

etcd深入解析
目录:
分布式系统与一致性协议
分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息系统进行通信和协调的系统
分布式系统需要满足
- 可用性
- 可扩展性 增加和减少机器不会改变系统行为,获得近似的线性提升
- 容错性 对错误进行规避以及从错误中恢复的能力
- 性能
CAP原理
- C:一致性
- A:可用性 系统在有限时间内给出请求的响应,无论成功与否
- P;分区容忍性 因为网络等原因无法通信,或者丢失消息后系统仍然可以正常工作
由于三者不能兼容,只能取其二,一些NoSQL就会放宽一致性的要求,最终一致即可;而金融领域会放弃可用性
一致性
一致性算法
- 可终止性 非失败进程在有限的时间内能够做出决定
- 一致性 所有进程必须对最终的决定达成一致
- 合法性 算法做出确定的值必须在其他进程的期望值内
以数据为中心的一致性模型
- 严格一致性
- 顺序一致性
- 因果一致性 朋友圈的数据就是因果一致性,针对性的评论的顺序会是正常的
- 串行一致性
以用户为中心的一致性模型
- 最终一致性 CDN和DNS都是这样的
复制状态机
对于mapreduce的场景,数据是只读的,不存在一致性的问题,而复制状态机用于允许修改数据的场景,例如分布式系统中的元数据
拜占庭将军问题
得出的如果容忍N个拜占庭问题,需要2N+1个复制节点,但是也不能保证万无一失
FLP不可能性
在异步通信模型下同时保证一致性和可终止性是做不到的
Paxos协议
只有理论没有实践
Raft算法
Raft算法包括
- 领袖选举 领袖节点挂掉之后重新给出一个新的领袖节点
- 日志复制 领袖节点从Client接收到操作请求,将操作日志复制到集群的全部节点,强制与领袖节点保持一致
- 安全性
- 成员关系变化 配置发生变化能正常工作
减少状态空间
通过减少需要考虑的状态简化状态空间
- 强领导人
- 领袖选举
- 成员变化 使用联合一致性算法
Raft一致性算法
分布式模型有两种节点关系模型
- 对称 节点平等,Client可以与任意节点交互
- 非对称 基于选主,主节点有决策权
包含的节点
- Leader
- Candidate(候选)
- Follower
在时间同步的时候对于时间不同步的问题,信息交换通过信息的ID(任期号等)来进行标识
领导人选举
为什么使用etcd
现在键值存储系统都是分布式的,例如zookeeper
zookeeper是成熟的,但是缺点
- 复杂,使用Paxos强一致性,只有Java和C两种接口
- Java编写,重依赖
- 发展缓慢
而etcd的优点
- 稳定
- 服务是发现的
- 支持稳定watch
- 性能
etcd架构简介
简单
- 支持RESTful风格的HTTP+JSON
- etcdv3增加了gRPC的支持,同时也提供restgateway
- Go编写
- 使用Raft算法
安全
- 支持TLS客户端安全认证
性能
- v3极限10k+QPS
可靠
- 可靠使用raft算法保证数据的强一致性
etcd即是持久化键值存储系统,又是分布式系统数据一致性提供者
架构
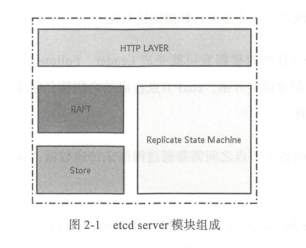
- 网络层 提供网络读写,监听端口,集群节点之间数据通信
- Raft模块
- 存储模块 kv存储,WAL文件,Snapshot管理,处理etcd功能事务,包括数据索引,节点状态变更,监控和反馈,事件处理和执行
- 复制状态机 抽象模块,数据存储在内存中,定期持久化到磁盘,每次写请求都会持久化到WAL文件,并且根据写请求的内容修改状态机数据。基于WAL的存储系统的所有数据提交都会事先记录日志。
一个用户请求发送过来,经由HTTPS的Server转发给存储模块进行事务处理,如果涉及节点状态更新,则交由Raft模块进行仲裁和日志记录,然后再同步到别的etcd节点,当半数以上节点确认状态的修改,才会数据持久化
etcd在启动的时候会在各个节点之间建立长链接
- Leader向Follower发送心跳包,Follower向Leader回复消息
- Leader向Follower发送日志
- Leader向Follower发送Snopshot数据
- Candidate节点发起选举,向其他节点发起投票请求
- Follower将收到的写操作转发到Leader
etcd数据通道
etcd根据消息类型进行不同的传输方式
- Snapshot的数据量就比较大,甚至超过1GB
- Leader到Follower节点之间的只有几十KB
所以抽象出两种数据通道
- Stream类型 用于心跳和日志等,通过HTTP的长连接,分别关联着Channel模块和Raft模块
- Pipline类型 用于Snapshot,防止阻塞心跳包,当Stream不可用的时候也会使用Pipline类型数据包
etcd应用场景
etcd的应用场景包括分布式数据库,服务注册和发现,分布式锁,分布式消息队列,分布式选主等
- 服务注册和发现:通过注册服务配置key的TTL,定时保持心跳的方式监控健康状态
- 分布式消息队列:通过watch变化实现
- 分布式锁
etcd性能测试
略
etcd与其他键值存储系统的对比
优点有
- 版本控制
- Json的API
- Watch
- 高性能
etcd发展史
0.4版本
- Raft算法分布式协同
- HTTP/Json的API
- 使用SSL证书认证
2.0版本
- 内部协议优化
- 动态更新member配置
- CRC校验
3.0版本
- 提高了整体的吞吐率,降低时延
- 内存开销减小
- 自动TLS配置
- 支持key为前缀和范围的watch
- 多版本
- 事务
- 租约
- 监控/告警
etcd初体验
单机部署
多节点集群化部署
$ etcd name infraO --initial-advertise-peer-urls http://10.0.l.10:2380 \
--listen-peer-urls http://10.0.l.10:2380 \
--listen-client-urls http://10.0.l.10:2379,http://127.0.0.1:2379 \
--advertise-client-urls http://10.0.l.10:2379 \
--initial-cluster-token etcd-cluster-1 \
--initial-cluster infra0=http://10.0.1.10:2380,infral=http://10.0.1.11:2380,infra2=http://10.0.1.12:2380 \
--initial-cluster-state new
- initial-cluster 各集群地址,在启动后的后续更新就失效了,需要使用运行中重置配置操作
- advertise-client-urls 该节点的ClientURL,会同步到其他节点,用于重定向请求
etcd支持服务发现功能
- etcd自发现 需要准备etcd集群,用--discovery参数
- DNS发现 使用--discovery-srv参数
常用命令行
设置使用的API
export ETCDCTL_APL=3
CURD
写入key
etcdctl put foo bar
写入key并设置租约,这里使用了1234abcd
etcdctl put fool barl --lease=1234abcd
读取key
$ etcdctl get foo
foo
bar
读取key,只读取值使用--print-value-only
etcdctl get foo --print-value-only
读取key,遍历前缀为foo,可以使用--1imit=2等限制输出
etcdctl get --prefix --1imit=2 foo
读取key,按照范围
etcdctl get foo foo3
或者示例数据
a = 123
b = 456
z = 789
读取大于等于b的
$ etcdctl get --from-key b
b
456
z
789
读取key,按照版本
示例数据
foo = bar # revision = 2
fool = barl # revision = 3
foo = bar_new # revision = 4
fool = barl_new # revision = 5
进行读取
#访问最近(当前)版本的 key
$ etcdctl get --prefix foo
foo
bar_new
fool
barl_new
# 访问版本号为4时的key
$ etcdctl get --prefix --rev=4 foo
foo
bar_new
fool
barl
# 访问版本号为3时的key
$ etcdctl get --prefix --rev=3 foo
foo
bar
fool
barl
# 访问版本号为2时的key
$ etcdctl get --prefix --rev=2 foo
foo
bar
#访问版本号为l时的key
$ etcdctl get -prefix --rev=l foo
删除key
$ etcdctl del foo
1
删除key,执行指定范围--prefix和--from-key
watch数据
$ etcdctl watch foo
另一终端写入数据即可
watch数据,从一个版本开始
$ etcdctl watch --rev=2 foo
因为etcd会保留所有的历史数据,但是磁盘大小有限制,需要对旧数据进行压缩
# 压缩所有key版本号5之前的所有数据
$ etcdctl compact 5
$ etcdctl get --rev=4 foo
Error : rpc error : code = 11 desc = etcdserver : mvcc : required revision
has been compacted
压缩后之前所有key的value都不可用了
获取当前版本可以通过任意一个key来获取
$ etcdctl get mykey - w=json
{"header": {"cluster id": 14841639068965178418,"member id": 10276657743932975437,"revision": 15, " raft term": 4}}
租约
创建租约并设置
$ etcdctl lease grant 10
lease 32695410dcc0ca06 granted with TTL(lOs)
$ etcdctl put --lease=32695410dcc0ca06 foo bar
OK
撤销租约,但是撤销租约后会删除绑定在上边的key
$ etcdctl lease revoke 32695410dcc0ca06
lease 32695410dcc0ca06 revoked
$ etcdctl get foo
续租
$ etcdctl lease keep-alive 32695410dcc0ca06
lease 32695410dcc0ca06 keepalived with TTL(1O)
lease 32695410dcc0ca06 keepalived with TTL(1O)
lease 32695410dcc0ca06 keepalived with TTL(1O)
获取租约信息
$ etcdctl lease grant 500
lease 694d5765fc71500b granted with TTL(500s)
$ etcdctl put zool val1 --lease=694d5765fc71500b
OK
$ etcdctl put zoo2 val2 --lease=694d5765fc71500b
OK
# 获取租约的TTL和剩余时间
$ etcdctl lease timetolive 694d5765fc71500b
lease 694d5765fc71500b granted with TTL(500s), remaining(258s)
# 获取绑定在租约上的keys用--keys
$ etcdctl lease timetolive --keys 694d5765fc71500b
lease 694d5765fc71500b granted with TTL(500s), remaining(132s), attached keys (zoo2 zool])
etcd常用配置参数
etcd以命令行选项和环境变量配置启动参数,环境变量以ETCD_为前缀,例如ETCD_MY_FLAG和--my-flag
- member相关有名称,数据目录,触发快照次数,心跳时间,选举等待时间,通信URL,WAL和快照的最大保留数量
- cluster相关的参数,用于初始化运行和服务发现的配置
- proxy相关的参数
- 安全相关的参数
- 日志相关的参数
- 还有统计认证等相关参数
API之v2
v2主要包括读写,读包括
- 范围查询
- watch
写包括
- 更新
- 删除
一个etcd操作完成的标志是通过一致性协议提交并且执行了,即被etcd持久化存储了。
但是由于client与etcd之间断开,没有收到响应,或者是etcd选举时可能会丢弃一些指令而不通知客户端
etcd的API保证
- 原子性 对于事件watch到的也是全部事件,而不会是一个操作的部分事件
- 一致性 除watch之外的操作都是保持线性一致的,watch需要自己根据版本号判断一下
- 隔离性 读操作不会看到中间数据
- 持久性 获取的数据一定都是持久化的
v2的API使用
管理API类
$ curl -L http://127.0.0.1:2379/version
etcd 2.0.12
$ curl -L http://127.0.0.1:2379/health
{"health": "true")
可以通过API进行数据的增删和watch等操作
也可以获取统计数据,更改member数据
API之v3
v3保留v2的协议和API,并且单独提供了一套v3的API
v3的改进和优化
- 使用gRPC+protobuf取代HTTP+JSON,通过gRPCgateway的方式支持HTTP的Json接口卡
- 使用轻量的租约代替TTL
- watch由HTTP长连接事件驱动机制调整为HTTP2的server push
- 由简单的kv数据库到支持事务,多版本
- v2不直接落盘,而v3落盘是数据的最终形态
主要特性
- gRPC是google开源的一个高性能,跨语言的RPC框架,基于HTTP2协议,使用protobuf作为序列化和反序列化协议,换句话就是基于protobuf来声明数据模型
- 序列化和反序列化优化,protobuf的效率远高于json,即使v2对json做了优化,v3仍是v2的两倍多
- 减少TCP连接
- 租约机制提高性能
- watch在v2版本每个Client都会保持一个长连接,而在v3是多路复用
- 条件更新变为事务
- 数据模型由1000个滑动窗口变为了MVCC多版本并发控制
- 快照变为增量
- 支持大规模的watch
集群运维和稳定性
etcd版本升级
etcd版本升级直接关掉一个旧版本启动一个新版本的滚动升级即可,但是只支持2.3及以上的版本进行升级
升级前查看集群健康状况
etcdctl cluster-health
在升级过程中,集群支持存在混合版本,使用最低版本进行通信,并且这个版本也会是对外报告的版本
当数据量较大的时候(大于50MB),升级的节点需要几分钟同步数据
如果集群中还有旧版本,还可以再回滚回来,如果都升级后就不能回滚了
升级会打印如下日志,知道集群升级完毕
2016-06-27 15:22:05.679644 W I etcdserver: the local etcd version 2.3.7 is not up-to-date
2016-06-27 15:22:05.679660 W I etcdserver: member 82llfld0f64f3269 has a higher version 3.0.0
从etcdv2切换到v3
对于client只能是修改代码了
数据迁移分线上迁移和线下迁移
线下迁移需要先停etcd的写入
检查状态机
ETCDCTL_API=3 etcdctl endpoint status
将v2的数据转换为v3数据,写入MVCC
ETCDCTL_API=3 etcdctl migrate
线上迁移就需要代码支持,v3读取不到的用v2读取并写入v3版本
运行时重配置
略
参数调优
时间参数
- 心跳时间
--heartbeat-interval=lOO - 选举超时时间(上限为50000)
--election-timeout=500
快照
快照会积累到一定数量才会创建,如果内存和磁盘使用很高,就调低快照的阈值
- 快照阈值
--snapshot-count=5000
磁盘
etcd对磁盘IO的时延敏感,fsync的时候堵塞可能会丢失心跳包,请求超时等,可以调高etcd的磁盘优先级
ionice -c2 -n0 -p `pgrep etcd`
网络
etcd在网络堵塞的情况可能会有缓冲区报错
dropped MsgProp to 247ae2lff9436b2d since streamMsg's sending buffer is full
dropped MsgAppResp to 247ae2lff9436b2d since streamMsg's sending buffer is full
可以提高etcd节点的优先级
$ tc qdisc add dev ethO root handle 1 : prio bands 3
$ tc fi1ter add dev ethO parent 1: protocol ip prio 1 u32 match ip sport 2380 0xffff flowid 1:1
$ tc filter add dev ethO parent 1: protocol ip prio 1 u32 match ip dport 2380 Oxffff flowid 1:1
$ tc filter add dev ethO parent 1: protocol ip prio 2 u32 match ip sport 2739 Oxffff flowid 1:1
$ tc filter add dev ethO parent 1: protocol ip prio 2 u32 match ip dport 2739 Oxffff flowid 1:1
监控
$ curl - L http://localhost:2379/metrics
维护
压缩历史版本
$ etcd --auto-compaction-retention=l
消除碎片化
压缩历史版本会有内部碎片
$ etcdctl defrag
存储配额
$ etcd --quota-backend-bytes=$((16*1024*1024))
当达到配额只支持查询和删除,直到有足够空间才能恢复
$ while [ 1 ]; do dd if=/dev/urandom bs=1024 count=1024 | ETCDCTL API=3 etcdctl put key || break ; done
Error: rpc error : code = 8 desc = etcdserver : mvcc: database space exceeded
# 确认是否超出配额
$ ETCDCTL_API=3 etcdctl --write-out=table endpoint status
# 确认告警是否触发
$ ETCDCTL_API=3 etcdctl alarm list
memberID : 13803658152347727308 alarm : NOSPACE
快照备份
$ etcdctl snapshot save backup.db
$ etcdctl --write-out=table s napshot status backup db
灾备
执行过etcdctl snapshot save会有一个hash值,etcdctl snapshot restore的时候会进行校验,而直接从数据目录拷贝的没有hash值,需要使用--skip-hash-check跳过
创建数据目录(每个节点执行)
ETCDCTL_API=3 etcdct l snapshot restore snapshot.db \
--name ml \
--initial-cluster ml=http://hostl:2380,m2=http://host2:2380,m3=http://host3:2380 \
--initial-cluster-token etcd-cluster-1 \
--initial-advertise-peer-urls http://host1:2380
启动服务(每个节点执行)
etcd \
--name ml \
--listen-client- urls http://host1:2379 \
--advertise-client-urls http://host1:2379 \
--listen-peer-urls http://host1:2380 &
etcd网关
一个TCP网关,用于向etcd集群转发网络数据,支持多个后端,进行负载和轮训
etcd网关并非提升性能,不提供缓存,watch合并和批处理等功能
grpc代理
grpc代理可以合并watch请求,缓存range结果等
etcd grpc-proxy start --endpoints=infraO.example.com,infral.example.com,infra2.example.com --listen-addr=l27.0.0.1:2379
支持--namespace隔离数据空间
故障恢复
- 小部分节点故障,集群正常,只是会丢失故障节点的连接
- 主节点故障,超过选举周期会自动选举
- 大部分节点故障,集群无法接收写请求了,当大部分节点恢复才能恢复正常,否则只能通过备份恢复了
- 网络分区,大节点可用,小节点不可用,就不会出现
硬件
- CPU 一般集群的节点需要2~4核,如果上千连接或者每秒上万请求的情况,需要8~16核
- 内存 etcd会进行缓存,剩下的内存跟踪watch,一般8GB即可,如果上千连接或者每秒上万请求的情况,需要16~64GB
- 磁盘 正常高于50串行IOPS(7200转)即可,如果上千连接或者每秒上万请求的情况,建议SSD
50个节点的k8s集群,2核8G即可,250个节点的k8s集群,4核16G即可
etcd安全
访问安全
etcd在2.1加入了User和Role的概念,无论数据通道是否进行加密,etcd都支持安全认证和权限管理
etcd包含三种资源类型
- 权限资源 User和Role信息
- 键值资源 kv存储
- 配置资源 安全配置,权限配置和etcd集群动态配置
当etcd创建root用户时,root用户有所有的权限,其他用户的权限也是需要root角色来管理的,支持读和写两种方式
etcd默认创建了guest用户,可以用root用户撤销guest的用户
etcdct1 role revoke guest
访问控制实践
创建用户
$ etcdctl user list
$ etcdctl user add myusername
授权
$ etcdctl user grant myusername -roles foo,bar,baz
$ etcdctl user revoke myusername -roles bar,baz
获取用户信息
$ etcdctl user get myusername
修改密码
$ etcdctl user passwd rnyusernarne
删除用户
$ etcdctl user remove myusername
创建角色
$ etcdctl role list
$ etcdctl role add myrolename
授权
# 授予key为/foo的只读权限
$ etcdctl role grant-permission myrolename read /foo
# 授予前缀为/foo的只读权限
$ etcdctl role grant-permission myrolename --prefix=true read /foo/
# 授予key为/foo的只写权限
$ etcdctl role grant-permission myrolename write /foo
# 读写权限
$ etcdctl role grant-permission myrolename readwrite keyl keys
$ etcdctl role grant myrolename -path '/pub/*' -readwrite
查看权限
$ etcdct1 role get myrolename
收回权限
$ etcdctl role revoke-permission myrolename /foo/bar
移除role
$ etcdctl role remove myrolename
创建用户
$ etcdctl user add root
启用权限认证
$ etcdctl auth enable
关闭权限认证
$ etcdctl -u root:rootpw auth disable
整体步骤
- 添加root用户
etcdctl user add root - 开启认证
etcdctl auth enable - 添加其他用户
etcdctl user add <user> - 添加角色
etcdctl --usemame root:<passwd> role add <role> - 为角色授权
etcdctl --username root:<passwd> role grant --readwrite --path <path> <role> - 用户分配角色
etcdctl --username root:<passwd> user grant --roles <role> <user>
传输安全
etcd支持TLS协议加密通信,TLS既可以用于Server之间,又可以用于Client和Server
如果使用了--client-certauth=true,Client端的CN字段就能被用于标识一个用户,默认使用这个证书登录的用户就是权限系统的用户
etcd的传输层安全模型使用了非对称加密
多版本高并发控制
使用MVCC,和MySQL等一样
在etcdv2中,是一个内存数据,写操作通过raft复制日志,复制成功写入内存,数据的持久化是通过快照实现,快照的原理也是将数据序列化写入磁盘
在etcdv3中,因为要保存多个历史版本,数据是直接存储在磁盘的,使用BoltDB
BoltDB的key是revision,value是etcd的kv组合
举个例子,用etcdctl写人两条记录
etcdctl put key l "vl" put key2 "v2"
再通过etcdctl更新这两条记录
etcdctl put key l "v1l" put key2 "v12"
BoltDB中其实包含了4条数据
rev={3,0), key=keyl, value="vl"
rev={3,1), key=key2, value="v2"
rev={4,0), key=keyl, value="vl2"
rev={4,1), key=key2, value="v22"
revision的第一个值是main revision,第二个值是sub revision,main revision相同代表的是一个事务
BoltDB是基于B树和mmap的数据库,将磁盘page映射到内存,通过COW(copy-on-wirte)进行管理page,系统可以无锁读写并发,但不能写写并发,适合读多写少的场景
日志和快照管理
etcd对数据的持久化,采用的WAL加Snapshot
所有的修改提交都要先写入log中,log文件包括redo信息,undo信息。在程序异常退出可以来区分是否完成,快照的作用是为了数据恢复时的效率,并在快照之后,筷子骄傲之前的binlog数据就可以删除
v2和v3的快照流程是类似的,只不过v2是把内存的数据序列化为Json存在磁盘,而v3是读取BoltDB的数据序列化到磁盘
事务和隔离
etcdv2在操作key的时候是通过key的版本号比较来确认操作是否成功,v2只提供单个key的事务,而在v3引入的transaction支持多个key的原子操作
watch机制
etcdv2的watch
- 内部基于HTTP的long poll实现,是HTTP1.1的长连接,需要维护连接
- 一个watch请求不支持多个key
- 只保留1000条历史记录并不支持通过watch进行数据同步
etcdv3的watch
- 使用grpc,利用HTTP2的TCP连接多路复用
- 一个watch支持多个key
- 没有1000条历史记录的限制
etcdv3的watch流程
- watch请求分两种,单个key和区间key,对应不同的watcher
- etcd有一个线程持续的遍历watch请求,每个watch对象会负责维护监控key的已经推送到那个revison
- etcd根据revison去BoltDB遍历这个revison之后的数据,如果key符合就通过watch对象发给client

