

极客时间——Linux内核技术实战课:TCP重传问题
目录:
TCP重传问题
TCP连接和断开受那些配置影响
在连接建立的三次握手过程
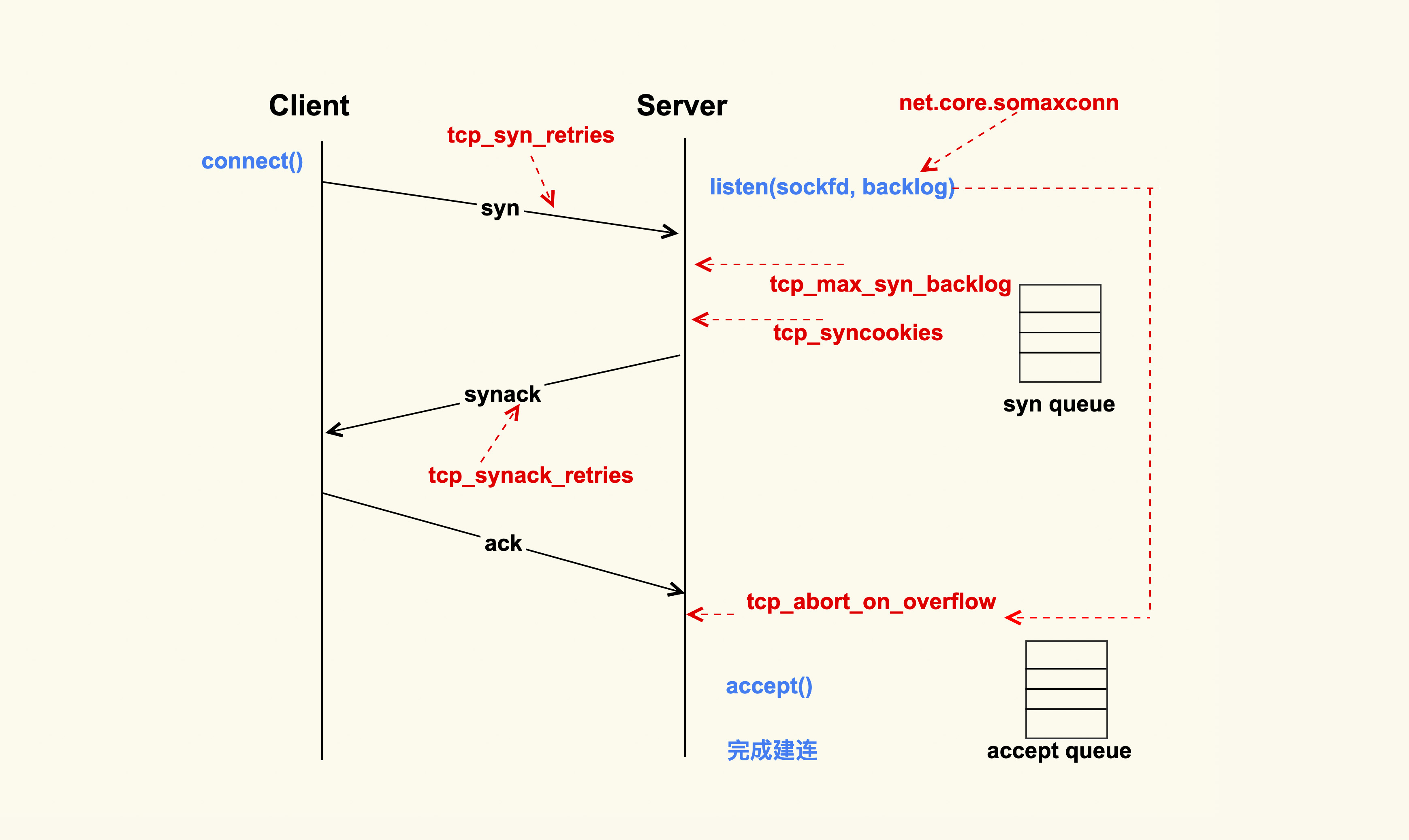
Client请求Server发送SYN包的时候,SYN如果在传输过程中丢失,Client就会触发重传,重传的间隔会依次的增大
- 重传次数
tcp_syn_retries
对于多次重传,例如3次重试,发送SYN之后,等待1s后进行第一次重试,第一次重试后等待2s进行第二次重试,第二次重试后等待4s进行第三次重试,超过8s没响应,Client的connect方法会返回TIMEOUT,整个过程为(1+2+4+8)s
默认值为6,也就是(1+2+4+8+16+32+64)=127s,服务器内部可以调小为
net.ipv4.tcp_syn_retries = 2
握手的超时时间也可以从1s调整为100ms
Server端接收到SYN包之后,会建立一个半连接并将半连接加入到半连接队列,即syn queue
- 半连接队列长度
tcp_max_syn_backlog
超过半连接队列之后的SYN数据包会被丢弃,可以适当调大
net.ipv4.tcp_max_syn_backlog = 16384
对于SYN连接,可以会有发送SYN攻击,Server端接收到SYN包会根据这个包计算一个cookies值,通过SYN+ACK包发回去,对于正常的连接,会在ACK包中带着cookies回来的,验证合法性再创建TCP连接
net.ipv4.tcp_syncookies = 1
SYN+ACK的重传策略等同于SYN的重试
net.ipv4.tcp_synack_retries = 2
Server获取到ACK包之后会建立全连接,全连接的长度是由listen(sockfd, backlog)的backlog参数控制,backlog的最大值为somaxconn,默认在128(5.4内核为4096),建议调大
net.core.somaxconn = 16384
超过这个值之后,新的全连接会被丢弃,可以发送reset给client,这样client就不会重试了,默认情况下不会发送reset给client,让client进行重试
net.ipv4.tcp_abort_on_overflow = 0
一般全连接队列超了,是因为大量连接Server端来不及进行accept()导致的,所以重试后一般可以连接
然后连接进入ESTABLISHED
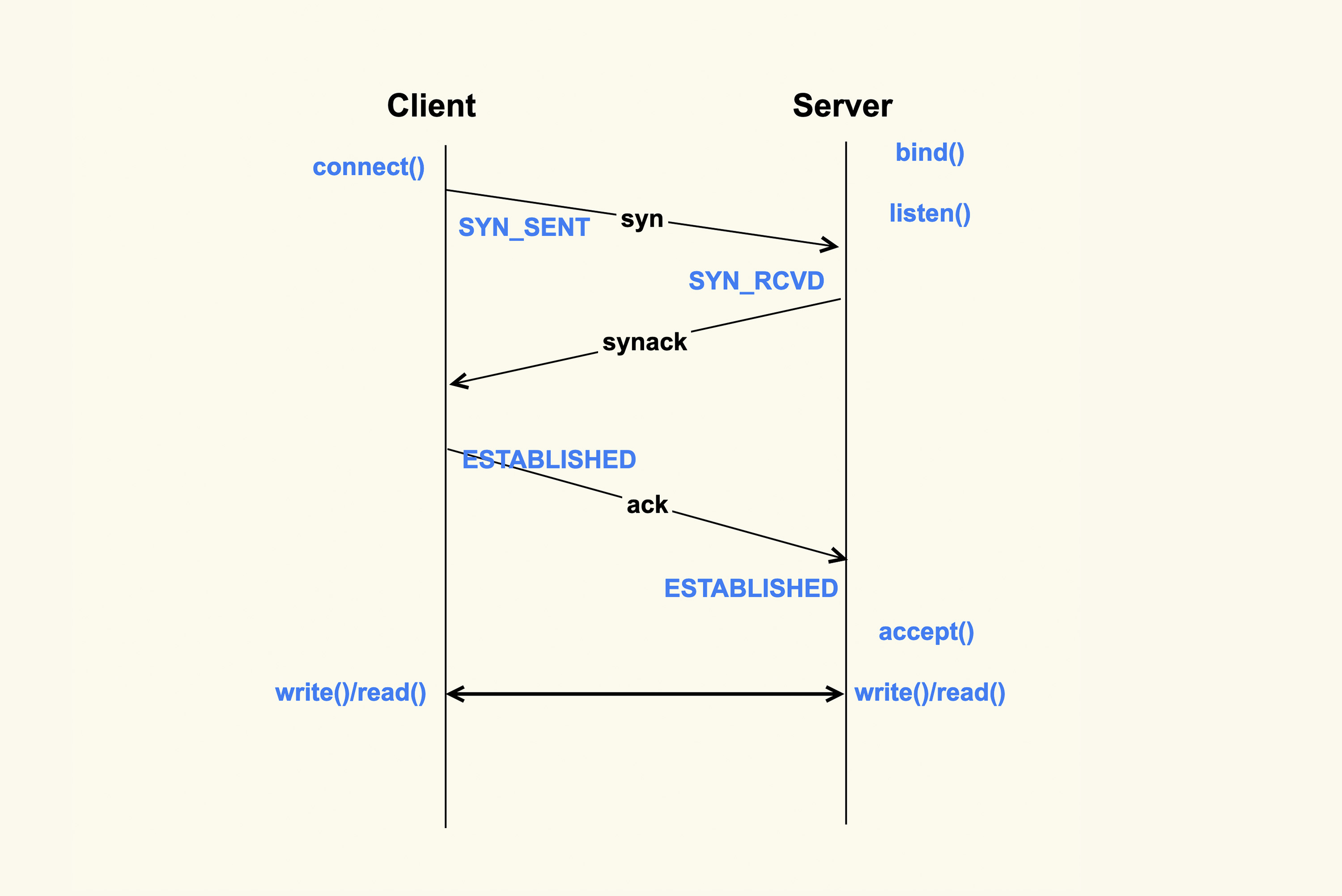
在四次挥手的过程中
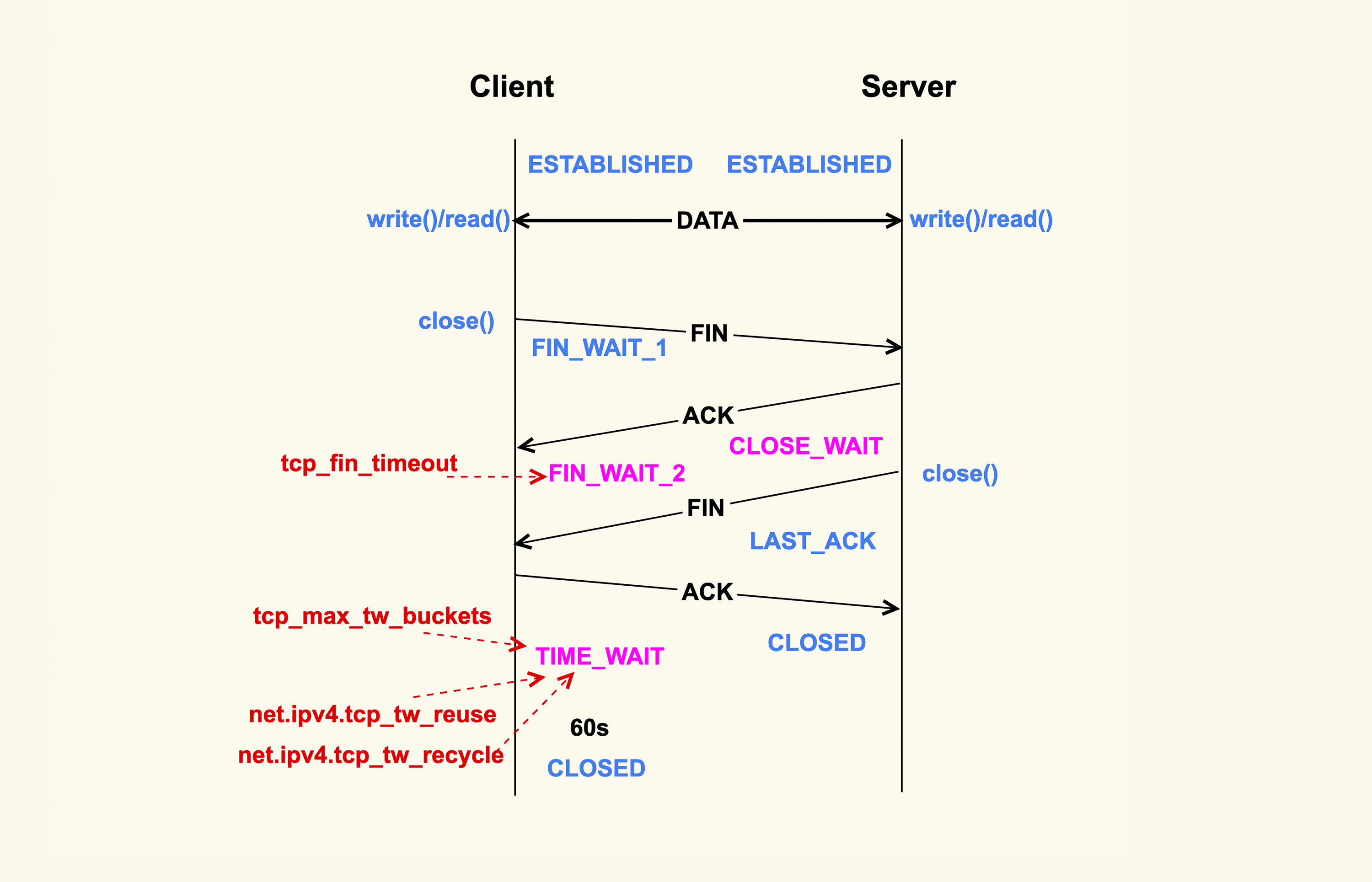
通过close方法关闭连接,优先调用close方法的一侧为主动关闭,发送FIN包,接收到FIN包调用close的一侧为被动关闭,会发送ACK包和FIN包
主动关闭侧,接收到ACK包进入了FIN_WAIT_2,如果收不到ACK的数据包,就会处于这个状态一直消耗系统资源,为了防止这种情况设置了超时时间tcp_fin_timeout,超过之后会直接释放资源
默认情况下是60s,而在内网环境可以为2s
net.ipv4.tcp_fin_timeout = 2
在主动关闭侧,发送了ACK包之后,会进入TIME_WAIT状态,状态维持时间为tcp_timeout_len,默认为60s,也可以考虑调小
tcp_timeout_len =
系统也可以设置TIME_WAIT状态的数量,因为内网很少存在FIN包的异常,减少资源的浪费,可以减少这个值
net.ipv4.tcp_max_tw_buckets = 10000
当Client关闭与Server连接的时候,和可能和Server再次建立连接,而TCP的端口只有65535个,就需要重新复用一些TIMW_WAIT的端口进行连接
net.ipv4.tcp_tw_reuse = 1
还有参数用于控制TIME_WAIT,但是在NAT环境下会有丢包的问题,建议关闭
net.ipv4.tcp_tw_recycle = 0
TCP收发包受那些配置影响
系统收发包参考
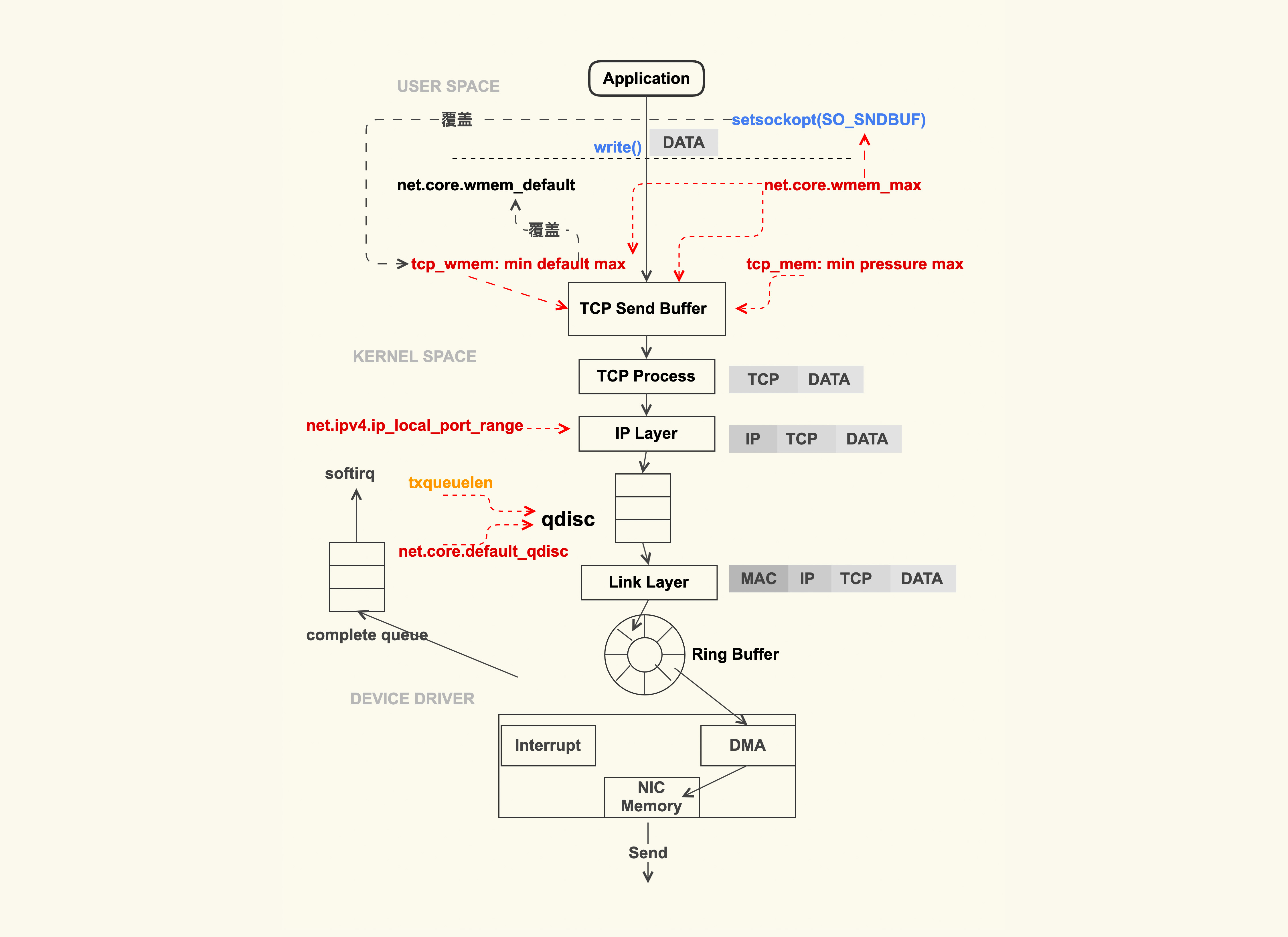
应用程序调用write(2)和read(2)进行发包,系统调用会将数据包从用户的缓冲区拷贝到tcp的sendbuffer,发往tcp发送缓冲区的大小配置,针对单个TCP连接,单位为byte
net.ipv4.tcp_wmem = 8192 65536 16777216
三个值默认是min、default、max,sendbuffer会在min和max之间调整,初始大小为default
net.ipv4.tcp_wmem的最大值不能超过net.core.wmem_max,如果超过了使用net.core.wmem_max为最大值
应用程序通过setsockopt(2)的SO_SNDBUF可以设置固定的缓冲区大小,但是也不能超过net.core.wmem_max
eBPF技术可以通过eBPF来设置SO_SNDBUF和SO_RCVBUF
所有tcp连接的总内存使用量
net.ipv4.tcp_mem = 8388608 12582912 16777216
这个单位是page,4k
4.16+内核之后有tcp限制而无法发包或者抖动,开启tracepiont
$ echo 1 > /sys/kernel/debug/tracing/events/sock/sock_exceed_buf_limit/enable
$ cat /sys/kernel/debug/tracing/trace_pipe
如果有日志输出说明需要调高限制
tcp层完成之后是IP层,需要设置与其他服务器建立连接的本地端口范围
net.ipv4.ip_local_port_range = 1024 65535
为了进行TCP/IP的数据流进行控制,内核在IP层实现了qdisc排队规则,可以通过ifconfig进行查看
$ ip -s -s link ls dev eth0
…
TX: bytes packets errors dropped carrier collsns3263284 25060 0 0 0 0
如果dropped不为0,可能是txqueuelen太小了,需要进行增大
$ ifconfig eth0 txqueuelen 2000
或
$ ip link set eth0 txqueuelen 2000
linux默认使用的qdisc为pfifo_fast(先入先出),通常不需要调整,如果需要改善拥堵情况
net.core.default_qdisc = fq
通过IP层之后,数据包进入网卡进行发送
接收数据包的过程和发送相反
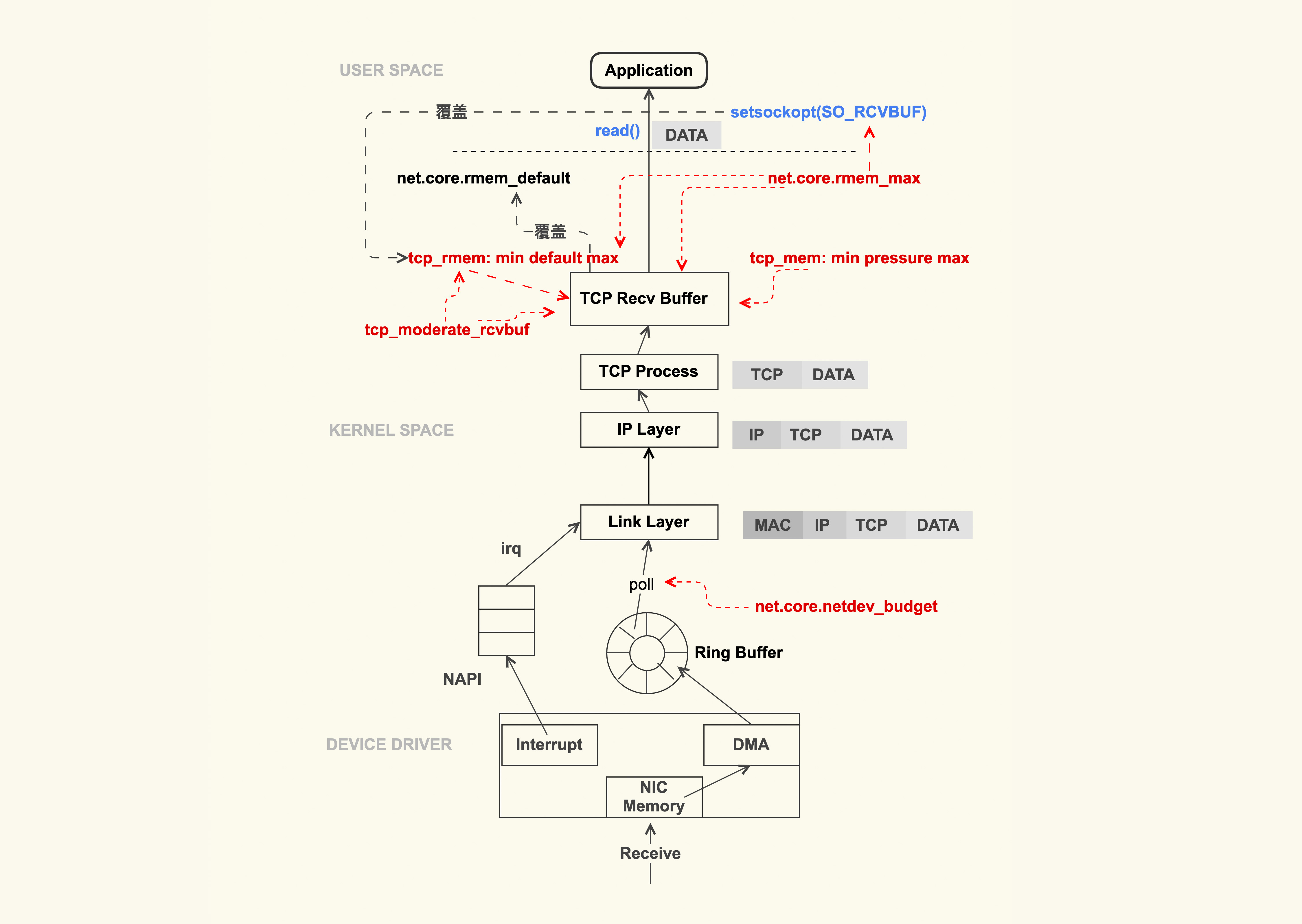
网卡收到数据包之后,触发IRQ中断告诉CPU接收数据包,CPU可以合并轮序数据包的批处理方式,默认是300
net.core.netdev_budget = 600
但是也会造成一次性处理多个数据包,poll的时间会增加,也会增大一些数据包的延迟
想发送相反的也有TCP的接收缓冲区
net.ipv4.tcp_rmem = 8192 87380 16777216
但是这个动态调整可以进行关闭
net.ipv4.tcp_moderate_rcvbuf = 1
当然也可以通过SO_RCVBUF来进行固定
最大值也受参数影响
net.core.rmem_max = 16777216
TCP拥塞控制
慢启动的初始发送到数据包由init_cwnd拥塞窗口控制,2.6.38之前默认为3,之后默认为10,配置为TCP_INIT_CWND,对于短连接,慢启动的数据包就完成数据的传输了,如果拥塞窗口过大也会增加重传概率
拥塞避免阶段,cwnd不是成倍增加,而是一个RTT增加1的缓慢增加。
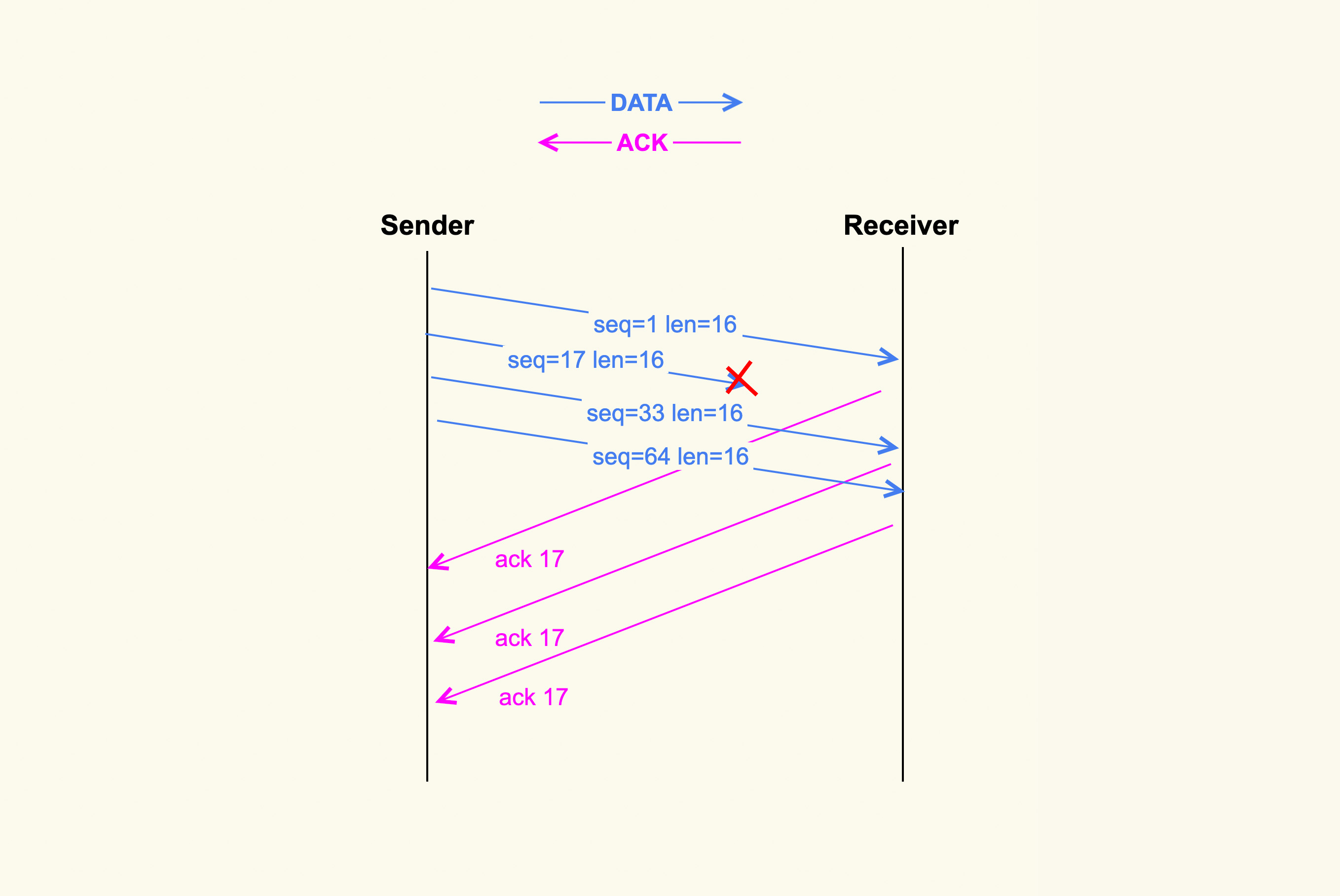
Client一次性发送了4个有序的TCP数据包,第二个数据包在传输的过程中被丢弃了,第三和第四个数据包就是乱序报文,会加入接收端的乱序队列,对收到的每个部分都会返回ACK17的数据包,在Client收到3个ACK17之后就会发现有丢包,会进入快速重传的阶段
快速重传和快速恢复一起工作,这种情况网络并没有拥塞,只是根据三个ACK判断的丢包,所以拥塞窗口不需要恢复到初始值,直接绕过重传延时进行快速重传,在3.6版本之后内核都支持这个特性
还有就是超时重传就是超过重传延时(RTO)没有收到它的ACK的包,判断网络拥塞了,将cwnd调整为为初始值,再次慢启动。在内网环境RTO可以从3s改小到1s,甚至更小,3.1版本内核开始支持
在生产环境可以strace跟踪进程,如果进程阻塞在send()之类的包上,用tcpdump去抓包看是否有达到RTO时间再次进行重传的现象
单个连接可以通过使用SO_SNDTIMEO来设置发送超时时间
ret = setsockopt(sockfd, SOL_SOCKET, SO_SNDTIMEO, &timeout, len);
查看tcp连接的cwnd大小
$ ss -nipt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 36 172.23.245.7:22 172.30.16.162:60490
users:(("sshd",pid=19256,fd=3))
cubic wscale:5,7 rto:272 rtt:71.53/1.068 ato:40 mss:1248 rcvmss:1248 advmss:1448 cwnd:10 bytes_acked:19591 bytes_received:2817 segs_out:64 segs_in:80 data_segs_out:57 data_segs_in:28 send 1.4Mbps lastsnd:6 lastrcv:6 lastack:6 pacing_rate 2.8Mbps delivery_rate 1.5Mbps app_limited busy:2016ms unacked:1 rcv_space:14600 minrtt:69.402
这个ssh的连接cwnd是10
追踪拥塞窗口可以使用
/sys/kernel/debug/tracing/events/tcp/tcp_probe
接收方也有拥塞窗口,为rwnd

Server接收到数据会返回一个ack,将rwnd写入到tcp的win字段,Client根据Server的rwnd和cwnd对比,用最小值机型数据发送
win的字段默认是16bit,最大只有65535,如果需要扩展需要
net.ipv4.tcp_window_scaling = 1
TCP端到端延迟变大问题
略
TCP重传问题
重传率通过/proc/net/snmp分析
| 指标 | 含义 |
|---|---|
| ActiveOpens | 主动打开tcp连接数量 |
| PassiveOpens | 被动打开tcp连接数量 |
| InSegs | 收到的tcp报文数 |
| OutSegs | 发送的tcp报文数 |
| EstabResets | tcp连接处于established时发生reset |
| AttemptFails | 连接失败的数量 |
| CurrEstab | 当前状态为established的数量 |
| RetransSegs | 重传的报文数量 |
重传率的公式
retrans = (RetransSegs-last RetransSegs) / (OutSegs-last OutSegs) * 100
当出现重传的时候,OutSegs和RetransSegs都会+1
分析tcp重传
$ tcpdump -s 0 -i eth0 -w tcpdumpfile
$ tshark -r tcpdumpfile -R tcp.analysis.retransmission
如果有重传包会有以下显示
3481 20.277303 10.17.130.20 -> 124.74.250.144 TCP 70 [TCP Retransmission] 35993 > https [SYN] Seq=0 Win=14600 Len=0 MSS=1460 SACK_PERM=1 TSval=3231504691 TSecr=0
3659 22.277070 10.17.130.20 -> 124.74.250.144 TCP 70 [TCP Retransmission] 35993 > https [SYN] Seq=0 Win=14600 Len=0 MSS=1460 SACK_PERM=1 TSval=3231506691 TSecr=0
8649 46.539393 58.216.21.165 -> 10.17.130.20 TLSv1 113 [TCP Retransmission] Change Cipher Spec, Encrypted Handshake Messag
在内核的ftrace 的 tracing 功能
$ echo 1 > /sys/kernel/debug/tracing/tracing_enabled
$ echo 1 > /sys/kernel/debug/tracing/tracing_on
4.16内核之后支持tcp tracepoint
$ cd /sys/kernel/debug/tracing/events/
$ echo 1 > tcp/tcp_retransmit_skb/enable
$ cat trace_pipe
<idle>-0 [007] ..s. 265119.290232: tcp_retransmit_skb: sport=22 dport=62264 saddr=172.23.245.8 daddr=172.30.18.225 saddrv6=::ffff:172.23.245.8 daddrv6=::ffff:172.30.18.225 state=TCP_ESTABLISHED
如何分析常见的tcp问题
检查网络的dstat
$ dstat
--total-cpu-usage-- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai stl| read writ| recv send| in out | int csw
8 1 91 0 0| 0 4096B|7492B 7757B| 0 0 |4029 7399
8 1 91 0 0| 0 0 |7245B 7276B| 0 0 |4049 6967
8 1 91 0 0| 0 144k|7148B 7386B| 0 0 |3896 6971
9 2 89 0 0| 0 0 |7397B 7285B| 0 0 |4611 7426
8 1 91 0 0| 0 0 |7294B 7258B| 0 0 |3976 7062
paging是内UC你,system.int为中断次数,system.csw为上下文切换次数
单独针对tcp
$ dstat --tcp
------tcp-sockets-------
lis act syn tim clo
27 38 0 0 0
27 38 0 0 0
分别是
- lis 监听
- act 处于ESTABLISHED状态的连接数
- syn 处于三次握手的连接数,如果过大,可能存在大量的新连接
- tim 处于TIME-WAIT状态的连接数
- clo 处于CLOSE状态的连接数,如果过大,可能程序有bug,没有调用close(2)
查看每个连接的状况
$ ss -natp
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN0 100 0.0.0.0:36457 0.0.0.0:* users:(("test",pid=11307,fd=17))
LISTEN0 5 0.0.0.0:33811 0.0.0.0:* users:(("test",pid=11307,fd=19))
ESTAB 0 0 127.0.0.1:57396 127.0.1.1:34751 users:(("test",pid=11307,fd=106))
ESTAB 0 0 127.0.0.1:57384 127.0.1.1:34751 users:(("test",pid=11307,fd=100))
Recv-Q和Send-Q分别是接收队列和发送队列的大小
netstat是通过直接读取/proc/net/下面的文件来解析网络连接信息的;而ss使用的是netlink方式,这种方式的效率会高很多
netstat来自net-tools,ss来自iproute2,命令几乎一致
- ifconfig等价于ip addr和ip link
- route,netstat-r等价于ip route
- netstat等价于ss
- netstat -s等价于nstat
查看是否丢包
$ nstat -z | grep -i drop
TcpExtLockDroppedIcmps 0 0.0
TcpExtListenDrops 0 0.0
TcpExtTCPPrequeueDropped 0 0.0
TcpExtTCPBacklogDrop 0 0.0
TcpExtPFMemallocDrop 0 0.0
TcpExtTCPMinTTLDrop 0 0.0
TcpExtTCPDeferAcceptDrop 0 0.0
TcpExtTCPReqQFullDrop 0 0.0
TcpExtTCPOFODrop 0 0.0
tcpdump原理
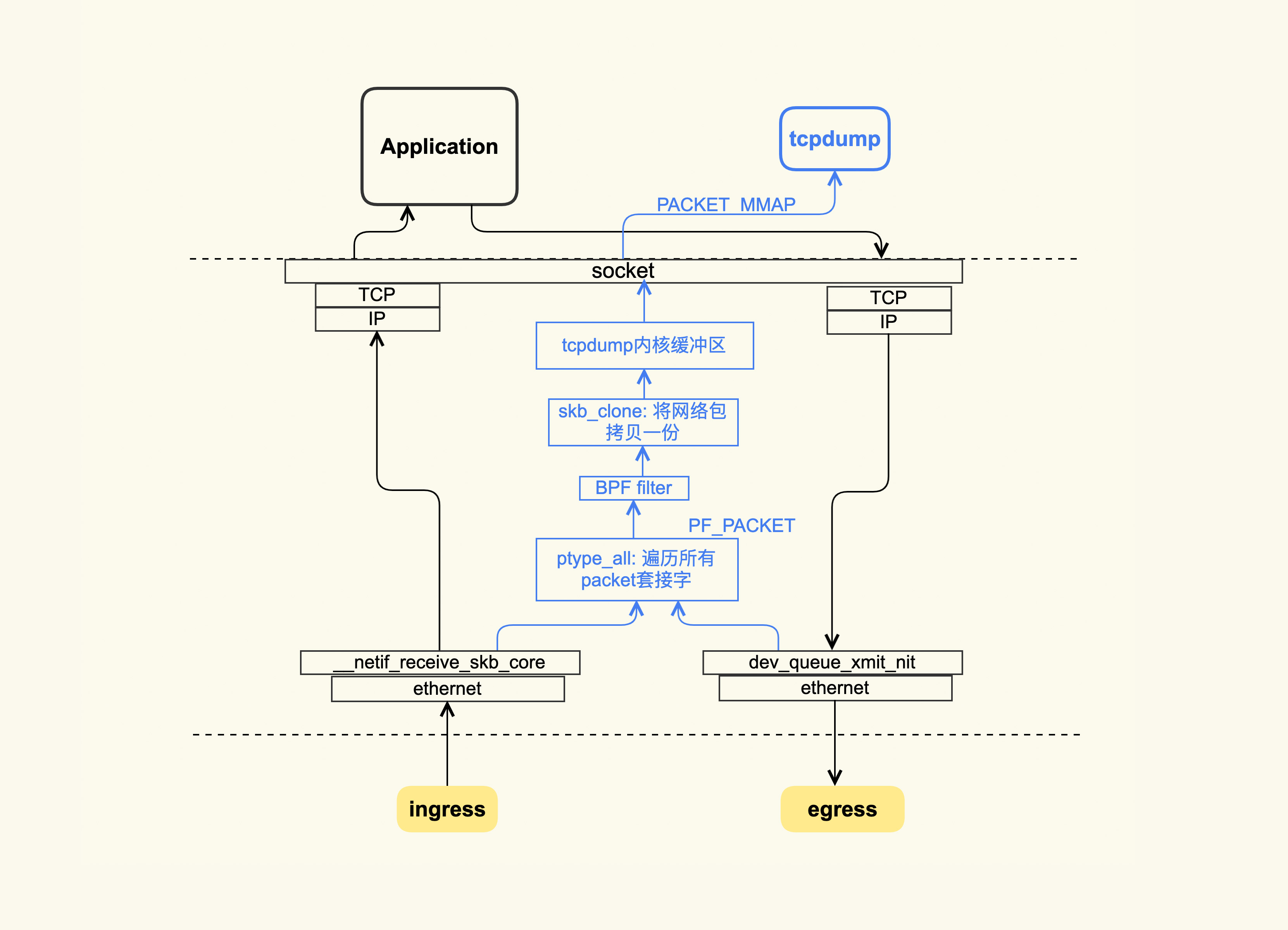
tcpdump基于BPF过滤器,如果存在非常多的连接,建议慎用
在4.16内核及以上使用tracepoint分析问题,路径位于/sys/kernel/debug/tracing/events/tcp/和/sys/kernel/debug/tracing/events/sock/
| tracepoint | 作用 |
|---|---|
tcp_retransmit_skb |
追踪tcp重传 |
tcp_retransmit_synack |
追踪半连接重传 |
tcp_rcv_space_adjust |
是否在内核空间缓冲区 |
tcp_probe |
追踪tcp拥塞控制 |
tcp_send_reset |
追踪发送的RST包 |
tcp_receive_reset |
追踪收到的RST包 |
tcp_destroy_sock |
追踪tcp连接的销毁 |
inet_sock_set_state |
追踪网络连接的变化 |

