

极客时间专栏——linux性能优化实战——CPU部分
目录:
开篇词 | 别再让Linux性能问题成为你的绊脚石
把观察到的性能问题和系统原理联系在一起,特别是把系统从应用程序,库函数,系统调用,再到内核和硬件等不同层级贯穿起来
- CPU使用率过高,top完不知道如何进一步定位,是CPU资源太少还是程序并发有问题
- 系统并没有跑什么吃内存的进程,free命令之后,发现系统没有内存
- zabbix监控发现数据库主机的iowait比较高,要怎么办
性能优化是个系统工程
01 | 如何学习Linux性能优化?
性能指标是什么?

从应用的角度来说就是吞吐和延迟,从资源的角度就是CPU和内存
性能不好主要来自系统资源达到瓶颈
找出系统或应用的性能瓶颈
- 选择指标评估应用程序和系统的性能
- 为应用程序和系统设置性能目标
- 进行性能基准测试
- 性能分析定位瓶颈
- 优化系统和应用程序
- 性能监控和告警
动态追踪工具Dtrace的作者,描绘的Linux性能工具图谱
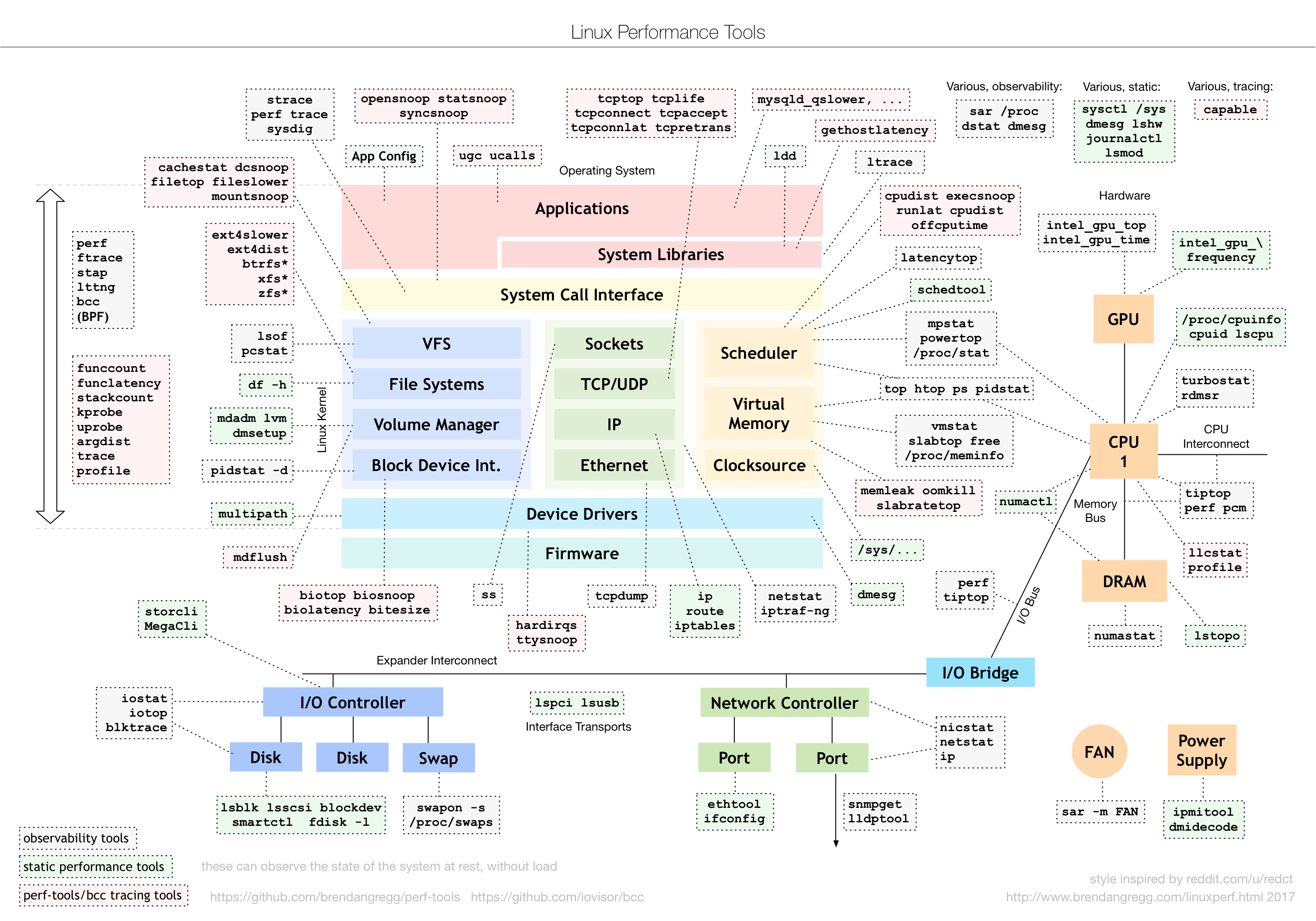
性能工具的选用很重要,可以简化性能优化的过程
02 | 基础篇:到底应该怎么理解“平均负载”?
平均负载
uptime
$ uptime
02:34:03 up 2 days, 20:14, 1 user, load average: 0.63, 0.83, 0.88
02:34:03 // 当前时间
up 2 days, 20:14 // 系统运行时间
1 user // 正在登录用户数
过去1分钟,5分钟和15分钟的平均负载
平均负载是单位时间内可运行状态和不可中断状态的平均进程数,也就是平均活跃进程
- 可运行状态的进程,是指正在使用CPU或者正在等待CPU的进程,就是通过ps命令所看到的,处于R状态(Running或Runnable)的进程
- 不可中断状态的进程,则是正处于内核态关键流程的进程,并且流程是不可打断的,最常见的就是等待硬件设备的I/O响应,就是通过ps命令看到的D状态的进程
当一个进程向磁盘写入数据时,为了保证数据一致性,在得到磁盘回复前,还不能被其他进程或中断中断的,这个时候的进程就处于不可中断状态,如果此时被打断,就会造成磁盘数据和进程数据不一致的问题
理想情况下是每个CPU都能运行一个进程,这样CPU就充分被利用,如果一个CPU的系统的负载为2,意味着一半的进程竞争不到CPU
平局负载多少合理,首先要知道机器的CPU核数,/proc/cpuinfo位置读取
# 关于 grep 和 wc 的用法请查询它们的手册或者网络搜索
$ grep 'model name' /proc/cpuinfo | wc -l
2
当系统的平均负载超多CPU核数的时候系统就是超载
三个不同时间间隔的平均值,反应了系统负载趋势,如果三个值基本相同,就可以表明系统平稳
当平均负载超过CPU数量的70%时,就应该排查负载问题了
平均负载高不代表CPU使用率高
- CPU密集型 使用大量CPU会导致平均负载升高
- I/O密集型 等待I/O也会导致平均负载升高,但是CPU使用率不一定很高
- 大量CPU进程调度也会导致平均负载升高,此时CPU使用率也会比较高
平均负载案例分析
环境准备 2CPU和8G内存,预先安装stress和sysstat
- stress 是一个linux系统压力测试工具,用来模拟平均负载升高
- systat 包含常用性能工具,使用mpstat和pidstat
- mpstat 多核CPU性能分析工具
- pidstat 进程性能分析工具,用来查看进程CPU,内存,I/O和上下文切换等性能指标
CPU密集型
模拟CPU密集型
$ stress --cpu 1 --timeout 600
查看平均负载
# -d 参数表示高亮显示变化的区域
$ watch -d uptime
..., load average: 1.00, 0.75, 0.39
查看CPU使用变化
# -P ALL 表示监控所有 CPU,后面数字 5 表示间隔 5 秒后输出一组数据
$ mpstat -P ALL 5
Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU)
13:30:06 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
13:30:11 all 50.05 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 49.95
13:30:11 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
13:30:11 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
只有一个CPU的使用率为100%,而iowait为0
# 间隔 5 秒后输出一组数据
$ pidstat -u 5 1
13:37:07 UID PID %usr %system %guest %wait %CPU CPU Command
13:37:12 0 2962 100.00 0.00 0.00 0.00 100.00 1 stress
可以看到stress使用了100%的CPU
IO密集型
模拟IO密集型
$ stress -i 1 --timeout 600
查看平均负载
$ watch -d uptime
..., load average: 1.06, 0.58, 0.37
查看CPU使用变化
# 显示所有 CPU 的指标,并在间隔 5 秒输出一组数据
$ mpstat -P ALL 5 1
Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU)
13:41:28 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
13:41:33 all 0.21 0.00 12.07 32.67 0.00 0.21 0.00 0.00 0.00 54.84
13:41:33 0 0.43 0.00 23.87 67.53 0.00 0.43 0.00 0.00 0.00 7.74
13:41:33 1 0.00 0.00 0.81 0.20 0.00 0.00 0.00 0.00 0.00 98.99
CPU的系统CPU使用率升高,而iowait升高到67,说明平均负载是因为iowait导致
# 间隔 5 秒后输出一组数据,-u 表示 CPU 指标
$ pidstat -u 5 1
Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU)
13:42:08 UID PID %usr %system %guest %wait %CPU CPU Command
13:42:13 0 104 0.00 3.39 0.00 0.00 3.39 1 kworker/1:1H
13:42:13 0 109 0.00 0.40 0.00 0.00 0.40 0 kworker/0:1H
13:42:13 0 2997 2.00 35.53 0.00 3.99 37.52 1 stress
13:42:13 0 3057 0.00 0.40 0.00 0.00 0.40 0 pidstat
大量进程场景
模拟大量进程(8个进程)
$ stress -c 8 --timeout 600
查看平均负载,已经到了8
$ uptime
..., load average: 7.97, 5.93, 3.02
查看占用CPU的进程
# 间隔 5 秒后输出一组数据
$ pidstat -u 5 1
14:23:25 UID PID %usr %system %guest %wait %CPU CPU Command
14:23:30 0 3190 25.00 0.00 0.00 74.80 25.00 0 stress
14:23:30 0 3191 25.00 0.00 0.00 75.20 25.00 0 stress
14:23:30 0 3192 25.00 0.00 0.00 74.80 25.00 1 stress
14:23:30 0 3193 25.00 0.00 0.00 75.00 25.00 1 stress
14:23:30 0 3194 24.80 0.00 0.00 74.60 24.80 0 stress
14:23:30 0 3195 24.80 0.00 0.00 75.00 24.80 0 stress
14:23:30 0 3196 24.80 0.00 0.00 74.60 24.80 1 stress
14:23:30 0 3197 24.80 0.00 0.00 74.80 24.80 1 stress
14:23:30 0 3200 0.00 0.20 0.00 0.20 0.20 0 pidstat
是8个进程在抢占2个CPU,每个进程都造成了75%的IOwait
03 | 基础篇:经常说的 CPU 上下文切换是什么意思?(上)
进程在竞争CPU的时候,并没有真真正的运行,但是系统负载还是要升高。
当很多进程在运行,系统需要将CPU轮流分配给这些进程。
每个任务运行的时候,CPU需要知道任务从那里加载并且在那里运行,就需要CPU寄存器和程序计数器
- CPU寄存器
- 程序计数器 用来存储CPU正在执行的指令或下一条需要执行的命令位置,和CPU寄存器都是CPU在运行任务前的依赖环境,被称为CPU上下文
CPU上下文切换是将前一条任务的CPU保存下来放到系统内核留作重新调度使用,加载新的任务CPU上下文到CPU寄存器和程序计数器位置,运行新的任务,包括
- 进程上下文切换
- 线程上下文切换
- 中断上下文切换
这些寄存器本身是为了高速运行任务而设计,而过度的CPU调度会造成了CPU的浪费
进程上下文切换
Linux按照特权等级,进程被分为内核空间和用户空间,对应CPU特权等级的Ring0和Ring3
进程从用户态到内核态的转变,是通过系统调用来实现,例如open()打开文件,调用read()读取文件内容,调用write()打印到标准输出,然后调用close()关闭文件
系统调用的时候就会发生上下文切换,将用户态指令保存起来执行系统调用,系统调用完成再恢复用户态,所以一次系统调用进行了两次CPU的上下文切换
进程的上下文是从一个进程切换到另一个进程,而中断上下文切换是在同一个进程
进程是由内核来管理和调度,进程的切换发生在内核态,进程的上下文切换包括虚拟内存,栈,全局变量等用户空间资源,还有内核堆栈,寄存器等内核空间
因此进程的上下文切换比系统调用多了保存进程的内核状态和CPU寄存器之前,先将虚拟内不吃呢,栈等保存,而加载下一个进程也需要刷新进程的虚拟内存和用户栈

每次上下文切换需要几十纳秒或者几微秒的CPU时间,在进程上下文切换较多的时候容易导致CPU将大量时间用于寄存器,内核栈以及虚拟内存等资源的保存和载入上,缩短了进程的使用时间
Linux通过TLB管理虚拟内存到物理内存的映射,虚拟内存更新之后TLB也需要进行更新,内存的访问也是会变慢,在多处理系统上,缓存是多个处理器共享,所以也会影响到其他的处理器的进程
CPU进行进程切换的情况
- 进程时间片耗尽
- 进程在系统资源不足的时候被挂载,等待资源满足
- 进程通过sleep函数主动挂起
- 较高优先级进程需要运行的时候
- 发生硬件中断
线程上下文切换
线程是调度的基本单位,进程是资源拥有的基本单位,进程为线程提供了虚拟内存,全局变量等资源
- 当一个进程只有一个线程,可以认为进程等于线程
- 当一个进程拥有多个线程,线程会共享虚拟内存,全局变量等资源,这些在上下文切换的时候是不需要修改的
- 线程的私有数据,栈和寄存器在上下文切换的时候是需要保存的
所以线程的上下文切换包括
- 前后线程不属于一个进程,因为资源不共享,需要上下文切换参考进程上下文切换
- 前后线程属于一个进程,因为资源共享,只需要切换私有数据
多线程的一个优势
中断上下文切换
为了快速响应硬件事件,中断会打断当前进程的正常执行和调度,进而处理中断程序,在进程完成后会恢复运行。
在中断打断进程进行上下文切换的时候不需要保存虚拟内存和全局变量,只保存栈和寄存器,中断需要CPU寄存器,内核堆栈,硬件中断参数。
大部分中断都是非常快的
04 | 基础篇:经常说的 CPU 上下文切换是什么意思?(下)
vmstat可以用来查看上下文切换情况
# 每隔 5 秒输出 1 组数据
$ vmstat 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 7005360 91564 818900 0 0 0 0 25 33 0 0 100 0 0
- cs 每秒的上下文切换数
- in 每秒的中断次数
- r 就绪队列长度
- b 处于不可中断睡眠状态进程
每个进程的上下文切换情况
# 每隔 5 秒输出 1 组数据
$ pidstat -w 5
Linux 4.15.0 (ubuntu) 09/23/18 _x86_64_ (2 CPU)
08:18:26 UID PID cswch/s nvcswch/s Command
08:18:31 0 1 0.20 0.00 systemd
08:18:31 0 8 5.40 0.00 rcu_sched
...
- cswch 自愿上下文切换次数,因为资源不足导致的上下文切换
- nvcswch 非自愿上下文切换次数,进程时间片已到被系统强制调度
sysbench模拟多线程切换
# 以 10 个线程运行 5 分钟的基准测试,模拟多线程切换的问题
$ sysbench --threads=10 --max-time=300 threads run
$ sysbench --num-threads=10 --max-time=300 --max-requests=10000000 --test=threads run
查看上下文切换
# 每隔 1 秒输出 1 组数据(需要 Ctrl+C 才结束)
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
6 0 0 6487428 118240 1292772 0 0 0 0 9019 1398830 16 84 0 0 0
8 0 0 6487428 118240 1292772 0 0 0 0 10191 1392312 16 84 0 0 0
队列长度已经大于CPU核数,us+sy为100%,sy更高达了84%,in中断次数达到了1W
查看CPU上下文切换
# 每隔 1 秒输出 1 组数据(需要 Ctrl+C 才结束)
# -w 参数表示输出进程切换指标,而 -u 参数则表示输出 CPU 使用指标
$ pidstat -w -u 1
08:06:33 UID PID %usr %system %guest %wait %CPU CPU Command
08:06:34 0 10488 30.00 100.00 0.00 0.00 100.00 0 sysbench
08:06:34 0 26326 0.00 1.00 0.00 0.00 1.00 0 kworker/u4:2
08:06:33 UID PID cswch/s nvcswch/s Command
08:06:34 0 8 11.00 0.00 rcu_sched
08:06:34 0 16 1.00 0.00 ksoftirqd/1
08:06:34 0 471 1.00 0.00 hv_balloon
08:06:34 0 1230 1.00 0.00 iscsid
08:06:34 0 4089 1.00 0.00 kworker/1:5
08:06:34 0 4333 1.00 0.00 kworker/0:3
08:06:34 0 10499 1.00 224.00 pidstat
08:06:34 0 26326 236.00 0.00 kworker/u4:2
08:06:34 1000 26784 223.00 0.00 sshd
但是上下文切换没有到139W,是因为这个是线程上下文切换
# 每隔 1 秒输出一组数据(需要 Ctrl+C 才结束)
# -wt 参数表示输出线程的上下文切换指标
$ pidstat -wt 1
08:14:05 UID TGID TID cswch/s nvcswch/s Command
...
08:14:05 0 10551 - 6.00 0.00 sysbench
08:14:05 0 - 10551 6.00 0.00 |__sysbench
08:14:05 0 - 10552 18911.00 103740.00 |__sysbench
08:14:05 0 - 10553 18915.00 100955.00 |__sysbench
08:14:05 0 - 10554 18827.00 103954.00 |__sysbench
...
查看中断情况
# -d 参数表示高亮显示变化的区域
$ watch -d cat /proc/interrupts
CPU0 CPU1
...
RES: 2450431 5279697 Rescheduling interrupts
...
变化速度最快的是RES重调度中断,代表唤醒空闲状态的CPU来调度新的任务运行
根据上下文切换的变化
- 自愿上下文切换变多,进程都在等待资源,说明IO问题较大
- 非自愿上下文切换变多,进程都在被强制调度
- 中断变多,说明CPU被中断处理程序占用过多,需要通过/proc/interrupts来分析中断类型
总结一下,通过uptime看系统负载,然后结合mpstat和pidstat判断是计算量大还是进程抢占还是IO过多,然后根据vmstat分析切换次数切换类型来进一步确定IO过多还是进程抢占
05 | 基础篇:某个应用的CPU使用率居然达到100%,我该怎么办?
为了维护CPU时间,Linux通过事先定义的节拍率,触发时间中断,并调用全局变量Jiffies记开机以来的节拍数,每触发一次值就加1
- user 表示用户态CPU时间,不包含nice时间,包括guest时间
- nice 低优先级用户态CPU时间,即1~19之间的CPU时间
- system 内核态CPU时间
- idle 表示空闲时间,不包括I/O等待时间
- iowait 代表等待I/O的CPU时间
- irq(hi) 处理硬中断的CPU时间
- softirq(si) 处理软中断的CPU时间
steal(st) 代表当系统运行在虚拟机上,被其他虚拟机占用的CPU时间
CPU使用率=1-空闲时间/总CPU时间
- 平均CPU使用率=1-(new空闲时间-old空闲时间)/(new总CPU时间-old总CPU时间)
需要注意的是平均CPU使用率要看这个时间间隔的,top默认是3秒,而ps却是进程的整个生命周期
top输出的每个进程都是进程使用的CPU总量
pidstat输出的是用户态,内核态,虚拟机占用,等待IO,以及总CPU使用率,pidstat 1 5
perf top
类似top,能实时显示CPU时钟最多的函数或者指令,可以用来查看热点函数
$ perf top
Samples: 833 of event 'cpu-clock', Event count (approx.): 97742399
Overhead Shared Object Symbol
7.28% perf [.] 0x00000000001f78a4
4.72% [kernel] [k] vsnprintf
4.32% [kernel] [k] module_get_kallsym
3.65% [kernel] [k] _raw_spin_unlock_irqrestore
...
samples为采样数,event事件类型,event count事件总数,示例中总共采集了833个CPU时钟事件,总事件数为97742399
- Overhead为性能事件在所有采样中的比例
- Shared该函数或指令所在的动态共享对象,如内核,进程名,动态链接库名,内核模块名
- Object动态共享对象的类型,
[.]表示用户空间可执行程序,而[k]则代表内核空间 - Symbol函数名
perf record可以采样,perf report用于展示
操作分析
$ docker run --name nginx -p 10000:80 -itd feisky/nginx
$ docker run --name phpfpm -itd --network container:nginx feisky/php-fpm
# 192.168.0.10 是第一台虚拟机的 IP 地址
$ curl http://192.168.0.10:10000/
It works!
ab命令测试
# 并发 10 个请求测试 Nginx 性能,总共测试 100 个请求
$ ab -c 10 -n 100 http://192.168.0.10:10000/
This is ApacheBench, Version 2.3 <$Revision: 1706008 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd,
...
Requests per second: 11.63 [#/sec] (mean)
Time per request: 859.942 [ms] (mean)
...
每秒请求数只有11.63
请求总数到10000
$ ab -c 10 -n 10000 http://10.240.0.5:10000/
查看CPU使用率
$ top
...
%Cpu0 : 98.7 us, 1.3 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 99.3 us, 0.7 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
...
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
21514 daemon 20 0 336696 16384 8712 R 41.9 0.2 0:06.00 php-fpm
21513 daemon 20 0 336696 13244 5572 R 40.2 0.2 0:06.08 php-fpm
21515 daemon 20 0 336696 16384 8712 R 40.2 0.2 0:05.67 php-fpm
21512 daemon 20 0 336696 13244 5572 R 39.9 0.2 0:05.87 php-fpm
21516 daemon 20 0 336696 16384 8712 R 35.9 0.2 0:05.61 php-fpm
是用户态导致CPU飙升的
# -g 开启调用关系分析,-p 指定 php-fpm 的进程号 21515
$ perf top -g -p 21515
使用方向键切换到php-fpm,再按下回车键就可以看到php-fpm的调用关系,最终落到sqrt和add_function
# 从容器 phpfpm 中将 PHP 源码拷贝出来
$ docker cp phpfpm:/app .
# 使用 grep 查找函数调用
$ grep sqrt -r app/ # 找到了 sqrt 调用
app/index.php: $x += sqrt($x);
$ grep add_function -r app/ # 没找到 add_function 调用,这其实是 PHP 内置函数
sqrt函数在app/index.php中应用
$ cat app/index.php
<?php
// test only.
$x = 0.0001;
for ($i = 0; $i <= 1000000; $i++) {
$x += sqrt($x);
}
echo "It works!"
删除这个代码重新测试
$ ab -c 10 -n 10000 http://10.240.0.5:10000/
...
Complete requests: 10000
Failed requests: 0
Total transferred: 1720000 bytes
HTML transferred: 90000 bytes
Requests per second: 2237.04 [#/sec] (mean)
Time per request: 4.470 [ms] (mean)
Time per request: 0.447 [ms] (mean, across all concurrent requests)
Transfer rate: 375.75 [Kbytes/sec] received
...
06 | 案例篇:系统的 CPU 使用率很高,但为啥却找不到高 CPU 的应用?
execsnoop
用于短时进程设计的工具,通过ftrace实时监控进程执行exec()的行为,并输出短时进程的基本信息,包括进程的PID,父进程PID,命令行参数以及执行结果
碰到无法解释的CPU使用率情况,就可能是短时应用导致的问题
- 应用调用了其他二进制程序,这些程序运行时间比较短
- 应用本身在不停的崩溃和启动
07 | 案例篇:系统中出现大量不可中断进程和僵尸进程怎么办?(上)
当IO升高,进程很有可能得不到硬件的响应,而长时间处于不可中断的状态,通过ps命令看到的就是D状态
- R是进程在CPU的就绪队列,表示运行或者等待运行
- D是不可中断状态睡眠,表示进程与硬件交互,并且交互过程中不允许被打断
- Z是进程运行结束,但是父进程并没有回收其资源(PID和进程描述符的)
- S是可中断状态睡眠,表示进程等待某个事件被系统挂起,当事件发生后进入R状态
- I是空闲状态
- T是暂停状态,通过发送SIGSTOP信号变为Stopped,再发送SIGCONT就会继续运行
- X是进程消亡,在ps中并不会看到
当一个进程创建了子进程后,会通过wait或者waitpid方法等待子进程结束回收子进程资源的,而子进程在结束的时候会向SIGCHLD信号,父进程注册SIGCHLD信号的处理函数,异步的收回资源
如果父进程没有这么做或者子进程执行太快,父进程还没来得及处理子进程状态,这时的子进程就是僵尸进程,通常僵尸进程存在时间较短,父进程对其回收之后就会消亡,或者父进程退出后由init进程回收
大量的僵尸进程会占用进程号,导致新的进程不能创建
$ ps aux | grep /app
root 4009 0.0 0.0 4376 1008 pts/0 Ss+ 05:51 0:00 /app
root 4287 0.6 0.4 37280 33660 pts/0 D+ 05:54 0:00 /app
root 4288 0.6 0.4 37280 33668 pts/0 D+ 05:54 0:00 /app
这里s代表这个进程是一个会话的领导进程,+代表前台进程组
- 进程组表示一组互相关联的进程,每个子进程都是父进程所在组的成员
- 会话表示共享同一个控制终端的一个或多个进程组
通过ssh登录就会打开一个tty终端,这个终端就是一个会话,在终端执行的命令和其子进程就构成了一个进程组,后台运行的就是后台进程组
08 | 案例篇:系统中出现大量不可中断进程和僵尸进程怎么办?(下)
测试不可中断进程
$ docker run --privileged --name=app -itd feisky/app:iowait
dstat查看CPU和IO使用情况
# 间隔 1 秒输出 10 组数据
$ dstat 1 10
You did not select any stats, using -cdngy by default.
--total-cpu-usage-- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai stl| read writ| recv send| in out | int csw
0 0 96 4 0|1219k 408k| 0 0 | 0 0 | 42 885
0 0 2 98 0| 34M 0 | 198B 790B| 0 0 | 42 138
0 0 0 100 0| 34M 0 | 66B 342B| 0 0 | 42 135
0 0 84 16 0|5633k 0 | 66B 342B| 0 0 | 52 177
0 3 39 58 0| 22M 0 | 66B 342B| 0 0 | 43 144
0 0 0 100 0| 34M 0 | 200B 450B| 0 0 | 46 147
0 0 2 98 0| 34M 0 | 66B 342B| 0 0 | 45 134
0 0 0 100 0| 34M 0 | 66B 342B| 0 0 | 39 131
0 0 83 17 0|5633k 0 | 66B 342B| 0 0 | 46 168
0 3 39 59 0| 22M 0 | 66B 342B| 0 0 | 37 134
造成iowait的是读请求
然后去看那些D的进程
# -d 展示 I/O 统计数据,-p 指定进程号,间隔 1 秒输出 3 组数据
$ pidstat -d -p 4344 1 3
06:38:50 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:38:51 0 4344 0.00 0.00 0.00 0 app
06:38:52 0 4344 0.00 0.00 0.00 0 app
06:38:53 0 4344 0.00 0.00 0.00 0 app
但是没有任何读写,iodelay代表IO延时的单位时间周期
去掉进程号
# 间隔 1 秒输出多组数据 (这里是 20 组)
$ pidstat -d 1 20
...
06:48:46 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:48:47 0 4615 0.00 0.00 0.00 1 kworker/u4:1
06:48:47 0 6080 32768.00 0.00 0.00 170 app
06:48:47 0 6081 32768.00 0.00 0.00 184 app
06:48:47 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:48:48 0 6080 0.00 0.00 0.00 110 app
06:48:48 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:48:49 0 6081 0.00 0.00 0.00 191 app
06:48:49 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:48:50 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:48:51 0 6082 32768.00 0.00 0.00 0 app
06:48:51 0 6083 32768.00 0.00 0.00 0 app
06:48:51 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:48:52 0 6082 32768.00 0.00 0.00 184 app
06:48:52 0 6083 32768.00 0.00 0.00 175 app
06:48:52 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:48:53 0 6083 0.00 0.00 0.00 105 app
...
也可以通过dstat查看到底是不是磁盘IO问题
strace跟踪进程系统调用
$ strace -p 6082
strace: attach: ptrace(PTRACE_SEIZE, 6082): Operation not permitted
没有权限
$ ps aux | grep 6082
root 6082 0.0 0.0 0 0 pts/0 Z+ 13:43 0:00 [app] <defunct>
进程为僵尸进程
$ perf record -g
$ perf report
可以看到app调用sys_read()读取数据,并从new_sync_read和blkdev_direct_IO进行磁盘的直接读,而绕过了系统缓存,导致IO升高
通过僵尸进程找到父进程
# -a 表示输出命令行选项
# p 表 PID
# s 表示指定进程的父进程
$ pstree -aps 3084
systemd,1
└─dockerd,15006 -H fd://
└─docker-containe,15024 --config /var/run/docker/containerd/containerd.toml
└─docker-containe,3991 -namespace moby -workdir...
└─app,4009
└─(app,3084)
09 | 基础篇:怎么理解Linux软中断?
中断会打断其他进程的运行,所以中断程序会尽快的完成
中断在处理完成前其他中断都不能进行响应,就可能会发生中断丢失的情况
中断被分为两部分,上半部和下半部
- 上半部用于处理快速完成的中断,在中断禁止模式下运行,主要处理与硬件相关的或者时间敏感的中断
- 下半部用于延迟处理上半部未完成的工作,通常以内核线程的方式完成
网卡接收到数据包之后,通过硬件中断的方式通知内核有新的数据,内核负责调用中断处理程序来处理
- 上半部将网卡的数据读取到内存,更新一下硬件寄存器的状态,再发送一个软中断信号,通知下半部来处理
- 下半部被软中断唤醒后,从内存中找到网络数据,然后按照网络协议栈,对数据进行层层解析和处理发送给对应的应用程序
可以理解为
- 上半部直接处理硬件请求,就是硬中断
- 下半部由内核触发,就是软中断
上半部会打断CPU正在执行的任务,然后立即执行中断处理程序,下半部是以内核线程的方式运行,每个CPU都对应一个软中断内核线程,为ksoftirqd/<CPU编号>
一些内核自定义事件也属于软中断,例如内核调度和RCU锁
- 系统中的软中断
/proc/softirqs - 系统中的硬中断
/proc/interrupts
$ cat /proc/softirqs
CPU0 CPU1 CPU2 CPU3
HI: 0 0 0 0
TIMER: 2495123623 3311788581 2903326263 2960855297
NET_TX: 15 19 7 3
NET_RX: 337522522 342907196 319001048 333060116
BLOCK: 0 0 0 0
BLOCK_IOPOLL: 0 0 0 0
TASKLET: 62 4 2 0
SCHED: 335292028 376093827 310770039 308787945
HRTIMER: 1803773 1983166 1660493 1589293
RCU: 3053299570 3855973801 3451011333 3502135066
软中断主要包含10个类别
NET_TX就是网络发送中断,NET_RX是网络接收中断
10 | 案例篇:系统的软中断CPU使用率升高,我该怎么办?
软中断包括网络收发,定时,调度和RCU锁
一台运行nginx,一台运行client
运行nginx
$ docker run -itd --name=nginx -p 80:80 nginx
模拟请求
# -S 参数表示设置 TCP 协议的 SYN(同步序列号),-p 表示目的端口为 80
# -i u100 表示每隔 100 微秒发送一个网络帧
# 注:如果你在实践过程中现象不明显,可以尝试把 100 调小,比如调成 10 甚至 1
$ hping3 -S -p 80 -i u100 192.168.0.30
然后会发现终端开始卡了
# top 运行后按数字 1 切换到显示所有 CPU
$ top
top - 10:50:58 up 1 days, 22:10, 1 user, load average: 0.00, 0.00, 0.00
Tasks: 122 total, 1 running, 71 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.0 us, 0.0 sy, 0.0 ni, 96.7 id, 0.0 wa, 0.0 hi, 3.3 si, 0.0 st
%Cpu1 : 0.0 us, 0.0 sy, 0.0 ni, 95.6 id, 0.0 wa, 0.0 hi, 4.4 si, 0.0 st
...
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
7 root 20 0 0 0 0 S 0.3 0.0 0:01.64 ksoftirqd/0
16 root 20 0 0 0 0 S 0.3 0.0 0:01.97 ksoftirqd/1
2663 root 20 0 923480 28292 13996 S 0.3 0.3 4:58.66 docker-containe
3699 root 20 0 0 0 0 I 0.3 0.0 0:00.13 kworker/u4:0
3708 root 20 0 44572 4176 3512 R 0.3 0.1 0:00.07 top
1 root 20 0 225384 9136 6724 S 0.0 0.1 0:23.25 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.03 kthreadd
...
- 平均负载都为0,就绪队列只有一个进程在运行
- CPU使用率都很低,但是都是si使用
- 进程最大只用了0.3%的CPU
软中断主要关注的软中断的变化数
$ watch -d cat /proc/softirqs
CPU0 CPU1
HI: 0 0
TIMER: 1083906 2368646
NET_TX: 53 9
NET_RX: 1550643 1916776
BLOCK: 0 0
IRQ_POLL: 0 0
TASKLET: 333637 3930
SCHED: 963675 2293171
HRTIMER: 0 0
RCU: 1542111 1590625
会发现TIMER(定时中断),NET_RX(网络接收),SCHED(内核调度),RCU(RCU锁)等都在变化,而NET_RX变化最多
# -n DEV 表示显示网络收发的报告,间隔 1 秒输出一组数据
$ sar -n DEV 1
15:03:46 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
15:03:47 eth0 12607.00 6304.00 664.86 358.11 0.00 0.00 0.00 0.01
15:03:47 docker0 6302.00 12604.00 270.79 664.66 0.00 0.00 0.00 0.00
15:03:47 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
15:03:47 veth9f6bbcd 6302.00 12604.00 356.95 664.66 0.00 0.00 0.00 0.05
eth0每秒接收的数据帧为12607,而发送的只有6304,但是接收总大小才664KB,发送数据为358KB
664*1024/12607=54字节,就是小包问题
进行tcpdump抓包
# -i eth0 只抓取 eth0 网卡,-n 不解析协议名和主机名
# tcp port 80 表示只抓取 tcp 协议并且端口号为 80 的网络帧
$ tcpdump -i eth0 -n tcp port 80
15:11:32.678966 IP 192.168.0.2.18238 > 192.168.0.30.80: Flags [S], seq 458303614, win 512, length 0
...
可以看到只有SYN的包,就是SYN攻击了
11 | 套路篇:如何迅速分析出系统CPU的瓶颈在哪里?
CPU性能指标
- 使用率
- 负载
- 上下文切换
- 中断
缓存命中率
使用率通过top分析CPU使用情况,查到CPU占用高的进程,通过perf top获取造成问题的函数库
- 负载通过uptime查看,负载高的时候使用mpstat和pidstat观察每个CPU和每个进程的CPU使用情况,找出对应进程
- 上下文切换通过vmstat查看,通过pidstat观察进程的上下文切换情况
- 中断通过dstat查看磁盘情况,通过pidstat找到对应进程,用strace查看进程的系统调用失败,用perf分析函数调用;软中断通过top看到软中断升高,看/proc/softirqs文件,对变换较快的软中断通过sar看到是网络,通过tcpdump来判断网络帧类型
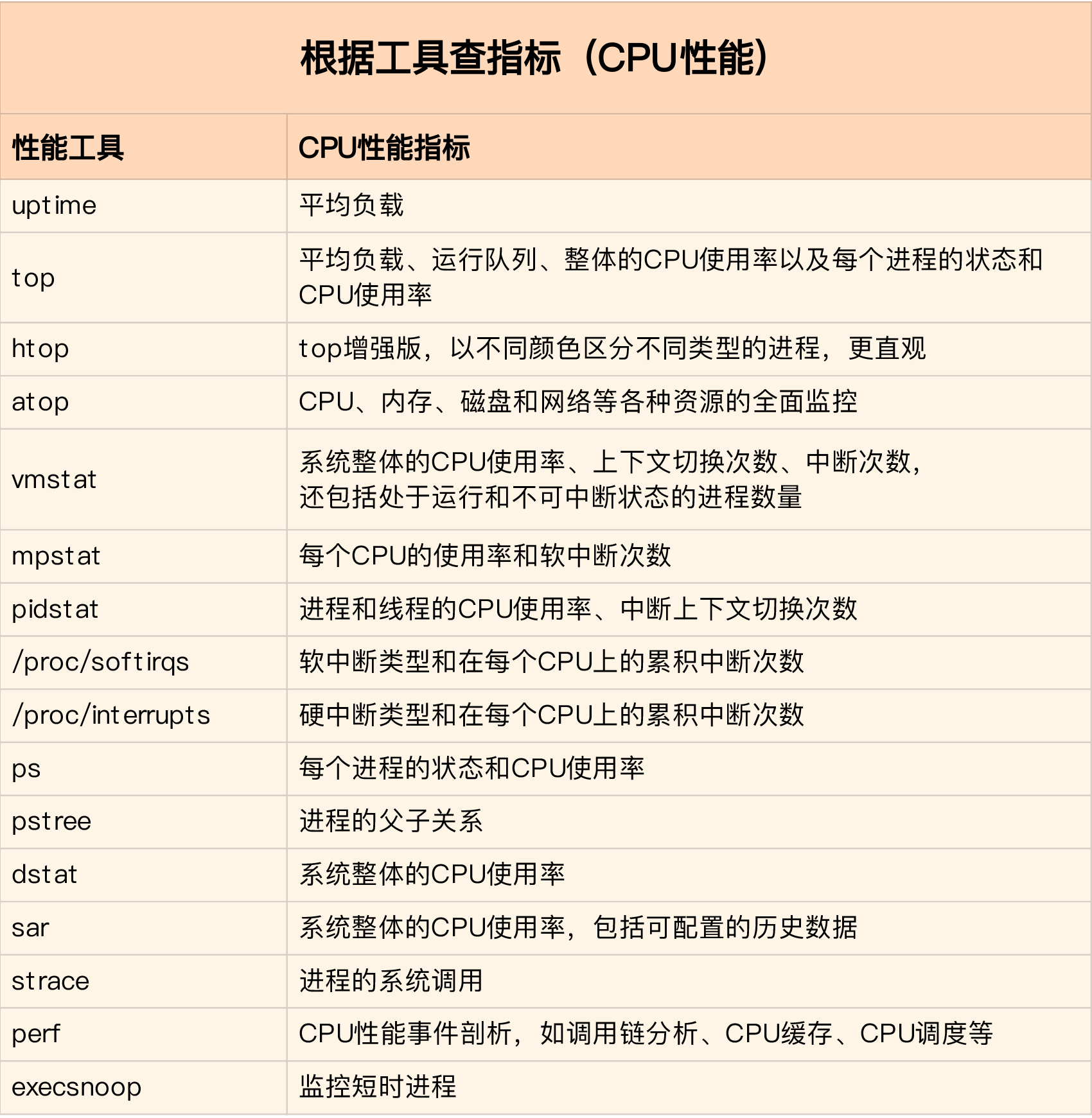
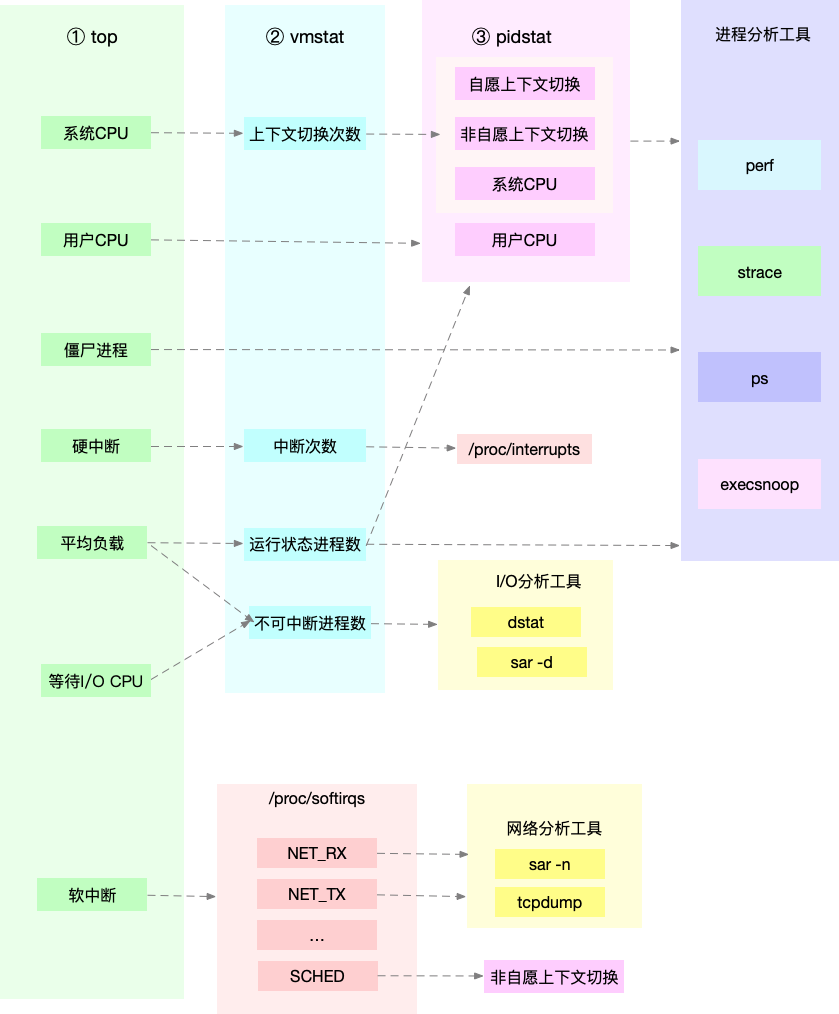
12 | 套路篇:CPU 性能优化的几个思路
过早的优化是万恶之源
优化要选择重要的点
系统级别CPU优化要充分利用CPU缓存和减少进程之间相互影响
- CPU绑定/独占 提高缓存命中率
- 优先级调整 nice
- 进程资源限制
- 中断绑定

