

kafka权威指南1~5
目录:
序
kafka最初是LinkedIn的一个内部基础设施系统,不是解决传统的数据存储系统,而是把数据看成持续变化和不断增长的流,基于这种想法构建的数据系统,而在想法实现后比预先有更广的适用性
kafka是一个分布式系统,可以自由伸缩,可以存储数据,提供了数据层的可复制,持久化和存储时间自由定义。
所以kafka并不是简单的消息队列
1. 初始kafka
1.1 发布和订阅消息系统
发布和订阅是一个经典的场景了,生产者根据某些方式进行分发(当然很多的都不分发直接发送到一个队列),订阅者通过订阅来接受指定的消息,中心点broker
1.2 kafka登场
kafka的数据按照一定的顺序持久化保存
1.2.1 消息和批次
kafka的数据单元为消息,包括键和值。消息写入的时候可以通过hash键的方式进行分发到不同分区,保证相同的键会到相同的分区。
为了提高效率,属于同一主题和分区的消息会分批次写入kafka,可以减少网络开销,不过时延就会增大
1.2.2 模式
消息模式是用来定义消息内容,例如json和xml格式
1.2.3 主题和分区
kafka的消息通过topic主题进行分类
topic可以分为好多partition分区,消息以追加的方式写入分区,因为分区的问题无法保持主题范围内的消息读取顺序,然后保持先进先出的方式顺序读取。
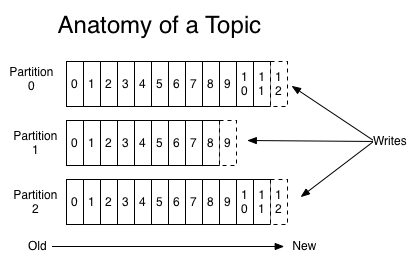
分区也是kafka实现数据冗余和伸缩性的方式。
1.2.4 生产者和消费者
生产者创建消息,一般一个消息会发布到一个topic上,会在默认情况下就将消息均匀的分布到主题的所有分区上,而不用关心是写到那个分区
消息键和分区器可以实现为键生成一个散列值,将其映射到指定分区,生产者也可以自定义分区器,根据业务规则将消息映射到分区
消费者读取消息,可以订阅一个或者多个topic,然后按照消息顺序读取,通过消息的偏移量来区分读取过的信息。
偏移量是另一种元数据,在给定分区每个消息的偏移量都是唯一的,消费者将每个消息偏移量保存在zookeeper或者kafka上,消费者关闭或者重启不会消失。
消费者是消费群组的一部分,消费者读取各自所属的分区,这种映射为所有权关系
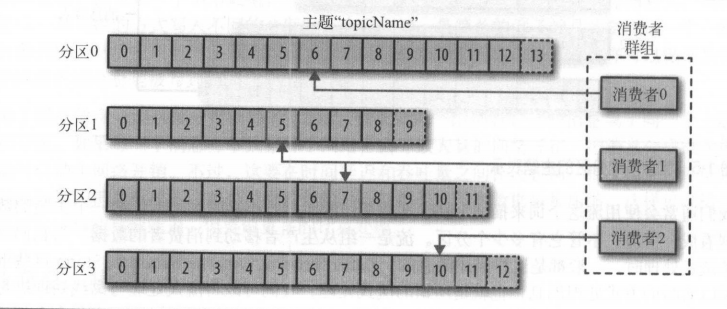
1.2.5 broker和集群
集群内节点被称为broker,负责接收消息,为消息设置偏移量,并提交到磁盘保存,为消费者提供服务,对分区请求响应,返回磁盘上的消息。
每个集群内部会有一个broker充当控制管理器,负责将分区分配到broker和监控broker
一个分区属于一个broker,这个broker就是分区的leader
一个分区会分配个多个broker,就会产生分区复制,为分区提供了消息冗余
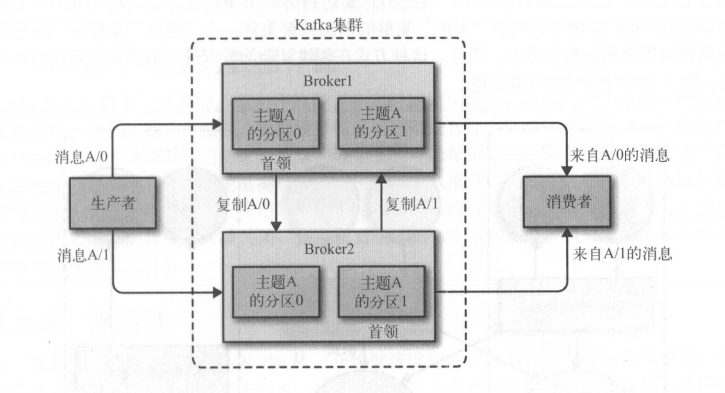
保留消息是在broker层面,保留一定时间或者一定大小,达到上限就删除,而主题层面定义保留策略,可以为消息保留到不再使用
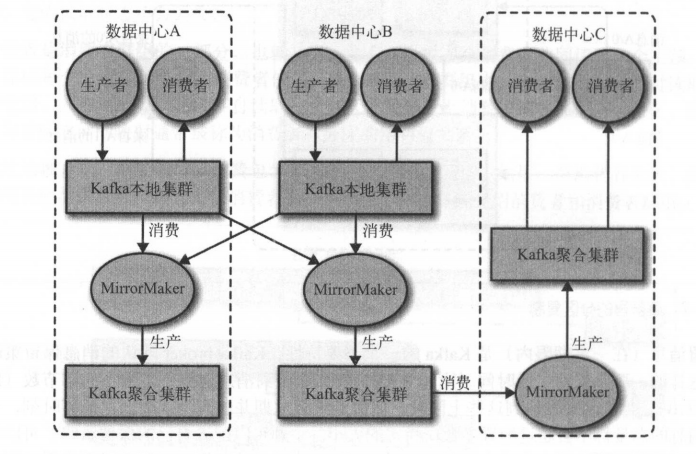
1.2.6 多集群
使用了kafka提供的MirrorMaker
1.3 为什么使用kafka
- 多生产者
- 多消费者
- 基于磁盘的数据存储
- 伸缩性
- 好性能
2 安装kafka
2.1 安装zk(略)
略
2.2 安装kafka的broker(略)
略
启动kafka
$ ./kafka-server-start.sh -daemon
创建topic
$ ./kafka-topics.sh --create --zookeeper 192.168.121.15:2181/kafka --replication-factor 2 --partitions 1 -topic test
Created topic "test".
$ ./kafka-topics.sh --list --zookeeper 192.168.121.15:2181/kafka | grep test
test
$ ./kafka-topics.sh --zookeeper 192.168.121.45:2181/kafka --describe --topic test
Topic:test PartitionCount:1 ReplicationFactor:2 Configs:
Topic: test Partition: 0 Leader: 2 Replicas: 2,6 Isr: 2,6
主要是配置的server.properties中zookeeper.connect=192.168.121.45:2181,192.168.121.4:2181,192.168.121.5:2181,192.168.121.14:2181,192.168.121.15:2181/kafka
往测试topic发送数据
$ ./kafka-console-producer.sh --broker-list 192.168.121.21:9092,192.168.121.115:9092,192.168.121.18:9092,192.168.121.92:9092,192.168.121.29:9092 --topic test
test message 1
test message 2
查看集群内的broker可以使用
$ ./kafka-broker-api-versions.sh --bootstrap-server 192.168.121.92:9092
测试读取数据
$. /kafka-console-consumer.sh --zookeeper 192.168.121.15:2181/kafka --topic test --from-beginning
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
test message 1
test message 2
2.3 broker配置
2.3.1 常规配置
- broker.id
- port
- zookeeper.connect
- log.dirs
- num.recovery.threads.per.data.dir 这个配置是每个目录的线程,对broker崩溃进行恢复的时候可以节省时间
- auto.create.topics.enable 如果是手动创建topic需要将其设置为false
2.3.2 topic的默认设置
kafka为topic设置了很多的默认配置,包括log.retention.hours.per.topic,log.retention.bytes.per.topic和log.seg.ment.bytes.per.topic
1.number.partition
参数指定了topic包含多少partition,默认topic自动创建功能是开启的,partition就是该参数的值,默认是1,分区数可以增加但是不能减少,如果如要小于配置值,需要手动创建主题了
选定分区数量考虑的因素
- topic的吞吐量
- 一般写入数据库也不会超过每秒50MB,单分区吞吐一般也不会超过50MB
- 参考broker的磁盘,网络带宽
- 单个broker对分区的个数有限制,分区越多,内存占用越多,会影响选举时间
2.log.retention.ms
kafka根据时间保留数据,默认是168小时(一周),一共有log.retention.hour|minutes|ms三个参数,但是是以文件最后修改时间为准,如果迁移过分区就不准确了
3.log.retention.bytes
kafka根据大小保留数据,默认是一个分区1GB,以时间和大小最先达到的为准
4.log.segment.bytes
kafka日志分段大小,默认是1GB
5.log.segment.ms
kafka日志分段时间,没有默认值
6.message.max.bytes
限制单个消息的大小,默认是1000000,也就是1MB,指的是压缩后的大小
如果生产者生产的消息大于这个值,broker会返回错误,消费者也最好设置与之相等,如果小于会存在不能消费的情况
同时需要调整的有replicas.fetch.max.byte,用于同步的消息大小,为啥不设置为一个?
2.4 硬件的选择
kafka的jvm不需要很大,内存都用作页缓存即可
2.5 云端kafka(略)
略
2.6 kafka集群(略)
略
2.7 生产环境的注意事项(略)
略
3. 生产者
3.1 生产者概览
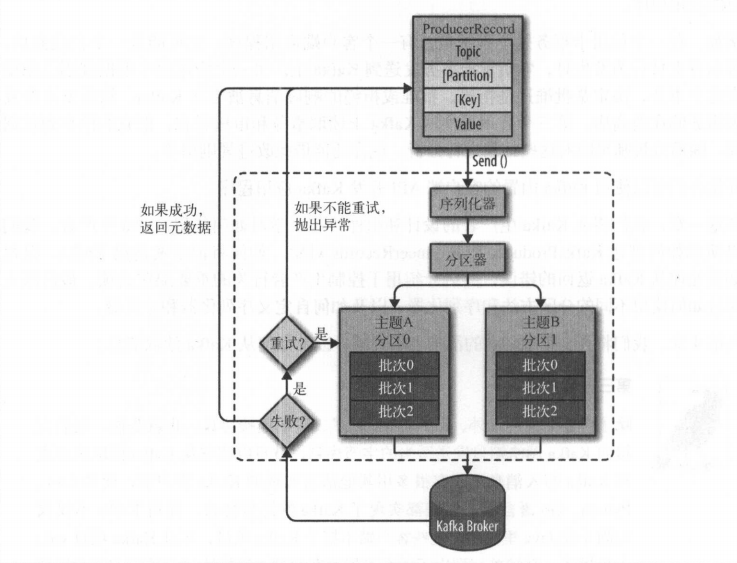
- 创建一个ProducerRecord发送给分区器
- 分区器确定分区后将记录添加到记录批次(属于同一主题和分区的属于一个批次)
- 生产者的独立线程将其发送到响应的broker
- server收到响应之后会返回一个RecordMetaData对象包含主题分区和偏移量,如果写入失败会返回错误,生产者重试,重试多次都失败就返回错误信息
3.2 创建kafka生产者(略)
略
3.3 发送消息到kafka(略)
略
3.4 生产者配置
1.acks
- 0 生产者不会等待有多少个副本收到消息
- 1 生产者等待leader写入回复消息
- all 生产者等待所有副本写入回复消息
2.buffer.memory
生产者内存缓冲区大小,当满了之后要不send阻塞,要不抛出异常,取决于block.on.buffer.full,在0.9版本更换为max.block.ms表示可以阻塞多久
3.compression.type
默认情况下消息不进行压缩,可以配置snappy,gzip和lz4等
- snappy占用cpu较少,但是压缩比更高
- gzip占用cpu较多,但是压缩后更小
4.retries
重试次数,重试间隔100ms,可以通过retry.backoff.ms配置(可以测试故障恢复或者选举的时间)
5.batch.size
同一批次可用的内存大小,如果配置小了,内存满了一定会发送,配置大了,生产者可能不会等到满就进行发送,由linger.ms配置
6.linger.ms
上述
7.client.id
用于表示,可以是任意字符串
8.max.in.flight.requests.per.connection
生产者在收到服务器响应之前可以发送多少消息,值越高就会占用越多的内存,但是也会提高吞吐量,timeout.ms指定了同步副本返回消息确认的时间
9.timeout.ms,request.timeout.ms
上述
10.max.block.ms
用于控制生产者获取元数据信息的阻塞时间
11.max.request.size
生产者发送的消息最大大小,也可以是一个批次的最大大小
12.receive.buffer.bytes和send.buffer.bytes
定义生产者接收和发送数据包的缓冲区大小,如果为-1使用操作系统默认值
3.5 序列化器
略
3.6 分区
略
4. 消费者
4.1 kafkaconsumer的概念
4.1.1 消费者和消费者群组
消费者属于消费者群组,订阅是由群组完成
当有四个分区
- 一个消费者,这个消费者消费四个分区
- 两个消费者就是一对二
- 四个消费者就是一对一
- 五个消费者也是一对一,但是有一个消费者没有分区
多个群组可以订阅同一个topic,群组之间互不影响
4.1.2 消费者群组和分区再平衡
当消费者群组中的消费者崩溃的时候,这个分区将由群组中的其他消费者来进行读取,这个过程被称为再平衡,在再平衡的期间的时候会造成群组消费短时间不可用,因为需要进行重新获取消费的偏移量
消费者通过群组协调器的broker(每个群组都有一个协调器)发送心跳,用于维护群组从属关系和分区所有权。消费者在轮训消息或者提交偏移量时发送心跳,在0.10版本出现单独的心跳线程,用于固定频率发送心跳
4.2 创建消费者
略
4.3 订阅主题
略
4.4 轮序主题
略
4.5 消费者配置
1.fetch.min.bytes
消费者从服务器获取消息的最小字节数,当有足够的数据才会发送给消费者,否则在数据量大的时候频番发送会造成CPU升高
2.fetch.max.wait.ms
消费者从服务器获取消息的最长等待时间,和fetch.min.bytes中第一个生效的
3.max.partition.fetch.bytes
每个分区返回给消费者的最大字节数,默认是1MB
4.session.timeout.ms
心跳超时时间,默认是3s,消费者发送的频率通过heartbeat.interval.ms,一般为session.timeout.ms的1/3
5.auto.offset.reset
当偏移量失效的读取位置,默认是latest是最新的,另一个earliest从分区起始位置
6.enable.auto.commit
提交偏移量的方式,more你是true,为了避免重复数据和数据丢失可以设置为false,由自己控制提交偏移量
7.partition.assignment.strategy
分区和消费者间的分配策略,有Range和RoundRobin
8.client.id
用来标识发送的消息
9.max.poll.records
单次调用call方法能返回的记录数
10.receive.buffer.bytes和send.buffer.bytes
读写的缓冲区大小,可以设置为-1使用操作系统的默认配置
4.6 提交和偏移量
略
4.7 再均衡监听器
略
4.8 从特定偏移量处开始处理记录
略
4.9 如何退出
略
4.10 反序列化器
略
4.11 独立消费者
略
5. 深入kafka
5.1 集群成员关系
kafka使用zookeeper维护成员关系,每个broker都有一个单独的标识符,会使用这个id注册到zookeeper上,kafka组件通过订阅zookeeper的/brokers/ids路径,当有broker退出或者加入集群,组件会获得通知
如果启动一个相同id的broker会在zookeeper无法注册
当broker宕机或者网络原因无法连通时,broker会与zookeeper的连接断掉,broker启动时注册的节点会在zookeeper上移除,监听broker列表的kafka组件也会告知broker移除
当broker关闭,id等数据还在zookeeper中保存,如果启动一个与之相同id的broker会拥有与之前一致的分区和topic(但是旧数据不会被拷贝???)
5.2 控制器
控制器其实就是broker,但是负责分区leader的选举,集群第一个启动的broker会在zookeeper里创建/controller让自己成为控制器,其他节点启动的时候也会尝试,但是会返回一个节点已经存在的异常,明白有控制器之后就会去watch控制节点创建的对象,获取节点变更的通知
当控制节点关闭,zookeeper上/controller节点小时,其他节点watch不到就会得到节点消失的消息,然后进行注册,第一个注册成功成为控制器,其他节点获取到存在控制器节点就开始watch这个控制器节点。控制节点会获取到一个全新的更大的Controller epoch,其他broker获取到这个值之后,小于这个值的消息就会忽略
当控制器发现broker关闭离开集群,对于leader为这个broker的分区,会遍历这些分区来为其分配新的leader,就是分区副本列表中的下一个副本(但是不会创建新的副本吗???)
当控制器发现一个broker加入集群,就会使用broker的id来检查是否包含现有分区的副本,如果有就直接,把变更消息发送给新来的broker和其他broker,新的broker上的副本从leader获取消息
如果有多个控制节点,通过Controller epoch防止脑裂
5.3 复制
topic包含多个分区,分区包含多个副本
副本分两种
- leader副本 每个分区都有一个首领副本,为了保证数据的一致性,所有请求者和消费者都过这个副本
- slave副本 leader副本以外的所有副本,不处理client的请求,只是从leader副本获取数据,与leader副本保持一致,如果其中一个崩溃,其中一个就会被变为leader副本
leader的另一个作用是搞清楚哪个副本与自己的状态是一致的。
slave副本为了和leader保持一致,会向leader发送获取数据的请求,这种请求和消费者读取消息而发送的请求一致,leader将消息发送给slave。
slave如果10s没有进行请求消息或者10s内没有请求最新的数据就会认为是不同步的,如果slave与leader不同步是不会成新的leader
5.4 处理请求
broker的大部分工作是处理客户端,分区副本和控制器发送分区首领的请求
kafka提供了一个基于TCP的二进制协议,指定了请求消息的格式以及broker如何对请求进行相应
请求消息格式包括
- Request type(API key)
- Request version(broker可以处理不同版本的客户端请求,并根据client版本做出不同的响应)
- Correlation ID(具有唯一性的数字,用于标识请求消息,也会出现在响应消息和错误日志)
- Client ID(用于标识发送请求的client)
broker会在它所监听的每个端口运行一个Acceptor线程,这个线程会创建一个连接,并将其交给Processor的线程(网络线程)去处理,Processor线程负责从Client获取消息, 并将其放到请求队列,然后从响应队列获取响应数据发送给client
请求消息被放到队列之后IO线程会进行处理会负责处理
- 生产请求 生产者发送的写入broker请求
- 获取请求 消费者或者slave副本从broker读取数据
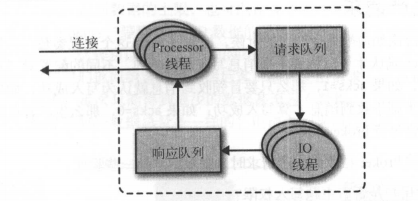
client访问leader副本是需要发往正确的broker,这些信息是从任意一个broker获取,broker会缓存这些信息,client也会缓存,并且会根据metadata.max.age.ms参数来定时更新这些信息
5.4.1 生产请求
acks配置参数指定了要多少个broker确认才可以认为一个消息是写入成功,如果acks为1则leader收到消息就认为写入成功,如果为all则需要所有同步副本收到消息才算写入成功,为0则是生产者把消息发送出去即可,完全不等broker回应
broker在接收请求前会判断发送用户权限,acks值是否有效,acks为all的时候是否有足够多的副本保证消息写入
broker在收到请求后,如果acks为0或1的时候返回响应,额如果为all则等待所有写入后返回响应,消息写入文件系统缓存,然后被刷写到磁盘。
5.4.2 获取请求
获取请求使用topic的那个分区从某一偏移量开始的数据,也可以设置broker最多可以返回多少数据
broker接收到的是一个不存在的偏移量等会返回错误
如果请求的偏移量存在,broker按照client指定的数量上限从分区读取消息,再返回客户端,也可以设置下限,当有一定量消息再进行发送减少CPU和网络开销,也可以定义超时时间,达到多久发送数据
kafka使用了零复制技术,kafka直接将其发送到网络通道,而不经过任何缓冲区,其他数据库会将其保存在本地缓存,这样避免了字节复制,也不需要管理内存缓冲区。
当leader副本写入数据,但是slave副本没有写入数据的时候,也不会将这些数据返回给slave,replica.lag.time.max.ms参数控制副本在复制消息的最大超时时间
5.4.3 其他请求
略
5.5 物理存储
存储目录通过log.dirs参数进行配置
5.5.1 分区分配
- broker之间平均分配分区副本
- 每个分区的每个副本分布在不同的broker
- 如果broker指定了机架信息,每个分区的每个副本分布在不同的机架
分区的时候没有考虑可用空间和工作负载的问题
5.5.2 文件管理
分区被分为若干的片段,默认一个片段为1GB或者一周的数据,以较小的为准,达到上限就会关闭当前文件并重新开始写一个新文件,新的文件叫做活跃片段,活跃片段不会被删除
5.5.3 文件格式
保存在磁盘上的数据格式和从发送者发送的数据格式,发送给消费者的数据格式是一致的,所以可以使用零复制,也避免了已压缩的数据进行解压和再压缩
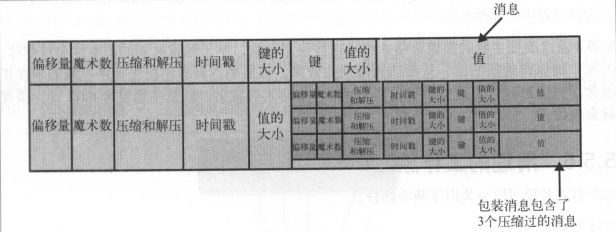
5.5.4 索引
kafka为每个分区维护一个索引,索引把偏移量映射到片段文件,索引也是分段的,在删除消息的时候删除对应索引
kafka不维护索引的校验和,如果索引损毁,会重新读取消息并录制偏移量和位置生成索引,如果有必要可以删除索引,是安全的。
5.5.5 清理
略
5.5.6 清理工作原理
日志片段可以分为两个部分
- 干净的部分
- 污浊的部分
主要应对的就是使用kafka存储一些服务的状态,可以合并保留最新的状态,而不关心中间态
5.5.7 被删除的事件
topic删除需要先将其置为null,然后保留一段事件才会被删除
5.5.8 何时会清理主题(略)
略

