

极客时间专栏——linux性能优化实战——网络部分
目录:
33 | 关于 Linux 网络,你必须知道这些(上)
网络模型
OSI网络模型, 开放式系统互联通信参考模型
- 应用层 负责为应用程序提供统一的接口
- 表示层 负责将数据转换成兼容接收系统的格式
- 会话层 维护计算机之间的通信
- 传输层 负责数据加上传输头和形成数据包
- 网络层 负责数据的转发和路由
- 数据链路层 负责MAC寻址,错误侦测和改错
- 物理层 负责物理网络中数据帧传输
TCP/IP网络模型
- 应用层 负责向用户提供一组应用程序,例如HTTP,FTP和DNS等
- 传输层 端到端通信,如TCP,UDP
- 网络层 网络包的封装寻址和路径,IP和ICMP
- 网络接口层 网络包在物理网络传输
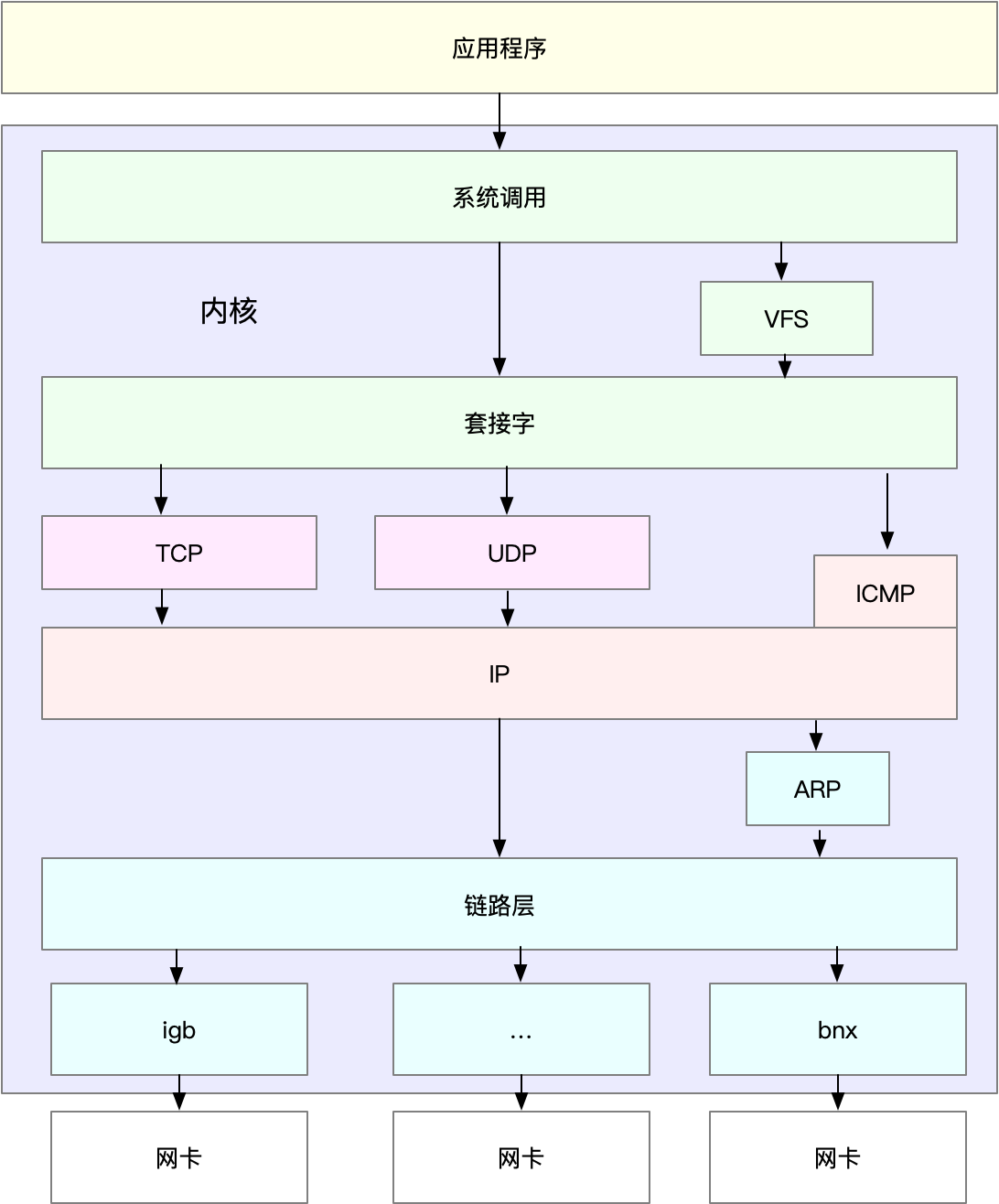
Linux网络栈
网络包在每一层传输都会进行封包或者解包
MTU最大网络传输单元,超过MTU就会在网络层分片
linux的通用网络栈示意图
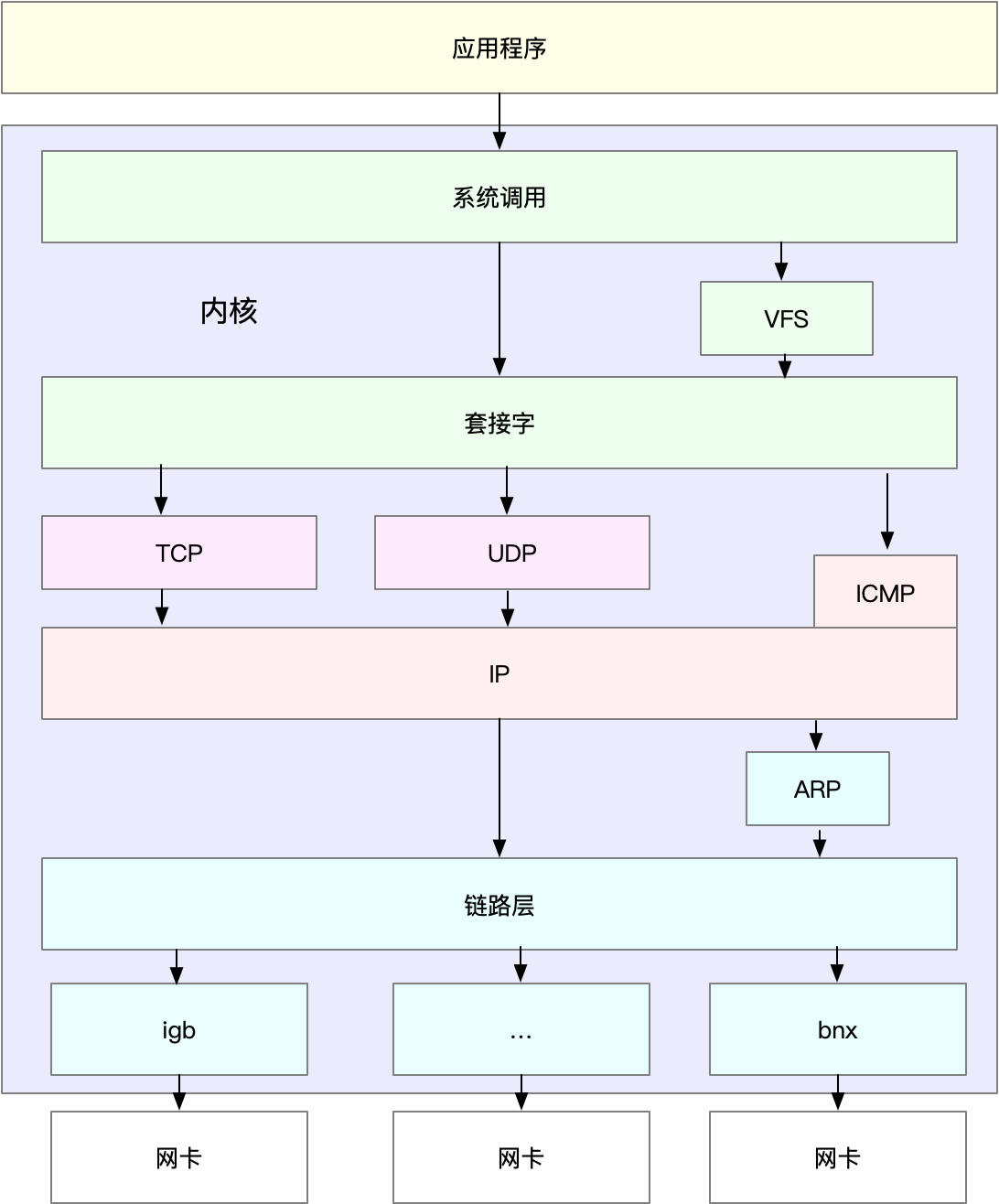
网络包接收的流程
- 网络帧到网卡
- 网卡通过DMA的方式将网络包放入到收报队列,然后通过硬中断告知中断程序收到网络包
- 网卡中断处理程序会为网络帧分配内核数据结构
sk_buffer,并将其拷贝到sk_buffer,然后通过软中断告诉内核接收到了新的网络帧 - 网络协议栈从缓冲区取出网络帧,并通过网络协议栈进行处理
- 链路层检验报文合法性,找出上层协议,去掉帧头帧尾
- 网络层取出IP头,判断网络包的下一步走向,是交到上层还是进行转发,如果是发往本机就会取出并去掉IP头交由传输层处理
- 传输层取出TCP头或者UDP头,根据源IP,源端口,目的IP和目的端口作为标识找到对应的socket,将数据拷贝到socket
网络包发送流程
与接收相反,使用的SocketAPI例如sendmsg
- 通过系统调用陷入内核态套接字层,将数据包放在socket发送缓冲区
- 网络协议栈从socket发往缓冲区取出数据包
- TCP/IP协议栈由上层到下层进行处理,添加TCP头,IP头,执行路由确认下一跳的地址,然后按照MTU大小进行分片
- 网络包由网络接口层进行物理地址寻址,找到下一跳MAC地址,添加帧头和帧尾,放到队列中,然后通过软中断通知驱动程序
- 驱动通过DMA从发包队列读出网络帧通过物理网卡发送
34 | 关于 Linux 网络,你必须知道这些(下)
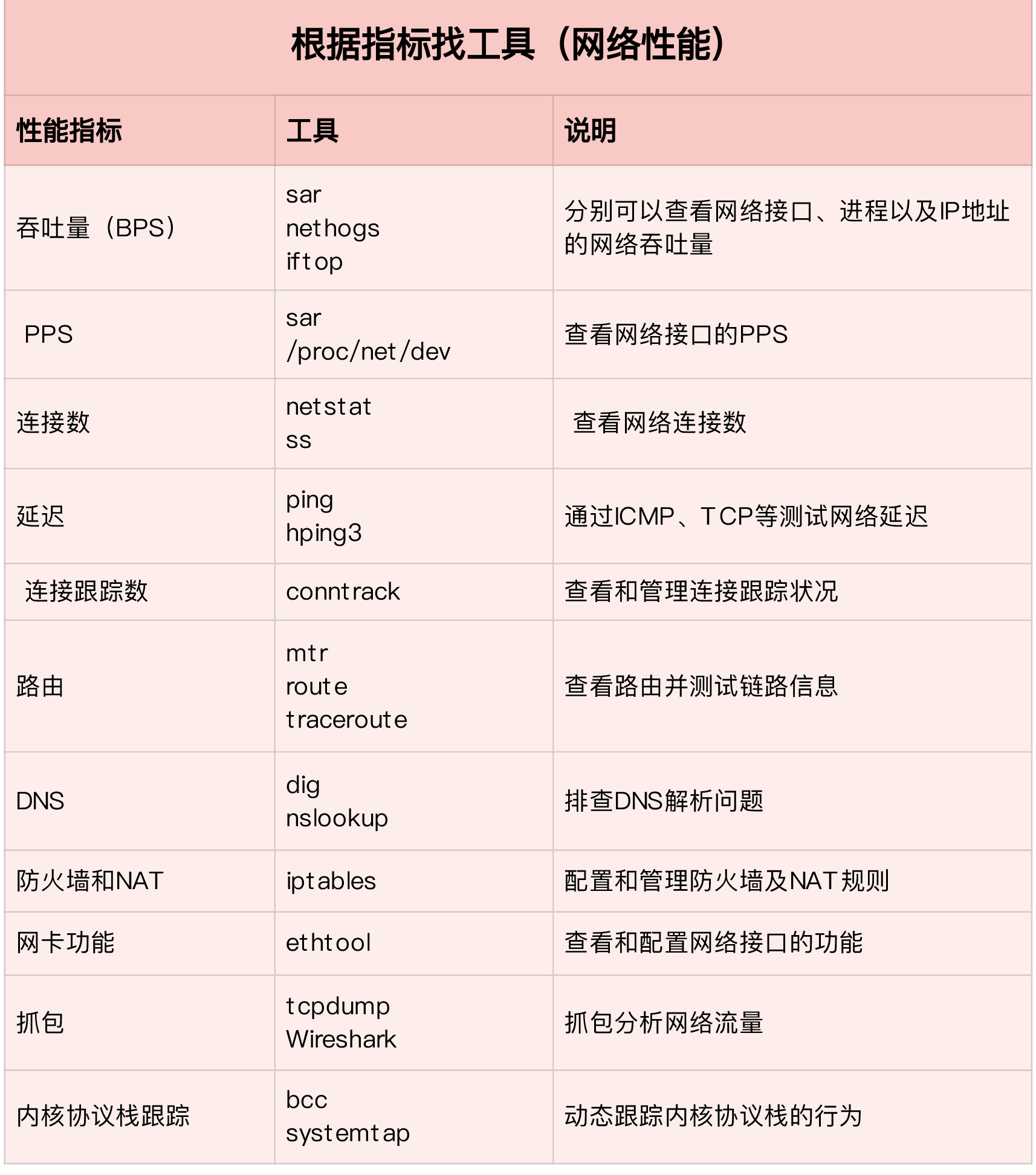
性能指标
- 带宽 链路的最大传输率,单位为b/s
- 吞吐量 单位时间内成功传输的数据量,单位为b/s
- 延时 可以指TCP握手延时或者一个数据包往返所需的时间RRT
- PPS 每秒发送的数据包的数量
- 网络可用性
- 并发连接数
- 丢包率
- 重传率
网络配置
ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.240.0.30 netmask 255.240.0.0 broadcast 10.255.255.255
inet6 fe80::20d:3aff:fe07:cf2a prefixlen 64 scopeid 0x20<link>
ether 78:0d:3a:07:cf:3a txqueuelen 1000 (Ethernet)
RX packets 40809142 bytes 9542369803 (9.5 GB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 32637401 bytes 4815573306 (4.8 GB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
$ ip -s addr show dev eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 78:0d:3a:07:cf:3a brd ff:ff:ff:ff:ff:ff
inet 10.240.0.30/12 brd 10.255.255.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::20d:3aff:fe07:cf2a/64 scope link
valid_lft forever preferred_lft forever
RX: bytes packets errors dropped overrun mcast
9542432350 40809397 0 0 0 193
TX: bytes packets errors dropped carrier collsns
4815625265 32637658 0 0 0 0
- 网络接口状态 RUNNING和LOWER_UP都表示物理网络是连通的,而网卡已经连接到交换机或者路由器
- MTU 默认是1500
- IP,掩码和MAC地址
网络收发的字节数,包数,错误数和丢包数
errors表示错误的数据包
- dropped表示丢弃的数据包,就是到达buffer但是因为内存等等原因丢弃了
- overruns表示超限的数据包,就是网络IO速度太快,到后buffer中的数据来不及处理,队列满了而导致的丢包
- carrier表示carrier错误的数据包,例如双工模式不匹配,物理电缆出问题
- collisions表示碰撞数据包数
套接字信息
# -l 表示只显示监听套接字
# -n 表示显示数字地址和端口 (而不是名字)
# -p 表示显示进程信息
$ netstat -nlp | head -n 3
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN 840/systemd-resolve
# -l 表示只显示监听套接字
# -t 表示只显示 TCP 套接字
# -n 表示显示数字地址和端口 (而不是名字)
# -p 表示显示进程信息
$ ss -ltnp | head -n 3
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 127.0.0.53%lo:53 0.0.0.0:* users:(("systemd-resolve",pid=840,fd=13))
LISTEN 0 128 0.0.0.0:22 0.0.0.0:* users:(("sshd",pid=1459,fd=3))
Recv-Q和Send-Q通常情况下应该是0
当套接字处于连接状态Established时
- Recv-Q表示套接字缓冲还没被应用程序取走的字节数(接收队列长度)
- Send-Q表示还没有被远端主机确认的字节数
当套接字处于监听状态Listening时
- Recv-Q表示syn backlog的当前值
- Send-Q表示最大的syn backlog值
syn backlog是TCP协议栈中的半连接状态队列的长度,半连接就是TCP三次握手还没有完成的连接,服务端接收到SYN包之后,将连接放到半连接队列向客户端发送SYN+ACK包,而全连接是指服务器收到了客户端的ACK之后完成了三次握手,连接会被放到全连接中的套接字,还需要被Accept()的系统调用取走,服务器才开始真正的接收请求
协议栈统计
netstat -s
...
Tcp:
3244906 active connection openings
23143 passive connection openings
115732 failed connection attempts
2964 connection resets received
1 connections established
13025010 segments received
17606946 segments sent out
44438 segments retransmitted
42 bad segments received
5315 resets sent
InCsumErrors: 42
...
$ ss -s
Total: 186 (kernel 1446)
TCP: 4 (estab 1, closed 0, orphaned 0, synrecv 0, timewait 0/0), ports 0
Transport Total IP IPv6
* 1446 - -
RAW 2 1 1
UDP 2 2 0
TCP 4 3 1
...
- ss只展示了已连接,关闭和孤儿套接字
- netstat则还有TCP协议的主动连接,被动连接,失败重试,发送和接收的分段数等信息
网络吞吐和PPS
# 数字 1 表示每隔 1 秒输出一组数据
$ sar -n DEV 1
Linux 4.15.0-1035-azure (ubuntu) 01/06/19 _x86_64_ (2 CPU)
13:21:40 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
13:21:41 eth0 18.00 20.00 5.79 4.25 0.00 0.00 0.00 0.00
13:21:41 docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
13:21:41 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
rxpck/s和txpck/s分别是接收和发送的数据包rxkB/s和txkB/s分别是接收和发送的吞吐量rxcmp/s和txcmp/s分别是接收和发送的压缩数据包数%ifutil网络接口的使用率,半双工模式下为(rxkB/s+txkB/s)/Bandwidth,而全双工模式下是max(rxkB/s, txkB/s)/Bandwidth
Bandwidth可以使用ethtool查询
$ ethtool eth0 | grep Speed
Speed: 1000Mb/s
连通性和时延
# -c3 表示发送三次 ICMP 包后停止
$ ping -c3 114.114.114.114
PING 114.114.114.114 (114.114.114.114) 56(84) bytes of data.
64 bytes from 114.114.114.114: icmp_seq=1 ttl=54 time=244 ms
64 bytes from 114.114.114.114: icmp_seq=2 ttl=47 time=244 ms
64 bytes from 114.114.114.114: icmp_seq=3 ttl=67 time=244 ms
--- 114.114.114.114 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2001ms
rtt min/avg/max/mdev = 244.023/244.070/244.105/0.034 ms
35 | 基础篇:C10K 和 C1000K 回顾
C是client的意思,C10K是单机同时处理一万个请求,而C1000k就是单机同时处理一百万个请求
C10K
- 非阻塞IO和水平通知,例如select和poll
原理是从文件描述符中找出那些可以执行IO的,然后进行网络IO的读写,但是问题就是需要对文件描述符列表进行轮询,请求多的时候就会耗时较长,并且select还受文件描述符的限制,在这个过程中需要把文件描述符集合从用户空间转移到内核空间,由内核修改之后回到用户空间,增加了时间成本
- 非阻塞IO和边缘通知,例如epoll
原理是在内核维护一个红黑树管理文件描述符的集合,并且使用事件驱动的方式,只有关注IO事件发生的文件描述符
- 异步IO
工程模型优化
第一种是一个主进程和多个worker子进程模型
- 主进程通过bind()+listen()启动后,创建多个子进程
- 子进程通过accept()或epoll_wait()来处理相同的套接字
例如nginx就是这么使用的,主进程初始化套接字,并管理子进程的生命周期,而子进程负责处理请求,不过当accept()或epoll_wait()后只有一个进程可以响应,其他进程被唤醒后重新休眠,为了避免这个惊群问题问题,nginx为每个worker增加了全局锁,worker进程需要竞争锁,然后去epoll中取数据
当然可以使用线程的方式,避免切换的消耗,甚至把epoll_wait()放入主进程,事件每次唤醒主进程,由主进程唤醒线程
第二种是监听相同端口的多进程模型
由内核取保只有一个进程被唤醒,在nginx1.9版本也开始支持该模式,不过需要linux3.9版本支持SO_REUSEPORT
C1000K
C1000K需要的系统资源
- 一个请求16KB内存,大概需要15GB内存
- 每个连接1KB/s的吞吐量,例如有20%的活跃连接,需要1.6GB的吞吐量
- 还需要大量的文件描述符,连接状态跟踪,网络协议栈的缓存,大量的中断,就需要CPU和网卡等等硬件
C10M
又翻倍硬件无法支撑就需要系统再度优化,DPDK和XDP等跳过内核协议栈,将网络数据包直接到应用程序
DPDK是用户态进程直接跳过内核协议栈,来轮询处理网络请求
如果每时每刻都有请求轮询的效率会很高,绝大多数时间都是在处理网络包,省略了硬中断和软中断,还可以通过大页,CPU绑定,内存对齐,流水线并发等机制增加
可以参考文档
XDP是linux内核提供的高效率数据路径,允许网络包在进入协议栈之前,就进行处理,基于内核的eBPF实现,需要4.8版本以上的内核
可以参考文档
36 | 套路篇:怎么评估系统的网络性能?
网络基准测试
- 对于web程序更考研的是应用层HTTP和HTTPS的性能
- 对于游戏是与client交互,更考验tcp和udp的性能
- 而如果把服务器作为路由则更考验转发的PPS的性能
转发性能
转发性能可以使用hping3进行测试,也可以使用内核自带的pktgen
在linux中没有办法找到pktgen这个命令,是以内核线程运行的,需要加载pktgen模块才能使用
$ modprobe pktgen
$ ps -ef | grep pktgen | grep -v grep
root 26384 2 0 06:17 ? 00:00:00 [kpktgend_0]
root 26385 2 0 06:17 ? 00:00:00 [kpktgend_1]
$ ls /proc/net/pktgen/
kpktgend_0 kpktgend_1 pgctrl
因为是在每个cpu都启动了一个内核线程pktgen,所以有多个,pgctrl用于控制测试的开始和结束
# 定义一个工具函数,方便后面配置各种测试选项
function pgset() {
local result
echo $1 > $PGDEV
result=`cat $PGDEV | fgrep "Result: OK:"`
if [ "$result" = "" ]; then
cat $PGDEV | fgrep Result:
fi
}
# 为0号线程绑定eth0网卡
PGDEV=/proc/net/pktgen/kpktgend_0
pgset "rem_device_all" # 清空网卡绑定
pgset "add_device eth0" # 添加eth0网卡
# 配置 eth0 网卡的测试选项
PGDEV=/proc/net/pktgen/eth0
pgset "count 1000000" # 总发包数量
pgset "delay 5000" # 不同包之间的发送延迟 (单位纳秒)
pgset "clone_skb 0" # SKB 包复制
pgset "pkt_size 64" # 网络包大小
pgset "dst 192.168.0.30" # 目的 IP
pgset "dst_mac 11:11:11:11:11:11" # 目的 MAC
# 启动测试
PGDEV=/proc/net/pktgen/pgctrl
pgset "start"
查看测试数据
cat /proc/net/pktgen/eth0
Params: count 1000000 min_pkt_size: 64 max_pkt_size: 64
frags: 0 delay: 0 clone_skb: 0 ifname: eth0
flows: 0 flowlen: 0
...
Current:
pkts-sofar: 1000000 errors: 0
started: 1534853256071us stopped: 1534861576098us idle: 70673us
...
Result: OK: 8320027(c8249354+d70673) usec, 1000000 (64byte,0frags)
120191pps 61Mb/sec (61537792bps) errors: 0
- Params测试选项
- Current测试进度,pkts-sofar表示发包数
- Result测试结果,包括测试用时,网络包数量,PPS,吞吐量和错误数
这里PPS为12W,吞吐量61Mb/s,对比千兆交换机150WPPS
TCP/UDP测试
iperf3或者netperf
# Ubuntu
apt-get install iperf3
# CentOS
yum install iperf3
目标机器启动server
# -s 表示启动服务端,-i 表示汇报间隔,-p 表示监听端口
$ iperf3 -s -i 1 -p 10000
测试机器启动client
# -c 表示启动客户端,192.168.0.30 为目标服务器的 IP
# -b 表示目标带宽 (单位是 bits/s)
# -t 表示测试时间
# -P 表示并发数,-p 表示目标服务器监听端口
$ iperf3 -c 192.168.0.30 -b 1G -t 15 -P 2 -p 10000
等待看一下测试结果
[ ID] Interval Transfer Bandwidth
...
[SUM] 0.00-15.04 sec 0.00 Bytes 0.00 bits/sec sender
[SUM] 0.00-15.04 sec 1.51 GBytes 860 Mbits/sec receiver
可以看到接收吞吐量为860Mb/s
HTTP测试
ab工具
# -c 表示并发请求数为 1000,-n 表示总的请求数为 10000
$ ab -c 1000 -n 10000 http://192.168.0.30/
...
Server Software: nginx/1.15.8
Server Hostname: 192.168.0.30
Server Port: 80
...
Requests per second: 1078.54 [#/sec] (mean)
Time per request: 927.183 [ms] (mean)
Time per request: 0.927 [ms] (mean, across all concurrent requests)
Transfer rate: 890.00 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 27 152.1 1 1038
Processing: 9 207 843.0 22 9242
Waiting: 8 207 843.0 22 9242
Total: 15 233 857.7 23 9268
Percentage of the requests served within a certain time (ms)
50% 23
66% 24
75% 24
80% 26
90% 274
95% 1195
98% 2335
99% 4663
100% 9268 (longest request)
Requests per second每秒可以处理的请求数Time per request平均延迟927ms(包括线程运行的调度时间和网络请求响应时间),0.927ms为实际响应时间Transfer rate吞吐量
应用负载性能
应用的性能更多取决于请求的类型,在实际情况下需要模拟,可以使用wrk和TCPCopy、Jmeter或者LoadRunner
$ https://github.com/wg/wrk
$ cd wrk
$ apt-get install build-essential -y
$ make
$ sudo cp wrk /usr/local/bin/
使用
# -c 表示并发连接数 1000,-t 表示线程数为 2
$ wrk -c 1000 -t 2 http://192.168.0.30/
Running 10s test @ http://192.168.0.30/
2 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 65.83ms 174.06ms 1.99s 95.85%
Req/Sec 4.87k 628.73 6.78k 69.00%
96954 requests in 10.06s, 78.59MB read
Socket errors: connect 0, read 0, write 0, timeout 179
Requests/sec: 9641.31
Transfer/sec: 7.82MB
wrk内置了luaJIT,可以模拟复杂的性能测试,wrk调用的lua脚本的流程
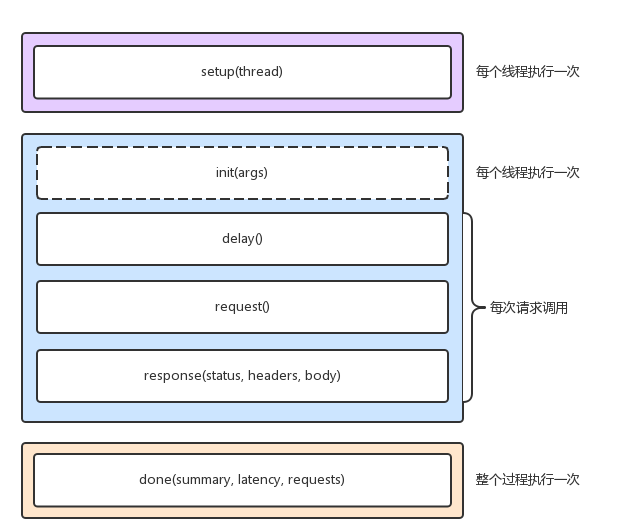
可以在setup的时候设置认证参数,参考官方示例
-- example script that demonstrates response handling and
-- retrieving an authentication token to set on all future
-- requests
token = nil
path = "/authenticate"
request = function()
return wrk.format("GET", path)
end
response = function(status, headers, body)
if not token and status == 200 then
token = headers["X-Token"]
path = "/resource"
wrk.headers["X-Token"] = token
end
end
使用脚本进行测试
$ wrk -c 1000 -t 2 -s auth.lua http://192.168.0.30/
37 | 案例篇:DNS 解析时快时慢,我该怎么办?
dig和nslookup是一个递归的过程,但是dig可以看到详细的解析过程
# +trace 表示开启跟踪查询
# +nodnssec 表示禁止 DNS 安全扩展
$ dig +trace +nodnssec time.geekbang.org
; <<>> DiG 9.11.3-1ubuntu1.3-Ubuntu <<>> +trace +nodnssec time.geekbang.org
;; global options: +cmd
. 322086 IN NS m.root-servers.net.
. 322086 IN NS a.root-servers.net.
. 322086 IN NS i.root-servers.net.
. 322086 IN NS d.root-servers.net.
. 322086 IN NS g.root-servers.net.
. 322086 IN NS l.root-servers.net.
. 322086 IN NS c.root-servers.net.
. 322086 IN NS b.root-servers.net.
. 322086 IN NS h.root-servers.net.
. 322086 IN NS e.root-servers.net.
. 322086 IN NS k.root-servers.net.
. 322086 IN NS j.root-servers.net.
. 322086 IN NS f.root-servers.net.
;; Received 239 bytes from 114.114.114.114#53(114.114.114.114) in 1340 ms
org. 172800 IN NS a0.org.afilias-nst.info.
org. 172800 IN NS a2.org.afilias-nst.info.
org. 172800 IN NS b0.org.afilias-nst.org.
org. 172800 IN NS b2.org.afilias-nst.org.
org. 172800 IN NS c0.org.afilias-nst.info.
org. 172800 IN NS d0.org.afilias-nst.org.
;; Received 448 bytes from 198.97.190.53#53(h.root-servers.net) in 708 ms
geekbang.org. 86400 IN NS dns9.hichina.com.
geekbang.org. 86400 IN NS dns10.hichina.com.
;; Received 96 bytes from 199.19.54.1#53(b0.org.afilias-nst.org) in 1833 ms
time.geekbang.org. 600 IN A 39.106.233.176
;; Received 62 bytes from 140.205.41.16#53(dns10.hichina.com) in 4 ms
对于
/# nslookup time.geekbang.org
;; connection timed out; no servers could be reached
/# nslookup -debug time.geekbang.org
;; Connection to 127.0.0.1#53(127.0.0.1) for time.geekbang.org failed: connection refused.
;; Connection to ::1#53(::1) for time.geekbang.org failed: address not available.
这种报错是没有在resolv.conf中配置dns服务器
对于解析时间较长的可以启动dnsmasq用来缓存dns,然后将resolv.conf中的监听地址设置为127.0.0.1
/# /etc/init.d/dnsmasq start
* Starting DNS forwarder and DHCP server dnsmasq [ OK ]
DNS的优化有多种
- DNS缓存
- DNS解析结果预存
- HTTPDNS
- DNS负载均衡(GSLB)
38 | 案例篇:怎么使用 tcpdump 和 Wireshark 分析网络流量?
$ yum install -y tcpdump
windows手动安装Wireshark,链接
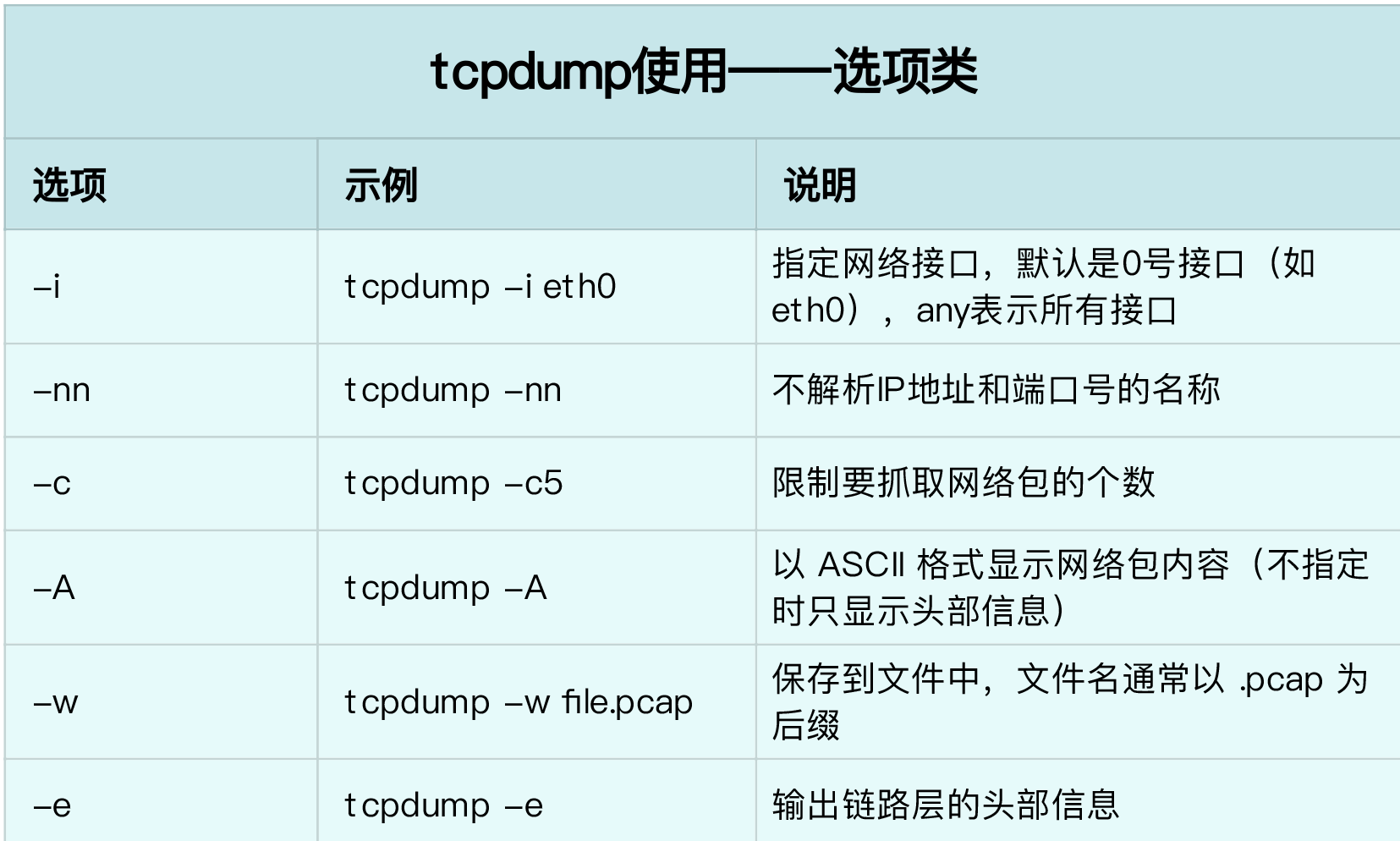
tcpdump
# 禁止接收从 DNS 服务器发送过来并包含 googleusercontent 的包
$ iptables -I INPUT -p udp --sport 53 -m string --string googleusercontent --algo bm -j DROP
配置dns为114.114.114.114
# ping 3 次(默认每次发送间隔 1 秒)
$ ping -c3 geektime.org
PING geektime.org (35.190.27.188) 56(84) bytes of data.
64 bytes from 35.190.27.188 (35.190.27.188): icmp_seq=1 ttl=43 time=36.8 ms
64 bytes from 35.190.27.188 (35.190.27.188): icmp_seq=2 ttl=43 time=31.1 ms
64 bytes from 35.190.27.188 (35.190.27.188): icmp_seq=3 ttl=43 time=31.2 ms
--- geektime.org ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 11049ms
rtt min/avg/max/mdev = 31.146/33.074/36.809/2.649 ms
可以看到总耗时11s?
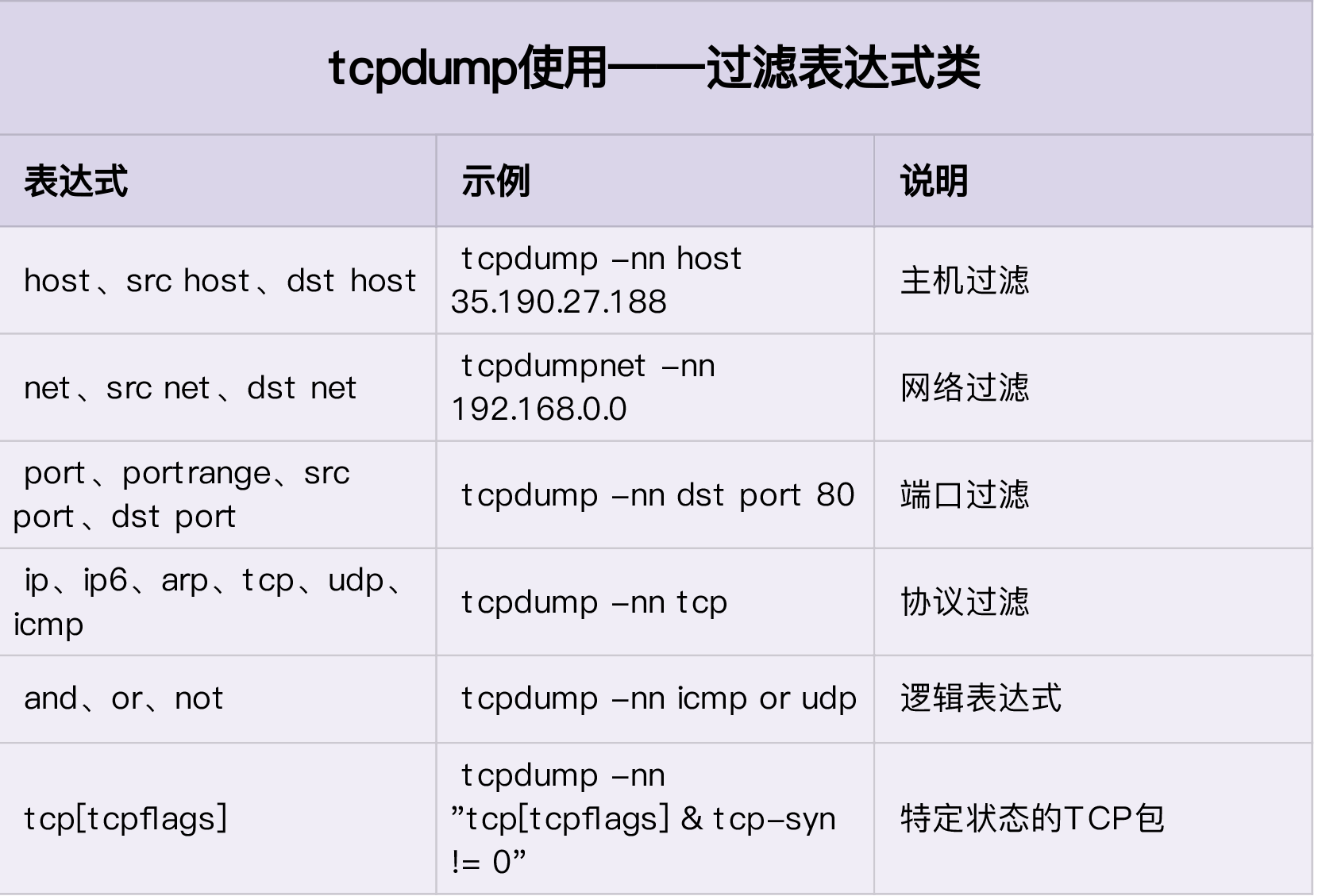
tcpdump -nn udp port 53 or host 35.190.27.188
然后再执行ping查看输出
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
14:02:31.100564 IP 172.16.3.4.56669 > 114.114.114.114.53: 36909+ A? geektime.org. (30)
14:02:31.507699 IP 114.114.114.114.53 > 172.16.3.4.56669: 36909 1/0/0 A 35.190.27.188 (46)
14:02:31.508164 IP 172.16.3.4 > 35.190.27.188: ICMP echo request, id 4356, seq 1, length 64
14:02:31.539667 IP 35.190.27.188 > 172.16.3.4: ICMP echo reply, id 4356, seq 1, length 64
14:02:31.539995 IP 172.16.3.4.60254 > 114.114.114.114.53: 49932+ PTR? 188.27.190.35.in-addr.arpa. (44)
14:02:36.545104 IP 172.16.3.4.60254 > 114.114.114.114.53: 49932+ PTR? 188.27.190.35.in-addr.arpa. (44)
14:02:41.551284 IP 172.16.3.4 > 35.190.27.188: ICMP echo request, id 4356, seq 2, length 64
14:02:41.582363 IP 35.190.27.188 > 172.16.3.4: ICMP echo reply, id 4356, seq 2, length 64
14:02:42.552506 IP 172.16.3.4 > 35.190.27.188: ICMP echo request, id 4356, seq 3, length 64
14:02:42.583646 IP 35.190.27.188 > 172.16.3.4: ICMP echo reply, id 4356, seq 3, length 64
可以看到进行了两次PTR反向域名解析
ping -n -c3 geektime.org
PING geektime.org (35.190.27.188) 56(84) bytes of data.
64 bytes from 35.190.27.188: icmp_seq=1 ttl=43 time=33.5 ms
64 bytes from 35.190.27.188: icmp_seq=2 ttl=43 time=39.0 ms
64 bytes from 35.190.27.188: icmp_seq=3 ttl=43 time=32.8 ms
--- geektime.org ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 32.879/35.160/39.030/2.755 ms
iptable规则就是干掉了PTR解析
$ nslookup -type=PTR 35.190.27.188 8.8.8.8
Server: 8.8.8.8
Address: 8.8.8.8#53
Non-authoritative answer:
188.27.190.35.in-addr.arpa name = 188.27.190.35.bc.googleusercontent.com.
Authoritative answers can be found from:
恢复一下
iptables -D INPUT -p udp --sport 53 -m string --string googleusercontent --algo bm -j DROP
tcpdump基于libpcap,利用内核的AF_PACKET关键字,抓取网络接口中传输的网络包并提供过滤规则,参考RFC
wireshark
$ dig +short example.com
93.184.216.34
$ tcpdump -nn host 93.184.216.34 -w web.pcap
然后
$ curl http://example.com
使用wireshark打开

选择Statistics -> Flow Graph,在Flow type选择TCP FLOWS可以看到TCP的流,如果网络包多可以选择一个包之后选择Follow -> TCP Stream
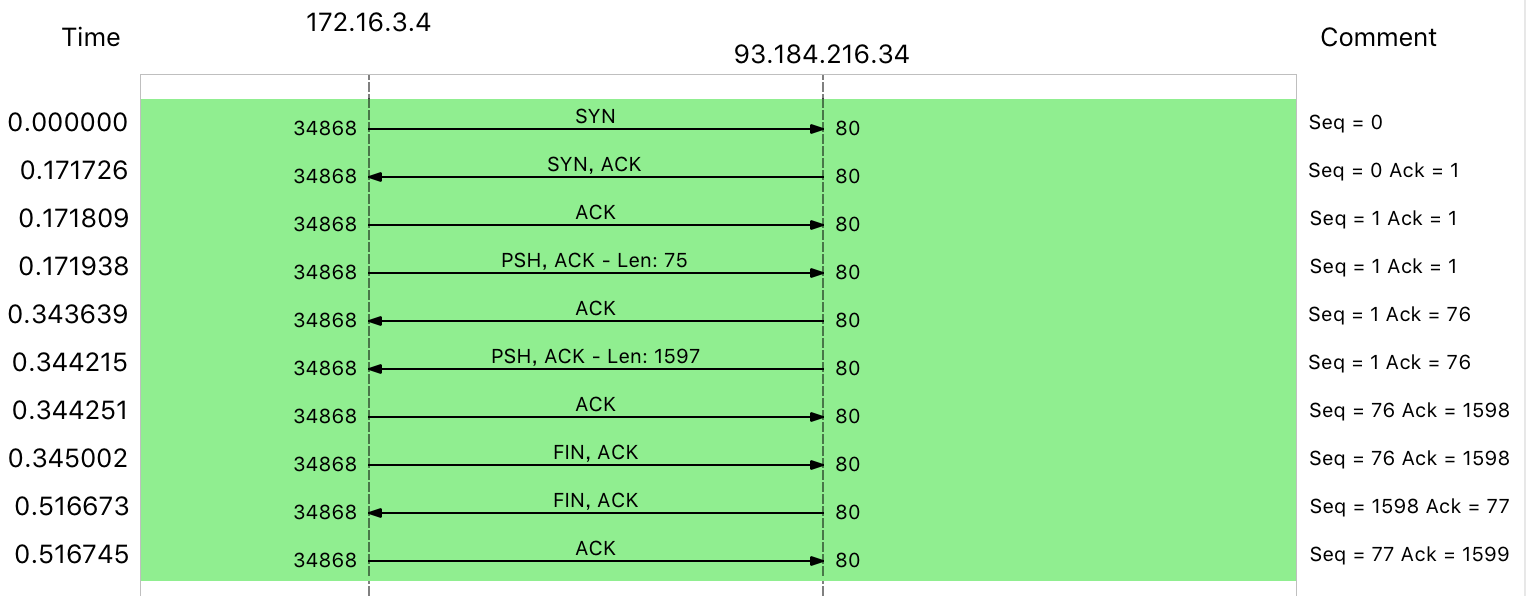
这边挥手只有三个包,是因为ACK和FIN合并了
39 | 案例篇:怎么缓解 DDoS 攻击带来的性能下降问题?
DDos有几种
- 耗尽带宽
- 耗尽操作系统资源
- 耗尽应用程序的资源
# -S 参数表示设置 TCP 协议的 SYN(同步序列号),-p 表示目的端口为 80
# -i u10 表示每隔 10 微秒发送一个网络帧
$ hping3 -S -p 80 -i u10 192.168.0.30
如果不明显可以改为u1
模拟正常请求
# --connect-timeout 表示连接超时时间
$ curl -w 'Http code: %{http_code}\nTotal time:%{time_total}s\n' -o /dev/null --connect-timeout 10 http://192.168.0.30
...
Http code: 000
Total time:10.001s
curl: (28) Connection timed out after 10000 milliseconds
然后进行抓包
# -i eth0 只抓取 eth0 网卡,-n 不解析协议名和主机名
# tcp port 80 表示只抓取 tcp 协议并且端口号为 80 的网络帧
$ tcpdump -i eth0 -n tcp port 80
09:15:48.287047 IP 192.168.0.2.27095 > 192.168.0.30: Flags [S], seq 1288268370, win 512, length 0
09:15:48.287050 IP 192.168.0.2.27131 > 192.168.0.30: Flags [S], seq 2084255254, win 512, length 0
09:15:48.287052 IP 192.168.0.2.27116 > 192.168.0.30: Flags [S], seq 677393791, win 512, length 0
09:15:48.287055 IP 192.168.0.2.27141 > 192.168.0.30: Flags [S], seq 1276451587, win 512, length 0
09:15:48.287068 IP 192.168.0.2.27154 > 192.168.0.30: Flags [S], seq 1851495339, win 512, length 0
...

server端会等待client最后的ACK包直到超时,会将连接表迅速占满,无法建立新的TCP连接
# -n 表示不解析名字,-p 表示显示连接所属进程
$ netstat -n -p | grep SYN_REC
tcp 0 0 192.168.0.30:80 192.168.0.2:12503 SYN_RECV -
tcp 0 0 192.168.0.30:80 192.168.0.2:13502 SYN_RECV -
tcp 0 0 192.168.0.30:80 192.168.0.2:15256 SYN_RECV -
tcp 0 0 192.168.0.30:80 192.168.0.2:18117 SYN_RECV -
...
$ netstat -n -p | grep SYN_REC | wc -l
193
# 禁掉IP
$ iptables -I INPUT -s 192.168.0.2 -p tcp -j REJECT
当然hping3支持--rand-source来变化源IP,可能需要以下操作
# 限制 syn 并发数为每秒 1 次
$ iptables -A INPUT -p tcp --syn -m limit --limit 1/s -j ACCEPT
# 限制单个 IP 在 60 秒新建立的连接数为 10
$ iptables -I INPUT -p tcp --dport 80 --syn -m recent --name SYN_FLOOD --update --seconds 60 --hitcount 10 -j REJECT
修改半连接队列
$ sysctl -w net.ipv4.tcp_max_syn_backlog=1024
net.ipv4.tcp_max_syn_backlog = 1024
SYNC重试默认为5次,改为1次
$ sysctl -w net.ipv4.tcp_synack_retries=1
net.ipv4.tcp_synack_retries = 1
TCP SYNC Cookies,这样通过cookie来判断连接,就不需要维护半开连接,也就不会放置在半连接队列,但是net.ipv4.tcp_max_syn_backlog也会无效
$ sysctl -w net.ipv4.tcp_syncookies=1
net.ipv4.tcp_syncookies = 1
40 | 案例篇:网络请求延迟变大了,我该怎么办?
网络请求延迟主要分两部分,网络延迟和应用程序延迟
$ docker run --network=host --name=good -itd nginx
fb4ed7cb9177d10e270f8320a7fb64717eac3451114c9fab3c50e02be2e88ba2
$ docker run --name nginx --network=host -itd feisky/nginx:latency
b99bd136dcfd907747d9c803fdc0255e578bad6d66f4e9c32b826d75b6812724
启动两个不同的docker容器,分别是80和8080端口
# 测试 80 端口性能
$ # wrk --latency -c 100 -t 2 --timeout 2 http://192.168.0.30/
Running 10s test @ http://192.168.0.30/
2 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 9.19ms 12.32ms 319.61ms 97.80%
Req/Sec 6.20k 426.80 8.25k 85.50%
Latency Distribution
50% 7.78ms
75% 8.22ms
90% 9.14ms
99% 50.53ms
123558 requests in 10.01s, 100.15MB read
Requests/sec: 12340.91
Transfer/sec: 10.00MB
# 测试 8080 端口性能
$ wrk --latency -c 100 -t 2 --timeout 2 http://192.168.0.30:8080/
Running 10s test @ http://192.168.0.30:8080/
2 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 43.60ms 6.41ms 56.58ms 97.06%
Req/Sec 1.15k 120.29 1.92k 88.50%
Latency Distribution
50% 44.02ms
75% 44.33ms
90% 47.62ms
99% 48.88ms
22853 requests in 10.01s, 18.55MB read
Requests/sec: 2283.31
Transfer/sec: 1.85MB
可以看到8080端口的50%的请求都在40ms以上
进行一下抓包
$ tcpdump -nn tcp port 8080 -w nginx.pcap
另一终端请求
# 测试 8080 端口性能
$ wrk --latency -c 100 -t 2 --timeout 2 http://192.168.0.30:8080/
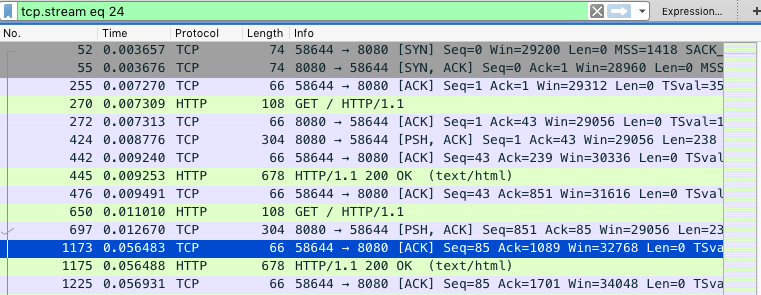
在wireshark中打开并选择一个包“Follow” -> “TCP Stream”,wireshark会自行设置一个表达式tcp.stream eq 24
在菜单栏点击Statics -> Flow Graph,然后选中“Limit to display filter” 并设置Flow type 为 “TCP Flows”
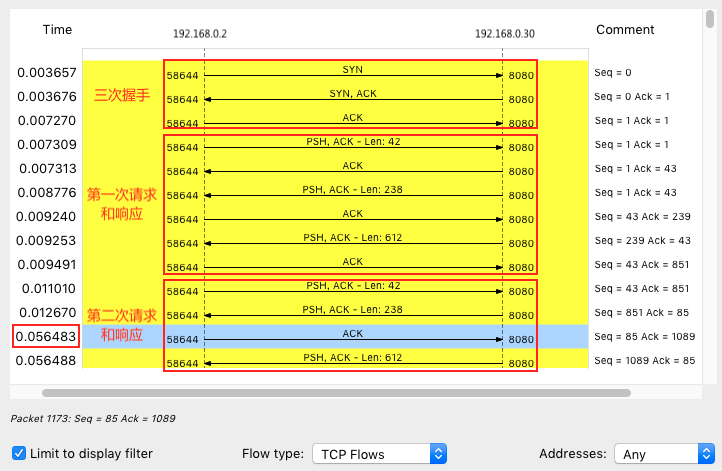
可以看到三次握手,第一次HTTP请求还是很快的,但是第二次HTTP请求就很慢,40ms之后才发出了ACK响应,蓝色行
这40ms正是TCP延迟确认(Delayed ACK)的最小时间,TCP延迟确认是一种优化机制,不是每次请求都发送一个ACK包,而是等一会,确认一下是否有顺风车,如果这段时间内有其他包要发送就捎带把ACK包发送过去,如果没有就在超时后单独发送ACK。
这是client开启了延迟确认,可以man tcp,看tcp的套接字设置TCP_QUICKACK才是开启快速确认模式,否则默认是延迟模式
TCP_QUICKACK (since Linux 2.4.4)
Enable quickack mode if set or disable quickack mode if cleared. In quickack mode, acks are sent imme‐
diately, rather than delayed if needed in accordance to normal TCP operation. This flag is not perma‐
nent, it only enables a switch to or from quickack mode. Subsequent operation of the TCP protocol will
once again enter/leave quickack mode depending on internal protocol processing and factors such as
delayed ack timeouts occurring and data transfer. This option should not be used in code intended to be
portable.
用strace确认一下
strace -f wrk --latency -c 100 -t 2 --timeout 2 http://192.168.0.30:8080/
...
setsockopt(52, SOL_TCP, TCP_NODELAY, [1], 4) = 0
...
可以看到没有开启快速确认
但是也可以看到第二次请求的时候,1173是延迟包,1175是nginx的第二个分组包,和697号包组合是一个完整的HTTP数据包,不过发送数据不需要等第一个包ACK之后才发送数据,这是Nagle算法,减少小包发送数量的优化算法,目的是提高带宽的利用率
举个栗子,有效数据只有一个字节,TCP+IP头就是40字节,数据包就是41字节,利用只有1/41,Nagle算法就是解决这个问题的,合并TCP小包,但是Nagle需要TCP连接上只有未被确认完成的分组,在收到这个分组
当Nagle和TCP延迟确认在一起的时候网络延迟就会明显了
需要在nginx中将tcp_nodelay off;设置为on
41 | 案例篇:如何优化 NAT 性能?(上)
NAT原理
NAT技术重写数据包的源地址或者目的地址
NAT可以在Linux系统实现也可以在支持NAT的路由器上
NAT分为三类
- 静态NAT,内网IP和外网IP做一对一映射
- 动态NAT,内网IP从外网IP池中,选择一个进行映射
- 网络地址端口转换,即NAPT,让内网IP通过不同的端口使用相同的公网
NAPT又分为
- 源地址转换SNAT
- 目的地址转换DNAT
- 网络地址转换
linux的NAT通过iptables的NAT表
- PREROUTING,用于路由判断前所执行的规则,比如,对接收数据包之前进行DNAT
- POSTROUTING,用于路由判断后所执行的规则,比如,对对发送或转发的数据包进行 SNAT 或 MASQUERADE...
- OUTPUT,类似于 PREROUTING,但只处理从本机发送
SNAT
为一个子网配置SNAT
$ iptables -t nat -A POSTROUTING -s 192.168.0.0/16 -j MASQUERADE
为一个IP地址配置SNAT并制定转换后的源地址
$ iptables -t nat -A POSTROUTING -s 192.168.0.2 -j SNAT --to-source 100.100.100.100
DNAT
$ iptables -t nat -A PREROUTING -d 100.100.100.100 -j DNAT --to-destination 192.168.0.2
对于本机发出的包也可以配置在OUTPUT
双向地址转换
$ iptables -t nat -A POSTROUTING -s 192.168.0.2 -j SNAT --to-source 100.100.100.100
$ iptables -t nat -A PREROUTING -d 100.100.100.100 -j DNAT --to-destination 192.168.0.2
以上操作都需要开启IP转发
$ sysctl -w net.ipv4.ip_forward=1
net.ipv4.ip_forward = 1
42 | 案例篇:如何优化 NAT 性能?(下)
安装需要的软件
# CentOS
$ curl -fsSL https://get.docker.com | sh
$ yum install -y tcpdump curl httpd-tools systemtap kernel-devel yum-utils kernel
$ stab-prep
systemtap是linux的一个动态追踪框架,把脚本转化为内核模块来执行,用于监视和追踪内核的行为
启动测试容器
$ docker run --name nginx-hostnet --privileged --network=host -itd feisky/nginx:80
确认服务启动
curl http://192.168.0.30/
...
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
进行ab测试
# 临时增大当前会话的最大文件描述符数
$ ulimit -n 65536
# -c 表示并发请求数为 5000,-n 表示总的请求数为 10 万
# -r 表示套接字接收错误时仍然继续执行,-s 表示设置每个请求的超时时间为 2s
$ ab -c 5000 -n 100000 -r -s 2 http://192.168.0.30/
...
Requests per second: 6576.21 [#/sec] (mean)
Time per request: 760.317 [ms] (mean)
Time per request: 0.152 [ms] (mean, across all concurrent requests)
Transfer rate: 5390.19 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 177 714.3 9 7338
Processing: 0 27 39.8 19 961
Waiting: 0 23 39.5 16 951
Total: 1 204 716.3 28 7349
...
- 每秒请求数(Requests per second)为6576
- 每个请求的平均延迟(Time per request)为 760ms
- 建立连接的平均延迟(Connect)为 177ms
再启动一个
docker run --name nginx --privileged -p 8080:8080 -itd feisky/nginx:nat
这种端口映射就是走的NAT方式
# -c 表示并发请求数为 5000,-n 表示总的请求数为 10 万
# -r 表示套接字接收错误时仍然继续执行,-s 表示设置每个请求的超时时间为 2s
$ ab -c 5000 -n 100000 -r -s 2 http://192.168.0.30:8080/
...
apr_pollset_poll: The timeout specified has expired (70007)
Total of 5602 requests completed
这时每秒的请求为2s,只完成了5602个请求
增加超时时间,改为10000个
ab -c 5000 -n 10000 -r -s 30 http://192.168.0.30:8080/
...
Requests per second: 76.47 [#/sec] (mean)
Time per request: 65380.868 [ms] (mean)
Time per request: 13.076 [ms] (mean, across all concurrent requests)
Transfer rate: 44.79 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 1300 5578.0 1 65184
Processing: 0 37916 59283.2 1 130682
Waiting: 0 2 8.7 1 414
Total: 1 39216 58711.6 1021 130682
...
- 每秒请求数(Requests per second)为 76
- 每个请求的延迟(Time per request)为 65s
- 建立连接的延迟(Connect)为 1300ms
问题出现在两个位置
- Netfilter中的钩子函数修改数据包
- 连接追踪模块conntrack关联每一个连接的请求和响应
创建stap脚本
#! /usr/bin/env stap
############################################################
# Dropwatch.stp
# Author: Neil Horman <nhorman@redhat.com>
# An example script to mimic the behavior of the dropwatch utility
# http://fedorahosted.org/dropwatch
############################################################
# Array to hold the list of drop points we find
global locations
# Note when we turn the monitor on and off
probe begin { printf("Monitoring for dropped packets\n") }
probe end { printf("Stopping dropped packet monitor\n") }
# increment a drop counter for every location we drop at
probe kernel.trace("kfree_skb") { locations[$location] <<< 1 }
# Every 5 seconds report our drop locations
probe timer.sec(5)
{
printf("\n")
foreach (l in locations-) {
printf("%d packets dropped at %s\n",
@count(locations[l]), symname(l))
}
delete locations
}
运行
$ stap --all-modules dropwatch.stp
Monitoring for dropped packets
另一终端测试
$ ab -c 5000 -n 10000 -r -s 30 http://192.168.0.30:8080/
脚本会跟踪kfree_skb()的调用,并统计丢包位置
10031 packets dropped at nf_hook_slow
676 packets dropped at tcp_v4_rcv
7284 packets dropped at nf_hook_slow
268 packets dropped at tcp_v4_rcv
大部分的包都丢在了nf_hook_slow
再用perf
# 记录一会(比如 30s)后按 Ctrl+C 结束
$ perf record -a -g -- sleep 30
# 输出报告
$ perf report -g graph,0
输入/,在弹出的对话框输入nf_hook_slow再展开调用栈
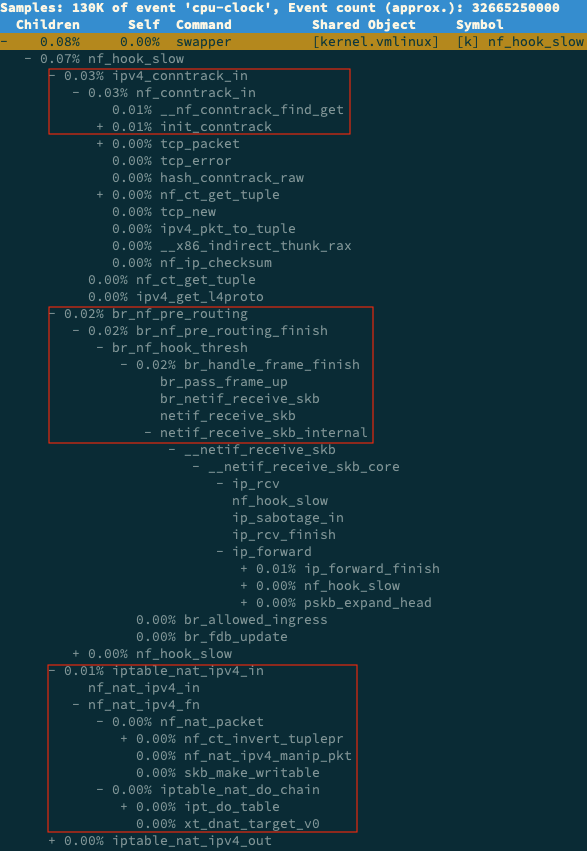
可以看到三个阶段涉及
ipv4_conntrack_in接收网络包,在连接跟踪表查找连接,对为新的连接分配跟踪对象br_nf_pre_routingLinux网桥中转发包,因为是容器所以是网桥iptable_nat_ipv4_in接收网络包执行DNAT,将8080端口收到的包发往容器
查看conntrack配置
$ sysctl -a | grep conntrack
net.netfilter.nf_conntrack_count = 180
net.netfilter.nf_conntrack_max = 1000
net.netfilter.nf_conntrack_buckets = 65536
net.netfilter.nf_conntrack_tcp_timeout_syn_recv = 60
net.netfilter.nf_conntrack_tcp_timeout_syn_sent = 120
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120
...
net.netfilter.nf_conntrack_count当前连接跟踪数net.netfilter.nf_conntrack_max最大连接跟踪数net.netfilter.nf_conntrack_buckets连接跟踪表大小
内核中会有报错
$ dmesg | tail
[104235.156774] nf_conntrack: nf_conntrack: table full, dropping packet
[104243.800401] net_ratelimit: 3939 callbacks suppressed
[104243.800401] nf_conntrack: nf_conntrack: table full, dropping packet
[104262.962157] nf_conntrack: nf_conntrack: table full, dropping packet
nf_conntrack: table full就是nf_conntrack_max太小了
conntrack也可以查看连接追踪表
# -L 表示列表,-o 表示以扩展格式显示
$ conntrack -L -o extended | head
ipv4 2 tcp 6 7 TIME_WAIT src=192.168.0.2 dst=192.168.0.96 sport=51744 dport=8080 src=172.17.0.2 dst=192.168.0.2 sport=8080 dport=51744 [ASSURED] mark=0 use=1
ipv4 2 tcp 6 6 TIME_WAIT src=192.168.0.2 dst=192.168.0.96 sport=51524 dport=8080 src=172.17.0.2 dst=192.168.0.2 sport=8080 dport=51524 [ASSURED] mark=0 use=1
示例
# 统计总的连接跟踪数
$ conntrack -L -o extended | wc -l
14289
# 统计 TCP 协议各个状态的连接跟踪数
$ conntrack -L -o extended | awk '/^.*tcp.*$/ {sum[$6]++} END {for(i in sum) print i, sum[i]}'
SYN_RECV 4
CLOSE_WAIT 9
ESTABLISHED 2877
FIN_WAIT 3
SYN_SENT 2113
TIME_WAIT 9283
# 统计各个源 IP 的连接跟踪数
$ conntrack -L -o extended | awk '{print $7}' | cut -d "=" -f 2 | sort | uniq -c | sort -nr | head -n 10
14116 192.168.0.2
172 192.168.0.96
43 | 套路篇:网络性能优化的几个思路(上)
网络性能测试
基准测试可以分层测试,底层决定高层的性能
- 网络层负责网络包的封包和解包,寻址,路由,发送和接受,每秒处理的包数量PPS为重要的指标,尤其是在小包情况下,可以用内核的pktgen
- 传输层负责网络传输,吞吐量BPS,连接数,延迟等为重要指标,可以用iperf或者netperf
- 应用层就需要wrk或者ab来进行测试了,关注吞吐量,每秒请求数
测试的时候尽量模拟生产场景
网络性能优化
应用程序
- 网络IO层面使用IO多路复用epoll
- 进程工作模型,一个主进程负责网络连接子进程处理业务或者多个进程监听相同的网络端口的多进程模型
其他方面
- 使用长连接,降低TCP连接成本
- 使用内存缓存长期不变的数据,降低网络开销
- 使用Protocol Buffer序列化数据
- 缓存DNS,禁用ipv6等减少解析耗时
套接字
每个套接字都有一个读写缓冲区
- 读缓冲区 缓存远端发送来的数据,如果读缓冲区已满,就不能再接收新的数据
- 写缓冲区 缓存要发送远端的数据,如果写缓冲区已满,应用程序的写操作会被堵塞
调整相关参数
- 每个套接字的缓冲区
net.core.optmem_max - 每个套接字的接收缓冲区
net.core.rmem_max和发送缓冲区net.core.wmem_max - TCP的接收缓冲区大小
net.ipv4.tcp_rmem和发送缓冲区大小net.ipv4.tcp_wmem
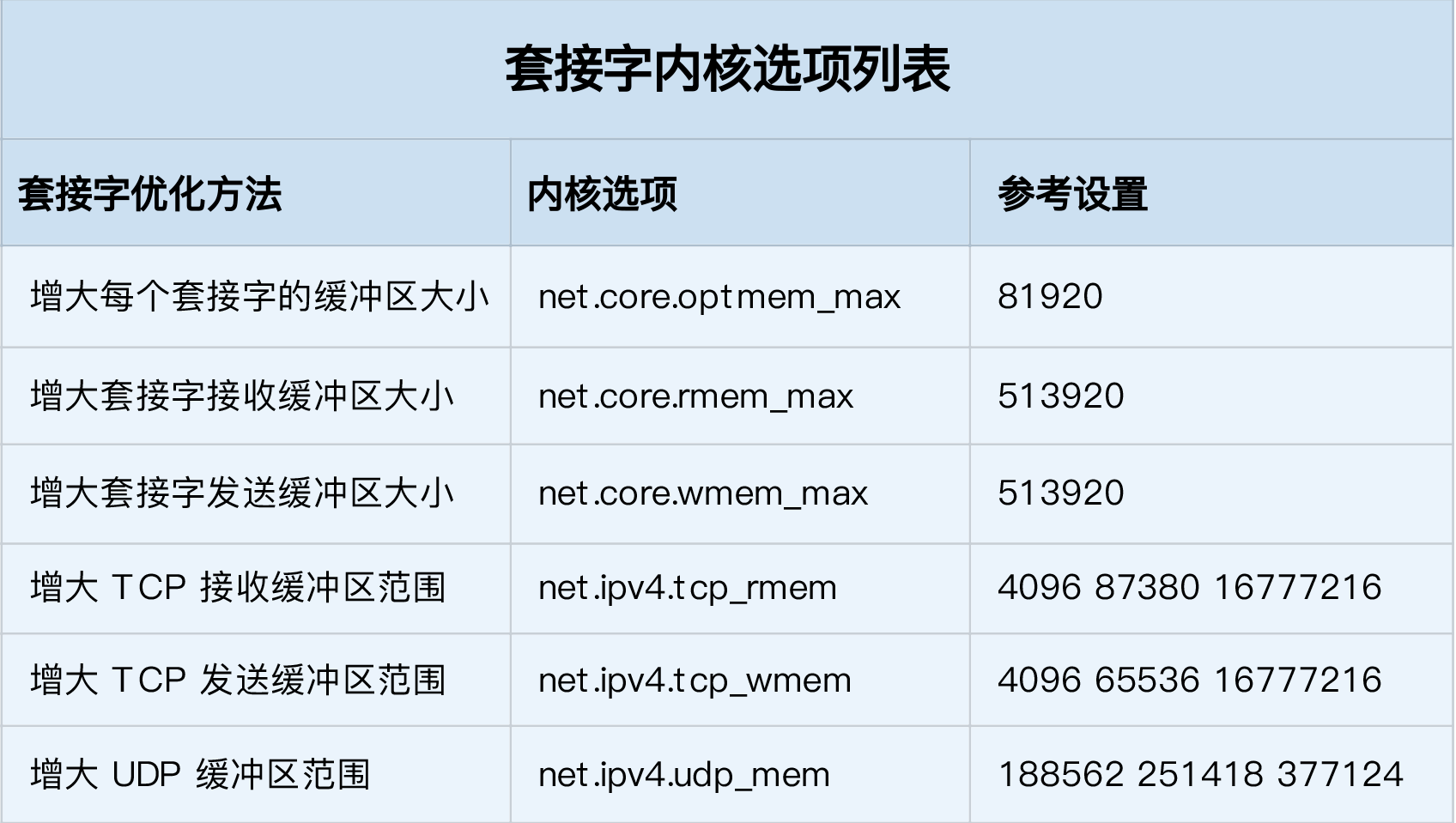
tcp_rmem和tcp_wmem的三个数值为min,default和max,系统会根据这些设置,自动调整TCP接收/发送缓冲区的大小
实际情况需要根据网络情况设置,应该为吞吐量*延迟
还有套接字选项
- TCP_NODELY可以禁用Nagle算法
- TCP_CORK开启可以将小包合并为大包发送,但是会阻塞小包发送
传输层
TCP分多种情况
第一种在请求较大的场景会看到大量处于TIME_WAIT状态的连接,占用大量的内存和端口资源
- 增大
TIME_WAIT状态的连接数量net.ipv4.tcp_max_tw_bucket - 增大连接跟踪表数量
net.netfilter.nf_conntrack_max - 减少
net.ipv4.tcp_fin_timeout和net.netfilter.nf_conntrack_tcp_timeout_time_wait - 开启端口复用
net.ipv4.tcp_tw_reuse - 增大本地端口范围
net.ipv4.ip_local_port_range - 增大进程和系统最大文件描述符数量
fs.nr_open和fs.file-max
第二种SYN攻击
- 增大TCP半连接的最大数量
net.ipv4.tcp_max_syn_backlog - 开启SYN Cookies
net.ipv4.tcp_syncookies(不能和第一条混用) - 减少
SYN_RECV状态连接重传SYN+ACK包的次数net.ipv4.tcp_synack_retries
第三种长连接场景
- 缩短最后一次数据包到keepalive探测包的间隔时间
net.ipv4.tcp_keepalive_time - 缩短发送keepalive探测包的间隔时间
net.ipv4.tcp_keepalive_intvl - 减少探测失败后的重试次数
net.ipv4.tcp_keepalive_probes

UDP相对简单
- 增加缓冲区大小,UDP缓冲区范围
- 增大本地端口范围
- 增大MTU防止UDP分片
网络层
路由和转发
- 开启转发
net.ipv4.ip_forward = 1 - 减少数据包的生存周期TTL,
net.ipv4.ip_default_ttl = 64 - 开启数据包反向地址校验
net.ipv4.conf.eth0.rp_filter = 1防止DDos
分片
- MTU通常以以太网的标准设置,以太网一个网络帧为1518B,去掉以太网头就是1500B,剩余的就是以太网MTU的大小,但是对于使用VXLAN或者GRE网络技术的时候,叠加会使网络包变大,所以MTU也需要调整,VXLAN在原来的报文基础上,增加了14B的以太网头部,8B的VXLAN头,8B的UDP头和20B的IP头,就是增加了50B,这时候路由器交换机的MTU都需要增大为1550,或者调整虚拟化环境为1450
ICMP
- 禁止ICMP
net.ipv4.icmp_echo_ignore_all = 1 - 禁止广播ICMP
net.ipv4.icmp_echo_ignore_broadcasts = 1
链路层
链路层负责网络包在物理网络传输,错误侦测和网卡传输
网卡收包软中断
- 为网卡硬中断配置CPU亲和性,或者开启irqbalance服务
- 开启RPS(Receive Packet Steering)和RFS(Receive Flow Steering)将应用程序和软中断调度到同一个CPU,提高CPU缓存的命中率,减少网络延迟
内核中的部分功能也可以放到物理网卡
- TSO(TCP Segmentation Offload)和UFO(UDP Fragmentation Offload),在TCP/UDP协议中直接发送大包,而TCP分段(按照MSS分段)和UDP分片(按照MTU分片)都是由网卡完成
- GSO(Generic Segmentation Offload)在网卡不支持TSO/UFO的时候,将TCP/UDP包的分段,延迟到进入网卡前再执行。这样,不仅可以减少CPU的消耗,还可以在发生丢包时只重传分段后的包。
- LRO(Large Receive Offload):在接收TCP分段包时,由网卡将其组装合并后,再交给上层网络处理。不过要注意,在需要IP转发的情况下,不能开启 LRO,因为如果多个包的头部信息不一致,LRO合并会导致网络包的校验错误。
- GRO(Generic Receive Offload):GRO修复了LRO的缺陷,并且更为通用,同时支持TCP和UDP。
- RSS(Receive Side Scaling):也称为多队列接收,它基于硬件的多个接收队列,来分配网络接收进程,这样可以让多个CPU来处理接收进程,这样可以让多个CPU来处理接收到的网络包。
- VXLAN 卸载:也就是让网卡来完成VXLAN的组包功能。

