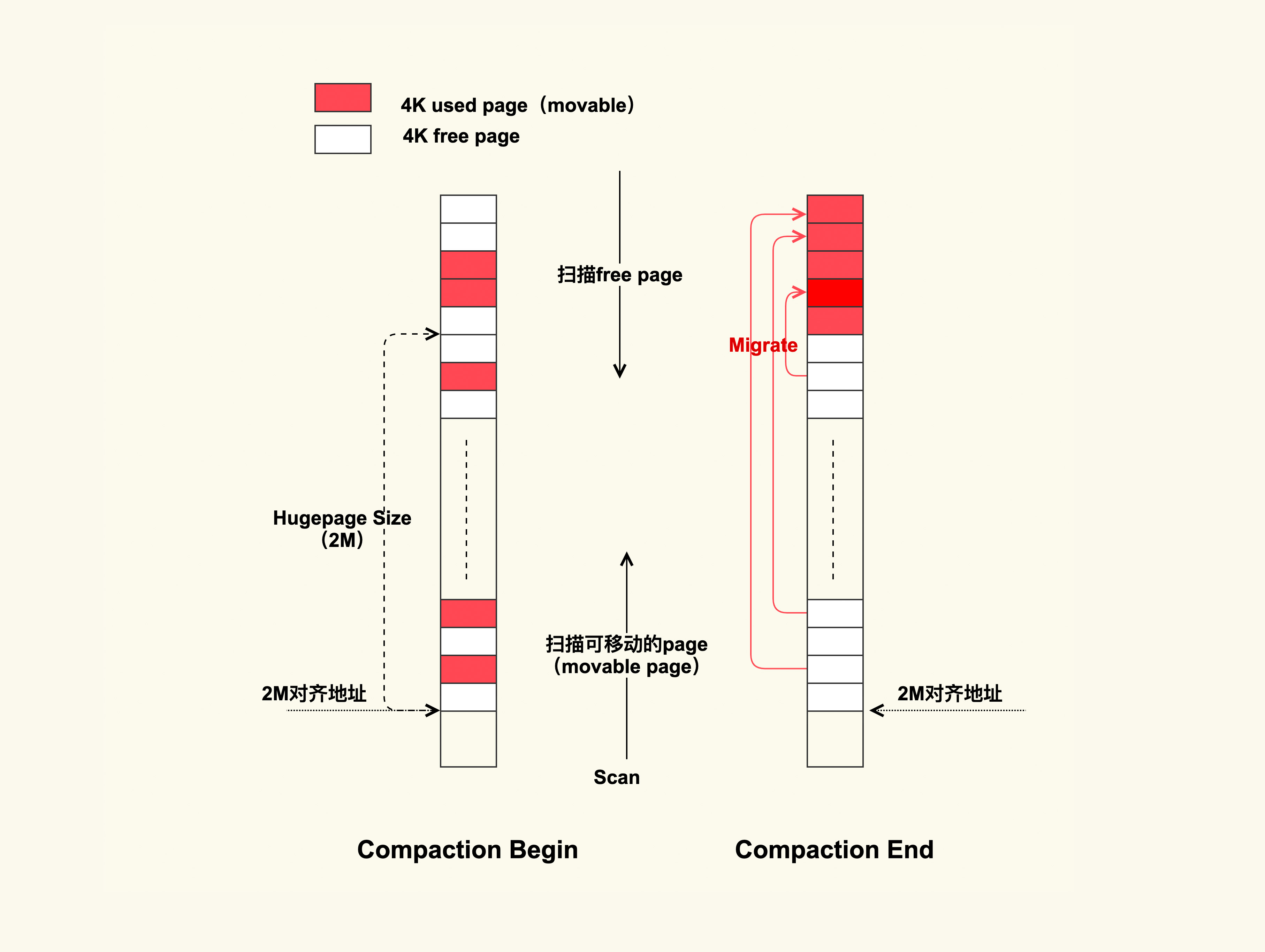
扫描内存进行迁移,然后再给THP申请
关闭THP
$ echo never > /sys/kernel/mm/transparent_hugepage/enabled
THP适合业务的数据局部性,业务的热点数据都聚合在一起
- 不要将
/sys/kernel/mm/transparent_hugepage/enabled配置为always,你可以将它配置为 madvise。如果你不清楚该如何来配置,那就将它配置为never - 如果你想要用THP优化业务,最好可以让业务以madvise的方式来使用大页,即通过修改业务代码来指定特定数据使用 THP,因为业务更熟悉自己的数据流
查看THP
$ grep -i HugePages /proc/meminfo
AnonHugePages: 0 kB
ShmemHugePages: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
网络吞吐量高的业务是否需要开启网卡特性
观测软中断
/sys/kernel/debug/tracing/events/irq/softirq_entry
/sys/kernel/debug/tracing/events/irq/softirq_exit
为了避免软中断太过频繁,进程无法获得CPU的情况,内核引入了ksoftirqd,如果短时间内无法被处理完,内核会唤醒ksoftirqd来处理软中断,ksoftirqd和普通进程的优先级一样。不过如果ksoftirqd获取不到CPU,会导致软中断延迟很大
ksoftirqd的nice值为0
$ ps -eo "pid,comm,ni" | grep softirqd
9 ksoftirqd/0 0
16 ksoftirqd/1 0
21 ksoftirqd/2 0
26 ksoftirqd/3 0
使用了RPS之后,每个CPU的软中断时间会增多
$ mpstat -P ALL 1
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
Average: all 66.21 0.00 17.73 0.00 0.00 11.15 0.00 0.00 0.00 4.91
Average: 0 68.17 0.00 18.33 0.00 0.00 7.67 0.00 0.00 0.00 5.83
Average: 1 60.57 0.00 15.81 0.00 0.00 20.80 0.00 0.00 0.00 2.83
Average: 2 69.95 0.00 19.20 0.00 0.00 7.01 0.00 0.00 0.00 3.84
Average: 3 66.39 0.00 17.64 0.00 0.00 8.99 0.00 0.00 0.00 6.99
但是会增大CPU的负担
如何分析CPU飙高
strace追踪多线程
$ strace -T -tt -ff -p pid -o strace.out
strace原理
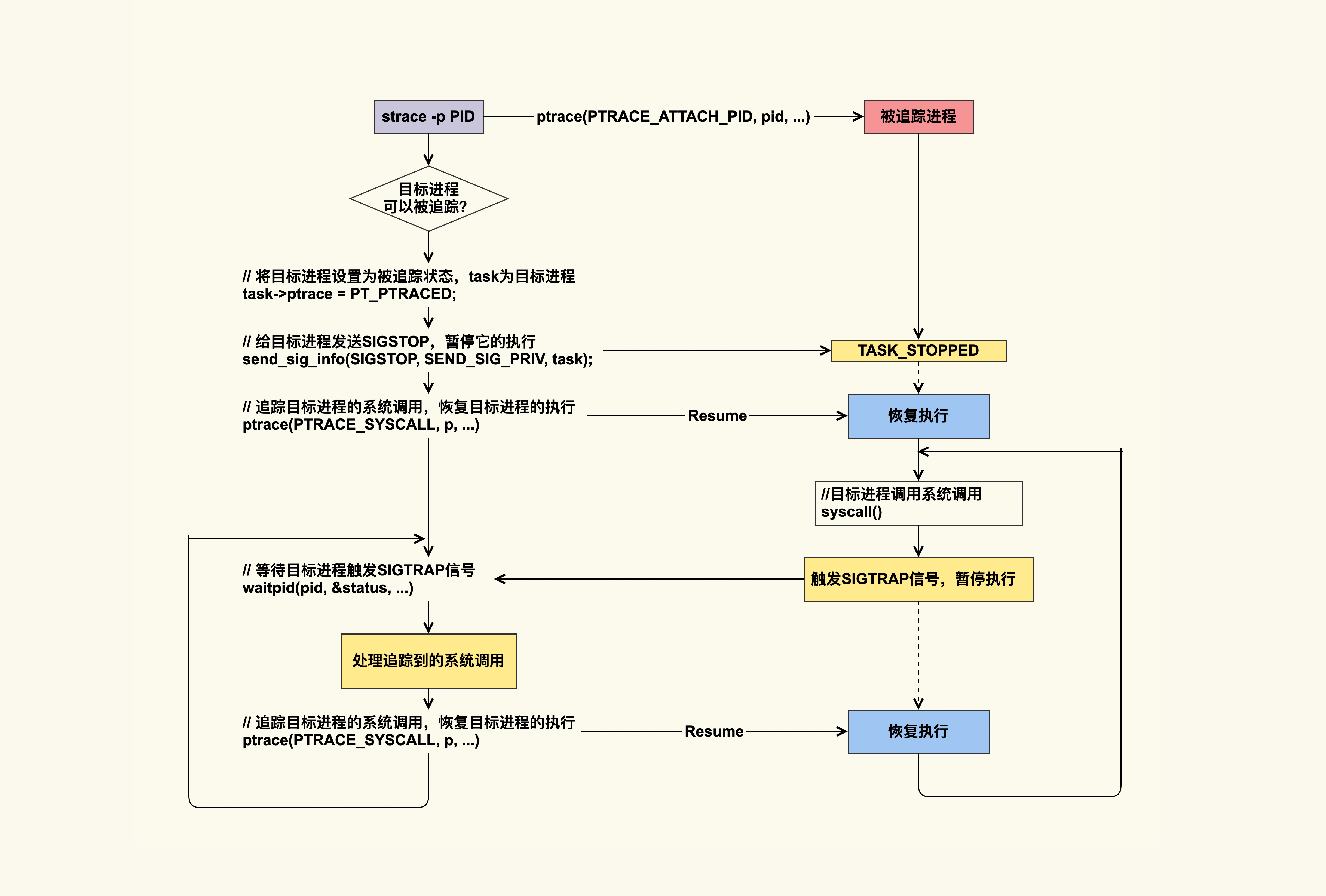
strace可以attach到目标进程,通过ptrace的系统调用实现,ptrace的PTRACE_SYSCALL会去追踪目标进程的系统调用,目标进程每次进入syscall,都会产生SIGTRAP信号并且暂停执行,strace去处理系统调用,处理完成恢复目标进程的执行,直到下一个系统调用
ftrace的function_graph追踪内核函数
# 首先设置要追踪的函数
$ echo ksys_pread64 > /sys/kernel/debug/tracing/set_graph_function
# 其次设置要追踪的线程的pid,如果有多个线程,那需要将每个线程都逐个写入
$ echo 6577 > /sys/kernel/debug/tracing/set_ftrace_pid
$ echo 6589 >> /sys/kernel/debug/tracing/set_ftrace_pid
# 将function_graph设置为当前的tracer,来追踪函数调用情况
$ echo function_graph > /sys/kernel/debug/tracing/current_trace
通过/sys/kernel/debug/tracing/trace_pipe获取结果
限制离线业务的PageCache大小
各种功能
tracepiont,kprobe和ePBF

