

k8s小tips
目录:
强制删除pod
$ kubectl delete pod [pod name] --force --grace-period=0 -n [namespace]
DaemonSet OnDelete
对于修改traefik等配置,默认情况下修改会直接重启,因为spec.updateStrategy.type的配置默认是使用的RollingUpdate,修改完为OnDelete之后就可以在流量低峰逐一删除pod升级
镜像拉取问题
$ docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.15.1
$ docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.15.1 gcr.io/kubernetes-helm/tiller:v2.15.1
$ docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.15.1
禁止调度驱逐pod
kubectl cordon <node name>
kubectl drain <node name> --ignore-daemonsets
ds部署在所有机器
nodeSelector:
beta.kubernetes.io/arch: amd64
tolerations:
- operator: Exists
node notready
报错containerruntime is down PLEG is not healthy
runtime是不工作的,PLEG是pod lifecycle event generator,为kubelet用于检测runtime状态的
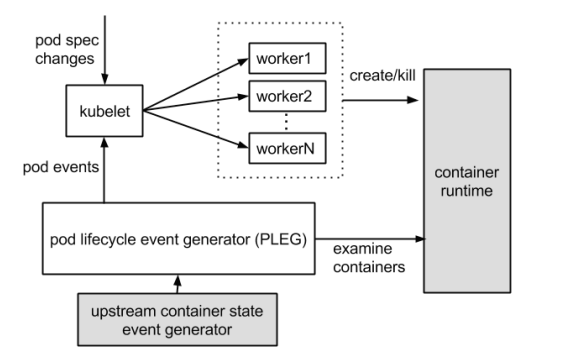
kill -USR1 <pid>
打印docker daemon的线程调用栈,位置/var/run/docker,daemon的主要作用是接收http请求,路由请求,然后进入处理函数,可能会存在等待mutex实例的情况
kill -SIGUSR1 <pid>
打印containerd的调用栈,输出到message日志,containerd接收daemon的grpc请求,一般都是start,process等相关
调用runc创建容器进程,容器启动后runc会退出,如果runc仍在执行的,说明runc不能正常启动容器
runc是一个libcontainer的简单封装,用来管理容器,可以kill掉runc进程,命令行启动strace整理过程
会存在调用dbus进行进程间通信,可以使用busctl查看,重启dbus-daemon完成,或者重启systemd
kubelet启动cpu绑定
$ vi /var/lib/kubelet/kubeadm-flags.env
KUBELET_KUBEADM_ARGS="--feature-gates=CPUManager=true --reserved-cpus=6 --kube-reserved=cpu=3 --cpu-manager-policy=static"
$ mv /var/lib/kubelet/cpu_manager_state !#$.bak
kubectl的krew
安装参考https://krew.sigs.k8s.io/docs/user-guide/setup/install/
nginx-ingress插件安装和使用方式参考https://kubernetes.github.io/ingress-nginx/kubectl-plugin/
kubectl补全
yum install -y bash-completion
source /usr/share/bash-completion/bash_completion
source <(kubectl completion bash)
强制删除namespace
ETCDCTL_API=3 /home/etcd/bin/etcdctl get /registry/deployments/default --prefix --keys-only
ETCDCTL_API=3 /home/etcd/bin/etcdctl get /registry/namespaces --prefix --keys-only
ETCDCTL_API=3 /home/etcd/bin/etcdctl del /registry/namespaces/cattle-system
查看部分日志
docker logs rancher --since="2021-01-29" --tail=100
docker使用其他用户
# 查询是否有docker组
$ cat /etc/group
# 如果没有
$ sudo groupadd docker
# 将当前用户添加到docker组
$ sudo usermod -G docker $(USER)
# 重启docker服务
$ sudo systemctl restart docker.service
优雅停止pod
spec:
contaienrs:
- name: my-awesome-container
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep", "10"]
因为
- endpoint摘除为apiserver完成
- stop容器为kubelet完成
两者没有先后顺序,这样可以保证先摘除
滚动升级策略
spec:
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
type: RollingUpdate
coredns强制解析
hosts {
203.209.230.17 restapi.amap.com
fallthrough
}
docker启动替换enterpoint
docker run -it --entrypoint "/bin/bash" why:v1
容器没有命令问题
export TARGET_ID=666666666
# 加入目标容器的 network, pid 以及 ipc namespace
docker run -it --network=container:$TARGET_ID --pid=container:$TARGET_ID --ipc=container:$TARGET_ID busybox
容器内vim乱码
在镜像中使用.vimrc文件,内容为set encoding=utf-8
docker构建镜像慢
升级存储引擎,device mapper-> overlay2
服务长连接问题
使用headless的service
clusterIP:None
dns解析返回pod的IP列表,再分别建立连接
pod挂载网络文件系统需要额外参数
示例报错
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned monitoring/grafana-5ddc8c7c88-xtx4p to worker01
Warning FailedMount 12m (x2 over 15m) kubelet, worker01 Unable to attach or mount volumes: unmounted volumes=[nfs-volume], unattached volumes=[default-token-vsw29 nfs-volume]: timed out waiting for the condition
Warning FailedMount 93s (x6 over 17m) kubelet, worker01 Unable to attach or mount volumes: unmounted volumes=[nfs-volume], unattached volumes=[nfs-volume default-token-vsw29]: timed out waiting for the condition
这里Unable to attach or mount volumes: unmounted volumes=[nfs-volume],nfs不能正常挂载
登录到机器发现可以挂载
$ /usr/bin/mount -t nfs -o vers=4.0,noresvport 10.210.104.52:/ /mnt/
$ ls /mnt
grafana_data
查看挂载失败的情况,发现kubelet一直在执行mount命令
$ ps -ef | grep kubelet
root 2324 1 8 8月07 ? 3-22:54:36 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --cgroup-driver=systemd --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.2
root 50718 2324 0 15:52 ? 00:00:00 /usr/bin/mount -t nfs 10.210.104.52:/grafana_data /var/lib/kubelet/pods/4cbeaa46-f957-47cc-900e-4fa1a2cc8790/volumes/kubernetes.io~nfs/nfs-volume
root 50720 50718 4 15:52 ? 00:01:28 /sbin/mount.nfs 10.210.104.52:/grafana_data /var/lib/kubelet/pods/4cbeaa46-f957-47cc-900e-4fa1a2cc8790/volumes/kubernetes.io~nfs/nfs-volume -o rw
work 61089 35600 0 16:27 pts/0 00:00:00 grep --color=auto kubelet
root 158470 2324 0 16:02 ? 00:00:00 /usr/bin/mount -t nfs 10.210.104.52:/grafana_data /var/lib/kubelet/pods/145e1631-4852-4b5b-af5e-8e4d5edb2887/volumes/kubernetes.io~nfs/nfs-volume
root 158553 158470 3 16:02 ? 00:00:59 /sbin/mount.nfs 10.210.104.52:/grafana_data /var/lib/kubelet/pods/145e1631-4852-4b5b-af5e-8e4d5edb2887/volumes/kubernetes.io~nfs/nfs-volume -o rw
root 189580 189561 0 9月22 ? 00:01:12 /metrics-server --metric-resolution=30s --kubelet-insecure-tls --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP
看到这里执行mount没有添加vers=4.0,noresvport参数,不使用这个参数mount执行命令进行挂载就不行了,直接夯住
在deployment的配置中,volume相关的有两处
volumeMounts:
- mountPath: /var/lib/grafana
subPath: grafana
name: nfs-volume
和
volumes:
- name: nfs-volume
nfs:
server: 10.210.104.52
path: /grafana_data
分别对应kubernetes的struct为v1.VolumeMount和v1.NFSVolumeSource,这两个结构体中并没有对应的挂载参数字段,源代码位置参考github
需要pv来支持
参考官方文档
dockerlog过大
/etc/docker/daemon.json配置日志滚动
{
...
"log-driver": "json-file",
"log-level": "warn",
"log-opts": {
"max-file": "10",
"max-size": "100m"
},
可以通过docker system df -v查看
这里需要注意,写入可写层的日志问题
容器数据磁盘被写满造成的危害:
- 不能创建 Pod (一直 ContainerCreating)
- 不能删除 Pod (一直 Terminating)
- 无法 exec 到容器
Pod处于Terminating状态
Need to kill Pod
Normal Killing 12s (x7 over 2h) kubelet, 10.210.0.12 Killing container with id docker://whysdomain:Need to kill Pod
可能是磁盘满了
DeadlineExceeded
Warning FailedSync 3m (x8 over 3h) kubelet, 10.210.0.12 error determining status: rpc error: code = DeadlineExceeded desc = context deadline exceeded
17旧版本dockerbug,建议升级到18版本以上
可以强制删除kubectl delete pod <pod-name> --force --grace-period=0
存在Finalizers
在metadata中存在finalizers,资源一般认为是程序创建,删除资源需要删除metadata中的
DNS解析时间超过5s
glibc中resolver的省却超时时间为5s,丢包的原因是并发发送相同五元组报文的时候,有概率发生冲突,造成查询请求丢弃
有两种规避方式
- 用tcp发送DNS,配置
options use-vc - 避免A和AAAA使用相同的源端口,就是不使用相同五元组
第二种有很多种操作
在启动脚本CMD或ENTRYPOINT中添加
/bin/echo 'options single-request-reopen' >> /etc/resolv.conf
在pod的postStart hook
lifecycle:
postStart:
exec:
command:
- /bin/sh
- -c
- "/bin/echo 'options single-request-reopen' >> /etc/resolv.conf"
template.spec.dnsConfig(v1.9以上)
template:
spec:
dnsConfig:
options:
- name: single-request-reopen
通过configmap挂载
apiVersion: v1
data:
resolv.conf: |
nameserver 1.2.3.4
search default.svc.cluster.local svc.cluster.local cluster.local ec2.internal
options ndots:5 single-request-reopen timeout:1
kind: ConfigMap
metadata:
name: resolvconf
---
...
volumeMounts:
- name: resolv-conf
mountPath: /etc/resolv.conf
subPath: resolv.conf
...
volumes:
- name: resolv-conf
configMap:
name: resolvconf
items:
- key: resolv.conf
path: resolv.conf
使用MutatingAdmissionWebhook
参考官方文档MutatingAdmissionWebhook
POD.spec.dnsPolicy实现dns文件替换
通过ns进入容器debug
$ kubectl -n <ns> describe pod <pod> | grep -Eo 'docker://.*$' | head -n 1 | sed 's/docker:\/\/\(.*\)$/\1/'
00c539c79c761a51936b5a558a1718a0a55d7fd3f63855593406bdca9f3c5442
$ docker inspect -f {{.State.Pid}} 00c539c79c761a51936b5a558a1718a0a55d7fd3f63855593406bdca9f3c5442
13384
$ nsenter -n --target 13384
基于ExitCode判断pod为什么退出
在kubectl describe pod查看异常的pod的State字段,ExitCode为进程退出时的状态码
退出的状态码
- 0正常退出
- 1~128为程序自身原因异常退出,只是一般约定,程序也可以用其他状态码
- 129-255为外界中断将程序退出
当退出码正常会做code%256转换,如果是负数会做转换256-(|code|%256)
常见的状态码例如137,cgroup根据resources.limits限制了内存,OOM的时候,cgroup将容器kill -9掉,就是128+9=137
journalctl -k可以查看系统日志
prometheus监控项拆分
监控项拆分
- 根据监控维度拆分
- 通过hash的方式拆分
示例配置
kubernetes_sd_configs:
- role: node
# 通常不校验 kubelet 的 server 证书,避免报 x509: certificate signed by unknown authority
tls_config:
insecure_skip_verify: true
relabel_configs:
- source_labels: [__address__]
modulus: 4 # 将节点分片成 4 个 group
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^1$ # 只抓第 2 个 group 中节点的数据(序号 0 为第 1 个 group)
action: keep
ingress-nginx-controller优化
内核参数优化
initContainers:
- name: setsysctl
image: busybox
securityContext:
privileged: true
command:
- sh
- -c
- |
sysctl -w net.core.somaxconn=65535
sysctl -w net.ipv4.ip_local_port_range="1024 65535"
sysctl -w net.ipv4.tcp_tw_reuse=1
sysctl -w fs.file-max=1048576
或
apiVersion: v1
kind: Pod
metadata:
name: sysctl-example
spec:
securityContext:
sysctls:
- name: net.core.somaxconn
value: "1024"
nginx配置优化
apiVersion: v1
kind: ConfigMap
metadata:
name: nginx-ingress-controller
# nginx ingress 性能优化: https://www.nginx.com/blog/tuning-nginx/
data:
# nginx 与 client 保持的一个长连接能处理的请求数量,默认 100,高并发场景建议调高。
# 参考: https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/#keep-alive-requests
keep-alive-requests: "10000"
# nginx 与 upstream 保持长连接的最大空闲连接数 (不是最大连接数),默认 32,在高并发下场景下调大,避免频繁建联导致 TIME_WAIT 飙升。
# 参考: https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/#upstream-keepalive-connections
upstream-keepalive-connections: "200"
# 每个 worker 进程可以打开的最大连接数,默认 16384。
# 参考: https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/#max-worker-connections
max-worker-connections: "65536"
监控参考
https://github.com/kubernetes/ingress-nginx/tree/main/deploy/grafana/dashboards
补全request和limit
对于没有设置的可以设置LimitRange
apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
namespace: test
spec:
limits:
- default:
memory: 512Mi
cpu: 500m
defaultRequest:
memory: 256Mi
cpu: 100m
type: Container
namespace资源显示
apiVersion: v1
kind: ResourceQuota
metadata:
name: quota-test
namespace: test
spec:
hard:
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
打散pod
反亲和策略有强弱之分
- requiredDuringSchedulingIgnoredDuringExecution调度时必须满足该反亲和性条件,如果没有节点满足条件就不调度到任何节点 (Pending)。
- preferredDuringSchedulingIgnoredDuringExecution调度时尽量满足反亲和性条件,如果实在没有满足条件的,只要节点有足够资源,还是可以让其调度到某个节点,至少不会 Pending。
强反亲和性的示例
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values:
- kube-dns
topologyKey: kubernetes.io/hostname
- labelSelector.matchExpressions为服务对应pod中labels的key与value,通过判断replicas的pod label来实现的
- topologyKey 指定反亲和的拓扑域,即node的label的key。这里用的kubernetes.io/hostname表示避免pod调度到同一节点,如果你有更高的要求可以给node打label
弱反亲和性的示例:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values:
- kube-dns
topologyKey: kubernetes.io/hostname
多了一个weight,表示此匹配条件的权重
docker支持普通用户访问
但是这样约等于给了普通用户root权限
gpasswd docker -a rd
cat /etc/group | grep rd
gpasswd docker -d rd
通过环境变量控制启动参数
ENV JAVA_OPTS="-Xms2g -Xmx2g"
ENTRYPOINT java ${JAVA_OPTS} -Dsun.net.inetaddr.ttl=0 -jar app-boot.jar -XX:+UseG1GC
kubelet的证书过期时间调整
1.controller-manager添加参数
/etc/kubernetes/manifests/kube-controller-manager.yaml
- --experimental-cluster-signing-duration=262800h0m0s
- --feature-gates=RotateKubeletServerCertificate=true
kube-controller-manager会自动重启
2.kubelet添加参数并重启
/var/lib/kubelet/kubeadm-flags.env
--feature-gates=RotateKubeletServerCertificate=true --rotate-server-certificates
3.手动通过轮换申请
kubectl get certificatesigningrequests.certificates.k8s.io
kubectl certificate approve csr-tgzb4
4.验证证书时间
openssl x509 -noout -dates -in kubelet-server-current.pem
openssl x509 -noout -dates -in kubelet-client-current.pem
服务降配
kubectl patch deployment -n why why-platform -p '{"spec":{"template":{"spec":{"containers":[{
"name": "why-platform",
"resources": {
"limits": {
"cpu": "4",
"memory": "8000Mi"
},
"requests": {
"cpu": "2",
"memory": "4000Mi"
}
}}]}}}}'
nodejs镜像
将对应版本的镜像的dockerfile的FROM改为基础镜像即可
具体参考
- https://registry.hub.docker.com/_/node
- https://github.com/nodejs/docker-node/tree/6e7d6511aba22da645ec21bd157a369a78794e6c/10/stretch
设置内核参数
在1.12之后默认支持sysctls特性,可以直接在security设置
apiVersion: v1
kind: Pod
metadata:
name: sysctl-example
spec:
securityContext:
sysctls:
- name: net.core.somaxconn
value: "1024"
- name: net.core.somaxconn
value: "1024"
...
使用initContainer
apiVersion: v1
kind: Pod
metadata:
name: sysctl-example-init
spec:
initContainers:
- image: busybox
command:
- sh
- -c
- |
sysctl -w net.core.somaxconn=65535
sysctl -w net.ipv4.ip_local_port_range="1024 65535"
sysctl -w net.ipv4.tcp_tw_reuse=1
sysctl -w fs.file-max=1048576
imagePullPolicy: Always
name: setsysctl
securityContext:
privileged: true
containers:
...
使用tuning CNI插件统一设置sysctl
{
"name": "mytuning",
"type": "tuning",
"sysctl": {
"net.core.somaxconn": "500",
"net.ipv4.tcp_tw_reuse": "1"
}
}
Pod绑定NUMA
需要在1.18的版本之上,并且 /etc/default/grub中numa=on
kubelet添加参数
--topology-manager-policy=single-numa-node
lscpu可以查看numa情况
对于单numa不满足request资源的会出现Pod为TopologyAffinityError状态
1.24不支持docker问题
通过cri-docker解决
配置开机启动,注意pod-infra-container-image配置
/usr/lib/systemd/system/cri-docker.service
[Unit]
Description=CRI Interface for Docker Application Container Engine
Documentation=https://docs.mirantis.com
After=network-online.target firewalld.service docker.service
Wants=network-online.target
Requires=cri-docker.socket
[Service]
Type=notify
ExecStart=/usr/bin/cri-dockerd --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.7
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
StartLimitBurst=3
StartLimitInterval=60s
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TasksMax=infinity
Delegate=yes
KillMode=process
[Install]
WantedBy=multi-user.target
socket文件
/usr/lib/systemd/system/cri-docker.socket
[Unit]
Description=CRI Docker Socket for the API
PartOf=cri-docker.service
[Socket]
ListenStream=%t/cri-dockerd.sock
SocketMode=0660
SocketUser=root
SocketGroup=docker
[Install]
WantedBy=sockets.target
在kubeadm初始化的时候或者kubelet启动的时候需要指定cri-socket参数
kubeadm init --image-repository registry.aliyuncs.com/google_containers --kubernetes-version=v1.24.1 --pod-network-cidr=10.244.0.0/16 --cri-socket /var/run/cri-dockerd.sock
基于环境变量更新配置
模板文件
location ^~/main/ {
proxy_pass http://${UPSTREAM_IP}:${UPSTREAM_PORT}/;
}
entrypoint脚本
#!/usr/bin/env sh
set -eu
envsubst '${UPSTREAM_IP} ${UPSTREAM_PORT}' < /usr/local/nginx/nginx.conf.template > /usr/local/nginx/conf/nginx.conf
exec "$@"
envsubst在gettext包中
dockerfile中的启动模式改为
ENTRYPOINT ["/docker-entrypoint.sh"]
CMD ["/usr/local/nginx/sbin/nginx","-g","daemon off"]

