

极客时间——Linux内核技术实战课:page cache管理问题
目录:
page cache管理问题
用数据观测page cache
page cache是内核管理的内存
$ cat /proc/meminfo
...
Buffers: 1224 kB
Cached: 111472 kB
SwapCached: 36364 kB
Active: 6224232 kB
Inactive: 979432 kB
Active(anon): 6173036 kB
Inactive(anon): 927932 kB
Active(file): 51196 kB
Inactive(file): 51500 kB
...
Shmem: 10000 kB
...
SReclaimable: 43532 kB
...
有着以下的公式
Buffers + Cached + SwapCached = Active(file) + Inactive(file) + Shmem + SwapCached
这里Active(file)和nactive(file)就是pagecache,文件对应的内存页。平时使用mmap()内存映射方式和bufferIO消耗的就是这部分
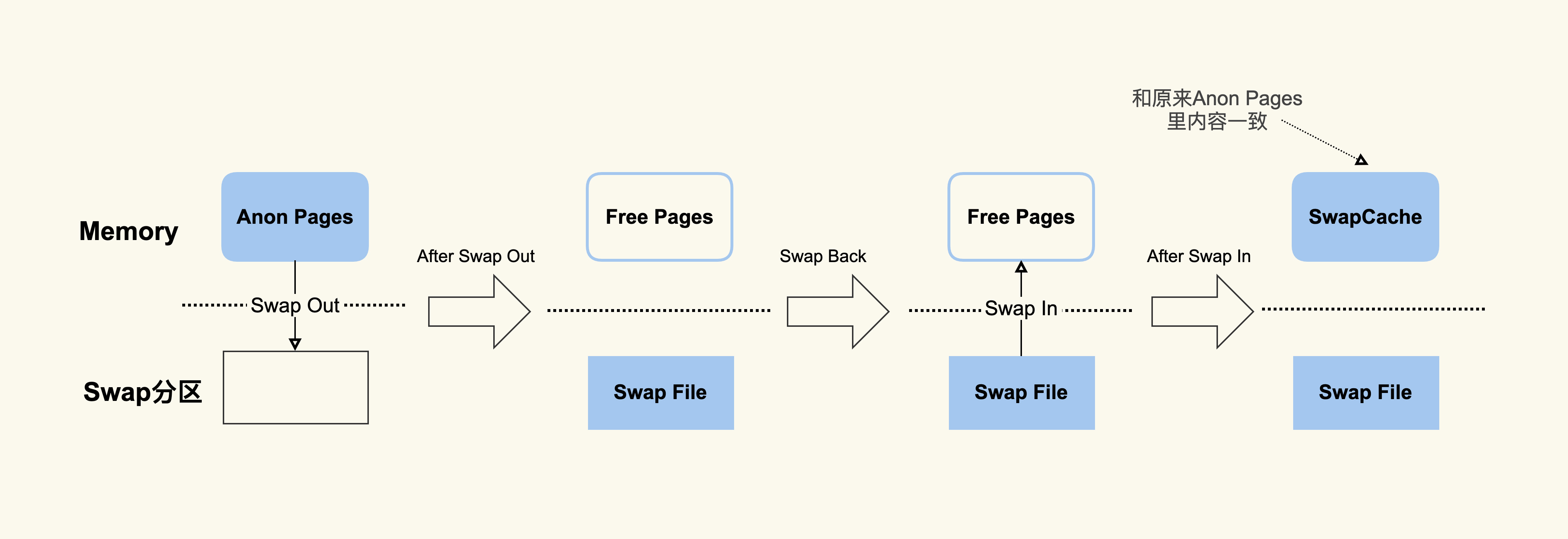
SwapCached是打开了swap分区之后,将Active(file)和nactive(file)中的匿名页换到swap中,再读到内存的时候分配的内存,因为swapfile还在,所以可以认为是pagecache
原理为
free中内存读取的/proc/meminfo
buff/cache = Buffers + Cached + SReclaimable
buff/cache都是可回收的内存
SReclaimable是内核内存中dentry和inode
在应用本身RSS使用不大的情况,系统内存使用过高,就可能是Shmem(共享内存)消耗太多
如果不使用内核的cache就需要两种方式
- 维护cache
- 调用DirectI/O绕过pagecache
绕过pagecache性能会很差
$ ddif=/dev/zeroof=/home/yafang/test/dd.outbs=4096count=((1024*256))
# 清空Page Cache,先sync脏页再清空
$ sync && echo 3 > /proc/sys/vm/drop_caches
# 第一次读取
$ time cat /home/yafang/test/dd.out &> /dev/null
real 0m5.733s
user 0m0.003s
sys 0m0.213s
# 再次读取
$ time cat /home/yafang/test/dd.out &> /dev/null
real 0m0.132s
user 0m0.001s
sys 0m0.130s
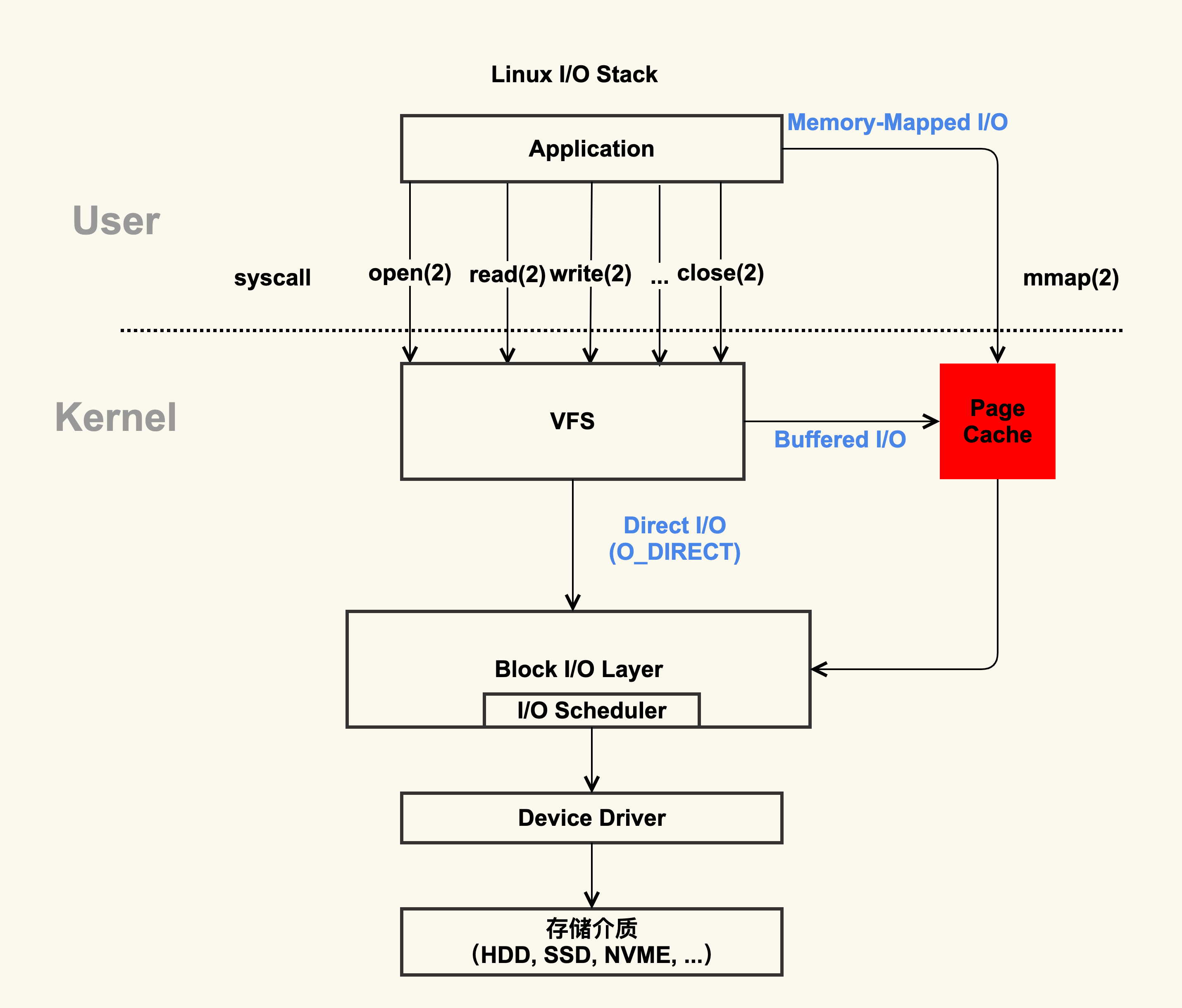
page cache的产生和释放
page的产生方式由两种
- Buffered I/O(标准 I/O)
- Memory-Mapped I/O(存储映射 I/O)
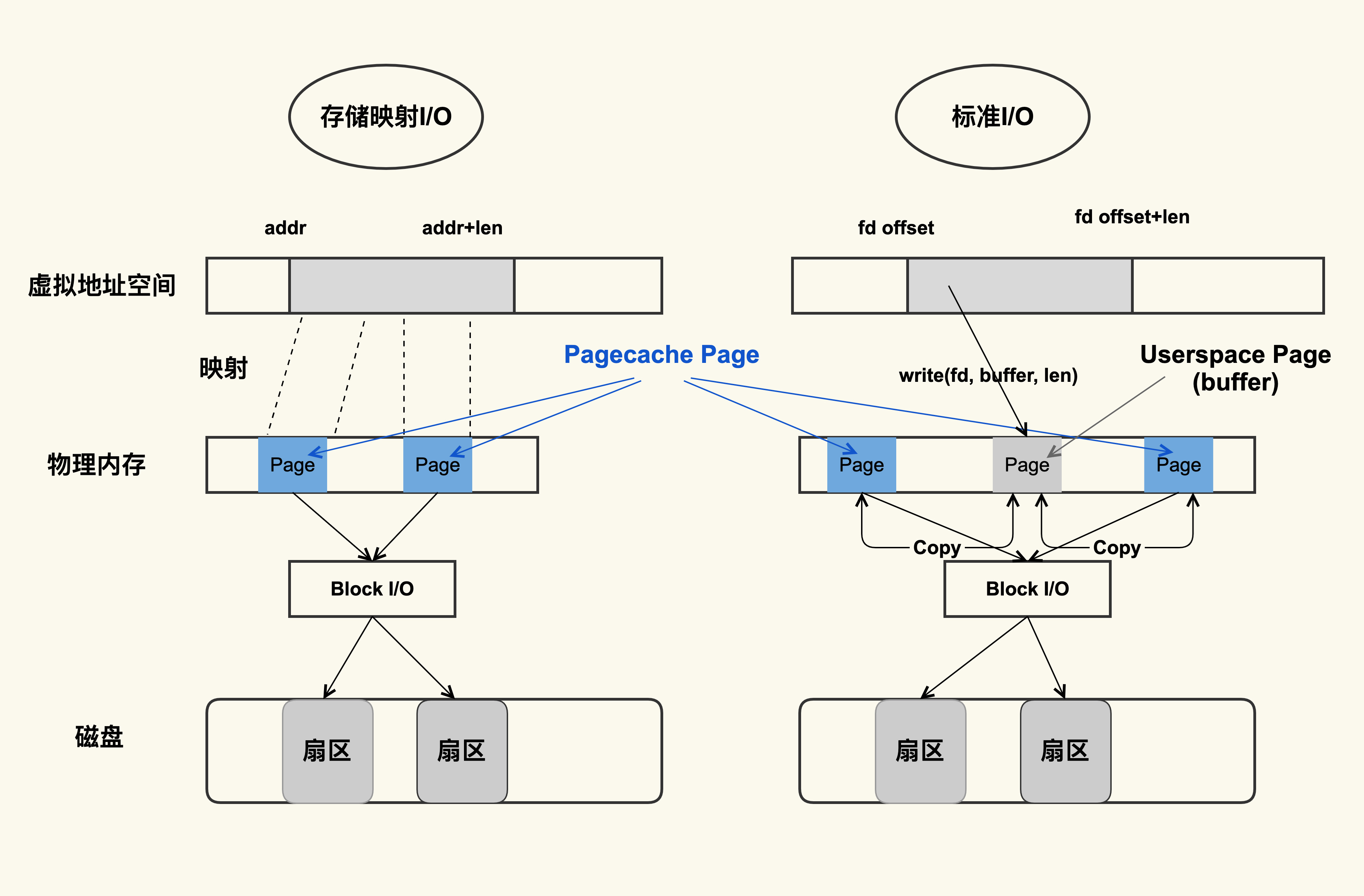
标准IO在调用write的时候写入用户缓冲区(userspace page),然后将用户缓冲区的数据拷贝到内核缓冲区(page cache),read的时候相反,是由内核缓冲区读取到内核缓冲区
存储IO直接将pagecache映射到用户的地址空间,直接读写pagecache
存储IO比标准IO的效率要高,因为少了拷贝的过程
标准IO的流程
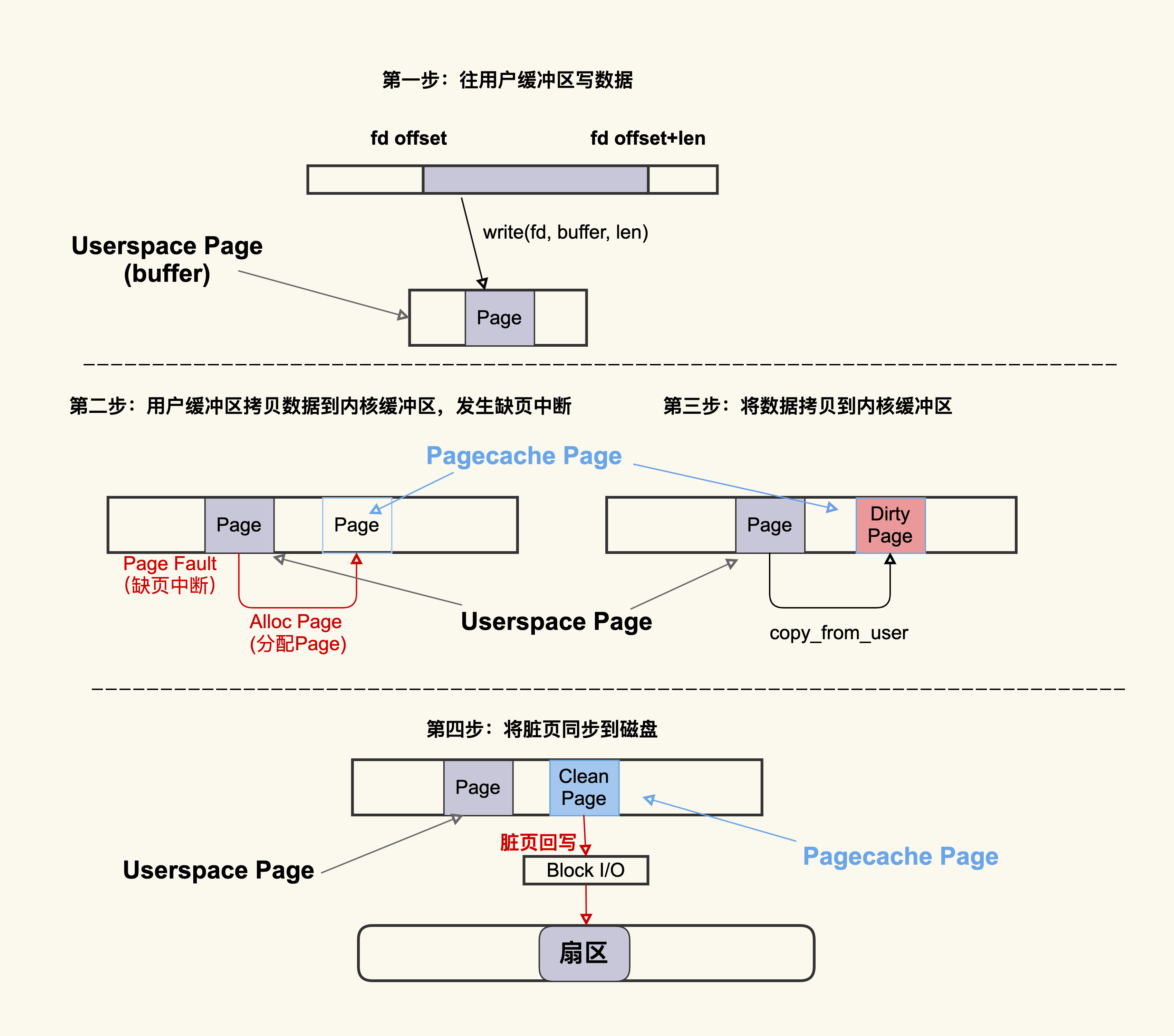
查看脏页,nr_dirty为积压的脏页,nr_writeback为正在回写到磁盘的脏页
$ cat /proc/vmstat | egrep "dirty|writeback"
nr_dirty 40
nr_writeback 2
page cache回收流程

回收主要有两种
- 直接回收
- 后台回收
查看回收情况
$ sar -B 1
02:14:01 PM pgpgin/s pgpgout/s fault/s majflt/s pgfree/s pgscank/s pgscand/s pgsteal/s %vmeff
02:14:01 PM 0.14 841.53 106745.40 0.00 41936.13 0.00 0.00 0.00 0.00
02:15:01 PM 5.84 840.97 86713.56 0.00 43612.15 717.81 0.00 717.66 99.98
02:16:01 PM 95.02 816.53 100707.84 0.13 46525.81 3557.90 0.00 3556.14 99.95
02:17:01 PM 10.56 901.38 122726.31 0.27 54936.13 8791.40 0.00 8790.17 99.99
02:18:01 PM 108.14 306.69 96519.75 1.15 67410.50 14315.98 31.48 14319.38 99.80
02:19:01 PM 5.97 489.67 88026.03 0.18 48526.07 1061.53 0.00 1061.42 99.99
- pgscank/s: kswapd(后台回收线程) 每秒扫描的page个数
- pgscand/s: 应用程序在内存申请过程中每秒直接扫描的page个数
- pgsteal/s: 扫描的page中每秒被回收的个数
- %vmeff: pgsteal/(pgscank+pgscand), 回收效率,越接近100说明系统越安全,越接近0说明系统内存压力越大。
page cache难以回收产生的load飙高
内存在回收的时候,首先开始异步的内存回收,不会引起进程的延迟,如果后台异步回收的速度赶不上内存的申请速度,就会开始同步阻塞回收,导致延迟
内存回收水位一般128G配置4G即可
vm.min_free_kbytes = 4194304
也可以渐进的调整,sar -B中pgscand是否还有不为0的情况,如果有就再调大
在系统中可能会存在网络文件系统和SSD,当回写网络文件系统的时候就会有脏页堆积的问题
page cache回收的性能问题
inode是内存中对磁盘文件的索引,结合pageindex偏移量查找具体的page
- 如果page在,证明文件被读取到内存了
- 如果page不在就需要去读取文件
drop_cache会释放不同的inode,用户数据page cache和内核数据slab
- 1 释放page cache
- 2 释放slab
- 3 释放两者
但是在释放slab的时候也会释放page cache
/proc/vmstat记录的释放的事件
$ grep drop /proc/vmstat
drop_pagecache 3
drop_slab 2
pagecache释放了3次,slab释放了2次
$ grep inodesteal /proc/vmstat
pginodesteal 114341
kswapd_inodesteal 1291853
- kswapd_inodesteal是内核kswapd线程回收的pagecache数
- pginodesteal 其他的进程回收是的pagecache数
应用程序可以通过mlock(2)来保护数据不被回收和drop,madvise(2)告诉内核主动释放,例如日志
unmlock可以取消保护,进程退出也是回收这部分
查看被锁的pagecache
$ egrep "Unevictable|Mlocked" /proc/meminfo
Unevictable: 1000000 kB
Mlocked: 1000000 kB
memory的cgroup提供了
- memory.max这是指 memory cgroup 内的进程最多能够分配的内存,如果不设置的话,就默认不做内存大小的限制。
- memory.high如果设置了这一项,当 memory cgroup 内进程的内存使用量超过了该值后就会立即被回收掉,所以这一项的目的是为了尽快的回收掉不活跃的 Page Cache。
- memory.low这一项是用来保护重要数据的,当 memory cgroup 内进程的内存使用量低于了该值后,在内存紧张触发回收后就会先去回收不属于该 memory cgroup 的 Page Cache,等到其他的 Page Cache 都被回收掉后再来回收这些 Page Cache。
- memory.min这一项同样是用来保护重要数据的,只不过与 memoy.low 有所不同的是,当 memory cgroup 内进程的内存使用量低于该值后,即使其他不在该 memory cgroup 内的 Page Cache 都被回收完了也不会去回收这些 Page Cache,可以理解为这是用来保护最高优先级的数据的。
任务进程可以放到一个单独的memory cgroup
判断问题是否由page cache产生
$ sar -r 1
07:30:01 PM kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
09:20:01 PM 5681588 2137312 27.34 0 1807432 193016 2.47 534416 1310876 4
09:30:01 PM 5677564 2141336 27.39 0 1807500 204084 2.61 539192 1310884 20
09:40:01 PM 5679516 2139384 27.36 0 1807508 196696 2.52 536528 1310888 20
09:50:01 PM 5679548 2139352 27.36 0 1807516 196624 2.51 536152 1310892 24
查看系统中脏页的数量
vm.dirty_background_bytes = 0
vm.dirty_background_ratio = 10
vm.dirty_bytes = 0
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 20
调整参数有利有弊,调大这些值会导致脏页的积压,但是同时也可能减少了I/O的次数,从而提升单次刷盘的效率;调小这些值可以减少脏页的积压,但是同时也增加了I/O的次数,降低了I/O的效率
内存问题的分析
sar -B来分析分页信息 (Paging statistics)
sar -r来分析内存使用情况统计 (Memory utilization statistics)
关注一些常见指标

添加tcacepoint
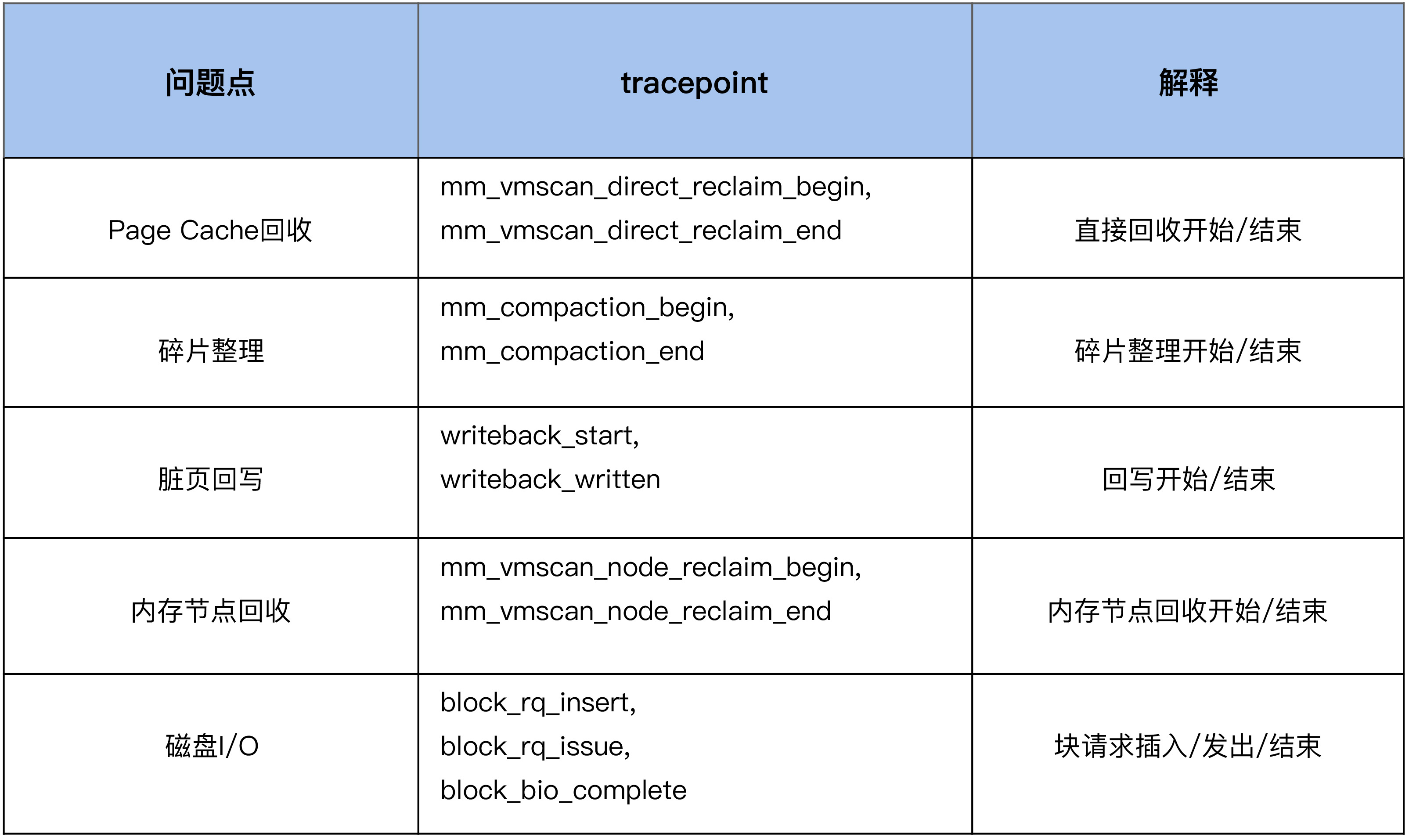
#首先来使能compcation相关的一些tracepoing
$ echo 1 >
/sys/kernel/debug/tracing/events/compaction/mm_compaction_begin/enable
$ echo 1 >
/sys/kernel/debug/tracing/events/compaction/mm_compaction_end/enable
#然后来读取信息,当compaction事件触发后就会有信息输出
$ cat /sys/kernel/debug/tracing/trace_pipe
<...>-49355 [037] .... 1578020.975159: mm_compaction_begin:
zone_start=0x2080000 migrate_pfn=0x2080000 free_pfn=0x3fe5800
zone_end=0x4080000, mode=async
<...>-49355 [037] .N.. 1578020.992136: mm_compaction_end:
zone_start=0x2080000 migrate_pfn=0x208f420 free_pfn=0x3f4b720
zone_end=0x4080000, mode=async status=contended
49355这个进程触发了compaction,begin和end这两个tracepoint触发的时间戳相减,就可以得到compaction给业务带来的延迟,我们可以计算出这一次的延迟为 17ms。

