

极客时间专栏——linux性能优化实战——文件系统部分
目录:
23 | 基础篇:Linux 文件系统是怎么工作的?
- 磁盘为系统提供持久化存储
- 文件系统则在磁盘的基础上提供了用来管理文件的树状结构
文件系统
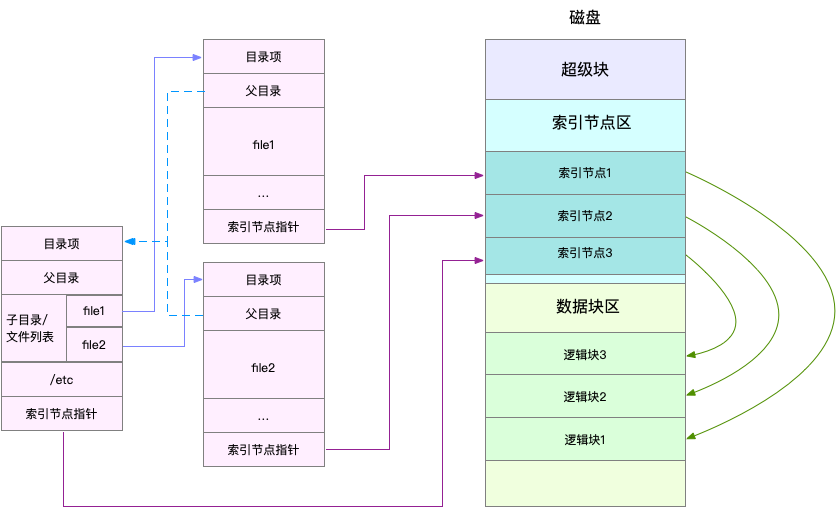
Linux文件系统的每个文件都被分配了索引节点和目录项,分别用于记录元数据信息和目录结构
索引节点就是常说的Inode,用于记录元数据,包括inode编号,文件大小,访问权限,修改日期,数据的位置,和文件是一一对应关系,也会持久化存储到磁盘
目录项为dentry,用于记录文件的名字,索引节点的指针,和其他目录项的关联关系。多级个关联的目录项就构成了目录结构,目录项是由内核维护的数据结构
对于磁盘,读写的最小单位为扇区,每个扇区512B,这样读写效率很低,文件系统将连续的扇区组成逻辑块,每次以逻辑块为最小单元,来管理数据
需要注意的点
- 目录项本事就是缓存,为了协调快速的CPU和慢速的磁盘,文件内容需要缓存到页缓存的Cache中
- 磁盘在进行初始化的时候分成了三个存储区域,超级块,索引节点区和数据节点区,超级块主要的目的就是存储整个文件系统的状态
虚拟文件系统
用户进程和文件系统中间加入了虚拟文件系统VFS
VFS定义了一组所有文件系统的都支持的数据结构和标准接口,用户进程只需要通过这个VFS的统一接口进行交互即可
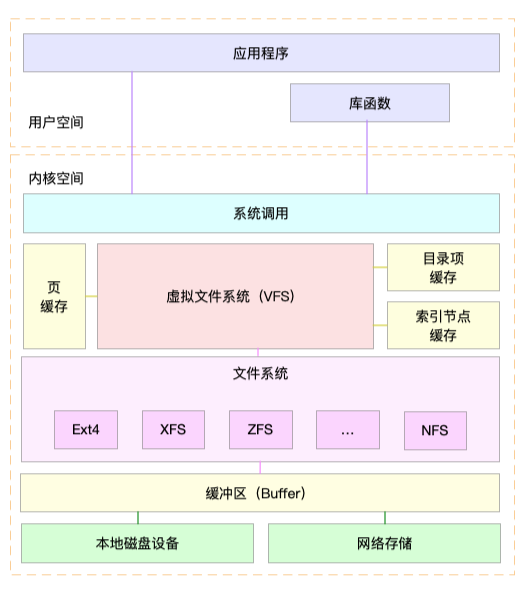
文件系统包括磁盘文件系统,内存文件系统(/proc和/sys)和网络系统
这些文件系统需要挂载到VFS的子目录,也称挂载点才能访问其内部的文件
文件I/O
对于cat命令,调用open()方法,打开文件,通过read()方法读取文件内容,然后调用write()方法将文件内容输出到控制台的标准输出
文件读写的方式有各种差异,导致I/O的分类也有多种
第一种是根据时候使用标准库进行缓存,将文件I/O分为缓冲I/O和非缓冲I/O
- 缓冲I/O是指利用标准库来加速文件的访问,而标准库在通过系统调用访问文件
- 非缓冲I/O是指直接通过系统调用来访问文件,而不经过标准库
但是不论是否使用标准库,系统调用都会通过页缓存,来减少I/O的操作
第二种是是否利用页缓存,可以将文件I/O分为直接I/O和非直接I/O
- 直接I/O是指跳过页缓存,直接和文件系统交互来访问文件
- 非直接I/O是在读写时,经过页缓存,然后由内核或者额外的系统调用真正写入磁盘
想要实现直接I/O,就在系统调用中指定O_DIRECT标志
直接和非直接I/O都是和文件系统交互,而数据库等场景还会有跳过文件系统直接读写磁盘的情况,就是裸I/O
第三种是根据应用程序是否阻塞自身运行,可以把文件I/O分为阻塞I/O和非阻塞I/O
- 阻塞I/O是指应用程序执行了I/O操作之后没有获得响应就会阻塞当前进程等待响应,不能执行其他的任务
- 非阻塞I/O是指应用程序执行了I/O操作之后,不会阻塞当前线程,可以继续执行其他的任务,随后通过轮序和事件通知的形式获取调用结果
例如访问管道或者网络套接字,设置O_NONBLOCK标志,代表非阻塞的方式,默认为阻塞方式
第四种是是否等待响应结果,可以将其分为同步I/O和异步I/O
- 同步I/O是指在应用程序执行I/O操作后,等待整个I/O操作,才能获取I/O响应
- 异步I/O是指在应用程序制定I/O操作后,不用等待完成和完成后的响应,而继续执行即可,IO完成后会通过事件通知的方式告知应用程序
在操作文件的时候设置了O_SYNC或者O_DSYNC都是代表的同步I/O,区别是O_DSYNC只需要等待文件数据写入磁盘才返回,而O_SYNC需要文件数据和文件源数据都写入磁盘才返回
在访问管道或者网络套接字的时候,设置了O_ASYNC,相应的I/O就是异步I/O
获取Cache,页缓存和Slab缓存的和
$ cat /proc/meminfo | grep -E "SReclaimable|Cached"
Cached: 8212328 kB
SwapCached: 0 kB
SReclaimable: 432100 kB
获取文件系统的目录项和索引节点缓存
$ cat /proc/slabinfo | grep -E '^#|dentry|inode'
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
ovl_inode 8040 11976 680 24 4 : tunables 0 0 0 : slabdata 499 499 0
isofs_inode_cache 75 75 640 25 4 : tunables 0 0 0 : slabdata 3 3 0
ext4_inode_cache 94240 95263 1032 31 8 : tunables 0 0 0 : slabdata 3073 3073 0
mqueue_inode_cache 72 72 896 18 4 : tunables 0 0 0 : slabdata 4 4 0
hugetlbfs_inode_cache 52 52 608 26 4 : tunables 0 0 0 : slabdata 2 2 0
sock_inode_cache 3450 4250 640 25 4 : tunables 0 0 0 : slabdata 170 170 0
shmem_inode_cache 5112 5304 680 24 4 : tunables 0 0 0 : slabdata 221 221 0
proc_inode_cache 12828 13488 656 24 4 : tunables 0 0 0 : slabdata 562 562 0
inode_cache 41584 41742 592 27 4 : tunables 0 0 0 : slabdata 1546 1546 0
dentry 315904 329028 192 21 1 : tunables 0 0 0 : slabdata 15668 15668 0
selinux_inode_security 14382 14382 40 102 1 : tunables 0 0 0 : slabdata 141 141 0
- dentry为目录项缓存
- inode_cache为索引节点缓存
slabtop可以查看占用内存最多的缓存类型
按c可以按照缓存大小排列,而按a可以按照缓存活跃对象排列
Active / Total Objects (% used) : 3090942 / 3183728 (97.1%)
Active / Total Slabs (% used) : 87475 / 87475 (100.0%)
Active / Total Caches (% used) : 89 / 116 (76.7%)
Active / Total Size (% used) : 528024.80K / 543911.99K (97.1%)
Minimum / Average / Maximum Object : 0.01K / 0.17K / 8.00K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
1850901 1849849 99% 0.10K 47459 39 189836K buffer_head
95263 94240 98% 1.01K 3073 31 98336K ext4_inode_cache
329049 315966 96% 0.19K 15669 21 62676K dentry
53032 52480 98% 0.57K 1894 28 30304K radix_tree_node
41742 41584 99% 0.58K 1546 27 24736K inode_cache
107746 107746 100% 0.12K 3169 34 12676K kernfs_node_cache
2608 2030 77% 4.00K 326 8 10432K kmalloc-4096
2440 2423 99% 3.95K 305 8 9760K task_struct
4704 4378 93% 2.00K 294 16 9408K kmalloc-2048
13488 12826 95% 0.64K 562 24 8992K proc_inode_cache
12000 8064 67% 0.66K 500 24 8000K ovl_inode
7232 6578 90% 1.00K 452 16 7232K kmalloc-1024
89856 73504 81% 0.06K 1404 64 5616K kmalloc-64
123216 119633 97% 0.04K 1208 102 4832K ext4_extent_status
24171 21895 90% 0.19K 1151 21 4604K kmalloc-192
19098 19098 100% 0.21K 1061 18 4244K vm_area_struct
1860 1846 99% 2.06K 124 15 3968K idr_layer_cache
2320 2320 100% 1.56K 116 20 3712K mm_struct
14624 12666 86% 0.25K 914 16 3656K kmalloc-256
7216 6550 90% 0.50K 451 16 3608K kmalloc-512
5304 5112 96% 0.66K 221 24 3536K shmem_inode_cache
1515 1467 96% 2.06K 101 15 3232K sighand_cache
3534 3534 100% 0.81K 186 19 2976K task_xstate
30702 27642 90% 0.09K 731 42 2924K kmalloc-96
2520 2520 100% 1.12K 90 28 2880K signal_cache
当时使用find的时候,dentry会升高
24 | 基础篇:Linux 磁盘I/O是怎么工作的(上)
磁盘
磁盘分为机械磁盘和固态磁盘
- 机械磁盘HDD,由盘片和电子磁头组成,需要进行磁盘寻址,定位数据磁道,移动磁头访问数据,对于连续的I/O请求,不需要磁道寻址,可以获得最佳性能,而随机I/O需要不停移动磁头,性能就会下降
- 固态磁盘SDD,由固态电子元器件组成,不需要磁道寻址,随机I/O和连续I/O都会比机械磁盘要好
机械磁盘的读写单位为扇区,为512字节,固态磁盘的读写单位为4KB或8KB
接口分为IDE,SCSI,SAS,SATA,FC等,会根据不同的接口生成不同的块设备名称前缀,多块相同类型会分配字母编号
磁盘可以独立使用,也可以划分分区
架构方面可以做raid
也可以通过网络文件系统提供服务
磁盘在Linux中作为一个块设备来进行管理,以块为单位进行读写
通用块层
通用块层是用于连接VFS和块设备的,主要功能
- 向上为文件系统和应用程序提供访问块设备的标准接口,向下把各种异构的磁盘设备抽象为统一的块设备,并提供统一的框架来管理这些设备驱动
- 对发往文件系统和应用程序进行I/O排队,提高磁盘的读写效率
调度算法
- 第一种是NONE,就是并不适用I/O调度算法
- 第二种是NOOP,是一种简单的I/O调度算法,是一个先入先出队列,做一些基本的合并请求,适用于SSD
- 第三种是CFQ,被称为完全公平调度器,是很多发型版默认的调度器,为每个进程维护了一个I/O调度队列,按照时间片来均匀分配每个请求,适用于运行大量进程的系统
- 最后一种是Deadline,为读写创建不同的I/O队列,可以提高机械硬盘的吞吐量,并确保达到Deadline的请求优先处理
I/O栈
分三层,文件系统层,通用模块层和设备层
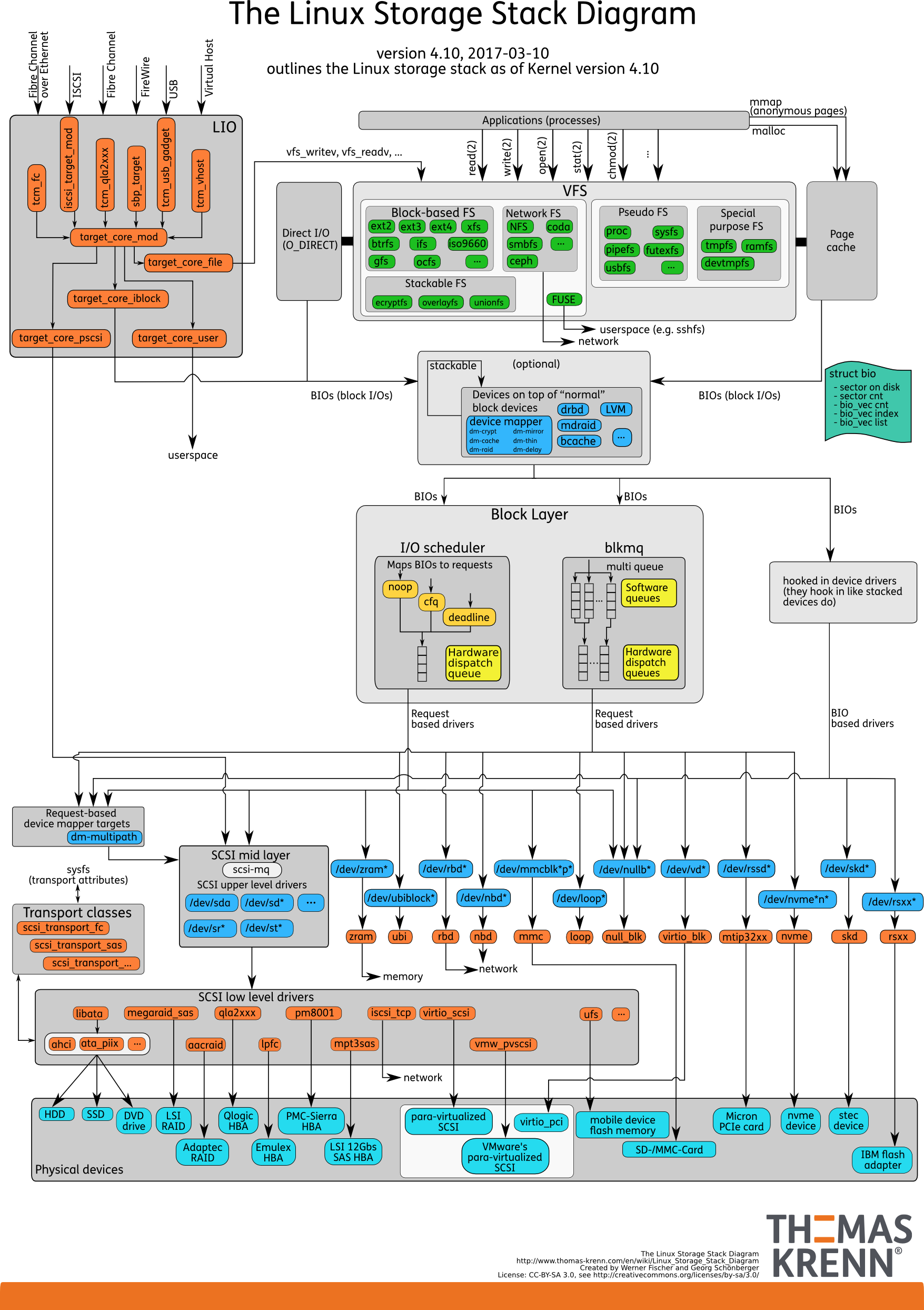
- 文件系统层 包括虚拟文件系统和其他文件系统的具体实现
- 通用模块层 包括设备I/O队列和I/O调度器
- 设备层 包括存储设备和响应的驱动,负责硬件设备的I/O操作
25 | 基础篇:Linux 磁盘I/O是怎么工作的(下)
磁盘性能指标
- 使用率 磁盘处理I/O的时间百分比
- 饱和度 磁盘处理I/O的繁忙程度
- IOPS 每秒的I/O请求数
- 吞吐量 每秒I/O的请求大小
- 响应时间 I/O请求发出到收到响应的时间
在数据库或者小文件等随机读写较多的场景,IOPS更能反映系统的性能,而多媒体等顺序读写的场景,吞吐量才能反映系统性能
一般测试会使用fio来测试磁盘I/O的基本性能,一般需要测不同I/O场景下(512B~1MB之间的若干值)的随机读,顺序读,随机写和顺序写的性能
iostat
$ iostat -x -d 1
Linux 3.10.0-862.el7.x86_64 (node-01) 03/01/2019 _x86_64_ (4 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 6.33 0.05 4.36 1.13 50.43 23.40 0.01 2.91 1.93 2.92 0.54 0.24
scd0 0.00 0.00 0.00 0.00 0.00 0.00 10.25 0.00 0.21 0.21 0.00 0.20 0.00
指标解读
- rrqm 每秒合并的读请求数
- wrqm 每秒合并的写请求数
- rs 每秒发给磁盘的读请求(合并后)
- ws 每秒发给磁盘的写请求(合并后)
- rkB 每秒从磁盘读取的数据量
- wkB 每秒向磁盘写入的数据量
- avgrq-sz
- avgqu-sz 平均请求队列
- rareq-sz 平均读请求大小
- wareq-sz 平均写请求大小
- await
- r_await 读请求处理完成等待时间(包括队列等待时间和设备处理时间,单位为ms)
- w_await 写请求处理完成等待时间(包括队列等待时间和设备处理时间,单位为ms)
- svctm 处理I/O请求所需要的平均时间
%util磁盘处理I/O的时间百分比(可能存在并行IO)
换句话说
rs+ws就是IOPS了rkB+wkB就是吞吐量r_await+w_await就是请求时间
iostat不能直接得到磁盘的饱和度,需要根据队列长度和读写请求完成时间和基准测试来对比
进程I/O
pidstat或iotop
$ pidstat -d 1
13:39:51 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
13:39:52 102 916 0.00 4.00 0.00 0 rsyslogd
可以看到
- UID 用户ID
- PID 进程ID
- kB_rd 每秒读取的数据大小
- kB_wr 每秒发出的写请求数据大小
- kB_ccwr 每秒取消的写请求数据大小
- iodelay 块IO延迟(包括等待同步块IO和换入块IO结束的时间,单位是时钟周期)
$ iotop
Total DISK READ : 0.00 B/s | Total DISK WRITE : 7.85 K/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
15055 be/3 root 0.00 B/s 7.85 K/s 0.00 % 0.00 % systemd-journald
前两行为磁盘读写大小总数和磁盘真实写入大小总数,因为缓冲区,缓存,IO合并等,这些可能不相等
然后是从进程角度表示进程IO,包括线程ID,I/O优先级,每秒读磁盘的大小,每秒写磁盘的大小,换入和等待IO的时钟百分比
26 | 案例篇:如何找出狂打日志的“内鬼”?
需要2核8G机器,安装systat和docker
$ docker run -v /tmp:/tmp --name=app -itd feisky/logapp
思路是top看一下CPU和内存的使用情况,iostat观察磁盘IO
# 按 1 切换到每个 CPU 的使用情况
$ top
top - 14:43:43 up 1 day, 1:39, 2 users, load average: 2.48, 1.09, 0.63
Tasks: 130 total, 2 running, 74 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.7 us, 6.0 sy, 0.0 ni, 0.7 id, 92.7 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.0 us, 0.3 sy, 0.0 ni, 92.3 id, 7.3 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8169308 total, 747684 free, 741336 used, 6680288 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7113124 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
18940 root 20 0 656108 355740 5236 R 6.3 4.4 0:12.56 python
1312 root 20 0 236532 24116 9648 S 0.3 0.3 9:29.80 python3
- CPU0的使用率为sys6%,iowait则是90%+,说明在进行IO密集型操作的进程,只有这个python进程使用了大量的CPU,PID为18940
- 8G的内存剩余730MB,Buffer+Cache使用了6.6GB,内存主要被缓存占用
# -d 表示显示 I/O 性能指标,-x 表示显示扩展统计(即所有 I/O 指标)
$ iostat -x -d 1
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda 0.00 64.00 0.00 32768.00 0.00 0.00 0.00 0.00 0.00 7270.44 1102.18 0.00 512.00 15.50 99.20
sda的IO使用率已经为99%,接近IO饱和,每秒写入请求数为64,写的大小为32MB,写请求响应时间为7s,而请求队列长度达到了1000
使用pidstat加上-d参数显示每个进程的IO情况
$ pidstat -d 1
15:08:35 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
15:08:36 0 18940 0.00 45816.00 0.00 96 python
15:08:36 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
15:08:37 0 354 0.00 0.00 0.00 350 jbd2/sda1-8
15:08:37 0 18940 0.00 46000.00 0.00 96 python
15:08:37 0 20065 0.00 0.00 0.00 1503 kworker/u4:2
python进程每秒写入45MB,比iostat看到的还要大,并且其他两个进程的iodelay(IO块延迟)比python进程大的多,很显然就是这个造成了性能的瓶颈
$ strace -p 18940
strace: Process 18940 attached
...
mmap(NULL, 314576896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f0f7aee9000
mmap(NULL, 314576896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f0f682e8000
write(3, "2018-12-05 15:23:01,709 - __main"..., 314572844
) = 314572844
munmap(0x7f0f682e8000, 314576896) = 0
write(3, "\n", 1) = 1
munmap(0x7f0f7aee9000, 314576896) = 0
close(3) = 0
stat("/tmp/logtest.txt.1", {st_mode=S_IFREG|0644, st_size=943718535, ...}) = 0
可以看到是在用write()系统调用向文件描述为3的文件写入300MB的数据
然后stat获取/tmp/logtest.txt.1文件的状态,一个类似文件回滚的方式
lsof获取进程打开的文件
$ lsof -p 18940
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
python 18940 root cwd DIR 0,50 4096 1549389 /
python 18940 root rtd DIR 0,50 4096 1549389 /
…
python 18940 root 2u CHR 136,0 0t0 3 /dev/pts/0
python 18940 root 3w REG 8,1 117944320 303 /tmp/logtest.txt
- FD代表文件描述符号
- NAME为文件路径
- TYPE文件类型
3w代表的文件描述符为3,w写入的方式打开
对于Buffer和Cache,可以使用
- pcstat(page cache stat)
- cat /proc/meminfo
- hcache -top 3
27 | 案例篇:为什么我的磁盘I/O延迟很高?
$ docker run --name=app -p 10000:80 -itd feisky/word-pop
在另一终端上请求,这是一个单词热度的接口
$ time curl http://192.168.0.10:10000/popularity/word
在iostat
$ iostat -d -x 1
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda 0.00 71.00 0.00 32912.00 0.00 0.00 0.00 0.00 0.00 18118.31 241.89 0.00 463.55 13.86 98.40
每秒写入32MB,写入次数为71,写响应时间为28s
$ pidstat -d 1
14:39:14 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
14:39:15 0 12280 0.00 335716.00 0.00 0 python
strace追踪
$ strace -p 12280
strace: Process 12280 attached
select(0, NULL, NULL, NULL, {tv_sec=0, tv_usec=567708}) = 0 (Timeout)
stat("/usr/local/lib/python3.7/importlib/_bootstrap.py", {st_mode=S_IFREG|0644, st_size=39278, ...}) = 0
stat("/usr/local/lib/python3.7/importlib/_bootstrap.py", {st_mode=S_IFREG|0644, st_size=39278, ...}) = 0
$ strace -p 12280 2>&1 | grep write
可以看到没有write,这是因为写入是由子线程实现,而strace默认是不追踪线程的,可以通pstree查一下线程,也可用-f参数跟踪所有线程
filetop,bcc软件包的一部分,基于内核的eBPF机制,跟踪内存中文件读写情况,git地址
# 切换到工具目录
$ cd /usr/share/bcc/tools
# -C 选项表示输出新内容时不清空屏幕
$ ./filetop -C
TID COMM READS WRITES R_Kb W_Kb T FILE
514 python 0 1 0 2832 R 669.txt
514 python 0 1 0 2490 R 667.txt
514 python 0 1 0 2685 R 671.txt
514 python 0 1 0 2392 R 670.txt
514 python 0 1 0 2050 R 672.txt
...
TID COMM READS WRITES R_Kb W_Kb T FILE
514 python 2 0 5957 0 R 651.txt
514 python 2 0 5371 0 R 112.txt
514 python 2 0 4785 0 R 861.txt
514 python 2 0 4736 0 R 213.txt
514 python 2 0 4443 0 R 45.txt
可以看到线程ID,命令行参数,读写次数,读写大小,文件类型和读写的文件内容
可以看到写之后在进行的读文件,不过没有路径
$ opensnoop
12280 python 6 0 /tmp/9046db9e-fe25-11e8-b13f-0242ac110002/650.txt
12280 python 6 0 /tmp/9046db9e-fe25-11e8-b13f-0242ac110002/651.txt
12280 python 6 0 /tmp/9046db9e-fe25-11e8-b13f-0242ac110002/652.txt
案例通过动态生成一些文件,用做保存临时目录,用完删除,文件读写引发了IO性能瓶颈,如果可以进行放在内存中,或者优化算法
28 | 案例篇:一个SQL查询要15秒,这是怎么回事?
$ git clone https://github.com/feiskyer/linux-perf-examples
$ cd linux-perf-examples/mysql-slow
# 注意下面的随机字符串是容器 ID,每次运行均会不同,并且你不需要关注它,因为我们只会用到名字
$ make run
docker run --name=mysql -itd -p 10000:80 -m 800m feisky/mysql:5.6
WARNING: Your kernel does not support swap limit capabilities or the cgroup is not mounted. Memory limited without swap.
4156780da5be0b9026bcf27a3fa56abc15b8408e358fa327f472bcc5add4453f
$ docker run --name=dataservice -itd --privileged feisky/mysql-dataservice
f724d0816d7e47c0b2b1ff701e9a39239cb9b5ce70f597764c793b68131122bb
$ docker run --name=app --network=container:mysql -itd feisky/mysql-slow
81d3392ba25bb8436f6151662a13ff6182b6bc6f2a559fc2e9d873cd07224ab6
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9a4e3c580963 feisky/mysql-slow "python /app.py" 42 seconds ago Up 36 seconds app
2a47aab18082 feisky/mysql-dataservice "python /dataservice…" 46 seconds ago Up 41 seconds dataservice
4c3ff7b24748 feisky/mysql:5.6 "docker-entrypoint.s…" 47 seconds ago Up 46 seconds 3306/tcp, 0.0.0.0:10000->80/tcp mysql
初始化数据库
$ make init
docker exec -i mysql mysql -uroot -P3306 < tables.sql
curl http://127.0.0.1:10000/db/insert/products/10000
insert 10000 lines
# 然后请求
$ curl http://192.168.0.10:10000/products/geektime
Got data: () in 15.364538192749023 sec
# 通过for循环的方式
$ while true; do curl http://192.168.0.10:10000/products/geektime; sleep 5; done
一会会发现系统响应也明显变慢,随便执行一个命令都会停顿一会儿才能看出输出
$ top
top - 12:02:15 up 6 days, 8:05, 1 user, load average: 0.66, 0.72, 0.59
Tasks: 137 total, 1 running, 81 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.7 us, 1.3 sy, 0.0 ni, 35.9 id, 62.1 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.3 us, 0.7 sy, 0.0 ni, 84.7 id, 14.3 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8169300 total, 7238472 free, 546132 used, 384696 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7316952 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
27458 999 20 0 833852 57968 13176 S 1.7 0.7 0:12.40 mysqld
27617 root 20 0 24348 9216 4692 S 1.0 0.1 0:04.40 python
1549 root 20 0 236716 24568 9864 S 0.3 0.3 51:46.57 python3
22421 root 20 0 0 0 0 I 0.3 0.0 0:01.16 kworker/u
两个CPU都出线了iowait,但是CPU使用率都不高
$ iostat -d -x 1
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
...
sda 273.00 0.00 32568.00 0.00 0.00 0.00 0.00 0.00 7.90 0.00 1.16 119.30 0.00 3.56 97.20
pidstat看一下是那个进程在进行读写
# -d 选项表示展示进程的 I/O 情况
$ pidstat -d 1
12:04:11 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
12:04:12 999 27458 32640.00 0.00 0.00 0 mysqld
12:04:12 0 27617 4.00 4.00 0.00 3 python
12:04:12 0 27864 0.00 4.00 0.00 0 systemd-journal
$ strace -f -p 27458
[pid 28014] read(38, "934EiwT363aak7VtqF1mHGa4LL4Dhbks"..., 131072) = 131072
[pid 28014] read(38, "hSs7KBDepBqA6m4ce6i6iUfFTeG9Ot9z"..., 20480) = 20480
[pid 28014] read(38, "NRhRjCSsLLBjTfdqiBRLvN9K6FRfqqLm"..., 131072) = 131072
[pid 28014] read(38, "AKgsik4BilLb7y6OkwQUjjqGeCTQTaRl"..., 24576) = 24576
[pid 28014] read(38, "hFMHx7FzUSqfFI22fQxWCpSnDmRjamaW"..., 131072) = 131072
[pid 28014] read(38, "ajUzLmKqivcDJSkiw7QWf2ETLgvQIpfC"..., 20480) = 20480
可以看到是在读27458进程的38编号的文件
$ lsof -p 28014
$ echo $?
1
没有获取到结果,可以看一下返回值,发现为1,因为这是一个线程
# -t 表示显示线程,-a 表示显示命令行参数
$ pstree -t -a -p 27458
mysqld,27458 --log_bin=on --sync_binlog=1
...
├─{mysqld},27922
├─{mysqld},27923
└─{mysqld},28014
然后再用lsof获取文件
$ lsof -p 27458
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
...
mysqld 27458 999 38u REG 8,1 512440000 2601895 /var/lib/mysql/test/products.MYD
38u,u代表可读写访问,而/var/lib/mysql/test/products.MYD的
- MYD文件是MyISAM引擎用来存储表数据的文件
- 文件名是数据表的名字
- 文件的父目录就是数据库的名字
$ docker exec -it mysql ls /var/lib/mysql/test/
db.opt products.MYD products.MYI products.frm
这四个文件分别是
- MYD文件用来存储表的数据
- MYI文件用来存储表的索引
- frm文件用来存储表的元数据信息(表结构)
- opt文件用来存储数据库的元数据信息(字符集,字符校验规则)
$ docker exec -i -t mysql mysql -e 'show global variables like "%datadir%";'
+---------------+-----------------+
| Variable_name | Value |
+---------------+-----------------+
| datadir | /var/lib/mysql/ |
+---------------+-----------------+
查看一下运行的线程
$ docker exec -i -t mysql mysql
mysql> show full processlist;
+----+------+-----------------+------+---------+------+--------------+-----------------------------------------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+------+-----------------+------+---------+------+--------------+-----------------------------------------------------+
| 27 | root | localhost | test | Query | 0 | init | show full processlist |
| 28 | root | 127.0.0.1:42262 | test | Query | 1 | Sending data | select * from products where productName='geektime' |
+----+------+-----------------+------+---------+------+--------------+-----------------------------------------------------+
2 rows in set (0.00 sec)
- db为操作的数据库名称
- Command为SQL类型
- Time为执行时间
- State为状态
- Info为完整的SQL
在请求的时候我们也是请求的/products/geektime这个接口
# 切换到 test 库
mysql> use test;
# 执行 explain 命令
mysql> explain select * from products where productName='geektime';
+----+-------------+----------+------+---------------+------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+----------+------+---------------+------+---------+------+-------+-------------+
| 1 | SIMPLE | products | ALL | NULL | NULL | NULL | NULL | 10000 | Using where |
+----+-------------+----------+------+---------------+------+---------+------+-------+-------------+
1 row in set (0.00 sec)
- select_type 表示查询类型,不包括UNION查询或子查询
- table 表示数据库的名称
- type 表示查询类型,ALL代表全表查询,但是走索引应该是INDEX
- possible_keys 表示可选用的索引
- key 表示确切会使用的索引
- rows 查询扫描的行数,这里是10000
所以这查询在扫描了10000行都没有使用索引,创建一下索引就可以了
可以创建索引
也停止DataService应用
$ docker rm -f dataservice
vmstat除了IO读写还能看到CPU和内存
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 1 0 6809304 1368 856744 0 0 32640 0 52 478 1 0 50 49 0
0 1 0 6776620 1368 889456 0 0 32640 0 33 490 0 0 50 49 0
0 0 0 6747540 1368 918576 0 0 29056 0 42 568 0 0 56 44 0
0 0 0 6747540 1368 918576 0 0 0 0 40 141 1 0 100 0 0
0 0 0 6747160 1368 918576 0 0 0 0 40 148 0 1 99 0 0
可以看到bi的IO读和iowait开始还是很高的,但是后来降下来了
这个dataservice的作用就是在读之前将/proc/sys/vm/drop_caches改为1,释放了pagecache文件缓存,而mysql读数据就是使用的文件缓存,而MyISAM引擎不会缓存数据
29 | 案例篇:Redis响应严重延迟,如何解决?
$ docker run --name=redis -itd -p 10000:80 feisky/redis-server
ec41cb9e4dd5cb7079e1d9f72b7cee7de67278dbd3bd0956b4c0846bff211803
$ docker run --name=app --network=container:redis -itd feisky/redis-app
2c54eb252d0552448320d9155a2618b799a1e71d7289ec7277a61e72a9de5fd0
案例插入5000条数据,在实践时可以根据磁盘的类型适当调整,比如使用SSD时可以调大,而HDD可以适当调小
$ curl http://192.168.0.10:10000/init/5000
{"elapsed_seconds":30.26814079284668,"keys_initialized":5000}
访问应用缓存接口
$ curl http://192.168.0.10:10000/get_cache
{"count":1677,"data":["d97662fa-06ac-11e9-92c7-0242ac110002",...],"elapsed_seconds":10.545469760894775,"type":"good"}
这个接口返回需要10s
$ top
top - 12:46:18 up 11 days, 8:49, 1 user, load average: 1.36, 1.36, 1.04
Tasks: 137 total, 1 running, 79 sleeping, 0 stopped, 0 zombie
%Cpu0 : 6.0 us, 2.7 sy, 0.0 ni, 5.7 id, 84.7 wa, 0.0 hi, 1.0 si, 0.0 st
%Cpu1 : 1.0 us, 3.0 sy, 0.0 ni, 94.7 id, 0.0 wa, 0.0 hi, 1.3 si, 0.0 st
KiB Mem : 8169300 total, 7342244 free, 432912 used, 394144 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7478748 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9181 root 20 0 193004 27304 8716 S 8.6 0.3 0:07.15 python
9085 systemd+ 20 0 28352 9760 1860 D 5.0 0.1 0:04.34 redis-server
368 root 20 0 0 0 0 D 1.0 0.0 0:33.88 jbd2/sda1-8
149 root 0 -20 0 0 0 I 0.3 0.0 0:10.63 kworker/0:1H
1549 root 20 0 236716 24576 9864 S 0.3 0.3 91:37.30 python3
CPU0的iowait很高,剩余内存还有很多
$ iostat -d -x 1
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
...
sda 0.00 492.00 0.00 2672.00 0.00 176.00 0.00 26.35 0.00 1.76 0.00 0.00 5.43 0.00 0.00
可以看到写磁盘的数据量只有2MB,写入磁盘的请求次数为492
$ pidstat -d 1
12:49:35 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
12:49:36 0 368 0.00 16.00 0.00 86 jbd2/sda1-8
12:49:36 100 9085 0.00 636.00 0.00 1 redis-server
通过strace追踪一下
# -f 表示跟踪子进程和子线程,-T 表示显示系统调用的时长,-tt 表示显示跟踪时间
$ strace -f -T -tt -p 9085
[pid 9085] 14:20:16.826131 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 65, NULL, 8) = 1 <0.000055>
[pid 9085] 14:20:16.826301 read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:5b2e76cc-"..., 16384) = 61 <0.000071>
[pid 9085] 14:20:16.826477 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000063>
[pid 9085] 14:20:16.826645 write(8, "$3\r\nbad\r\n", 9) = 9 <0.000173>
[pid 9085] 14:20:16.826907 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 65, NULL, 8) = 1 <0.000032>
[pid 9085] 14:20:16.827030 read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:55862ada-"..., 16384) = 61 <0.000044>
[pid 9085] 14:20:16.827149 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000043>
[pid 9085] 14:20:16.827285 write(8, "$3\r\nbad\r\n", 9) = 9 <0.000141>
[pid 9085] 14:20:16.827514 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 64, NULL, 8) = 1 <0.000049>
[pid 9085] 14:20:16.827641 read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:53522908-"..., 16384) = 61 <0.000043>
[pid 9085] 14:20:16.827784 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000034>
[pid 9085] 14:20:16.827945 write(8, "$4\r\ngood\r\n", 10) = 10 <0.000288>
[pid 9085] 14:20:16.828339 epoll_pwait(5, [{EPOLLIN, {u32=8, u64=8}}], 10128, 63, NULL, 8) = 1 <0.000057>
[pid 9085] 14:20:16.828486 read(8, "*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535"..., 16384) = 67 <0.000040>
[pid 9085] 14:20:16.828623 read(3, 0x7fff366a5747, 1) = -1 EAGAIN (Resource temporarily unavailable) <0.000052>
[pid 9085] 14:20:16.828760 write(7, "*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535"..., 67) = 67 <0.000060>
[pid 9085] 14:20:16.828970 fdatasync(7) = 0 <0.005415>
[pid 9085] 14:20:16.834493 write(8, ":1\r\n", 4) = 4 <0.000250>
频繁调用的就是这些系统调用,文件描述符为3,5,7和8
$ lsof -p 9085
redis-ser 9085 systemd-network 3r FIFO 0,12 0t0 15447970 pipe
redis-ser 9085 systemd-network 4w FIFO 0,12 0t0 15447970 pipe
redis-ser 9085 systemd-network 5u a_inode 0,13 0 10179 [eventpoll]
redis-ser 9085 systemd-network 6u sock 0,9 0t0 15447972 protocol: TCP
redis-ser 9085 systemd-network 7w REG 8,1 8830146 2838532 /data/appendonly.aof
redis-ser 9085 systemd-network 8u sock 0,9 0t0 15448709 protocol: TCP
3是一个管道,5是eventpoll,7是一个aof文件,8是一个TCP socket
只有文件7才会有文件的读写,fdatasync的系统调用正是刷新数据
应该是appendonly和appendfsync选项配置的问题了
$ docker exec -it redis redis-cli config get 'append*'
1) "appendfsync"
2) "always"
3) "appendonly"
4) "yes"
appendfsync被设置为always,代表每次写入都刷写磁盘
指定查看系统调用
$ strace -f -p 9085 -T -tt -e fdatasync
strace: Process 9085 attached with 4 threads
[pid 9085] 14:22:52.013547 fdatasync(7) = 0 <0.007112>
[pid 9085] 14:22:52.022467 fdatasync(7) = 0 <0.008572>
[pid 9085] 14:22:52.032223 fdatasync(7) = 0 <0.006769>
...
[pid 9085] 14:22:52.139629 fdatasync(7) = 0 <0.008183>
可以看到每10ms就会有一次系统调用,但是本事就会消耗7~8ms
$ strace -f -T -tt -p 9085
read(8, "*2\r\n$3\r\nGET\r\n$41\r\nuuid:53522908-"..., 16384)
write(8, "$4\r\ngood\r\n", 10)
read(8, "*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535"..., 16384)
write(7, "*3\r\n$4\r\nSADD\r\n$4\r\ngood\r\n$36\r\n535"..., 67)
write(8, ":1\r\n", 4)
不过我们明明是在读啊
是因为在GET之后有一个SADD,SADD是一个写操作
使用nsenter
$ docker run --rm -v /usr/local/bin:/target jpetazzo/nsenter
# 由于这两个容器共享同一个网络命名空间,所以我们只需要进入 app 的网络命名空间即可
$ PID=$(docker inspect --format {{.State.Pid}} app)
# -i 表示显示网络套接字信息
$ nsenter --target $PID --net -- lsof -i
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
redis-ser 9085 systemd-network 6u IPv4 15447972 0t0 TCP localhost:6379 (LISTEN)
redis-ser 9085 systemd-network 8u IPv4 15448709 0t0 TCP localhost:6379->localhost:32996 (ESTABLISHED)
python 9181 root 3u IPv4 15448677 0t0 TCP *:http (LISTEN)
python 9181 root 5u IPv4 15449632 0t0 TCP localhost:32996->localhost:6379 (ESTABLISHED)
redis的8号文件描述符就是python使用client来获取
30 | 套路篇:如何迅速分析出系统I/O的瓶颈在哪里?
性能指标
磁盘的基础就是存储空间包括容量,使用量等
缓存的部分包括页缓存,目录项缓存,索引节点缓存以及各个具体文件系统(ext4,XFS)的缓存,这些缓存会使用速度更快的内存
文件IO的性能主要就是IOPS(rs和ws),响应时间(延迟)和吞吐量(B/s)
特定的场景特定的分析
31 | 套路篇:磁盘 I/O 性能优化的几个思路
IO基准测试
用于获取文件系统或者磁盘的极限IO性能
fio提供了大量的可定制化选项,可以测试裸盘或者文件系统在各种场景下的IO
对于CentOS可以直接yum install -y fio
常见场景是随机读写和顺序读写
# 随机读
fio -name=randread -direct=1 -iodepth=64 -rw=randread -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 随机写
fio -name=randwrite -direct=1 -iodepth=64 -rw=randwrite -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 顺序读
fio -name=read -direct=1 -iodepth=64 -rw=read -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 顺序写
fio -name=write -direct=1 -iodepth=64 -rw=write -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
这里参数的含义
- direct 是否跳过系统缓存,设置为1就是跳过文件系统缓存
- iodepath 使用异步IO,同时发出IO请求上限
- rw IO模式
- ioengine IO引擎,sync同步,libabo异步,mmap内存映射,net网络
- bs
- filename 可以是文件系统目录也可以是磁盘
read: (g=0): rw=read, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=64
fio-3.1
Starting 1 process
Jobs: 1 (f=1): [R(1)][100.0%][r=16.7MiB/s,w=0KiB/s][r=4280,w=0 IOPS][eta 00m:00s]
read: (groupid=0, jobs=1): err= 0: pid=17966: Sun Dec 30 08:31:48 2018
read: IOPS=4257, BW=16.6MiB/s (17.4MB/s)(1024MiB/61568msec)
slat (usec): min=2, max=2566, avg= 4.29, stdev=21.76
clat (usec): min=228, max=407360, avg=15024.30, stdev=20524.39
lat (usec): min=243, max=407363, avg=15029.12, stdev=20524.26
clat percentiles (usec):
| 1.00th=[ 498], 5.00th=[ 1020], 10.00th=[ 1319], 20.00th=[ 1713],
| 30.00th=[ 1991], 40.00th=[ 2212], 50.00th=[ 2540], 60.00th=[ 2933],
| 70.00th=[ 5407], 80.00th=[ 44303], 90.00th=[ 45351], 95.00th=[ 45876],
| 99.00th=[ 46924], 99.50th=[ 46924], 99.90th=[ 48497], 99.95th=[ 49021],
| 99.99th=[404751]
bw ( KiB/s): min= 8208, max=18832, per=99.85%, avg=17005.35, stdev=998.94, samples=123
iops : min= 2052, max= 4708, avg=4251.30, stdev=249.74, samples=123
lat (usec) : 250=0.01%, 500=1.03%, 750=1.69%, 1000=2.07%
lat (msec) : 2=25.64%, 4=37.58%, 10=2.08%, 20=0.02%, 50=29.86%
lat (msec) : 100=0.01%, 500=0.02%
cpu : usr=1.02%, sys=2.97%, ctx=33312, majf=0, minf=75
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.1%, >=64=0.0%
issued rwt: total=262144,0,0, short=0,0,0, dropped=0,0,0
latency : target=0, window=0, percentile=100.00%, depth=64
Run status group 0 (all jobs):
READ: bw=16.6MiB/s (17.4MB/s), 16.6MiB/s-16.6MiB/s (17.4MB/s-17.4MB/s), io=1024MiB (1074MB), run=61568-61568msec
Disk stats (read/write):
sdb: ios=261897/0, merge=0/0, ticks=3912108/0, in_queue=3474336, util=90.09%
需要关注的点就是
- slat IO从提交到实际执行IO的时长
- clat IO从提交到完成IO的时长
- lat IO从fio创建到完成IO的时长
- bw 吞吐量,平均吞吐量大约16MB
- iops 每秒IO的次数,示例平均为4250
对于同步IO,IO提交和完成是一个动作,所以slat会存在,clat为0
对于异步IO,lat近似等于slat和clat之和
fio支持IO重放,可以借助blkstrace记录IO访问情况,使用fio重放
# 使用 blktrace 跟踪磁盘 I/O,注意指定应用程序正在操作的磁盘
$ blktrace /dev/sdb
# 查看 blktrace 记录的结果
# ls
sdb.blktrace.0 sdb.blktrace.1
# 将结果转化为二进制文件
$ blkparse sdb -d sdb.bin
# 使用 fio 重放日志
$ fio --name=replay --filename=/dev/sdb --direct=1 --read_iolog=sdb.bin
IO性能优化
程序上应用程序在IO栈的最上端,可以通过系统调用来调整IO模式,是顺序还是随机,同步还是异步
- 使用追加写代替随机写,减少寻址开销,加快IO写
- 借助缓存IO,利用系统缓存,降低IO次数
- 在应用程序内部构建缓存,或者使用Redis这类外部缓存系统,C的标准库fopen和fread都会利用标准库缓存的,而open和read只能利用操作系统的页缓存和缓冲区
- 需要频繁读写同一块磁盘空间的时候可以使用mmap代替read和write,减少内存拷贝次数
- 在同步写的场景尽量将写请求合并,使用fsync()取代
- 在多个应用进程共享磁盘可以通过Group来限制进程或者进程组的IOPS和吞吐量
- 使用CFQ调度时,使用ionice来调整IO调度优先级,提高核心应用的优先级,支持idle,best-effort和realtime,其中best-effort和realtime还支持分级,0~7,0为最高
文件系统优化
- 文件系统选择,ext4和xfs
- 文件系统特性,
ext_attr和dir_index - 日志模式,
journal,ordered和writeback - 挂载选项,
noatime,以上三条可以通过tune2fs调整或者mount参数修改 - 文件系统缓存,优化脏页刷新频率(
dirty_expire_centisecs和dirty_writeback_centisecs)和脏页限制(dirty_background_ratio和dirty_ratio) - 内核回收目录项缓存和索引节点缓存的倾向,
vfs_cache_pressure
磁盘优化
- SSD
- RAID
- IO调度算法优化,虚拟机和SSD磁盘用noop算法,数据库采用deadline
- 对应用的数据磁盘进行隔离
- 在顺序读较多的场景增大磁盘预读,
/sys/block/sdb/queue/read_ahead_kb,默认是128KB,blockdev工具blockdev --setra 8192 /dev/sdb,单位是B - 优化内核块设备IO,调整磁盘队列长度,
/sys/block/sdb/queue/nr_requests,适当增加队列长度,可以提升磁盘的吞吐量,但是也会造成IO延迟增大

