

极客时间专栏——深入剖析kubernetes的阅读笔记
目录:
00 | 开篇词 打通“容器技术”的任督二脉
专栏的主要目的是讲述kubernetes容器栈中与操作系统内核,网络,存储,分布式系统等等技术本质和设计思想
01 | 预习篇 · 小鲸鱼大事记(一):初出茅庐
Cloud Foundry当时也是依赖Cgroup和Namespace,但是是通过push软件包之后创建的,诟病就是如何弄出这个软件包,在社区没有地位的docker开源后镜像成功解决了构建软件包的问题,当然,docker却没有解决容器管理的问题
02 | 预习篇 · 小鲸鱼大事记(二):崭露头角
Docker迅速崛起的原因
- Docker镜像通过技术手段解决了PaaS的根本性问题
- Docker容器同开发者之间有着与生俱来的密切关系
- PaaS概念已经深入人心的完美契机
03 | 预习篇 · 小鲸鱼大事记(三):群雄并起
Docker公司提供了Swarm项目,在收购了Fig项目后推出了Compose,而mesos根据多年的大规模集群的经验提供了独特的竞争力,14年6月google发布了kubernetes
04 | 预习篇 · 小鲸鱼大事记(四):尘埃落定
从API到容器运行时的每一层,Kubernetes项目为开发者暴露出了可以扩展的插件机制,鼓励用户通过代码的方式介入到Kubernetes项目的每个阶段
05 | 白话容器基础(一):从进程说开去
沙盒将应用和应用之间就有了边界,而不相互干扰,而放入沙盒就方便搬来搬去
如果要写一个加法程序,无论使用那些语言来编写,都会以某种方式翻译为二进制文件,在计算机操作系统运行,能够让代码进行运行,还需要提供对应的数据,而数据和程序放在磁盘上,就是我们所说的程序。
执行程序时操作系统发现数据在一个文件中,就会将其加载到内存,同时操作系统又读取到了计算加法的指令,通过CPU完成加法操作。CPU和内存协作进行加法计算,又会使用寄存器存放数值,内存堆栈保存执行的命令和变量,与此同时,计算机内被打开的文件,以及各种各样的IO设备在不断改变自己的状态。
程序被执行起来,就从二进制文件变为计算机中内存中的数据,寄存器中的值,堆栈中的指令,被打开的文件,以及各个设备的状态的一个集合,计算机执行环境的综合就是进程。
进程是程序的动态表现。
容器的核心功能就是通过约束和修改进程的动态表现,从而创造出的边界。对于Linux的容器,Cgroups用于制造约束,而Namespace用于修改进程的视图
$ docker run -it busybox /bin/sh
/ #
-it在容器启动后分配一个文本输入/输出环境(TTY)和容器的标准输入进行联系,而/bin/sh就是docker内部运行的程序
/ # ps
PID USER TIME COMMAND
1 root 0:00 /bin/sh
5 root 0:00 ps
可以看到在容器中最开始执行的/bin/sh为容器的1号进程,而在宿主机上并非如此,Docker将/bin/sh运行在容器中,因为其他进程被容器隔离,容器中没有其他进程,所以在容器中计算进程编号为1,而在宿主机上可定不是1的,这就是Namespace机制。
在Linux创建进程的时候使用的系统调用为clone(),在使用clone函数的时候可以指定CLONE_NEWPID参数,这样创建的进程就是一个全新的进程空间,在这个进程空间中,PID为1。
除了PID,还提供了Mount,UTS,IPC,NetWork和User的Namespace。
在启动容器的时候指定了一系列的Namespace参数,这样当前容器就只能看到Namespace所限制的资源了,而容器对于宿主机来说就是一个特殊的进程,容器中的所有进程都以这个进程为父进程进行创建
06 | 白话容器基础(二):隔离与限制
隔离方面
由于虚拟化存在,虚拟机上运行依然是会对磁盘,网络等请求进行拦截和处理。
对比虚拟机,容器的隔离并不彻底,尽管可以通过Mount Namespace来实现不同的操作系统,还是使用相同的宿主机内核,就会造成了低版本宿主机不能支持高版本容器的部分功能。
很多资源不能被Namespace化,例如时间,如果在容器中调用系统settimeofday(2)系统调用修改了时间,那么宿主机时间也会被修改,所以需要进行限制部署的时候什么可以做而什么不能做,容器暴露出来的攻击面相对于虚拟化来说要大得多。
在生产中如果使用Seccomp等技术进行限制容器内部的系统调用进行过滤加固,就会造成多了一层导致容器性能变差,而且也不知道需要开启那些系统调用,禁止那些系统调用
限制方面
限制就是通过Cgroups,其主要作用是限制一个进程组能够使用的资源上限,例如CPU,内存,磁盘和网络等,还能进行优先级调度,审计,进程挂载恢复等操作
$ mount -t cgroup
缺少cgroup实践
Cgroups对资源的限制能力也有很多不完善的地方,最明显的就是/proc文件系统,在容器中top看到的是宿主机的情况,需要容器单独挂载对应的目录,可以参考lxcfs
07 | 白话容器基础(三):深入理解容器镜像
容器中看到的文件系统和宿主机,是因为Mount Namespace修改的是容器进程对文件系统挂载点的认知,当挂载操作发生之后,进程的视图才会被改变,否则新创建的容器会直接继承各个挂载点
依赖的是chroot和rootfs技术
专栏中有c的代码
容器层的概念
用到的是UnionFS,联合文件系统,目的是使多个不同位置的目录联合挂载(union mount)到同一个目录
$ tree ./
./
├── A
│ ├── a
│ └── b
└── B
├── b
└── c
在ubuntu系统上
$ mkdir C
$ mount -t aufs -o dirs=./A:./B none ./C
$ tree ./C
docker任凭器分层为三种,一种是只读层(ro+wh),一种是init层(以init结尾的ro+wh)层,一种是可读写层(rw)
- 只读层是最下面的层
- init在只读层和可读写层中间,用于存放
/etc/hosts,/etc/resolv.conf等,在commit的时候这层是不会被提交的 - 读写层,读写层进行增改的时候在读写层进行创建新的文件,而删除则创建
.wh.<filename>的文件,在联合挂载时就会没有<filename>的文件
08 | 白话容器基础(四):重新认识Docker容器
docker exec的实现原理
$ docker inspect --format '{{ .State.Pid }}' 4ddf4638572d
25686
通过宿主机查看25686进程的所有Namespace文件
$ ls -l /proc/25686/ns
total 0
lrwxrwxrwx 1 root root 0 Aug 13 14:05 cgroup -> cgroup:[4026531835]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 ipc -> ipc:[4026532278]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 mnt -> mnt:[4026532276]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 net -> net:[4026532281]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 pid -> pid:[4026532279]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 pid_for_children -> pid:[4026532279]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Aug 13 14:05 uts -> uts:[4026532277]
进程的namespace都在对应的/proc/<pid>/ns下有一个对应的虚拟文件,一个进程可以选择的加入到Namespace中,达到进入容器的目的。
使用的是setns()的系统调用,专栏中的有c代码
通过这中方式可以将进程加入到另一个进程的Namespace中,docker run中的-net就是加入到另一容器进程的Network Namespace
Volume的实现
Volume允许将宿主机上指定的目录或者文件挂载到容器中
挂载的时候,容器进程(dockerinit进程而不是应用进程,完成初始化之后会通过execv()系统调用让应用进程取代自己)已经创建,Mount Namespace也就已经创建了,所以挂载只在容器进程中存在,宿主机是看不到这个挂载点的
Linux挂载机制是允许将一个目录或者文件挂载到一个指定目录,对这个目录下的操作都是对挂载点你的操作,而原挂载点的内容会被隐藏起来不受影响。对于一个Linux内核,挂载的本质是一个inode的替换的过程,目录项只是访问这个inode的指针。
对于docker commit是发生在宿主机空间,而挂载是在容器空间,所示宿主机并不知打这个挂载点的存在,所以commit也不会提交,但是目录是会存在的。
docker的copyData功能可以使挂载点文件和挂载目录下的文件同时存在
09 | 从容器到容器云:谈谈Kubernetes的本质
- rootfs构建的是容器镜像,是容器的静态视图
- Namespace和Cgroups构成的隔离环境,是容器的动态视图
在开发-测试-发布的流程中,真正承载的是容器信息进行传递的,是容器镜像,而不是容器进行时
kubernetes基于谷歌内部的Borg系统,在master和node方面就借鉴了Borg系统,在设计之初就没有与其他平台一样以Docker为基础,而是作为容器进行时
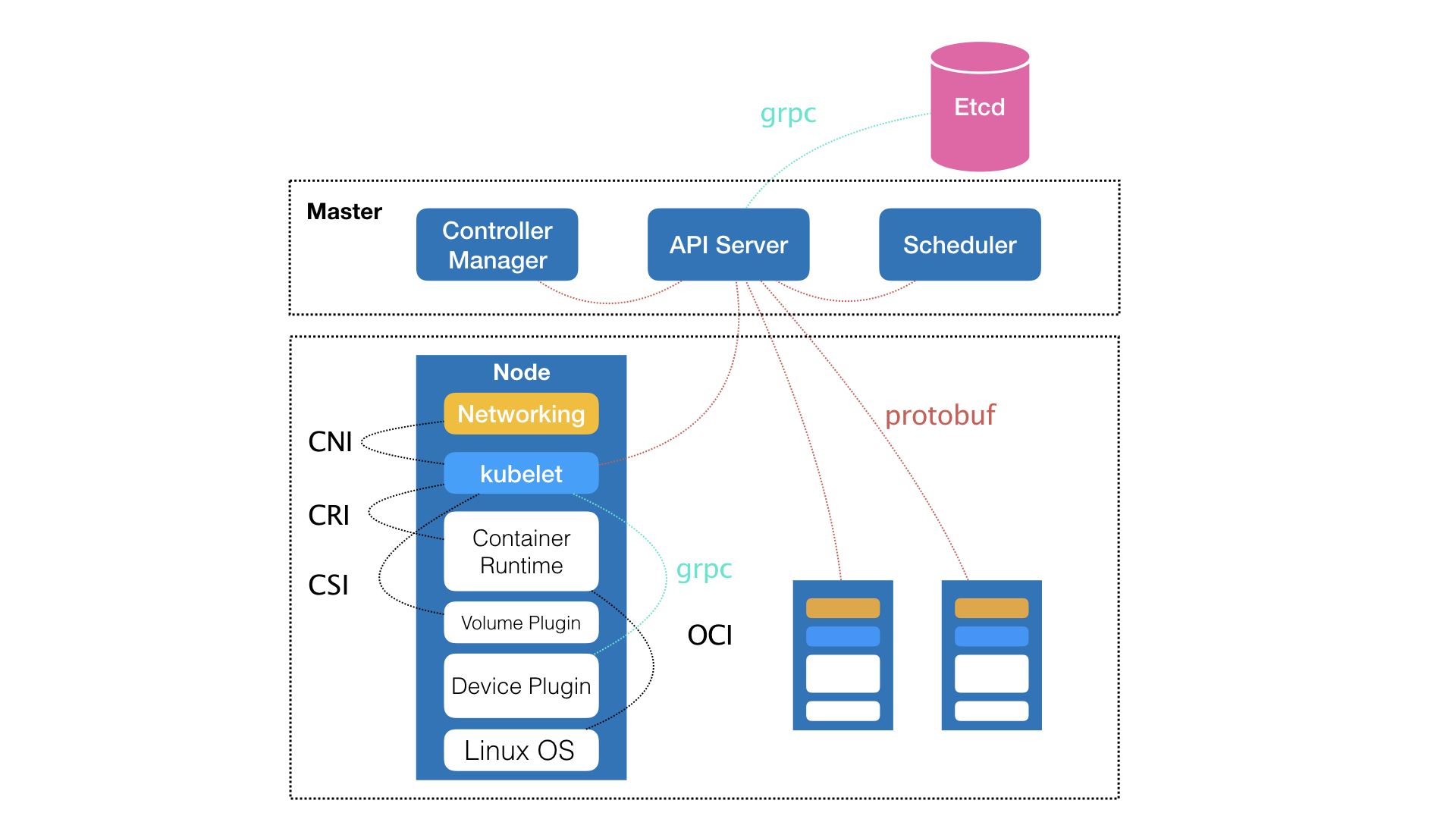
- master的kube-api负责API服务,kube-scheduler负责调度,kube-controller-manager负责容器编排,API处理后持久化的数据放在etcd集群
- node上kubelet负责容器进行时,通过CRI与docker进行打交道,docker会将CRI请求转化为OCI容器运行规范与底层操作系统进行交互,kubelet通过gRPC协议与Device Plugin的插件交互,用来管理GPU宿主机物理设备,CNI和CSI调用网络插件和存储插件为容器配置网络和持久化存储
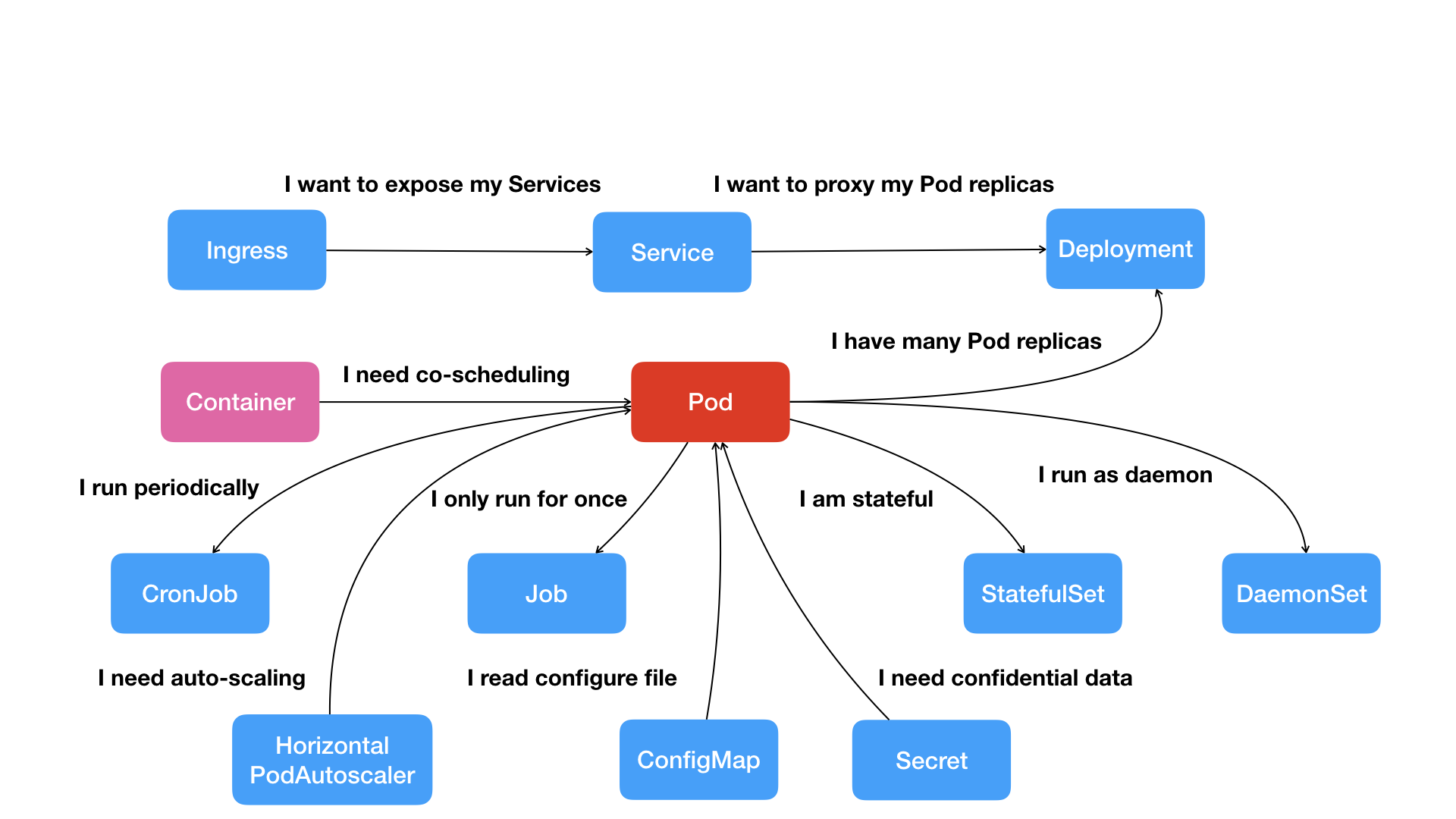
对于常规应用部署在一台机器上,通过localhost进行通信,通过本地磁盘进行文件交换,而Pod就是其在kubernetes中的实现,Pod中的容器共享一个NetWork Namespace,数据卷。
应用之间的访问关系通过Service的机制,提供对Pod的负载均衡和代理功能,为Pod暴露一个固定的网络地址
Pod的扩展依赖Deployment进行管理,HPA负责自动扩容缩容
kubernetes对容器间的访问做了分类,提供了Secret,ConfigMap,Job,CronoJob和DaemonSet等
10 | Kubernetes一键部署利器:kubeadm
早期kubernetes都是通过saltstack和Ansible等运维工具来实现部署,直到2017年才有了kubeadm项目,这个作品是一个17岁的芬兰人用业余时间完成的社区项目
kubeadm的部署只需要两个命令
# 创建一个 Master 节点
$ kubeadm init
# 将一个 Node 节点加入到当前集群中
$ kubeadm join <Master 节点的 IP 和端口 >
kubeadm的原理
kubeadm通过容器部署api-server,kube-scheduler等,但是kubelet由于用于操作Docker,配置网络存储等需要直接操作宿主机,网络可以不挂载Network Namespace,但是隔着Mount Namespace操作宿主机就有了问题,所以现在是一个折中的方式kubelet还是需要手动部署,还有kubeadm和kubectl三个组件
kubeadm部署参数可以在kubeadm init命令指定--config参数
工作流程
- Preflight Checks检查工作,检查内核版本3.10以上,Cgroups模块可用。hostname标准,kubeadm和kubelet版本匹配,工作端口是否被占用,ip和mount等指令存在,Docker安装等
- 生成kubernetes对外提供服务的各种证书 kube-apiserveer的证书ca.crt和kube-apiserver向kubelet请求的证书apiserver-kubelet-client.crt等
- 生成其他组件到kube-apiserver的配置文件
- 为master组件生成Pod配置文件,将配置文件放在mainfests下,使用StaticPod(kubelet启动时会检查这个目录并进行启动这些)
- kubeadm检查api-server:6443/healthz的URL等待master完全启动
- 为集群生成bootstrap token,用于其他节点加入时使用
- 将master节点的重要信息通过ConfigMap的方式存储在Etcd中,名为cluster-info,供后续Node节点使用
- 安装默认插件kube-proxy和DNS
kubeadm join的原理
kubernetes集群加入一个节点必须在kube-apiserver上进行注册,但是与kube-apiserver进行交互需要有对应的CA证书,为了省去拷贝文件这一步骤,使用token的方式请求kube-apiserver并且拿到cluster-info的信息,kubelet就可以以安全模式与kube-apiserver进行通信了
11 | 从0到1:搭建一个完整的Kubernetes集群
全篇在讲kubeadm搭建集群
Dashboard项目在1.7版本之后,为了防止使用公有云将Dashboard外露,默认只能通过proxy方式在本地访问,具体可以参考官方文档
rook项目
Rook项目是一个基于Ceph的Kubernetes存储插件(它后期也在加入对更多存储实现的支持)。不过,不同于对Ceph的简单封装,Rook在自己的实现中加入了水平扩展、迁移、灾难备份、监控等大量的企业级功能,使得这个项目变成了一个完整的、生产级别可用的容器存储插件。
$ kubectl apply -f https://raw.githubusercontent.com/rook/rook/master/cluster/examples/kubernetes/ceph/operator.yaml
$ kubectl apply -f https://raw.githubusercontent.com/rook/rook/master/cluster/examples/kubernetes/ceph/cluster.yaml
Rook项目合理利用了Oprator和CRD实现了扩展等功能
Taint/Toleration
默认情况下master节点是不允许运行Pod的,kubernetes的实现方式就是Taint/Toleration机制
原理就是一个节点一旦被打上了Taint,那么Pod就不能在这个节点运行了,但是Pod可以声明可以容忍那些Taint,即声明了Toleration
节点打Taint
$ kubectl taint nodes node1 foo=bar:NoSchedule
这样node1上就会有一个键值对的taint为foo=bar:NoSchedule,这里NoSchedule代表这个taint只会调度新的Pod的时候启用,不会影响已经在node1上运行的Pod,即使这些Pod上没有声明Toleration
Pod声明Tolerations字段
apiVersion: v1
kind: Pod
...
spec:
tolerations:
- key: "foo"
operator: "Equal"
value: "bar"
effect: "NoSchedule"
operator为Equal代表等于
master上在集群创建之初就被添加了Taint
$ kubectl describe node master
Name: master
Roles: master
Taints: node-role.kubernetes.io/master:NoSchedule
key为node-role.kubernetes.io/master,没有value,其他Pod可以使用operator为Exists(存在)即可
apiVersion: v1
kind: Pod
...
spec:
tolerations:
- key: "foo"
operator: "Exists"
effect: "NoSchedule"
这样Pod就能运行到Master上,当然也可以删除matser节点上的Taint
$ kubectl taint nodes --all node-role.kubernetes.io/master-
这里最后一个短横线'-'为移除
12 | 牛刀小试:我的第一个容器化应用
全篇在讲kubernetes应用部署(略)
13 | 为什么我们需要Pod?
Pod是kubernetes的API调度的最小单位,Pod可以理解为是一个虚拟机,包含一组进程用于完成一个工作。
示例为rsyslogd,由三个进程一个imklog模块,一个imuxsock模块和一个rsyslogd自己的main函数主进程,三个进程需要基于sock进行通信和文件交换,所以三个进程就需要运行在一个虚拟机上。
- 容器为单进程模式,并不是指容器只能运行一个进程,而是容器没有管理多个进程的能力,而PID=1的进程就是应用本身,其他进程都是PID=1的子进程,当这些子进程异常退出,要如何知道并且进行进程的垃圾回收工作就无法完成了
- 如说上述三个容器的内存配额都为1GB,但是有一个Node上有4G内存,另一个Node上有2.5GB内存,如果Docker Swarm来运行,就是让余下的两个容器设置亲密性同时绑定到main容器上,才能完成运行在同一节点,但是执行的顺序是main,然后才是其他两个,如果被调度到2.5GB内存的机器上,最后一个容器就无法运行,这就是成组调度的反面例子,对于Mesos就有了资源囤积的机制等,对于Pod则是在调度的之后Pod就是3GB的需求,就直接被调度到4GB内存的机器
对于这三个容器组成的Pod,一般需要这样实现超亲密关系的特征包括并不限于:
- 互相之间有直接的文件交换
- 会用localhost和Socket文件进行通信
- 会发生频繁的远程调用
- 共享某些Namespace
单一的容器之间会通过Namespace和Cgroups进行隔离,但是Pod是由一个优先启动中间的容器,其他Pod中的容器通过join Network Namespace的方式共享Network Namespace,并且可以声明挂载同一个Volume,这样就实现了容器之间是同等关系而不是拓扑关系的问题了。
优先启动的容器为Infra容器,镜像为k8s.gcr.io/pause,由汇编语言编写,永远处于暂停状态的容器,解压后为100~200KB左右
Pod中的容器
- 可以直接用localhost进行通信
- 网络设备和Infra容器一致
- Pod只有一个IP地址
- Pod生命周期和Infra容器一致
- 容器的流量进出都通过Infra容器完成
最后一点造成为kubernetes开发网络插件的时候考虑的是这个Pod的Network Namespace
Volume的定义也是设计到了Pod层级,然后由容器进行挂载
例子,也是解决了我好久困惑的问题
对于WAR包和Tomcat
- WAR包直接放到Tomcat镜像的webapps目录下直接运行,这样就是每次都要打一个新的镜像
- 不管WAR包,每次只发布Tomcat容器,然后通过Volume的形式挂载,这样就需要维护一个分布式存储
对于Pod来说,直接将WAR包和Tomcat分别做成镜像
apiVersion: v1
kind: Pod
metadata:
name: javaweb-2
spec:
initContainers:
- image: geektime/sample:v2
name: war
command: ["cp", "/sample.war", "/app"]
volumeMounts:
- mountPath: /app
name: app-volume
containers:
- image: geektime/tomcat:7.0
name: tomcat
command: ["sh","-c","/root/apache-tomcat-7.0.42-v2/bin/start.sh"]
volumeMounts:
- mountPath: /root/apache-tomcat-7.0.42-v2/webapps
name: app-volume
ports:
- containerPort: 8080
hostPort: 8001
volumes:
- name: app-volume
emptyDir: {}
第一个容器只有一个WAR包,第二个则是直接使用标准的tomcat镜像。
在Pod中,initContainers定义的容器会比containers先启动,并且按照配置文件配置的启动,直到其退出,才会运行containers定义的容器。initContainers容器启动之后执行了cp /sample.war /app就进行了退出,而后这个/app的目录挂载了一个app-volume的Volume,而tomcat将app-volume挂载到webapps目录下了,这种被称为sidecar,就是启动了一个辅助容器来完成一些主容器之外的工作
日志收集也可以运行一个sidecar容器并声明volume就可以挂载到/var/log或者对应的Pod目录
Istio就是使用sidercar完成微服务治理工作的
14 | 深入解析Pod对象(一):基本概念
Pod中几个重要字段的含义和用法
NodeSelector
NodeSelector是一个供用户将Pod与Node进行绑定的字段
apiVersion: v1
kind: Pod
...
spec:
nodeSelector:
disktype: ssd
这样Pod就只能运行在disktype: ssd标签的Node上了
NodeName
直接指定调度到的NodeName的机器,一般用于调试或者测试
HostAliases
HostAliases定义了Pod中hosts文件的内容
apiVersion: v1
kind: Pod
...
spec:
hostAliases:
- ip: "10.1.2.3"
hostnames:
- "foo.remote"
- "bar.remote"
...
指定了这样一组IP和hostname数据,Pod启动之后看到的文件
cat /etc/hosts
# Kubernetes-managed hosts file.
127.0.0.1 localhost
...
10.244.135.10 hostaliases-pod
10.1.2.3 foo.remote
10.1.2.3 bar.remote
直接修改hosts文件Pod删除和重建就会被覆盖
shareProcessNamespace
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
shareProcessNamespace: true
containers:
- name: nginx
image: nginx
- name: shell
image: busybox
stdin: true
tty: true
意味着Pod里的容器需要共享PID Namespaces
Yaml中还定义了两个容器,一个nginx容器和一个开启了tty和stdin的shell容器
创建了这个容器之后就可以通过kubectl attach命令连接到shell的tty上
$ kubectl attach -it nginx -c shell
Pod需要共享宿主机的Namespace
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
hostNetwork: true
hostIPC: true
hostPID: true
containers:
- name: nginx
image: nginx
- name: shell
image: busybox
stdin: true
tty: true
这样就共享了宿主机的Network,IPC和PID Namespace,这样Pod中容器就可以直接使用宿主机的网络,直接与宿主机进行IPC通信,看到宿主机运行的所有进程
Container
其中有Image镜像,Command启动命令,workingDir容器工作目录,Ports容器需要开放端口,volumeMounts容器要茬的volume等等都是需要关注的
除此之外还有
- ImagePullPolicy定义了镜像拉取策略,默认为Always,就是每次创建Pod都拉取一次新的镜像,当容器拉取类似nginx或者nginx:latest这样的名字也会使用Always,如果设置为Never或者IfNotPresent就意味着Pod永远不会主动拉取,只有在宿主机不存在的时候才进行拉取
- Lifecycle可以添加容器状态变化时的钩子
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
preStop:
exec:
command: ["/usr/sbin/nginx","-s","quit"]
- postStart是在容器启动后立刻完成的操作,但是postStart执行时ENTERPOINT可能还没有结束,如果postStart执行失败,Pod也会处于失败状态
- preStop是在容器被杀死之前完成的操作,会阻塞当前容器被杀死,直到perStop执行完成容器才能被杀死
容器生命周期
- Pending Pod的yaml提交到kubernetes,API对象被保存到etcd,但是Pod因为某种原因不能被顺利创建,例如调度不成功
- Running Pod调度成功,与一个具体节点绑定,包含容器创建成功并至少有一个在启动
- Succeeded Pod中的容器都正常的运行完成并退出,一般为一次性任务
- Failed Pod中至少一个容器为不正常
- Unknown Pod的状态不能通过kubelet持续的汇报给api-server,很有可能是kubelet和Master节点的通信有了问题
Pod除了Status还有Conditions,例如Status为Pending对应的Conditions为Unschedulable则为不能调度,Ready和Running不一样,Ready代表可以提供服务
15 | 深入解析Pod对象(二):使用进阶
Projected Volume
Projected Volume为v1.11版本之后的新特性,作用是为预先定义好的数据供Pod使用,包括四类
- Secret
- ConfigMap
- DownwardAPI
- ServiceAccountToken
Secret是将Pod需要访问的加密数据存储在etcd中,Pod通过挂载Volume的形式访问Secret里的数据,最基本的就是数据库用户名密码的操作了,与环境变量不同的是,一旦Secret的数据发生变化,Volume中数据通过kubelet组件定时维护也随之变化(虽然有些延迟),只需要数据库有重试和超时的逻辑即可。
ConfigMap和Secret类似,只不过是不需要加密的
DownwardAPI能够让Pod获取到Pod的API对象本身的信息
apiVersion: v1
kind: Pod
metadata:
name: test-downwardapi-volume
labels:
zone: us-est-coast
cluster: test-cluster1
rack: rack-22
spec:
containers:
- name: client-container
image: k8s.gcr.io/busybox
command: ["sh", "-c"]
args:
- while true; do
if [[ -e /etc/podinfo/labels ]]; then
echo -en '\n\n'; cat /etc/podinfo/labels; fi;
sleep 5;
done;
volumeMounts:
- name: podinfo
mountPath: /etc/podinfo
readOnly: false
volumes:
- name: podinfo
projected:
sources:
- downwardAPI:
items:
- path: "labels"
fieldRef:
fieldPath: metadata.labels
声明了数据的来源为downwardAPI,需要暴露的为Pod的metadata.labels信息,存放在容器的/etc/podinfo/labels,原理是在Pod启动时候直接将这些信息打印到标准输出,可以通过kubectl logs看到
$ kubectl logs test-downwardapi-volume
cluster="test-cluster1"
rack="rack-22"
zone="us-est-coast"
可以支持的可以参考官方文档
ServiceAccount是在Pod中通过kubernetes的Client直接访问kubernetes的API的过程中,解决API Server授权问题的。kubernetes系统中内置了一种服务账户,是kubernetes进行授权分配的对象,例如ServiceAccount A允许对API进行GET操作,而ServiceAccount B可以对所有API有操作权限。
ServiceAccountToken就是保存ServiceAccount的授权信息和文件的Secret对象,通过Token,才能合法访问API Server
这些配置是在Pod启动的时候会自动挂载一个default-token的volume,这个过程是对用户透明的
$ kubectl describe pod nginx-deployment-5c678cfb6d-lg9lw
Containers:
...
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-s8rbq (ro)
Volumes:
default-token-s8rbq:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-s8rbq
Optional: false
挂载在指定的/var/run/secrets/kubernetes.io/serviceaccount目录下
$ ls /var/run/secrets/kubernetes.io/serviceaccount
ca.crt namespace token
如果使用kubernetes官方的Client包(k8s.io/client-go)会自动加载这下边的文件,这种授权方式被称为InClusterConfig
由于安全问题kubernetes可以设置默认不挂载这个Volume
livenessProbe和readinessProbe
livenessProbe用于容器级别,定义监控监测机制
restartPolicy参数则是定义监测失败后的处理方式,默认为Always
- Always 只要不是Running状态就重启
- OnFailure 只有在异常情况下重启(Pod中有容器异常退出)
- Never 从来不重启
kubernetes介绍了各种的情况,总结一下就是
- 只要Pod的restartPolicy指定的策略允许重启异常的容器(比如:Always),那么这个Pod就会保持Running状态,并进行容器重启。否则,Pod就会进入Failed状态 。
- 对于包含多个容器的Pod,只有它里面所有的容器都进入异常状态后,Pod才会进入Failed状态。在此之前,Pod都是Running状态。此时,Pod的READY字段会显示正常容器的个数
readinessProbe是用于启动的时候进行检测的,如果检测能通过才能被Service访问到,但是检查成功与否并不影响Pod的生命周期
PodPreset
kubernetes的v1.11版本增加了PodPreset(Pod 预设置)的功能,可以使开发人员编写的Pod追加字段
apiVersion: settings.k8s.io/v1alpha1
kind: PodPreset
metadata:
name: allow-database
spec:
selector:
matchLabels:
role: frontend
env:
- name: DB_PORT
value: "6379"
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir: {}
这里实现了env里定义了DB_PORT这个环境变量,volumeMounts定义了容器Volume的挂载目录,volumes定义了一个emptyDir的Volume
selector中的目的是追加的定义,只会作用于带有role: frontend标签的Pod对象,这就可以防止误伤。
创建了这个PodPreset,然后开发人员创建Pod的时候添加对应的label就会自动追加
apiVersion: v1
kind: Pod
metadata:
name: website
labels:
app: website
role: frontend
spec:
...
16 | 编排其实很简单:谈谈“控制器”模型
Deployment是最基本的控制器对象
对比Pod,Deployment只比Pod的配置多了spec.replicas的参数,用于定义Pod的个数,如果维持集群中对应Lalel的Pod数量,kube-controller-manager组件就负责这个功能
源码中也可能看到
$ ls -d kubernetes/pkg/controller/
deployment/ job/ podautoscaler/
cloud/ disruption/ namespace/
replicaset/ serviceaccount/ volume/
cronjob/ garbagecollector/ nodelifecycle/ replication/ statefulset/ daemon/
...
目录下的控制器都遵循kubernetes的一个通用编排模式——控制循环(control loop),对于一个待编排的对象X,使用Go程序的伪代码来描述就是
for {
实际状态 := 获取集群中对象 X 的实际状态(Actual State)
期望状态 := 获取集群中对象 X 的期望状态(Desired State)
if 实际状态 == 期望状态{
什么都不做
} else {
执行编排动作,将实际状态调整为期望状态
}
}
实际状态来自kubelet上报到APi Server或者控制器主动收集,而期望状态来自yaml等创建后保存在Etcd中,编排的过程就在第三步对比阶段完成,删除Pod和增加Pod过程,通常被叫作调谐(Reconcile)。这个调谐的过程,则被称作Reconcile Loop(调谐循环)或者Sync Loop(同步循环)
Deployment的配置文件可以分为控制器定义和被控制对象

17 | 经典PaaS的记忆:作业副本与水平扩展
水平扩展
Deployment实现了Pod的水平扩展和缩容,并且支持滚动更新和回滚,其实是Deployment控制的ReplicaSet来实现的
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-set
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
副本数目的定义和一个Pod模板组成的,是Deployment的一个子集
ReplicaSet对比Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
Deployment和ReplicaSet的关系如下
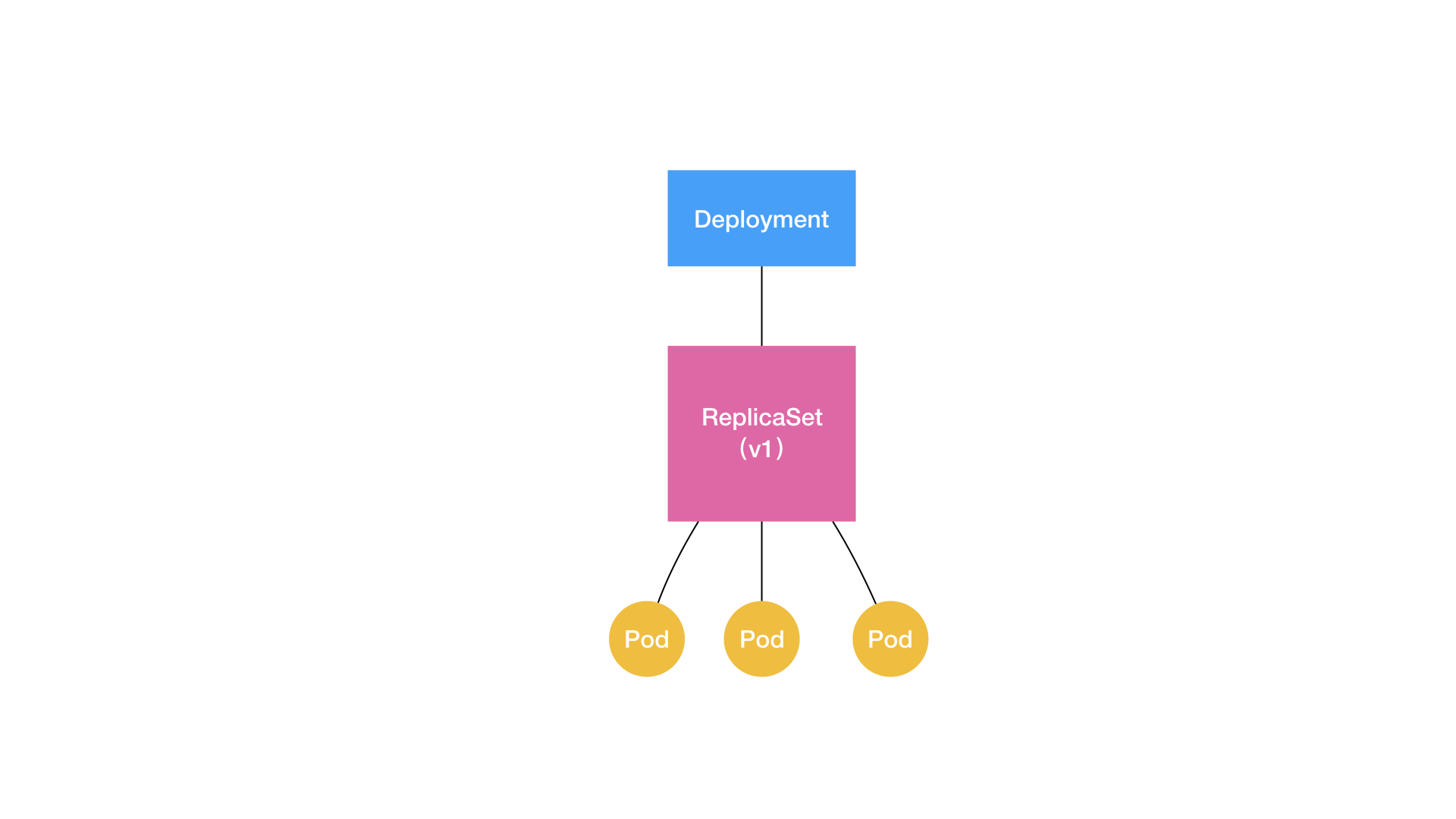
ReplicaSet负责通过控制器模式保证Pod数量,所以Deployment只允许容器的restartPolicy=Always,这样才能保证调整Pod个数才有意义
调整Pod数量可以直接通过修改replicas的数量即可
$ kubectl scale deployment nginx-deployment --replicas=4
滚动更新
创建的时候可以指定--record
$ kubectl create -f nginx-deployment.yaml --record
$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 0 0 0 1s
在返回结果中,四个状态字段含义如下所示。
- DESIRED:用户期望的Pod副本个数(spec.replicas的值)
- CURRENT:当前处于Running状态的Pod的个数
- UP-TO-DATE:当前处于最新版本的Pod的个数,所谓最新版本指的是Pod的Spec部分与Deployment里Pod模板里定义的完全一致
- AVAILABLE:当前已经可用的Pod的个数,即:既是Running状态,又是最新版本,并且已经处于 Ready(健康检查正确)状态的Pod的个数
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-3167673210 3 3 3 20s
在用户提交了一个Deployment对象后,Deployment Controller就会立即创建一个Pod副本个数为3的ReplicaSet。这个ReplicaSet的名字,则是由Deployment的名字和一个随机字符串共同组成
修改可以直接通过kubectl edit修改,或者重新kubectl apply等等,kubectl edit原理就是通过API拉取Deployment到本次临时文件,修改完成再进行提交
这个滚动更新的过程会通过Deployment Controller先创建一个Replicas,初始Pod为0,然后将这个Replicas的Pod变为1,而旧的Replicas的Pod减少一个,这种交替进行的方式就是滚动更新,滚动更新完成后就直接变为旧的Replicas的Pod数量为0,新的Replicas的Pod数量为3。
滚动更新可以在启动的时候检查Pod的启动状态,升级刚开始如果有问题滚动更新就会停止,进而开发和运维就可以进行介入,由于应用还有旧的Pod在线,服务不会受到太大的影响
spec:
...
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
RollingUpdateStrategy的配置中
- maxSurge指定的是除了DESIRED数量之外,在一次“滚动”中,Deployment控制器还可以创建多少个新Pod
- 而maxUnavailable指的是,在一次“滚动”中,Deployment控制器可以删除多少个旧Pod
Deployment和ReplicaSet的关系如下
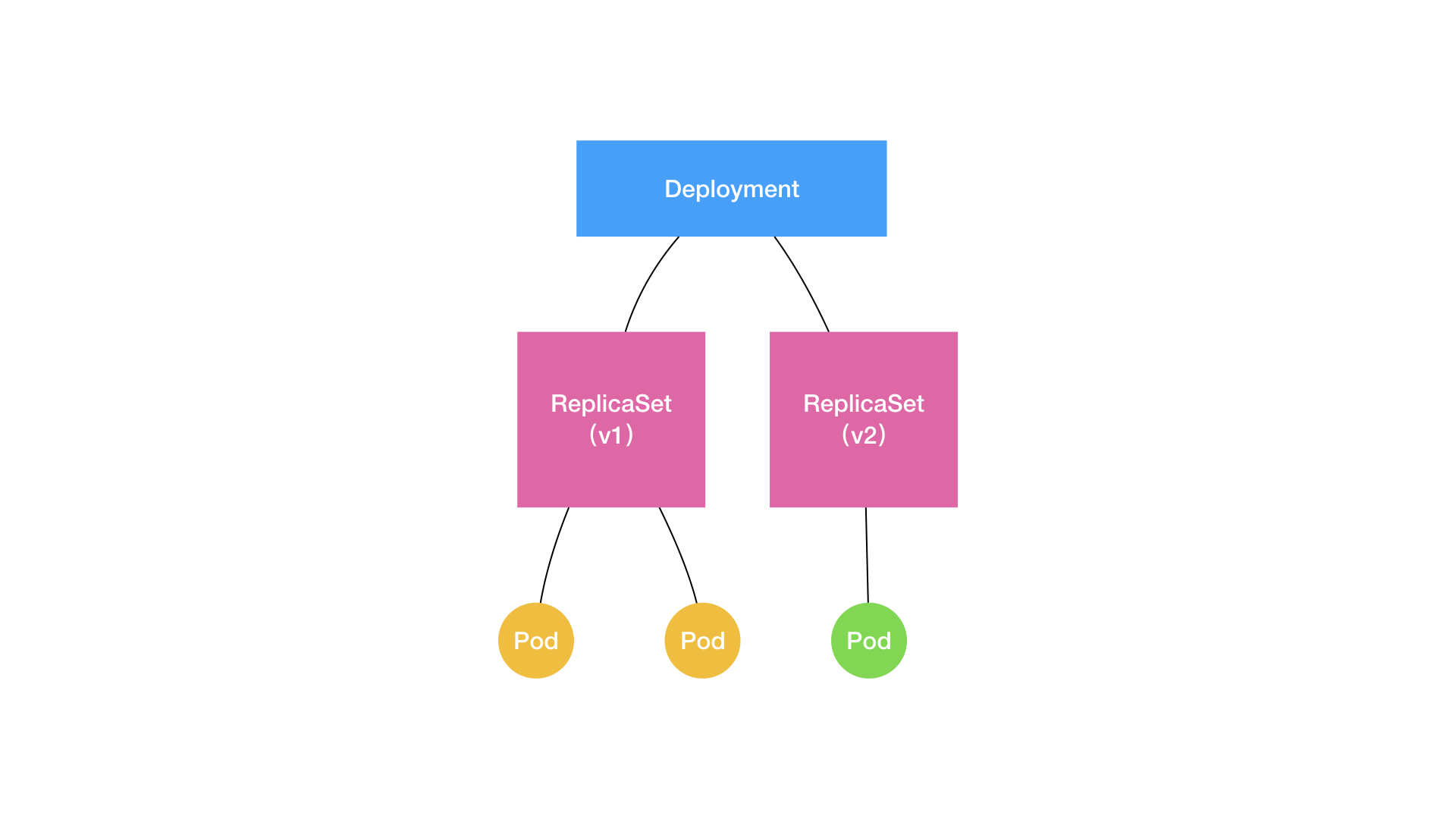
回滚
由于创建deployment的时候指定了–record参数,每次对deployment的操作都会被记录,可以使用kubectl rollout history命令,查看每次Deployment变更对应的版本
$ kubectl rollout history deployment/nginx-deployment
deployments "nginx-deployment"
REVISION CHANGE-CAUSE
1 kubectl create -f nginx-deployment.yaml --record
2 kubectl edit deployment/nginx-deployment
3 kubectl set image deployment/nginx-deployment nginx=nginx:1.91
可以看每个版本的细节
$ kubectl rollout history deployment/nginx-deployment --revision=2
回滚到指定版本
$ kubectl rollout undo deployment/nginx-deployment --to-revision=2
Kubernetes提供了一个指令,使得对Deployment的多次更新操作,最后只生成一个ReplicaSet
$ kubectl rollout pause deployment/nginx-deployment
使deployment进入暂停状态,修改都不会触发ReplicasSet,只有在恢复回来才会创建
$ kubectl rollout resume deploy/nginx-deployment
18 | 深入理解StatefulSet(一):拓扑状态
有状态和无状态
- 实例之间有不对等关系(主从关系、主备关系)以及实例对外部数据有依赖关系的应用被称为有状态应用(Stateful Application)
- 实例没有依赖,没有启动顺序,可以随意杀死或者启动就被称为无状态应用
StatefulSet
StatefulSet抽象了两种情况
- 拓扑状态。这种情况意味着,应用的多个实例之间不是完全对等的关系。这些应用实例,必须按照某些顺序启动,比如应用的主节点A要先于从节点B启动。而如果你把A和B两个Pod删除掉,它们再次被创建出来时也必须严格按照这个顺序才行。并且,新创建出来的Pod,必须和原来Pod的网络标识一样,这样原先的访问者才能使用同样的方法,访问到这个新Pod。
- 存储状态。这种情况意味着,应用的多个实例分别绑定了不同的存储数据。对于这些应用实例来说,Pod A第一次读取到的数据,和隔了十分钟之后再次读取到的数据,应该是同一份,哪怕在此期间Pod A被重新创建过。这种情况最典型的例子,就是一个数据库应用的多个存储实例。
StatefulSet的核心功能,就是通过某种方式记录这些状态,然后在Pod被重新创建时,能够为新Pod恢复这些状态
Service暴露机制
- 以Service的VIP方式,进行请求的转发
- 以Service的DNS方式,获取地址进行访问
而在第二种情况下,也分两种
- Dns解析到Service的VIP,即Normal Service
- Dns解析到Service的Pod IP地址上,Headless Service
创建Service的时候Headless Service的yaml文件
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
通过clusterIP: None定义,Service没有VIP,就是DNS暴露的为Pod的IP地址,访问可以使用<pod-name>.<svc-name>.<namespace>.svc.cluster.local的域名就能通过kubernetes的DNS解析到对应的Pod上
StatefulSet维持Pod的拓扑状态
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.9.1
ports:
- containerPort: 80
name: web
相比Deployment多了一个serviceName: nginx,用于告知StatefulSet控制器,在执行控制循环的时候,用nginx这个Headless Service来保证Pod的可解析身份
$ kubectl create -f svc.yaml
$ kubectl get service nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx ClusterIP None <none> 80/TCP 10s
$ kubectl create -f statefulset.yaml
$ kubectl get statefulset web
NAME DESIRED CURRENT AGE
web 2 1 19s
创建过程可以看到
$ kubectl get pods -w -l app=nginx
NAME READY STATUS RESTARTS AGE
web-0 0/1 Pending 0 0s
web-0 0/1 Pending 0 0s
web-0 0/1 ContainerCreating 0 0s
web-0 1/1 Running 0 19s
web-1 0/1 Pending 0 0s
web-1 0/1 Pending 0 0s
web-1 0/1 ContainerCreating 0 0s
web-1 1/1 Running 0 20s
StatefulSet给管理的Pod添加了编号,编号为<name>-<编号>,这些Pod的创建严格按照编号顺序进行,在web-0为Running状态之前,web-01会一直处于Pending状态
$ kubectl exec web-0 -- sh -c 'hostname'
web-0
$ kubectl exec web-1 -- sh -c 'hostname'
web-1
创建Pod监测一下DNS
$ kubectl run -i --tty --image busybox dns-test --restart=Never --rm /bin/sh
$ nslookup web-0.nginx
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-0.nginx
Address 1: 10.244.1.7
$ nslookup web-1.nginx
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-1.nginx
Address 1: 10.244.2.7
删除这两个Pod
$ kubectl delete pod -l app=nginx
pod "web-0" deleted
pod "web-1" deleted
然后会按照之前的顺序重新创建Pod
$ kubectl run -i --tty --image busybox dns-test --restart=Never --rm /bin/sh
$ nslookup web-0.nginx
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-0.nginx
Address 1: 10.244.1.8
$ nslookup web-1.nginx
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-1.nginx
Address 1: 10.244.2.8
并没有讲主从如何实现
19 | 深入理解StatefulSet(二):存储状态
Pod对声明的Volume可以直接挂载,但是例如Ceph的RBD类型的Volume会暴露公司基础设施
apiVersion: v1
kind: Pod
metadata:
name: rbd
spec:
containers:
- image: kubernetes/pause
name: rbd-rw
volumeMounts:
- name: rbdpd
mountPath: /mnt/rbd
volumes:
- name: rbdpd
rbd:
monitors:
- '10.16.154.78:6789'
- '10.16.154.82:6789'
- '10.16.154.83:6789'
pool: kube
image: foo
fsType: ext4
readOnly: true
user: admin
keyring: /etc/ceph/keyring
imageformat: "2"
imagefeatures: "layering"
就引入了PV和PVC(Persistent Volume Claim)的概念
开发想要使用一个Volume只需要
- 定义一个PVC
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pv-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
- storage: 1Gi,表示我想要的Volume大小至少是1GiB
- accessModes: ReadWriteOnce,表示挂载是可读写的,但是只能被挂载到一个节点
PVC与PV绑定成功后,就会进入Bound状态,这就意味着Pod可以挂载并使用这个PV了。
- 在Pod中应用这个PVC
apiVersion: v1
kind: Pod
metadata:
name: pv-pod
spec:
containers:
- name: pv-container
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: pv-storage
volumes:
- name: pv-storage
persistentVolumeClaim:
claimName: pv-claim
在Volume中声明类型为persistentVolumeClaim,指定pvc的名字
这些符合条件的Volume的来源是维护的PV对象
kind: PersistentVolume
apiVersion: v1
metadata:
name: pv-volume
labels:
type: local
spec:
capacity:
storage: 10Gi
rbd:
monitors:
- '10.16.154.78:6789'
- '10.16.154.82:6789'
- '10.16.154.83:6789'
pool: kube
image: foo
fsType: ext4
readOnly: true
user: admin
keyring: /etc/ceph/keyring
imageformat: "2"
imagefeatures: "layering"
PV和PVC的设计类似接口和实现的思想,开发只需要会通过PVC调用接口,运维负责提供PVC接口绑定的PVC,对于某些公有云可以通过Dynamic Provisioning直接提供PVC
而通过StatefulSet创建的Pod
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.9.1
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
通过statefulSet创建的PVC,会按照<PVC 名字 >-<StatefulSet 名字 >-< 编号 >的格式创建,创建的Pod会根据对应的编号挂载PVC所绑定的PV上,让Pod被删除之后,重新创建的Pod依然会挂载这个PVC,进而获取保留在Volume中的数据,进而完成了对存储状态的管理
20 | 深入理解StatefulSet(三):有状态应用实践
案例通过StatefulSet部署一个MySQL集群,相比Etcd,Cassandra等原生就考虑了分布式的项目,MySQL在分布式集群搭建不是很友好
描述MySQL集群需求
- 主从复制,有个主节点多个从节点
- 从节点水平能扩展
- 主节点写入,从节点读取
实施流程
- 安装好master节点通过XtraBackup将master节点的数据备份到指定目录
$ cat xtrabackup_binlog_info
TheMaster-bin.000001 481
- 配置Slave节点
TheSlave|mysql> CHANGE MASTER TO
MASTER_HOST='$masterip',
MASTER_USER='xxx',
MASTER_PASSWORD='xxx',
MASTER_LOG_FILE='TheMaster-bin.000001',
MASTER_LOG_POS=481;
- 启动从节点
TheSlave|mysql> START SLAVE;
- 增加更多的从节点
在这个实施流程中遇到的三个主要问题
- 主从节点配置不一致
- Master节点和Slave节点能够完成数据传输
- Slave节点在第一次启动要执行初始化SQL
解决主从节点配置不一致
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
labels:
app: mysql
data:
master.cnf: |
# 主节点 MySQL 的配置文件 使用二进制日志文件的方式进行主从复制
[mysqld]
log-bin
slave.cnf: |
# 从节点 MySQL 的配置文件 从节点拒绝除了主节点的数据同步操作之外的所有写操作
[mysqld]
super-read-only
通过Stateful创建的集群会根据编号顺序来创建,Pod的初始化需要通过initContainer来完成
...
# template.spec
initContainers:
- name: init-mysql
image: mysql:5.7
command:
- bash
- "-c"
- |
set -ex
# 从 Pod 的序号,生成 server-id
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
echo [mysqld] > /mnt/conf.d/server-id.cnf
# 由于 server-id=0 有特殊含义,我们给 ID 加一个 100 来避开它
echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf
# 如果 Pod 序号是 0,说明它是 Master 节点,从 ConfigMap 里把 Master 的配置文件拷贝到 /mnt/conf.d/ 目录;
# 否则,拷贝 Slave 的配置文件
if [[ $ordinal -eq 0 ]]; then
cp /mnt/config-map/master.cnf /mnt/conf.d/
else
cp /mnt/config-map/slave.cnf /mnt/conf.d/
fi
volumeMounts:
- name: conf
mountPath: /mnt/conf.d
- name: config-map
mountPath: /mnt/config-map
init-mysql通过hostname获取Pod的序号,写入server-id,如果序号为0就拷贝从定义的master的ConfigMap中的master.cnf,否则就拷贝slave.cnf
...
# template.spec
volumes:
- name: conf
emptyDir: {}
- name: config-map
configMap:
name: mysql
基于Pod Volume共享的原理,当InitContainer复制完配置文件退出后,后面启动的MySQL容器只需要直接声明挂载这个名叫conf的Volume,它所需要的.cnf配置文件已经出现在里面了。
解决Master节点和Slave节点能够完成数据传输
定义第二个InitContainer
...
# template.spec.initContainers
- name: clone-mysql
image: gcr.io/google-samples/xtrabackup:1.0
command:
- bash
- "-c"
- |
set -ex
# 拷贝操作只需要在第一次启动时进行,所以如果数据已经存在,跳过
[[ -d /var/lib/mysql/mysql ]] && exit 0
# Master 节点 (序号为 0) 不需要做这个操作
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
[[ $ordinal -eq 0 ]] && exit 0
# 使用 ncat 指令,远程地从前一个节点拷贝数据到本地
ncat --recv-only mysql-$(($ordinal-1)).mysql 3307 | xbstream -x -C /var/lib/mysql
# 执行 --prepare,这样拷贝来的数据就可以用作恢复了
xtrabackup --prepare --target-dir=/var/lib/mysql
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
xtrabackup镜像内置了xtrabackup命令,使用ncat指令,向DNS记录为mysql-<当前序号减一>.mysql的Pod,也就是当前Pod的前一个Pod,发起数据传输请求,并且直接用xbstream指令将收到的备份数据保存在/var/lib/mysql目录下,3307是一个特殊端口,运行着一个专门负责备份MySQL数据的辅助进程
/var/lib/mysql作为一个PVC,数据就可以持久化存储了
Slave节点在第一次启动要执行初始化SQL
容器是一个单进程模型,Slave容器启动之前需要通过sidecar容器完成初始化
...
# template.spec.containers
- name: xtrabackup
image: gcr.io/google-samples/xtrabackup:1.0
ports:
- name: xtrabackup
containerPort: 3307
command:
- bash
- "-c"
- |
set -ex
cd /var/lib/mysql
# 从备份信息文件里读取 MASTER_LOG_FILEM 和 MASTER_LOG_POS 这两个字段的值,用来拼装集群初始化 SQL
if [[ -f xtrabackup_slave_info ]]; then
# 如果 xtrabackup_slave_info 文件存在,说明这个备份数据来自于另一个 Slave 节点。这种情况下,XtraBackup 工具在备份的时候,就已经在这个文件里自动生成了 "CHANGE MASTER TO" SQL 语句。所以,我们只需要把这个文件重命名为 change_master_to.sql.in,后面直接使用即可
mv xtrabackup_slave_info change_master_to.sql.in
# 所以,也就用不着 xtrabackup_binlog_info 了
rm -f xtrabackup_binlog_info
elif [[ -f xtrabackup_binlog_info ]]; then
# 如果只存在 xtrabackup_binlog_inf 文件,那说明备份来自于 Master 节点,我们就需要解析这个备份信息文件,读取所需的两个字段的值
[[ `cat xtrabackup_binlog_info` =~ ^(.*?)[[:space:]]+(.*?)$ ]] || exit 1
rm xtrabackup_binlog_info
# 把两个字段的值拼装成 SQL,写入 change_master_to.sql.in 文件
echo "CHANGE MASTER TO MASTER_LOG_FILE='${BASH_REMATCH[1]}',\
MASTER_LOG_POS=${BASH_REMATCH[2]}" > change_master_to.sql.in
fi
# 如果 change_master_to.sql.in,就意味着需要做集群初始化工作
if [[ -f change_master_to.sql.in ]]; then
# 但一定要先等 MySQL 容器启动之后才能进行下一步连接 MySQL 的操作
echo "Waiting for mysqld to be ready (accepting connections)"
until mysql -h 127.0.0.1 -e "SELECT 1"; do sleep 1; done
echo "Initializing replication from clone position"
# 将文件 change_master_to.sql.in 改个名字,防止这个 Container 重启的时候,因为又找到了 change_master_to.sql.in,从而重复执行一遍这个初始化流程
mv change_master_to.sql.in change_master_to.sql.orig
# 使用 change_master_to.sql.orig 的内容,也是就是前面拼装的 SQL,组成一个完整的初始化和启动 Slave 的 SQL 语句
mysql -h 127.0.0.1 <<EOF
$(<change_master_to.sql.orig),
MASTER_HOST='mysql-0.mysql',
MASTER_USER='root',
MASTER_PASSWORD='',
MASTER_CONNECT_RETRY=10;
START SLAVE;
EOF
fi
# 使用ncat监听3307端口。它的作用是,在收到传输请求的时候,直接执行"xtrabackup --backup"命令,备份MySQL的数据并发送给请求者
exec ncat --listen --keep-open --send-only --max-conns=1 3307 -c \
"xtrabackup --backup --slave-info --stream=xbstream --host=127.0.0.1 --user=root"
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
先对从master同步来的数据还是slave节点同步的数据进行区分,生成change_master_to.sql.in文件,然后通过这个文件进行slave初始化,并将这个脚本改名,防止重启Pod后再度初始化,然后启动一个用于数据传输的端口3307,作用是一旦有请求执行xtrabackup --backup命令备份数据并返回给请求者
sidecar容器和MySQL容器同处于一个Pod里,所以它是直接通过Localhost来访问和备份MySQL容器里的数据的
MySQL使用标准的MySQL5.7的容器镜像
...
# template.spec
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ALLOW_EMPTY_PASSWORD
value: "1"
ports:
- name: mysql
containerPort: 3306
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
resources:
requests:
cpu: 500m
memory: 1Gi
livenessProbe:
exec:
command: ["mysqladmin", "ping"]
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
readinessProbe:
exec:
# 通过 TCP 连接的方式进行健康检查
command: ["mysql", "-h", "127.0.0.1", "-e", "SELECT 1"]
initialDelaySeconds: 5
periodSeconds: 2
timeoutSeconds: 1
对应的Service
apiVersion: v1
kind: Service
metadata:
name: mysql
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
clusterIP: None
selector:
app: mysql
---
apiVersion: v1
kind: Service
metadata:
name: mysql-read
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
selector:
app: mysql
可以直接使用创建PV
$ kubectl create -f rook-storage.yaml
$ cat rook-storage.yaml
apiVersion: ceph.rook.io/v1beta1
kind: Pool
metadata:
name: replicapool
namespace: rook-ceph
spec:
replicated:
size: 3
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-ceph-block
provisioner: ceph.rook.io/block
parameters:
pool: replicapool
clusterNamespace: rook-ceph
用到了StorageClass来完成这个操作。它的作用,是自动地为集群里存在的每一个PVC,调用存储插件(Rook)创建对应的PV,从而省去了我们手动创建PV的机械劳动
验证一下
$ kubectl run mysql-client --image=mysql:5.7 -i --rm --restart=Never --\
mysql -h mysql-0.mysql <<EOF
CREATE DATABASE test;
CREATE TABLE test.messages (message VARCHAR(250));
INSERT INTO test.messages VALUES ('hello');
EOF
扩容
$ kubectl scale statefulset mysql --replicas=5
读取测试数据
$ kubectl run mysql-client --image=mysql:5.7 -i -t --rm --restart=Never --\
mysql -h mysql-3.mysql -e "SELECT * FROM test.messages"
Waiting for pod default/mysql-client to be running, status is Pending, pod ready: false
+---------+
| message |
+---------+
| hello |
+---------+
pod "mysql-client" deleted
设计思路为
- Pod在扮演不同角色时的不同操作
- 很多“有状态应用”的节点,只是在第一次启动的时候才需要做额外处理。所以,在编写YAML文件时,一定要考虑“容器重启”的情况,不要让这一次的操作干扰到下一次的容器启动
- 通过InitContainer对容器进行区分
如果StatefulSet不能满足的可能需要Operator来实现了
例如主节点挂掉从slave升为master,读的时候读slave节点
21 | 容器化守护进程的意义:DaemonSet
StatefulSet滚动更新
以补丁的方式修改StatefulSet
$ kubectl patch statefulset mysql --type='json' -p='[{"op": "replace", "path": "/spec/template/spec/containers/0/image", "value":"mysql:5.7.23"}]'
statefulset.apps/mysql patched
StatefulSet Controller就会按照与Pod编号相反的顺序,从最后一个Pod开始,逐一更新这个StatefulSet管理的每个Pod。而如果更新发生了错误,这次“滚动更新”就会停止
StatefulSet还允许指定一部分不会更新到最新的版本
$ kubectl patch statefulset mysql -p '{"spec":{"updateStrategy":{"type":"RollingUpdate","rollingUpdate":{"partition":2}}}}'
statefulset.apps/mysql patched
修改spec.updateStrategy.rollingUpdate的partition字段为2,再进行Pod模板修改的时候,只有大于等于2的编号的Pod才会被修改
DaemonSet
DaemonSet是让每个Node上都运行一个所定义的Pod,特征为
- 运行在Kubernetes集群里的每一个节点
- 每个节点上只有一个这样的Pod实例
- 当有新的节点加入Kubernetes集群后,该Pod会自动地在新节点上被创建出来;而当旧节点被删除后,它上面的Pod也相应地会被回收掉
网络插件,存储插件Agent和监控日志组件都是以这种方式运行在每一个节点
在创建集群的时候,容器之间网络还不互通,创建其他类型Pod都是失败的,这时创建DaemonSet类型的网络Pod却可以
DaemonSet也是一个典型的“控制器模型”能够处理的问题
- DaemonSet Controller首先从Etcd里获取所有的Node列表
- 有这种Pod,但是数量大于1,那就说明要把多余的Pod从这个Node上删除掉
- 正好只有一个这种Pod,那说明这个节点是正常的
在Node上创建Pod,以前的nodeSelector已经快被舍弃了,新的字段为nodeAffinity
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: metadata.name
operator: In
values:
- node-geektime
Pod声明了一个spec.affinity字段,定义了nodeAffinity
- requiredDuringSchedulingIgnoredDuringExecution 这个nodeAffinity必须在每次调度的时候予以考虑。同时,这也意味着你可以设置在某些情况下不考虑这个nodeAffinity
- 这个Pod,将来只允许运行在“metadata.name”是“node-geektime”的节点上
当DaemonSet在创建的时候Pod的时候自动添加了nodeAffinity的定义,其中需要绑定的Node就是遍历Etcd中获取的Node。
另外还会给这个Pod对象加上一个tolerations字段,允许有指定Taint的Node上运行
apiVersion: v1
kind: Pod
metadata:
name: with-toleration
spec:
tolerations:
- key: node.kubernetes.io/unschedulable
operator: Exists
effect: NoSchedule
这些taint也可以理解为一个特殊的label
对于网络插件的DaemonSet就需要Pod容忍node.kubernetes.io/network-unavailable
...
template:
metadata:
labels:
name: network-plugin-agent
spec:
tolerations:
- key: node.kubernetes.io/network-unavailable
operator: Exists
effect: NoSchedule
当节点没有网络插件就会有这个Taint
在Kubernetes v1.11之前,由于调度器尚不完善,DaemonSet是由DaemonSet Controller自行调度的,即它会直接设置Pod的spec.nodename字段,这样就可以跳过调度器了。
对于DaemonSet,版本的维护通过v1.7版本之后提供的ControllerRevision,用来专门记录Controller对象的版本
$ kubectl create -f fluentd-elasticsearch.yaml
$ kubectl set image ds/fluentd-elasticsearch fluentd-elasticsearch=k8s.gcr.io/fluentd-elasticsearch:v2.2.0 --record -n=kube-system
$ kubectl rollout status ds/fluentd-elasticsearch -n kube-system
Waiting for daemon set "fluentd-elasticsearch" rollout to finish: 0 out of 2 new pods have been updated...
Waiting for daemon set "fluentd-elasticsearch" rollout to finish: 0 out of 2 new pods have been updated...
Waiting for daemon set "fluentd-elasticsearch" rollout to finish: 1 of 2 updated pods are available...
daemon set "fluentd-elasticsearch" successfully rolled out
$ kubectl rollout history daemonset fluentd-elasticsearch -n kube-system
daemonsets "fluentd-elasticsearch"
REVISION CHANGE-CAUSE
1 <none>
2 kubectl set image ds/fluentd-elasticsearch fluentd-elasticsearch=k8s.gcr.io/fluentd-elasticsearch:v2.2.0 --namespace=kube-system --record=true
# 查看controllerrevision
$ kubectl get controllerrevision -n kube-system -l name=fluentd-elasticsearch
NAME CONTROLLER REVISION AGE
fluentd-elasticsearch-64dc6799c9 daemonset.apps/fluentd-elasticsearch 2 1h
如果通过describe命令就可以看到ControllerRevision对象,实际上是在Data字段保存了该版本对应的完整的DaemonSet的API对象,在Annotation字段保存了创建这个对象所使用的kubectl命令
22 | 撬动离线业务:Job与CronJob
Job
对比Deployment,StatefulSet和DaemonSet,都是启动就保持运行状态,不能满足离线任务
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: resouer/ubuntu-bc
command: ["sh", "-c", "echo 'scale=10000; 4*a(1)' | bc -l "]
restartPolicy: Never
backoffLimit: 4
计算π值的容器,输出小数点后10000位
$ kubectl describe jobs/pi
Name: pi
Namespace: default
Selector: controller-uid=c2db599a-2c9d-11e6-b324-0209dc45a495
Labels: controller-uid=c2db599a-2c9d-11e6-b324-0209dc45a495
job-name=pi
Annotations: <none>
Parallelism: 1
Completions: 1
..
Pods Statuses: 0 Running / 1 Succeeded / 0 Failed
Pod Template:
Labels: controller-uid=c2db599a-2c9d-11e6-b324-0209dc45a495
job-name=pi
Containers:
...
Volumes: <none>
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
1m 1m 1 {job-controller } Normal SuccessfulCreate Created pod: pi-rq5rl
Job对象在创建后,它的Pod模板,被自动加上了一个controller-uid=<一个随机字符串> 这样的Label。而这个Job对象本身,则被自动加上了这个Label对应的Selector,从而 保证了Job与它所管理的Pod之间的匹配关系。
任务完成后Pod会变为Completed状态,restartPolicy在Job对象里只允许被设置为Never和OnFailure;而在Deployment对象里,restartPolicy则只允许被设置为Always,如果设置为Always则会一直重启再次运行,如果定义 restartPolicy=OnFailure,那么离线作业失败后,Job Controller就不会去尝试创建新的Pod。但是,它会不断地尝试重启Pod里的容器
- backoffLimit=4用于设置最大尝试次数,默认为6,创建Pod的间隔是呈指数增加的,分别发生在10s、20s、40s后
- spec.activeDeadlineSeconds 字段可以设置最长运行时间
spec:
backoffLimit: 5
activeDeadlineSeconds: 100
一旦超过100s,Job的所有Pod都会停止
并行控制的参数
- spec.parallelism,它定义的是一个Job在任意时间最多可以启动多少个Pod同时运行
- spec.completions,它定义的是Job至少要完成的Pod数目,即Job的最小完成数
JobController控制的对象,直接就是Pod
spec:
parallelism: 2
completions: 4
对于以上参数创建的Pod数目 = 最终需要的Pod数目 - 实际在Running状态Pod数目 - 已经成功退出的Pod数目 = 4 - 0 - 0 = 4
但是由于parallelism=2,所以每次就只会创建2个Pod
Job的常用放法有三种
- 外部管理器(例如for循环) + Job模板
- 拥有固定任务数目的并行Job(例如从消息队列读取数据处理后退出)
- 多个并行Job
2对应的处理,处理完成就退出
queue := newQueue($BROKER_URL, $QUEUE)
task := queue.Pop()
process(task)
exit
3对应的处理,只有队列为空才退出
for !queue.IsEmpty($BROKER_URL, $QUEUE) {
task := queue.Pop()
process(task)
}
print("Queue empty, exiting")
exit
CronJob
定时任务,通过CronJob控制Job实现
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
由于定时任务的特殊性,很可能某个Job还没有执行完,另外一个新Job就产生了,可以配置spec.concurrencyPolicy字段
- concurrencyPolicy=Allow,这也是默认情况,这意味着这些Job可以同时存在
- concurrencyPolicy=Forbid,这意味着不会创建新的Pod,该创建周期被跳过
- concurrencyPolicy=Replace,这意味着新产生的Job会替换旧的、没有执行完的Job
如果某一次Job创建失败,这次创建就会被标记为“miss”。当在指定的时间窗口内,miss的数目达到100时,那么CronJob会停止再创建这个Job,这个时间窗口,可以由spec.startingDeadlineSeconds字段指定。比如startingDeadlineSeconds=200,意味着在过去200s里,如果miss的数目达到了100次,那么这个Job就不会被创建执行了
23 | 声明式API与Kubernetes编程范式
声明式API
先看一下docker swarm的编排
$ docker service create --name nginx --replicas 2 nginx
$ docker service update --image nginx:1.7.9 nginx
kubernetes也有对应的命令,但是kubernetes有apply的指令,执行了一个对原有API对象的PATCH操作。
对于replace等操作,对api-server都是一次写请求,而不会apply一次可以处理多个写请求,并且具备Merge能力
Istio
2017年5月,Google、IBM和Lyft公司,共同宣布了Istio开源项目的诞生,是一个基于Kubernetes项目的微服务治理框架,架构如下所示
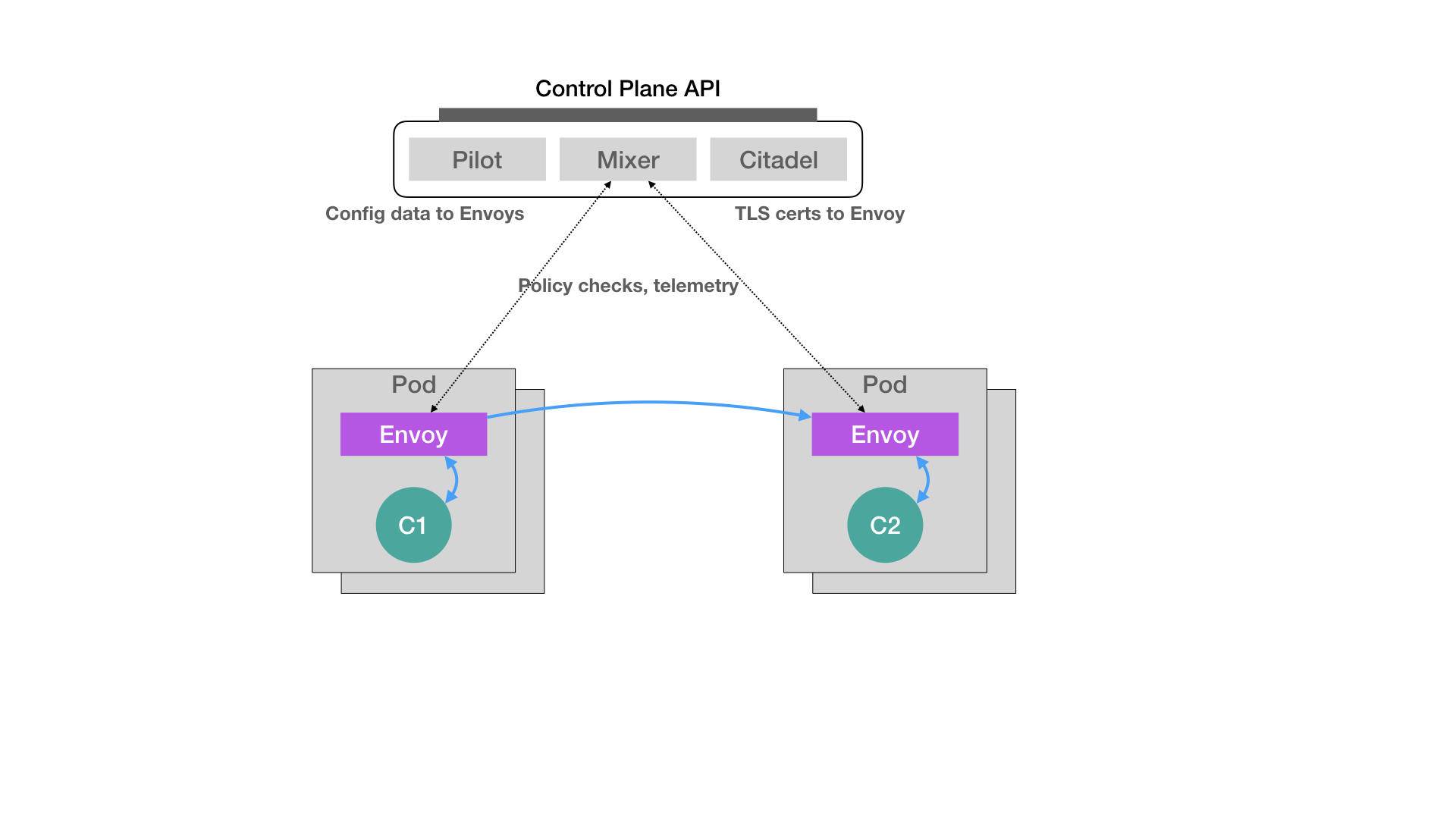
Istio最核心的组件是每个Pod中的Envoy容器,Envoy项目是Lyft公司推出的一个C++网络代理,代理服务以sidecar的方式运行在被治理的Pod上,原理是Pod中的所有容器都共享一个Network Namespace,Envoy容器可以直接通过配置Pod的防火墙规则来接管Pod的进出流量
Istio的控制层(Control Plane)里的 Pilot组件就可以通过调用Envoy容器的API来实现代理的配置,从而实现微服务治理
假设刚才的架构,左边是原有Pod,右边是新上的Pod,可以左边分配90%流量,右边分配10%流量,一个典型会灰度发布,之后就可以调整为70%和30%,50%和50%
在微服务治理的过程中,Envoy容器的部署及其代理的配置都是无感的,使用了kubernetes的一个Dynamic Admission Control功能,当一个Pod或者其他API对象被提交到APIServer之后会进行一些初始化操作,例如加上Label标签等
一种方式是将实现的代码编译进APIServer,另一种就是使用一种“热插拔”式的 Admission 机制Dynamic Admission Control,也被称为Initializer
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox
command: ['sh', '-c', 'echo Hello Kubernetes! && sleep 3600']
Istio做的就是在这个yaml提交到APIServer之后,在它对应的API对象加上Envoy容器的配置
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox
command: ['sh', '-c', 'echo Hello Kubernetes! && sleep 3600']
- name: envoy
image: lyft/envoy:845747b88f102c0fd262ab234308e9e22f693a1
command: ["/usr/local/bin/envoy"]
...
Istio实现的就是编译一个为Pod注入Envoy容器的Initializer
首先将这个配置存储在ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: envoy-initializer
data:
config: |
containers:
- name: envoy
image: lyft/envoy:845747db88f102c0fd262ab234308e9e22f693a1
command: ["/usr/local/bin/envoy"]
args:
- "--concurrency 4"
- "--config-path /etc/envoy/envoy.json"
- "--mode serve"
ports:
- containerPort: 80
protocol: TCP
resources:
limits:
cpu: "1000m"
memory: "512Mi"
requests:
cpu: "100m"
memory: "64Mi"
volumeMounts:
- name: envoy-conf
mountPath: /etc/envoy
volumes:
- name: envoy-conf
configMap:
name: envoy
ConfigMap的data为Pod的container定义,initializer做的就是将这部分添加到用户提交的Pod的API对象,通过声明式API把两部分中的内容Merge
然后Istio将一个编写好的Initializer作为一个Pod部署到kubernetes
apiVersion: v1
kind: Pod
metadata:
labels:
app: envoy-initializer
name: envoy-initializer
spec:
containers:
- name: envoy-initializer
image: envoy-initializer:0.0.1
imagePullPolicy: Always
envoy-initializer:0.0.1镜像就是一个实现编写好的自定义控制器
Initializer控制器的主要功能就是,不断获取实际状态(用户新创建的Pod),期望状态则是在Pod中添加Envoy容器的定义
Go语言风格的伪代码解释
for {
// 获取新创建的 Pod
pod := client.GetLatestPod()
// Diff 一下,检查是否已经初始化过
if !isInitialized(pod) {
// 没有?那就来初始化一下
doSomething(pod)
}
}
如果Pod中已经添加过Envoy容器,就进入下一个检查周期,如果没有则进行Initializer操作,即修改Pod的API对象
func doSomething(pod) {
// 从 APIServer 中拿到这个 ConfigMap
cm := client.Get(ConfigMap, "envoy-initializer")
// ConfigMap 里存储的 containers 和 volumes 字段,直接添加进一个空的 Pod 对象里
newPod := Pod{}
newPod.Spec.Containers = cm.Containers
newPod.Spec.Volumes = cm.Volumes
// 生成 patch 数据
patchBytes := strategicpatch.CreateTwoWayMergePatch(pod, newPod)
// 发起 PATCH 请求,修改这个 pod 对象
client.Patch(pod.Name, patchBytes)
}
kubernetes可以配置对什么样的资源使用该Initializer
apiVersion: admissionregistration.k8s.io/v1alpha1
kind: InitializerConfiguration
metadata:
name: envoy-config
initializers:
// 这个名字必须至少包括两个 "."
- name: envoy.initializer.kubernetes.io
rules:
- apiGroups:
- "" // 前面说过, "" 就是 core API Group 的意思
apiVersions:
- v1
resources:
- pods
一旦通过该InitializerConfiguration被创建,kubernetes就会将这initializer的名字加在Pod的Metadata上,格式如下所示
apiVersion: v1
kind: Pod
metadata:
initializers:
pending:
- name: envoy.initializer.kubernetes.io
name: myapp-pod
labels:
app: myapp
...
这个metadata正是Initializer控制器判断Pod是否执行过初始化的重要依据,所以在完成Initializer操作后要讲这个标志清除,Demo
Pod也可以声明使用某个Initializer
apiVersion: v1
kind: Pod
metadata
annotations:
"initializer.kubernetes.io/envoy": "true"
...
声明式API的独特之处
- 直接声明我期望的状态是什么样子
- 声明式API允许有多个写端,以PATCH的方式对API对象进行修改
24 | 深入解析声明式API(一):API对象的奥秘
CRD和如何添加自定义资源类型
25 | 深入解析声明式API(二):编写自定义控制器
创建自定义资源CRD的yaml
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: networks.samplecrd.k8s.io
spec:
group: samplecrd.k8s.io
version: v1
names:
kind: Network
plural: networks
scope: Namespaced
这个yaml定义了
group: samplecrd.k8s.ioversion: v1kind: Network资源plural: networks复数scope: Namespaced代表定义的是一个属于Namespace的对象,类似Pod
有了这个定义,kubernetes就能处理samplecrd.k8s.io/v1/networks的yaml文件了
创建CRD
$ kubectl apply -f crd/network.yaml
customresourcedefinition.apiextensions.k8s.io/networks.samplecrd.k8s.io created
获取CRD相关
$ kubectl get crd
NAME CREATED AT
networks.samplecrd.k8s.io 2019-01-16T09:19:11Z
创建自定义对象
$ kubectl apply -f example/example-network.yaml
network.samplecrd.k8s.io/example-network created
$ kubectl get network
NAME AGE
example-network 8s
$ kubectl describe network example-network
Name: example-network
Namespace: default
Labels: <none>
...API Version: samplecrd.k8s.io/v1
Kind: Network
Metadata:
...
Generation: 1
Resource Version: 468239
...
Spec:
Cidr: 192.168.0.0/16
Gateway: 192.168.0.1
然后就需要注册这个Network的Kind内部的数据类型了
生成自定义资源的clientset,informer和lister
$ tree $GOPATH/src/github.com/<your-name>/k8s-controller-custom-resource
.
├── controller.go
├── crd
│ └── network.yaml
├── example
│ └── example-network.yaml
├── main.go
└── pkg
└── apis
└── samplecrd
├── register.go
└── v1
├── doc.go
├── register.go
└── types.go
可以参考这个项目
pkg/apis/samplecrd/register.go
用于放置后边需要的全局变量
package samplecrd
const (
GroupName = "samplecrd.k8s.io"
Version = "v1"
)
pkg/apis/samplecrd/v1/doc.go
// +k8s:deepcopy-gen=package
// +groupName=samplecrd.k8s.io
package v1
+<tag_name>[=value]格式的注释是kubernetes进行代码生成的Annotation风格注释
代码生成注释的意思是
+k8s:deepcopy-gen=package是为整个v1的包里所有类型定义自动生成DeepCopy方法+groupName=samplecrd.k8s.io定义这个包对应的API组名字
这些起到的是全局代码生成控制的作用,也被称为Global Tags
pkg/apis/samplecrd/v1/types.go
package v1
import (
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
)
// +genclient
// +genclient:noStatus
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
// Network describes a Network resource
type Network struct {
// TypeMeta is the metadata for the resource, like kind and apiversion
metav1.TypeMeta `json:",inline"`
// ObjectMeta contains the metadata for the particular object, including
// things like...
// - name
// - namespace
// - self link
// - labels
// - ... etc ...
metav1.ObjectMeta `json:"metadata,omitempty"`
// Spec is the custom resource spec
Spec NetworkSpec `json:"spec"`
}
// NetworkSpec is the spec for a Network resource
type NetworkSpec struct {
// Cidr and Gateway are example custom spec fields
//
// this is where you would put your custom resource data
Cidr string `json:"cidr"`
Gateway string `json:"gateway"`
}
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
// NetworkList is a list of Network resources
type NetworkList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata"`
Items []Network `json:"items"`
}
- Network的type也是包含了TypeMeta(API 元数据)和ObjectMeta(对象元数据),Spec是是需要自定定制的部分
- NetworkSpec里定义了Cidr和Gateway两个字段,每个字段后边的代表这个字段被转化为json的名字,也就是yaml中需要定义的部分
- NetworkList中定义一组Network对象需要包含的字段,这是为了在kubernetes中通过list方法获取所有对象的时候返回值是list类型
代码生成注释的意思是
+genclient代表为下边的API资源类型生成对应的Client代码+genclient:noStatus代表这个API没有Status字段,否则生成的Client会自带UpdateStatus方法,如果有Status需要单独添加Status NetworkStatus `json:"status"+k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object代表在生成DeepCopy的时候实现kubernetes提供的runtime.Object接口,否则再某些kubernetes版本会出现一个编译错误,一个固定操作
pkg/apis/samplecrd/v1/register.go
package v1
import (
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/apimachinery/pkg/runtime"
"k8s.io/apimachinery/pkg/runtime/schema"
"github.com/resouer/k8s-controller-custom-resource/pkg/apis/samplecrd"
)
// GroupVersion is the identifier for the API which includes
// the name of the group and the version of the API
var SchemeGroupVersion = schema.GroupVersion{
Group: samplecrd.GroupName,
Version: samplecrd.Version,
}
// create a SchemeBuilder which uses functions to add types to
// the scheme
var (
SchemeBuilder = runtime.NewSchemeBuilder(addKnownTypes)
AddToScheme = SchemeBuilder.AddToScheme
)
// Resource takes an unqualified resource and returns a Group qualified GroupResource
func Resource(resource string) schema.GroupResource {
return SchemeGroupVersion.WithResource(resource).GroupResource()
}
// Kind takes an unqualified kind and returns back a Group qualified GroupKind
func Kind(kind string) schema.GroupKind {
return SchemeGroupVersion.WithKind(kind).GroupKind()
}
// addKnownTypes adds our types to the API scheme by registering
// Network and NetworkList
func addKnownTypes(scheme *runtime.Scheme) error {
scheme.AddKnownTypes(
SchemeGroupVersion,
&Network{},
&NetworkList{},
)
// register the type in the scheme
metav1.AddToGroupVersion(scheme, SchemeGroupVersion)
return nil
}
register的作用是注册一个Type给APIServer,Network资源类型在服务器端的注册
使用的时候只需要将Network相关的部分配置为属于我们自行定义的即可
使用kubernets提供的工具,为定义的Network资源类型主动生成clientset,informer和lister
$ ROOT_PACKAGE="github.com/resouer/k8s-controller-custom-resource"
# API Group
$ CUSTOM_RESOURCE_NAME="samplecrd"
# API Version
$ CUSTOM_RESOURCE_VERSION="v1"
# 安装 k8s.io/code-generator
$ go get -u k8s.io/code-generator/...
$ cd $GOPATH/src/k8s.io/code-generator
# 执行代码自动生成,其中 pkg/client 是生成目标目录,pkg/apis 是类型定义目录
$ ./generate-groups.sh all "$ROOT_PACKAGE/pkg/client" "$ROOT_PACKAGE/pkg/apis" "$CUSTOM_RESOURCE_NAME:$CUSTOM_RESOURCE_VERSION"
再看一下目录结构就是
$ tree
.
├── controller.go
├── crd
│ └── network.yaml
├── example
│ └── example-network.yaml
├── main.go
└── pkg
├── apis
│ └── samplecrd
│ ├── constants.go
│ └── v1
│ ├── doc.go
│ ├── register.go
│ ├── types.go
│ └── zz_generated.deepcopy.go
└── client
├── clientset
├── informers
└── listers
pkg/apis/samplecrd/v1下的zz_generated.deepcopy.go就是DeepCopy的代码文件- client目录下clientset、informers、listers就是自定义控制器的客户端了
创建控制器
main函数
定义并初始化一个自定义控制器
第一步
main函数根据我提供的Master配置(APIServer的地址端口和kubeconfig的路径),创建一个Kubernetes的client(kubeClient)和Network对象的client(networkClient)
cfg, err := clientcmd.BuildConfigFromFlags(masterURL, kubeconfig)
kubeClient, err := kubernetes.NewForConfig(cfg)
networkClient, err := clientset.NewForConfig(cfg)
对于没有提供Master配置的时候,main函数会使用一种InClusterConfig的方式来创建这个Client,这个方式会假定自定义控制器来创建在Pod中
第二步
为Network对象创建一个InformerFactory,通过其创建Informer传递给控制器
networkInformerFactory := informers.NewSharedInformerFactory(networkClient, ...)
controller := NewController(kubeClient, networkClient, networkInformerFactory.Samplecrd().V1().Networks())
第三步
Informer启动,并启动自定义控制器
go networkInformerFactory.Start(stopCh)
if err = controller.Run(2, stopCh); err != nil {
glog.Fatalf("Error running controller: %s", err.Error())
}
自定义控制器如下
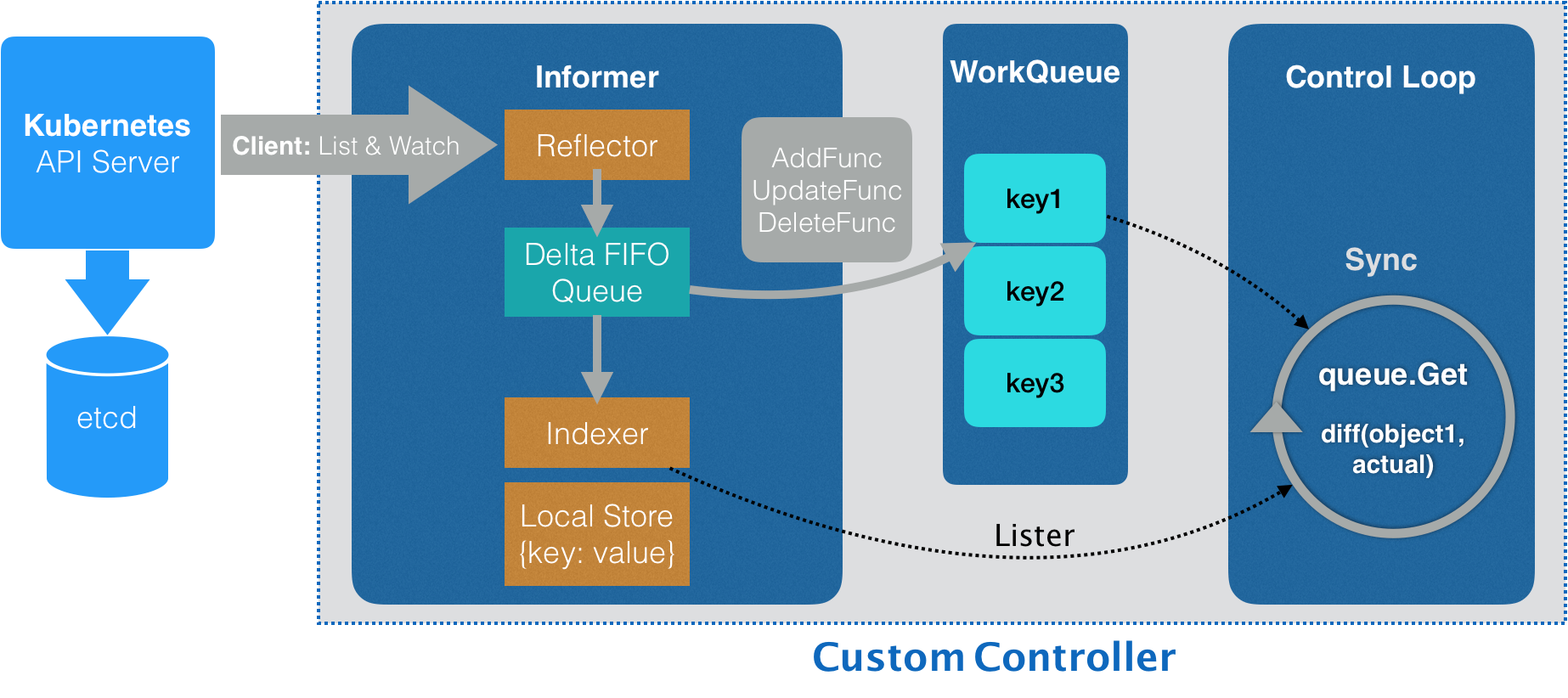
在第二步的时候创建的Network使用的就是创建InformerFactory时传递的networkClient,创建了与APIServer的连接,用于从APIServer获取跟Network相关的对象信息
这个连接是通过Informer的Reflector实现和维护的,通过ListAndWatch的方法,监听并获取这些Network对象的变化,会根据这些实例变化放入Delta FIFO Queue(一个先入先出队列)
Informer读取这个队列,更新或创建本地缓存,并且根据事件的类型调用实现注册好的ResourceEventHandler
定义控制器
第一步
使用了之前的kubeclientset,networkclientset和Informer,以及创建的WorkQueue来构建Controller
kubeclientset kubernetes.Interface,
networkclientset clientset.Interface,
networkInformer informers.NetworkInformer) *Controller {
...
controller := &Controller{
kubeclientset: kubeclientset,
networkclientset: networkclientset,
networksLister: networkInformer.Lister(),
networksSynced: networkInformer.Informer().HasSynced,
workqueue: workqueue.NewNamedRateLimitingQueue(..., "Networks"),
...
}
第二步
networkInformer上注册Handler(AddFunc、UpdateFunc和DeleteFunc),分别对应API对象的添加,更新和删除事件,具体的处理操作就是放入事件的工作队列,然后将API对象放入到工作队列,格式为<namespace>/<name>
networkInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.enqueueNetwork,
UpdateFunc: func(old, new interface{}) {
oldNetwork := old.(*samplecrdv1.Network)
newNetwork := new.(*samplecrdv1.Network)
if oldNetwork.ResourceVersion == newNetwork.ResourceVersion {
// Periodic resync will send update events for all known Networks.
// Two different versions of the same Network will always have different RVs.
return
}
controller.enqueueNetwork(new)
},
DeleteFunc: controller.enqueueNetworkForDelete,
})
控制器在监听过程是实时刷新更新本地缓存的,但是在进过resyncPeriod指定的时间,会使用最近list获取的返回结果强制刷新一次,保证缓存的有效性,这个resync操作也会触发Informer的更新事件,但是这个更新由于新老版本一致就不进行操作了,如果不一致才会操作
控制循环
第一步
等待Informer完成一次本地缓存的数据同步操作
if ok := cache.WaitForCacheSync(stopCh, c.networksSynced); !ok {
return fmt.Errorf("failed to wait for caches to sync")
}
第二步
通过 goroutine 启动一个(或者并发启动多个)“无限循环”的任务
for i := 0; i < threadiness; i++ {
go wait.Until(c.runWorker, time.Second, stopCh)
}
第三步
runWorker直接通过for循环调用的processNextWorkItem方法
func (c *Controller) runWorker() {
for c.processNextWorkItem() {
}
}
第四步
从工作队列获取成员数据,然后通过syncHandler从缓存获取数据
func (c *Controller) processNextWorkItem() bool {
obj, shutdown := c.workqueue.Get()
...
err := func(obj interface{}) error {
...
if err := c.syncHandler(key); err != nil {
return fmt.Errorf("error syncing '%s': %s", key, err.Error())
}
c.workqueue.Forget(obj)
...
return nil
}(obj)
...
return true
}
第五步
使用cache.SplitMetaNamespaceKey方法获取namespace和name,然后通过networksLister获取network信息,如果获取不到就返回err,获取到就返回空
func (c *Controller) syncHandler(key string) error {
namespace, name, err := cache.SplitMetaNamespaceKey(key)
...
network, err := c.networksLister.Networks(namespace).Get(name)
if err != nil {
if errors.IsNotFound(err) {
glog.Warningf("Network does not exist in local cache: %s/%s, will delete it from Neutron ...",
namespace, name)
glog.Warningf("Network: %s/%s does not exist in local cache, will delete it from Neutron ...",
namespace, name)
// FIX ME: call Neutron API to delete this network by name.
//
// neutron.Delete(namespace, name)
return nil
}
...
return err
}
第六步
通过Neutron方法获取实际状态,进行对比然后做对应操作
glog.Infof("[Neutron] Try to process network: %#v ...", network)
// FIX ME: Do diff().
//
// actualNetwork, exists := neutron.Get(namespace, name)
//
// if !exists {
// neutron.Create(namespace, name)
// } else if !reflect.DeepEqual(actualNetwork, network) {
// neutron.Update(namespace, name)
// }
c.recorder.Event(network, corev1.EventTypeNormal, SuccessSynced, MessageResourceSynced)
return nil
编译和启动
# Clone repo
$ git clone https://github.com/resouer/k8s-controller-custom-resource$ cd k8s-controller-custom-resource
### Skip this part if you don't want to build
# Install dependency
$ go get github.com/tools/godep
$ godep restore
# Build
$ go build -o samplecrd-controller .
$ ./samplecrd-controller -kubeconfig=$HOME/.kube/config -alsologtostderr=true
I0915 12:50:29.051349 27159 controller.go:84] Setting up event handlers
I0915 12:50:29.051615 27159 controller.go:113] Starting Network control loop
I0915 12:50:29.051630 27159 controller.go:116] Waiting for informer caches to sync
E0915 12:50:29.066745 27159 reflector.go:134] github.com/resouer/k8s-controller-custom-resource/pkg/client/informers/externalversions/factory.go:117: Failed to list *v1.Network: the server could not find the requested resource (get networks.samplecrd.k8s.io)
...
当CRD没有被创建的时候,会报错,因为获取list的时候为APIServer不存在
Failed to list *v1.Network: the server could not find the requested resource (get networks.samplecrd.k8s.io)
创建CRD
$ kubectl apply -f crd/network.yaml
之后日志就正常了
...
I0915 12:50:29.051630 27159 controller.go:116] Waiting for informer caches to sync
...
I0915 12:52:54.346854 25245 controller.go:121] Starting workers
I0915 12:52:54.346914 25245 controller.go:127] Started workers
创建Network
$ cat example/example-network.yaml
apiVersion: samplecrd.k8s.io/v1
kind: Network
metadata:
name: example-network
spec:
cidr: "192.168.0.0/16"
gateway: "192.168.0.1"
$ kubectl apply -f example/example-network.yaml
network.samplecrd.k8s.io/example-network created
创建对象之后
...
I0915 12:50:29.051349 27159 controller.go:84] Setting up event handlers
I0915 12:50:29.051615 27159 controller.go:113] Starting Network control loop
I0915 12:50:29.051630 27159 controller.go:116] Waiting for informer caches to sync
...
I0915 12:52:54.346854 25245 controller.go:121] Starting workers
I0915 12:52:54.346914 25245 controller.go:127] Started workers
I0915 12:53:18.064409 25245 controller.go:229] [Neutron] Try to process network: &v1.Network{TypeMeta:v1.TypeMeta{Kind:"", APIVersion:""}, ObjectMeta:v1.ObjectMeta{Name:"example-network", GenerateName:"", Namespace:"default", ... ResourceVersion:"479015", ... Spec:v1.NetworkSpec{Cidr:"192.168.0.0/16", Gateway:"192.168.0.1"}} ...
I0915 12:53:18.064650 25245 controller.go:183] Successfully synced 'default/example-network'
...
创建network的操作,触发了EventHandler的“添加”事件,从而被放进了工作队列。紧接着,控制循环就从队列里拿到了这个对象,并且打印出了正在“处理”这个Network对象的日志。可以看到,这个Network ResourceVersion,也就是API对象的版本号,是 479015,而它的Spec字段的内容,跟我提交的YAML文件一摸一样
修改一下yaml的内容
$ cat example/example-network.yaml
apiVersion: samplecrd.k8s.io/v1
kind: Network
metadata:
name: example-network
spec:
cidr: "192.168.1.0/16"
gateway: "192.168.1.1"
$ kubectl apply -f example/example-network.yaml
network.samplecrd.k8s.io/example-network configured
控制器输出
...
I0915 12:53:51.126029 25245 controller.go:229] [Neutron] Try to process network: &v1.Network{TypeMeta:v1.TypeMeta{Kind:"", APIVersion:""}, ObjectMeta:v1.ObjectMeta{Name:"example-network", GenerateName:"", Namespace:"default", ... ResourceVersion:"479062", ... Spec:v1.NetworkSpec{Cidr:"192.168.1.0/16", Gateway:"192.168.1.1"}} ...
I0915 12:53:51.126348 25245 controller.go:183] Successfully synced 'default/example-network'
获取的ResourceVersion为479062,Spec的字段为192.168.1.0/16网段
删除对象
$ kubectl delete -f example/example-network.yaml
控制台输出
W0915 12:54:09.738464 25245 controller.go:212] Network: default/example-network does not exist in local cache, will delete it from Neutron ...
I0915 12:54:09.738832 25245 controller.go:215] [Neutron] Deleting network: default/example-network ...
I0915 12:54:09.738854 25245 controller.go:183] Successfully synced 'default/example-network'
除了自定义了,我们也可以对原生的API对象创建Informer
func main() {
...
kubeInformerFactory := kubeinformers.NewSharedInformerFactory(kubeClient, time.Second*30)
controller := NewController(kubeClient, exampleClient,
kubeInformerFactory.Apps().V1().Deployments(),
networkInformerFactory.Samplecrd().V1().Networks())
go kubeInformerFactory.Start(stopCh)
...
}
- 首先使用Kubernetes的 client(kubeClient)创建了一个工厂
- 然后用跟Network类似的处理方法,生成了一个Deployment Informer
- 接着把Deployment Informer传递给了自定义控制器;当然,我也要调用Start方法来启动这个Deployment Informer
- 而有了这个Deployment Informer后,这个控制器也就持有了所有Deployment对象的信息。接下来,它既可以通过
deploymentInformer.Lister()来获取Etcd里的所有Deployment对象,也可以为这个Deployment Informer注册具体的Handler来
更重要的是,这就使得在这个自定义控制器里面,我可以通过对自定义API对象和默认API对象进行协同,从而实现更加复杂的编排功能。比如:用户每创建一个新的Deployment,这个自定义控制器,就可以为它创建一个对应的Network`供它使用。
26 | 基于角色的权限控制:RBAC
RBAC
对kubernetes的APIServer访问控制的机制就是RBAC
RBAC有三个最基本的概念
- Role角色,定义了一组对kubernetesAPI对象的操作权限
- Subject被作用者,可以是kubernetes中定义的用户
- RoleBinding将Role和Subject进行绑定
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: mynamespace
name: example-role
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list"]
Role对象定义了产生作用的Namespace为mynamespace,对于kubernetes来说,Namespace是一个逻辑管理单位,不同的Namespace的API对象通过kubectl命令的时候操作是互相隔离的
rules中则是对mynamespace下面的Pod对象,进行GET、WATCH和LIST操作
User是授权系统中的一个逻辑概念,需要通过外部认证服务,比如Keystone来提供,或者直接给APIServer指定一个用户名密码,也可以使用kubernetes的内置用户
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: example-rolebinding
namespace: mynamespace
subjects:
- kind: User
name: example-user
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: example-role
apiGroup: rbac.authorization.k8s.io
RoleBinding对象中subjects字段为被作用者,然后通过roleRef字段将Role和subjects进行绑定
对于非Namespace控制的对象,例如Node,需要通过ClusterRole和ClusterRoleBinding来实现,这里和Role和RoleBinding一样配置,只不过不需要指定Namespace
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: example-clusterrole
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list"]
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: example-clusterrolebinding
subjects:
- kind: User
name: example-user
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: example-clusterrole
apiGroup: rbac.authorization.k8s.io
例子中指定的是对所有的Namespace下的Pod
如果赋予所有的权限就是verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
rules字段也是可以细化的,指定到具体的对象
rules:
- apiGroups: [""]
resources: ["configmaps"]
resourceNames: ["my-config"]
verbs: ["get"]
最简单就是数据库的配置等
ServiceAccount 分配权限的过程
kubernetes的内置用户为ServiceAccount
创建一个ServiceAccount
apiVersion: v1
kind: ServiceAccount
metadata:
namespace: mynamespace
name: example-sa
通过RoleBinding进行绑定
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: example-rolebinding
namespace: mynamespace
subjects:
- kind: ServiceAccount
name: example-sa
namespace: mynamespace
roleRef:
kind: Role
name: example-role
apiGroup: rbac.authorization.k8s.io
查看sa
$ kubectl get sa -n mynamespace -o yaml
- apiVersion: v1
kind: ServiceAccount
metadata:
creationTimestamp: 2018-09-08T12:59:17Z
name: example-sa
namespace: mynamespace
resourceVersion: "409327"
...
secrets:
- name: example-sa-token-vmfg6
kubernetes会为ServiceAccount自动创建和分配一个Secret对象
用户pod可以通过声明使用这个ServiceAccount
apiVersion: v1
kind: Pod
metadata:
namespace: mynamespace
name: sa-token-test
spec:
containers:
- name: nginx
image: nginx:1.7.9
serviceAccountName: example-sa
Pod运行之后会将ServiceAccount的Token,也就是Secret通Volume的方式挂载到容器的/var/run/secrets/kubernetes.io/serviceaccount目录
$ kubectl describe pod sa-token-test -n mynamespace
Name: sa-token-test
Namespace: mynamespace
...
Containers:
nginx:
...
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from example-sa-token-vmfg6 (ro)
可以通过kubectl exec查看
$ kubectl exec -it sa-token-test -n mynamespace -- /bin/bash
root@sa-token-test:/# ls /var/run/secrets/kubernetes.io/serviceaccount
ca.crt namespace token
Pod中的应用就可以通过ca.crt来访问APIServer
对于没有声明ServiceAccount的Pod会默认绑定Namespace下名为default的ServiceAccount,这个默认的ServiceAccount是没有绑定任何Role的,所以有访问绝大部分APIServer的权限,所以需要为这些default的ServiceAccount添加只能View的权限
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: readonly-all-default
subjects:
- kind: ServiceAccount
name: system.serviceaccount.default
roleRef:
kind: ClusterRole
name: view
apiGroup: rbac.authorization.k8s.io
默认的ServiceAccount
$kubectl describe sa default
Name: default
Namespace: default
Labels: <none>
Annotations: <none>
Image pull secrets: <none>
Mountable secrets: default-token-s8rbq
Tokens: default-token-s8rbq
Events: <none>
$ kubectl get secret
NAME TYPE DATA AGE
kubernetes.io/service-account-token 3 82d
$ kubectl describe secret default-token-s8rbq
Name: default-token-s8rbq
Namespace: default
Labels: <none>
Annotations: kubernetes.io/service-account.name=default
kubernetes.io/service-account.uid=ffcb12b2-917f-11e8-abde-42010aa80002
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1025 bytes
namespace: 7 bytes
token: <TOKEN 数据 >
一个ServiceAccount在kubernetes的用户名字
system:serviceaccount:<ServiceAccount 名字 >
对应的用户组为
system:serviceaccounts:<Namespace 名字 >
如果为用户组RoleBinding
subjects:
- kind: Group
name: system:serviceaccounts:mynamespace
apiGroup: rbac.authorization.k8s.io
就作用与了namespace下的所有ServiceAccount了
而下边的例子作用于所有ServiceAccount
subjects:
- kind: Group
name: system:serviceaccounts
apiGroup: rbac.authorization.k8s.io
kubernetes也内置了很多的保留ClusterRole,以system:开头,可以通过kubectl get clusterroles查看
kubernetes还预先定义了四个ClusterRole
- cluster-admin 整个kubernetes的最高权限,
verbs=* - admin
- edit
- view
27 | 聪明的微创新:Operator工作原理解读
通过Operator创建Etcd集群
$ git clone https://github.com/coreos/etcd-operator
$ example/rbac/create_role.sh
脚本的作用是为Etcd Operator创建RBAC规则,对CRD对象有所有权限,对Pod、Service、PVC、Deployment、Secret等API对象有所有权限,对属于etcd.database.coreos.com这个API Group的CR对象有所有权限
Etcd Operator本身为一个Deployment
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: etcd-operator
spec:
replicas: 1
template:
metadata:
labels:
name: etcd-operator
spec:
containers:
- name: etcd-operator
image: quay.io/coreos/etcd-operator:v0.9.2
command:
- etcd-operator
env:
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
...
主要作用是创建一个Pod和一个CR
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
etcd-operator-649dbdb5cb-bzfzp 1/1 Running 0 20s
$ kubectl get crd
NAME CREATED AT
etcdclusters.etcd.database.coreos.com 2018-09-18T11:42:55Z
CRD名叫etcdclusters.etcd.database.coreos.com
$ kubectl describe crd etcdclusters.etcd.database.coreos.com
...
Group: etcd.database.coreos.com
Names:
Kind: EtcdCluster
List Kind: EtcdClusterList
Plural: etcdclusters
Short Names:
etcd
Singular: etcdcluster
Scope: Namespaced
Version: v1beta2
在APIServer中定义了etcd.database.coreos.com的API Group和EtcdCluster的Kind
Etcd Operator本身就是一个自定义资源的控制器
部署只需要声明一下size和version即可
apiVersion: "etcd.database.coreos.com/v1beta2"
kind: "EtcdCluster"
metadata:
name: "example-etcd-cluster"
spec:
size: 3
version: "3.2.13"
通过CRD来描述需要部署的有状态应用,在自定义控制器进行部署和变更
types.go中的内容为
// +genclient
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
type EtcdCluster struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec ClusterSpec `json:"spec"`
Status ClusterStatus `json:"status"`
}
type ClusterSpec struct {
// Size is the expected size of the etcd cluster.
// The etcd-operator will eventually make the size of the running
// cluster equal to the expected size.
// The vaild range of the size is from 1 to 7.
Size int `json:"size"`
...
}
- EtcdCluster是一个有Status字段的CRD
- size字段可以直接调整Etcd集群的大小
etcd的静态集群的方式,通过先创建集群的种子节点,然后通过member add的方式动态添加
$ etcd
--data-dir=/var/etcd/data
--name=infra0
--initial-advertise-peer-urls=http://10.0.1.10:2380
--listen-peer-urls=http://0.0.0.0:2380
--listen-client-urls=http://0.0.0.0:2379
--advertise-client-urls=http://10.0.1.10:2379
--initial-cluster=infra0=http://10.0.1.10:2380
--initial-cluster-state=new
--initial-cluster-token=4b5215fa-5401-4a95-a8c6-892317c9bef8
指定了initial-cluster-state是new,并且指定了唯一的initial-cluster-token
这个阶段为Bootstrap
添加成员为
$ etcdctl member add infra1 http://10.0.1.11:2380
生成参数并在对应节点启动etcd
$ etcd
--data-dir=/var/etcd/data
--name=infra1
--initial-advertise-peer-urls=http://10.0.1.11:2380
--listen-peer-urls=http://0.0.0.0:2380
--listen-client-urls=http://0.0.0.0:2379
--advertise-client-urls=http://10.0.1.11:2379
--initial-cluster=infra0=http://10.0.1.10:2380,infra1=http://10.0.1.11:2380
--initial-cluster-state=existing
指定了initial-cluster-state是existing代表要加入已有集群,initial-cluster中指定集群中节点,以此类推加到指定size
这个流程在Informer中展开
func (c *Controller) Start() error {
for {
err := c.initResource()
...
time.Sleep(initRetryWaitTime)
}
c.run()
}
func (c *Controller) run() {
...
_, informer := cache.NewIndexerInformer(source, &api.EtcdCluster{}, 0, cache.ResourceEventHandlerFuncs{
AddFunc: c.onAddEtcdClus,
UpdateFunc: c.onUpdateEtcdClus,
DeleteFunc: c.onDeleteEtcdClus,
}, cache.Indexers{})
ctx := context.TODO()
// TODO: use workqueue to avoid blocking
informer.Run(ctx.Done())
}
- etcd operate启动的首要工作就是创建EtcdCluster对象所需要的CRD,即
etcdclusters.etcd.database.coreos.com - 然后定义EtcdCluster对象的Informer
由于这个operate写的较早,没有使用队列,这样造成的问题可能是执行的业务逻辑比较耗时,而Informer的WATCH机制对API对象的变化响应是非常迅速的,这样就很可能由于业务逻辑拖慢了Informer的执行周期,甚至Block了,所以使用工作队列是一个很好的方法
由于Etcd Operator里没有工作队列,那么在它的EventHandler部分,就不会有什么入队操作,而直接就是每种事件对应的具体的业务逻辑了。
不过,Etcd Operator在业务逻辑的实现方式上,与常规的自定义控制器略有不同。我把在这一部分的工作原理,提炼成了一个详细的流程图,如下所示:
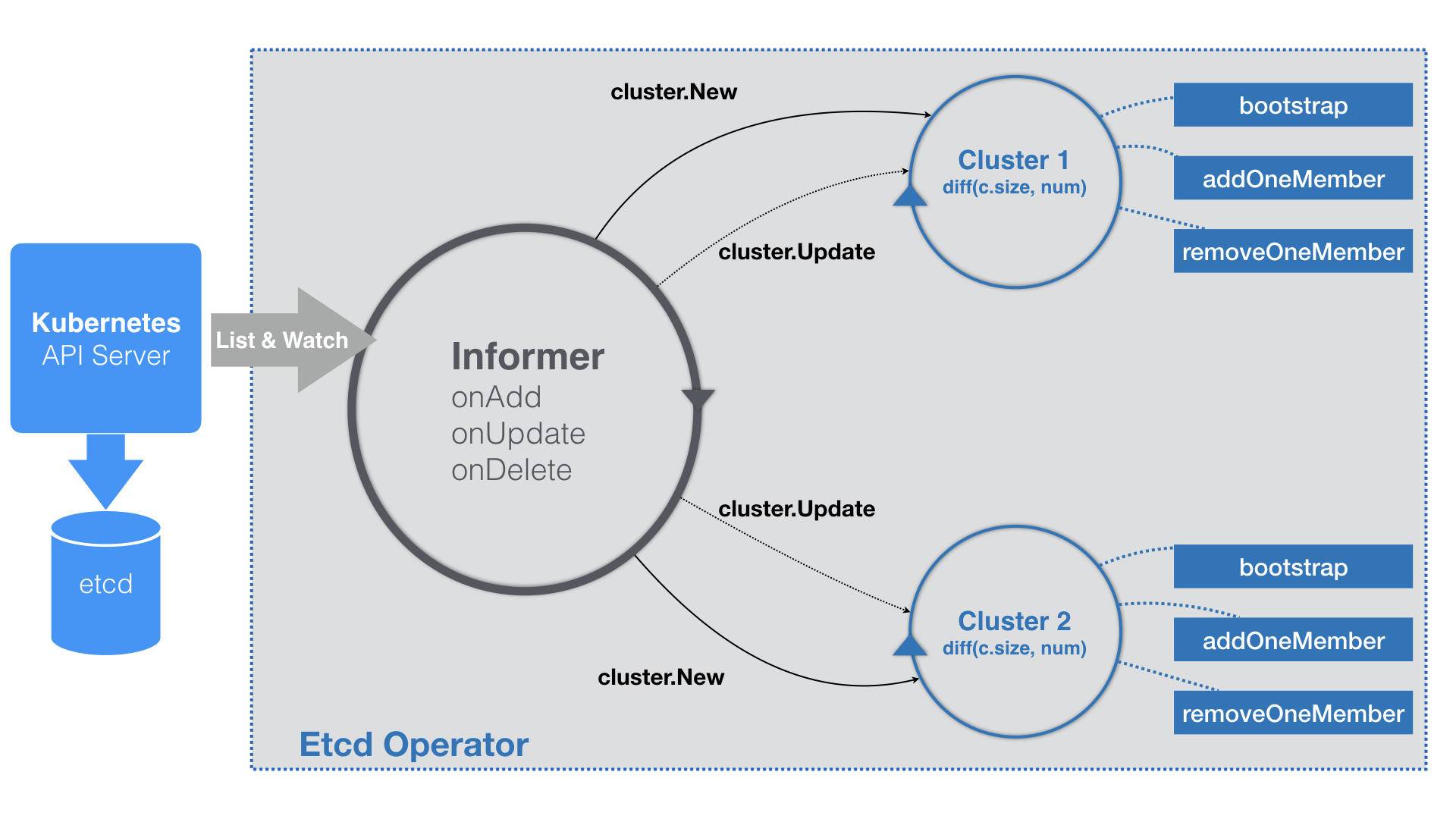
可以看到,Etcd Operator的特殊之处在于,它为每一个EtcdCluster对象,都启动了一个控制循环,“并发”地响应这些对象的变化。显然,这种做法不仅可以简化Etcd Operator的代码实现,还有助于提高它的响应速度。
当yaml提交到kubernetes,Etcd Operator的Informer会感知,并将EventHandler中的添加事件触发。
如果集群对象第一次被创建,就创建种子节点,然后生成Pod对象,Pod先启动InitContainer来检查Pod的DNS记录是否正常,然后启动Etcd容器
/usr/local/bin/etcd
--data-dir=/var/etcd/data
--name=example-etcd-cluster-mbzlg6sd56
--initial-advertise-peer-urls=http://example-etcd-cluster-mbzlg6sd56.example-etcd-cluster.default.svc:2380
--listen-peer-urls=http://0.0.0.0:2380
--listen-client-urls=http://0.0.0.0:2379
--advertise-client-urls=http://example-etcd-cluster-mbzlg6sd56.example-etcd-cluster.default.svc:2379
--initial-cluster=example-etcd-cluster-mbzlg6sd56=http://example-etcd-cluster-mbzlg6sd56.example-etcd-cluster.default.svc:2380
--initial-cluster-state=new
--initial-cluster-token=4b5215fa-5401-4a95-a8c6-892317c9bef8
在每个对象创建之前,都会事先创建一个与该EtcdCluster同名的Headless Service,在创建的过程中就可以直接使用Pod的DNS地址了
/usr/local/bin/etcd
--data-dir=/var/etcd/data
--name=example-etcd-cluster-v6v6s6stxd
--initial-advertise-peer-urls=http://example-etcd-cluster-v6v6s6stxd.example-etcd-cluster.default.svc:2380
--listen-peer-urls=http://0.0.0.0:2380
--listen-client-urls=http://0.0.0.0:2379
--advertise-client-urls=http://example-etcd-cluster-v6v6s6stxd.example-etcd-cluster.default.svc:2379
--initial-cluster=example-etcd-cluster-mbzlg6sd56=http://example-etcd-cluster-mbzlg6sd56.example-etcd-cluster.default.svc:2380,example-etcd-cluster-v6v6s6stxd=http://example-etcd-cluster-v6v6s6stxd.example-etcd-cluster.default.svc:2380
--initial-cluster-state=existing
然后就是增加节点
- 生成一个新的Pod名称
- 调用Etcd Client执行提到的
etcdctl member add - 使用和这个Pod和其他Pod组成一个新的initial-cluster
- 组成etcd启动命令启动Pod
当容器启动后,新的etcd节点加入集群,控制循环再次反复这个操作,直到达到指定size
在Etcd集群中没有不需要序号等来维持顺序,也不需要数据持久化
可以通过backup的方式进行
# 首先,创建 etcd-backup-operator
$ kubectl create -f example/etcd-backup-operator/deployment.yaml
# 确认 etcd-backup-operator 已经在正常运行
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
etcd-backup-operator-1102130733-hhgt7 1/1 Running 0 3s
# 可以看到,Backup Operator 会创建一个叫 etcdbackups 的 CRD
$ kubectl get crd
NAME KIND
etcdbackups.etcd.database.coreos.com CustomResourceDefinition.v1beta1.apiextensions.k8s.io
# 我们这里要使用 AWS S3 来存储备份,需要将 S3 的授权信息配置在文件里
$ cat $AWS_DIR/credentials
[default]
aws_access_key_id = XXX
aws_secret_access_key = XXX
$ cat $AWS_DIR/config
[default]
region = <region>
# 然后,将上述授权信息制作成一个 Secret
$ kubectl create secret generic aws --from-file=$AWS_DIR/credentials --from-file=$AWS_DIR/config
# 使用上述 S3 的访问信息,创建一个 EtcdBackup 对象
$ sed -e 's|<full-s3-path>|mybucket/etcd.backup|g' \
-e 's|<aws-secret>|aws|g' \
-e 's|<etcd-cluster-endpoints>|"http://example-etcd-cluster-client:2379"|g' \
example/etcd-backup-operator/backup_cr.yaml \
| kubectl create -f -
然后通过example/etcd-backup-operator/backup_cr.yaml创建备份
可以设置一个Crontab来定时备份
当集群故障还可以通过Etcd Restore Operator来进行恢复
# 创建 etcd-restore-operator
$ kubectl create -f example/etcd-restore-operator/deployment.yaml
# 确认它已经正常运行
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
etcd-restore-operator-4203122180-npn3g 1/1 Running 0 7s
# 创建一个 EtcdRestore 对象,来帮助 Etcd Operator 恢复数据,记得替换模板里的 S3 的访问信息
$ sed -e 's|<full-s3-path>|mybucket/etcd.backup|g' \
-e 's|<aws-secret>|aws|g' \
example/etcd-restore-operator/restore_cr.yaml \
| kubectl create -f -
然后通过example/etcd-restore-operator/restore_cr.yaml恢复之后,交由Etcd Operator管理
Operator可以控制的不只是Pod,也可以是StatefulSet等,Promethues就是这么做的,还有可以自动创建operator框架的operator-sdk
28 | PV、PVC、StorageClass,这些到底在说啥?
PV与PVC
PV是持久化存储卷,定义的是持久化存储在主机上的目录
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs
spec:
storageClassName: manual
capacity:
storage: 1Gi
accessModes:
- ReadWriteMany
nfs:
server: 10.244.1.4
path: "/"
PVC描述的是一个Pod希望使用的持久化存储属性
PVC需要与PV绑定才能被容器使用,绑定的条件
- PV大小满足PVC需求
- storageClassName字段一致
Pod使用PVC
apiVersion: v1
kind: Pod
metadata:
labels:
role: web-frontend
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
volumeMounts:
- name: nfs
mountPath: "/usr/share/nginx/html"
volumes:
- name: nfs
persistentVolumeClaim:
claimName: nfs
Pod声明使用的PVC,kubelet将PVC对应PV挂载到Pod目录,当PVC没有合适的PV可以绑定就会造成Pod启动报错
在Kubernetes中维护了着多个VolumeController,PersistentVolumeController就是负责绑定PV和PVC的
持久化存储不会因为容器销毁而删除,也不会跟宿主机绑定,当容器在其他节点启动的时候也依然可以挂载,而hostPath和emptyDir是不能满足的
持久化宿主机目录的两个阶段Attach阶段和Mount阶段
- Pod在被kubelet创建的时候会创建Volume目录
/var/lib/kubelet/pods/<Pod的ID>/volumes/kubernetes.io~<Volume类型>/<Volume名字> - 挂载到Volume对应的目录
例如nfs就是
$ mount -t nfs <NFS服务器地址 >:/ /var/lib/kubelet/pods/<Pod的ID>/volumes/kubernetes.io~<Volume类型>/<Volume名字>
可以看到第一阶段Kubernetes提供的是NodeName,第二阶段Kubernetes提供的参数是dir
- 第一阶段的控制器为AttachDetachController存在于master节点,用于不断检测Pod对应的PV和Pod在宿主机的挂载情况,从而决定是否需要对这个PV进行Attach操作或Dettach操作。
- 第二阶段的控制器为VolumeManagerReconciler存在于node节点,是一个独立于kubelet的进程,防止kubelet创建Pod等效率下降
StorageClass
对于PV需要手动创建,而StorageClass可以自动完成创建PV模板的功能
StorageClass包含两部分内容
- PV大小,存储类型
- 创建使用的插件
然后创建的PVC就可以找到一个对应的StorageClass,然后调用其创建需要的PV
如果Storage满了会有什么问题???
apiVersion: ceph.rook.io/v1beta1
kind: Pool
metadata:
name: replicapool
namespace: rook-ceph
spec:
replicated:
size: 3
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: block-service
provisioner: ceph.rook.io/block
parameters:
pool: replicapool
#The value of "clusterNamespace" MUST be the same as the one in which your rook cluster exist
clusterNamespace: rook-ceph
使用rook项目
创建PVC就可以
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: claim1
spec:
accessModes:
- ReadWriteOnce
storageClassName: block-service
resources:
requests:
storage: 30Gi
这里也指定了storageClassName为block-service,自动创建的PV也是storageClassName为block-service的
如果不指定storageClassName就为"",也就是PV也需要是storageClassName为""
当然需要存储插件支持Dynamic Provisioning
29 | PV、PVC体系是不是多此一举?从本地持久化卷谈起
本地持久化存储Local Persistent Volume,在v1.10开始支持
适合高优先级的系统应用,需要在多个节点存储数据,对IO要求高,例如MongoDB,Ceph等,如果节点宕机,数据就会丢失,所以还需要应用具有数据备份和恢复的能力
- 宿主机目录是一定不能当PV使用,否则就会将本地目录写满的问题,一定要是一块盘
- Kubernetes调度的时候是先选择Pod,然后进行创建Pod,所以需要调度的时候考虑到Volume的分布
# 在 node-1 上执行
$ mkdir /mnt/disks
$ for vol in vol1 vol2 vol3; do
mkdir /mnt/disks/$vol
mount -t tmpfs $vol /mnt/disks/$vol
done
为本地盘创建PV
apiVersion: v1
kind: PersistentVolume
metadata:
name: example-pv
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local:
path: /mnt/disks/vol1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node-1
local字段指定了是一个Local Persistent Volume,路径为/mnt/disks/vol1,然后在指定nodeAffinity
创建StorageClass
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
Local Persistent Volume不支持动态创建,所以需要之前手动创建PV,并且设置了volumeBindingMode: WaitForFirstConsumer延迟绑定,正常的PVC和PV是实时绑定的
如果有一个Pod,PVC叫做pvc-1,规定了Pod运行在Node2,就不能使用node1这个PV了,这样Pod的调度就失败了,所以延迟绑定是在推迟到调度的时候进行绑定,这样就不会影响PV的正常调度
创建PVC
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: example-local-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: local-storage
创建的PVC也是Pending状态
kind: Pod
apiVersion: v1
metadata:
name: example-pv-pod
spec:
volumes:
- name: example-pv-storage
persistentVolumeClaim:
claimName: example-local-claim
containers:
- name: example-pv-container
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: example-pv-storage
创建了Pod之后才会进行绑定,并且Pod也被调度到了Node1
StatafulSet也可以通过声明Local类型的PV和PVC来管理存储
这些PV删除的流程
- 删除PV的Pod
- 从宿主机移除本地磁盘(umount)
- 删除PVC
- 删除PV
Kubernetes也提供了Static Provisioner来管理PV
启动后是DaemonSet,自动检查指定目录,为每一个挂载点创建一个PV出来
$ kubectl get pv
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
local-pv-ce05be60 1024220Ki RWO Delete Available local-storage 26s
$ kubectl describe pv local-pv-ce05be60
Name: local-pv-ce05be60
...
StorageClass: local-storage
Status: Available
Claim:
Reclaim Policy: Delete
Access Modes: RWO
Capacity: 1024220Ki
NodeAffinity:
Required Terms:
Term 0: kubernetes.io/hostname in [node-1]
Message:
Source:
Type: LocalVolume (a persistent volume backed by local storage on a node)
Path: /mnt/disks/vol1
具体可以参考Provisioner,部署参考
30 | 编写自己的存储插件:FlexVolume与CSI
略
31 | 容器存储实践:CSI插件编写指南
略
32 | 浅谈容器网络
容器的网络是通过Network Namespace看到的linux的网络栈,包括网卡,回环设备,路由表和iptables规则
容器网络栈和宿主机的网络栈之间通过网桥(bridge)和虚拟网卡(Veth Pair)实现
- Bridge是一个工作在链路层的设备,根据MAC地址学习将数据包发送到网桥的不同的Port上,对于docker就是docker0网桥
- Veth Pair在创建的时候就是成对出现,一段挂在docker0网桥,另一端挂在内部
对于同一台宿主机docker0网卡上的两个容器,由于都连接在docker0网桥,两个容器之间是可以互通的,容器通过eth0网卡发往网桥上的其他容器直接进行ARP广播获取MAC地址就可以了
$ route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 172.17.0.1 0.0.0.0 UG 0 0 0 eth0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0
然后对于docker0本身就是一个二层交换机
在ping的过程使用TRACE功能看一下数据包的传输
# 在宿主机上执行
$ iptables -t raw -A OUTPUT -p icmp -j TRACE
$ iptables -t raw -A PREROUTING -p icmp -j TRACE
在宿主机上访问容器IP地址的时候,数据包根据路由规则到docker0网桥,然后转发到Veth Pair设备,最后到容器内部
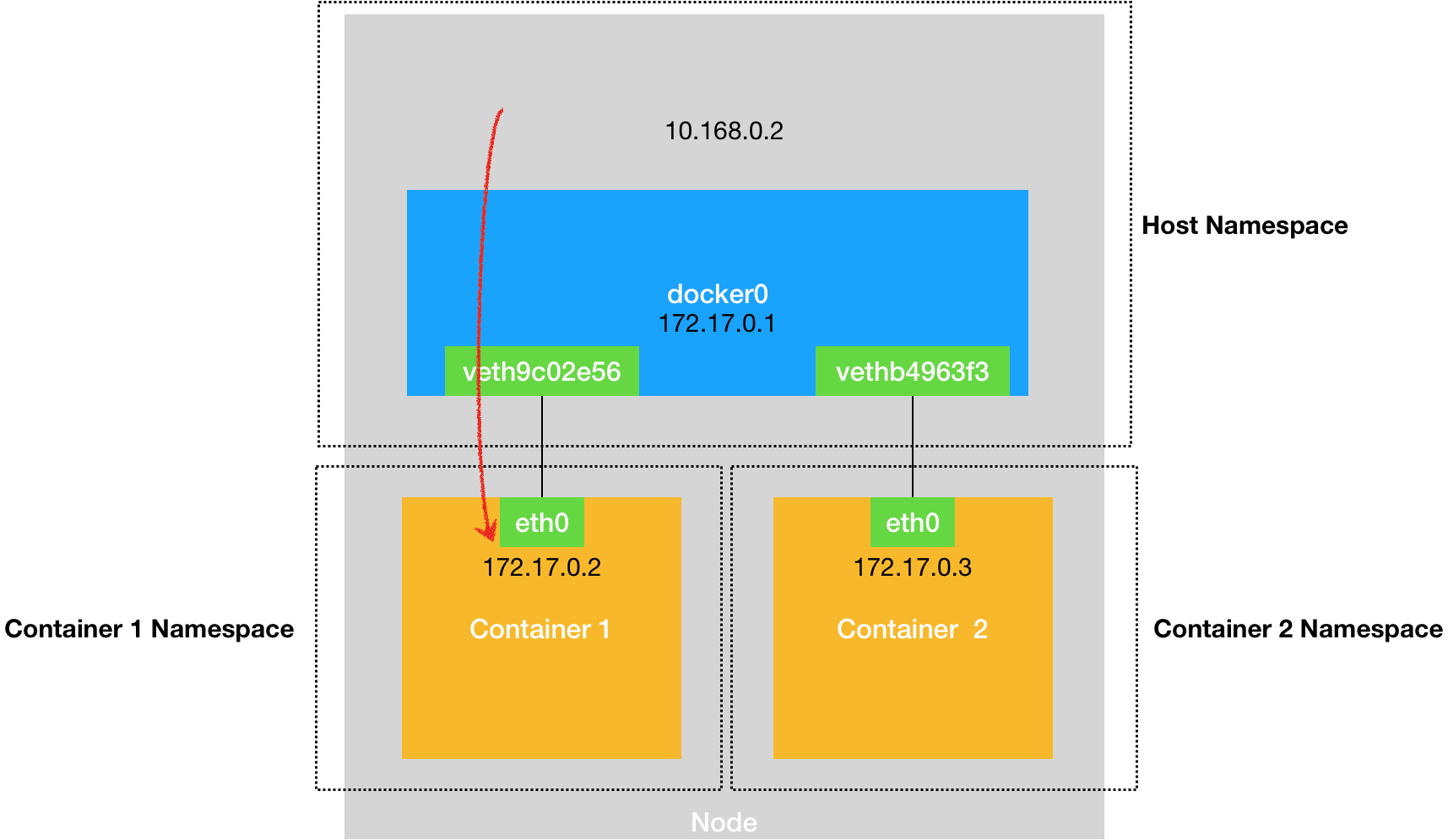
如果容器内部需要访问其他宿主机,可以根据路由直接达到,但是需要回来的路由
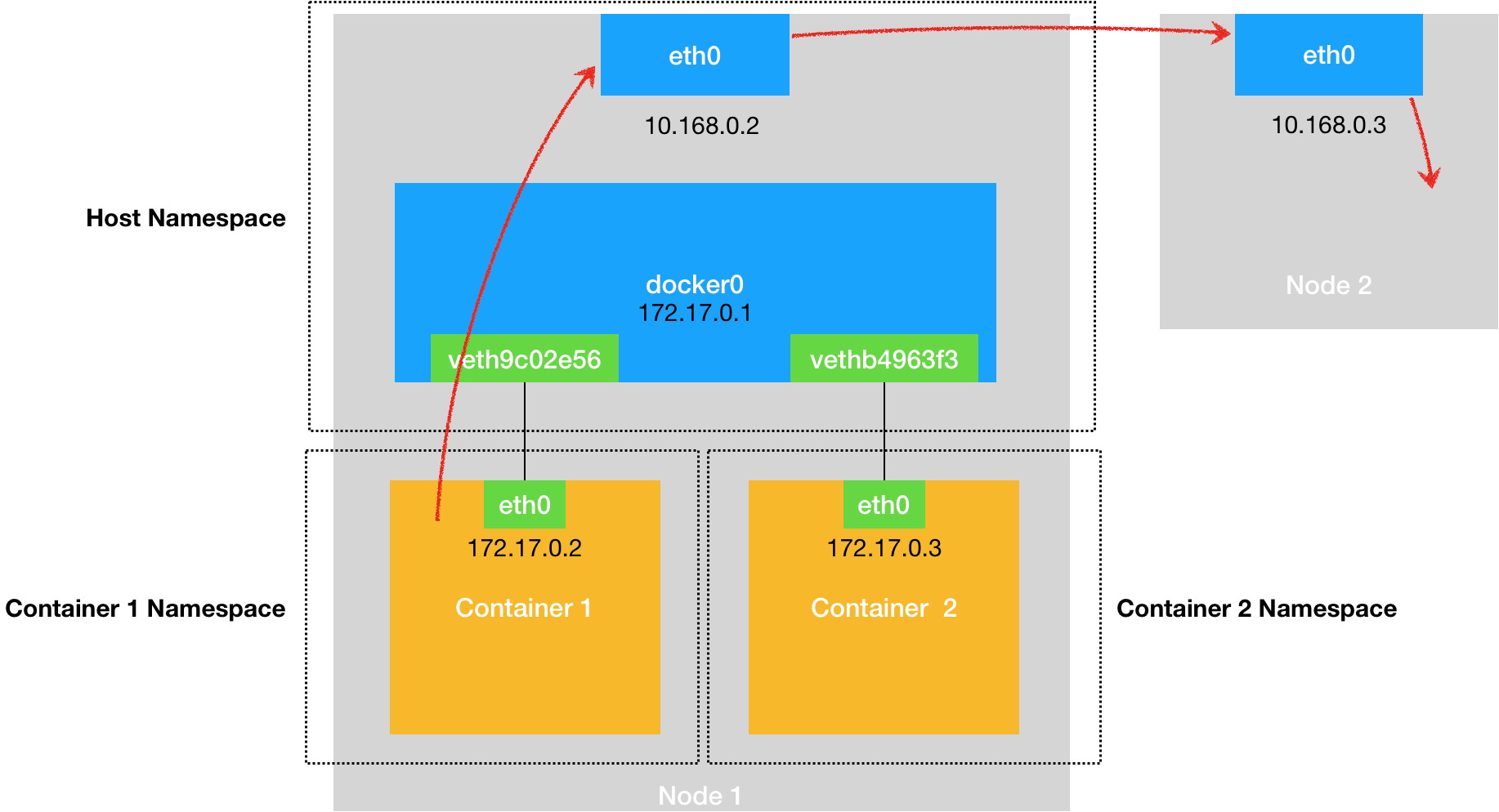
33 | 深入解析容器跨主机网络
跨主机通信需要构建覆盖网络(Overlay Network)
Flannel UDP模式
Flannel项目提供了三种跨主机通信方案,VXLAN,host-gw和UDP
UDP是最早支持的,flannel通过一个Tunnel设备flannel0完成的
Tunnel设备是一种三层网络设备,作用是在用户程序和操作系统内核之间传递数据包
容器之间通信流程
- 发往其他IP宿主机容器的数据包,先到docker0网桥,进入内核
- 在宿主机上根据路由转发到flannel0网卡,当操作系统将数据包发送到flannel0
- flannel0会将数据包交给flannel进程(这就实现了数据包从内核态到用户态的流动)
- flannel根据存储在etcd中的子网信息获取容器所在子网的宿主机IP地址然后
- flannel通过UDP包封装的方式,发送到对应宿主机的UDP8285端口,也就是宿主机的flannel进程
- flannel将这个UDP包解封
- flannel进程向flannel0发送数据包(这就实现了用户态到内核态的流动)
- 在宿主机上根据路由转发的方式发往docker0网桥
- docker0网桥将数据包发往对应容器
流程图就是
所以这个就需要Docker启动的时候docker0的网段必须是Flannel分配的子网,实现方式
$ FLANNEL_SUBNET=100.96.1.1/24
$ dockerd --bip=$FLANNEL_SUBNET ...
这种模式需要做三次内核态与用户态之间数据包的拷贝,而正常情况下是一次
上下文切换和用户态操作的代价其实是比较高的,这也正是造成Flannel UDP模式性能不好的主要原因,所以Flannel已经废弃了。
Flannel VXLAN模式
VXLAN为虚拟可扩展局域网,是一种由Linux内核支持的一种技术,可以构建和之前UDP模式一样的隧道机制
思路是在三层网络上覆盖一层虚拟的由内核VXLAN模块负责维护的二层网络,连接在二层网络上的主机(容器和宿主机)就可以在一个LAN(局域网)进行自由通信,宿主机上启动的设备为VTEP,即:VXLAN Tunnel End Point(虚拟隧道端点),它进行封装和解封装的对象,是二层数据帧(Ethernet frame),但是这些都是在内核完成
容器之间通信流程
- 发往其他IP宿主机容器的数据包,先到docker0网桥,进入内核
- 在宿主机上根据路由转发到flannel.1网卡
- flannel.1需要找到对应的目的宿主机VTEP设备IP地址,通过ARP表获取MAC地址,进行MAC地址封装成数据帧,然后加上用于识别VXLAN的HEADER,然后通过UDP封装后由内核交给eth0网卡进行传输
- 目的宿主机的内核解包的时候看到VXLAN的HEADER,就根据其中的VNI值转发到对应的VXLAN设备
- VTEP设备解包获取到原始数据包就根据路由转发的方式发往docker0网桥
- docker0网桥将数据包发往对应容器
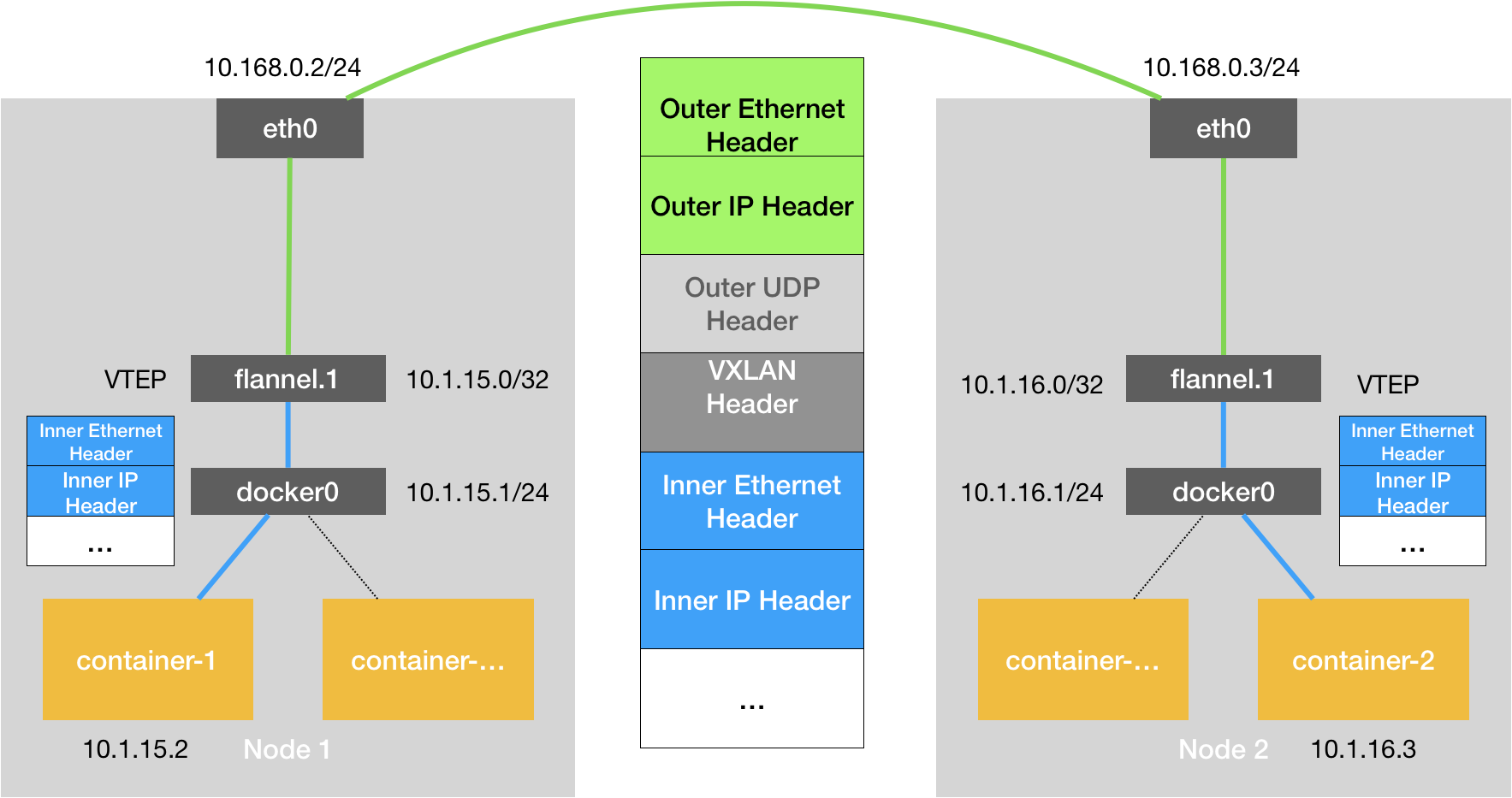
数据帧

Kubernetes替换网络插件
$ rm -rf /etc/cni/net.d/*
$ kubectl delete -f <network-yaml>
$ vi /etc/kubernetes/manifests/kube-controller-manager.yaml
--allocate-node-cidrs=true
--cluster-cidr=10.244.0.0/16
$ systemctl restart kubelet
$ kubectl create -f <network-yaml>
34 | Kubernetes网络模型与CNI网络插件
kubernetes没有使用docker0,而是使用自己启动的cni0,原因有两点
- 不使用docker的网络模型CNM
- Kubernetes配置Pod的Infra容器的Namespace
在kubeadm启动的之后可以指定
$ kubeadm init --pod-network-cidr=10.244.0.0/16
kubernetes在Pod启动的时候自动启动Infra容器,然后直接调动Cni网络插件,为这个Infra容器配置预期的网络栈
CNI网络插件在宿主机的/opt/cni/bin/目录下,可以分为三类
- main插件 用来创建网络设备的二进制文件,例如bridge,ipvlan,loopback,macvlan,ptp(Veth Pair 设备)和vlan等
- IPAM插件 用来分配IP地址的二进制文件,例如DHCP,host-local(使用预先分配的IP地址段进行分配)
- CNI插件 由CNI社区维护的插件 例如flannel,tuning,portmap和bandwidth等
flannel插件是内置了,其他Weave和Calico,就是直接启动一个DaemonSet并挂载宿主机的/opt/cni/bin/目录
flanneld启动后会在每台宿主机上生成它对应的CNI配置文件/etc/cni/net.d/10-flannel.conflist
{
"name": "cbr0",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
容器网络相关的逻辑也不在kubelet的主干代码,而是在容器进行时接口(CRI,Container Runtime Interface)实现完成的,对于docker为dockershim,Kubernetes目前不支持CNI插件混用,默认加载字母顺序的第一个插件,dockershim进行加载配置后,通过flannel和portmap插件完成配置容器网络和配置端口映射的工作
所以一个Pod创建的流程就是
- dockershim调用DockerAPI创建Infra容器
- 执行一个SetUpPod的方法,CNI插件准备参数,包含然后调用CNI插件为Infra容器配置网络
- 第一部分参数是CNI_COMMAND,有ADD和DEL参数,ADD参数是把容器加入到CNI网络,DEL则是把容器从CNI网络删除,对于网桥类的CNI,就是将Veth Pair的方式进行连接,还有
/proc/<容器进程的PID>/ns/net中的信息 - 第二部分参数是从CNI配置文件加载配置信息
- bridge插件根据完善的参数进行操作,如果CNI网桥不存在就创建,通过Infra容器的Network Namespace进入到这个该Namespace,在容器中添加Veth Pair,另一端挂在宿主机的cni0
- 然后bridge插件调用ipam插件设置IP地址到容器的eth0网卡
- 这些操作完成后容器IP地址等参数返回给dockershim,由kubelet添加到Pod相关信息上
需要注意以下参数,导致了第五步发生
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
Delegate字段的意思是,当前CNI插件不会做这些,需要内置的CNI插件完成,Delegate指就是bridge插件,所以dockershim调用Flannel的CNI插件就是完善配置Delegate的Type字段设置为bridge,将Delegate的IPAM字段设置为host-local,然后由具体的插件完成,让后flannel补全的字段如下传递给bridge
{
"hairpinMode":true,
"ipMasq":false,
"ipam":{
"routes":[
{
"dst":"10.244.0.0/16"
}
],
"subnet":"10.244.1.0/24",
"type":"host-local"
},
"isDefaultGateway":true,
"isGateway":true,
"mtu":1410,
"name":"cbr0",
"type":"bridge"
}
先加容器内的Veth Pair是因为容器的Namespace是可以直接通过Namespace文件拿到的;而Host Namespace,则是一个隐含在上下文的参数。先操作容器容易
为了防止自己通过宿主机IP访问自己,还需要flannel配置中添加hairpinMode=true
Kubernetes的CNI网络实现的网络模型
- 所有容器都可以直接使用IP地址与其他容器通信,而无需使用NAT
- 所有宿主机都可以直接使用IP地址与所有容器通信,而无需使用NAT,反之亦然
- 容器自己看到的自己的IP地址,和别人(宿主机或者容器)看到的地址是完全一样的
35 | 解读Kubernetes三层网络方案
Flannel host-gw模式

使用host-gw模式之后,会在宿主机上创建一条规则
$ ip route
...
10.244.1.0/24 via 10.168.0.3 dev eth0
直接指定了下一跳的IP地址就是宿主机的IP地址,这样数据包就直接发送到对应宿主机上,根据对应宿主机到cni0网桥就进入了对应的容器
在这种过程中,减少了封包和解包的性能损耗,host-gw的性能损耗大概在10%左右,而其他基于VXLAN隧道等模式的性能损耗在20%~30%之间
这样直接路由就需要二层网络是互通的,也就是kubernetes集群要在一个子网
Calico
Calico在网络的实现方面和Flannel的host-gw模式一样,但是Calico直接通过BGP边界网关协议来实现路由表的维护
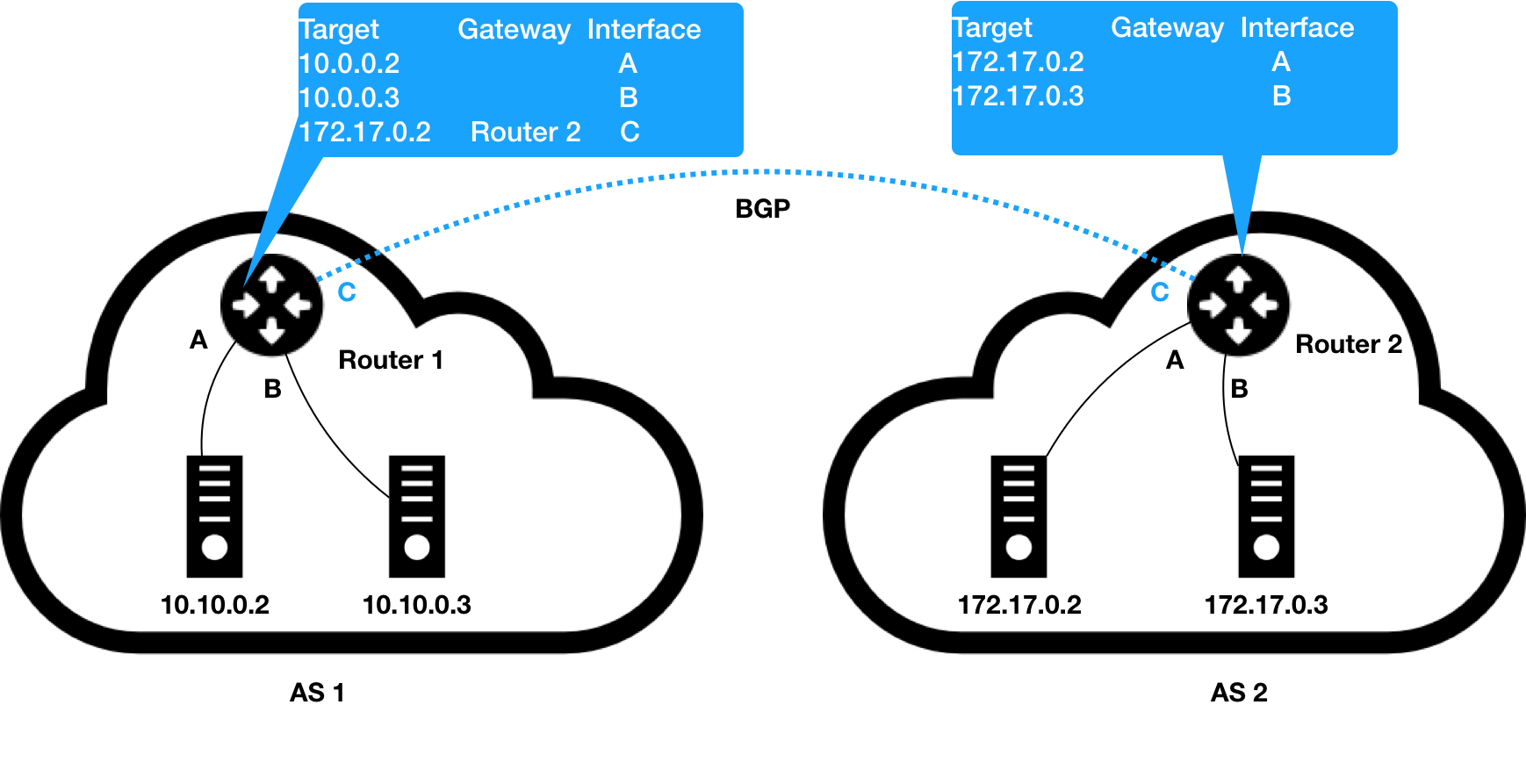
Calico将每个宿主机作为了一个自治系统,每个网关都运行着一个小程序,用于将各自的路由表信息通过TCP协议发送到其他边界网关,其他边界网关的小程序收到这些数据进行分析并更新自身的路由表
Calico项目分三个部分
- Calico的CNI网络插件
- Felix,一个DaemonSet,负责在宿主机上插入路由规则,写入内核转发库,维护Calico网络设备
- BIRD,BGP的Client,在集群分发路由
Calico网络实际工作原理
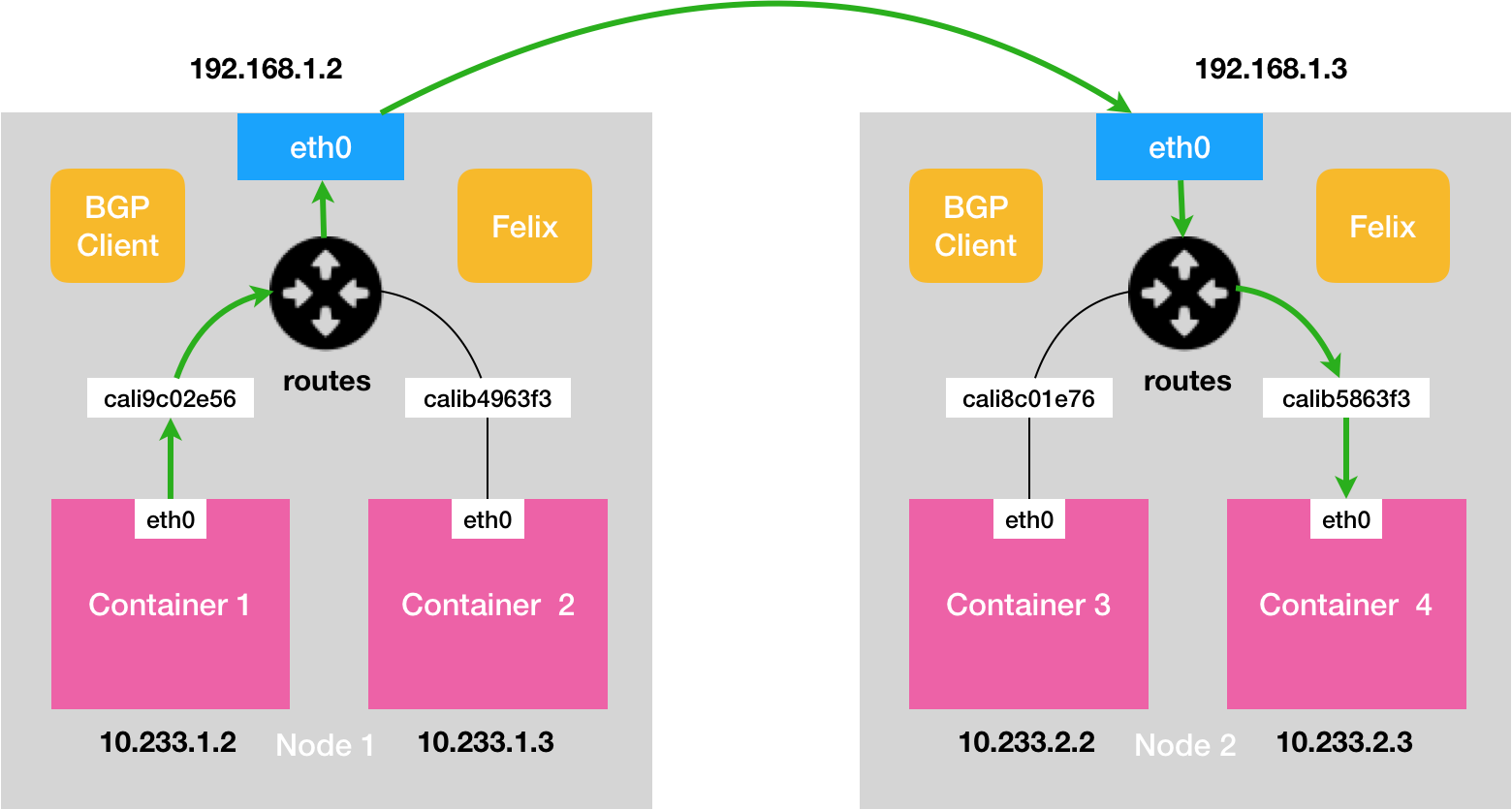
Calico会为每个容器配置一个Veth Pair设备,一端放到宿主机上,一端加入到容器,并且为宿主机上每个容器配置路由10.233.2.3 dev cali5863f3 scope link用于接收数据包
容器发出去的数据包经过Veth Pair设备到达宿主机之后,就会根据路由直接发送正确的网关
下一跳的路由是由Calico的Felix进程维护,而路由规则是BGPClient使用BGP协议传输而来的
Calico默认使用的Node-to-Node Mesh模式,每个宿主机都需要和集群的所有宿主机通信,随着宿主机数量增加,连接的规模会以N的2次方增长,一般100个节点内还可以接受,对于更大的集群就需要Route Reflector模式了,Calico指定几个专门的代理节点用于接收和汇总全局的路由规则,其他节点只需要和代理节点交换数据即可,这样BGP连接的数量级就变为N了
对于Calico也需要二层网络是互通的,不过Calico支持IPIP模式
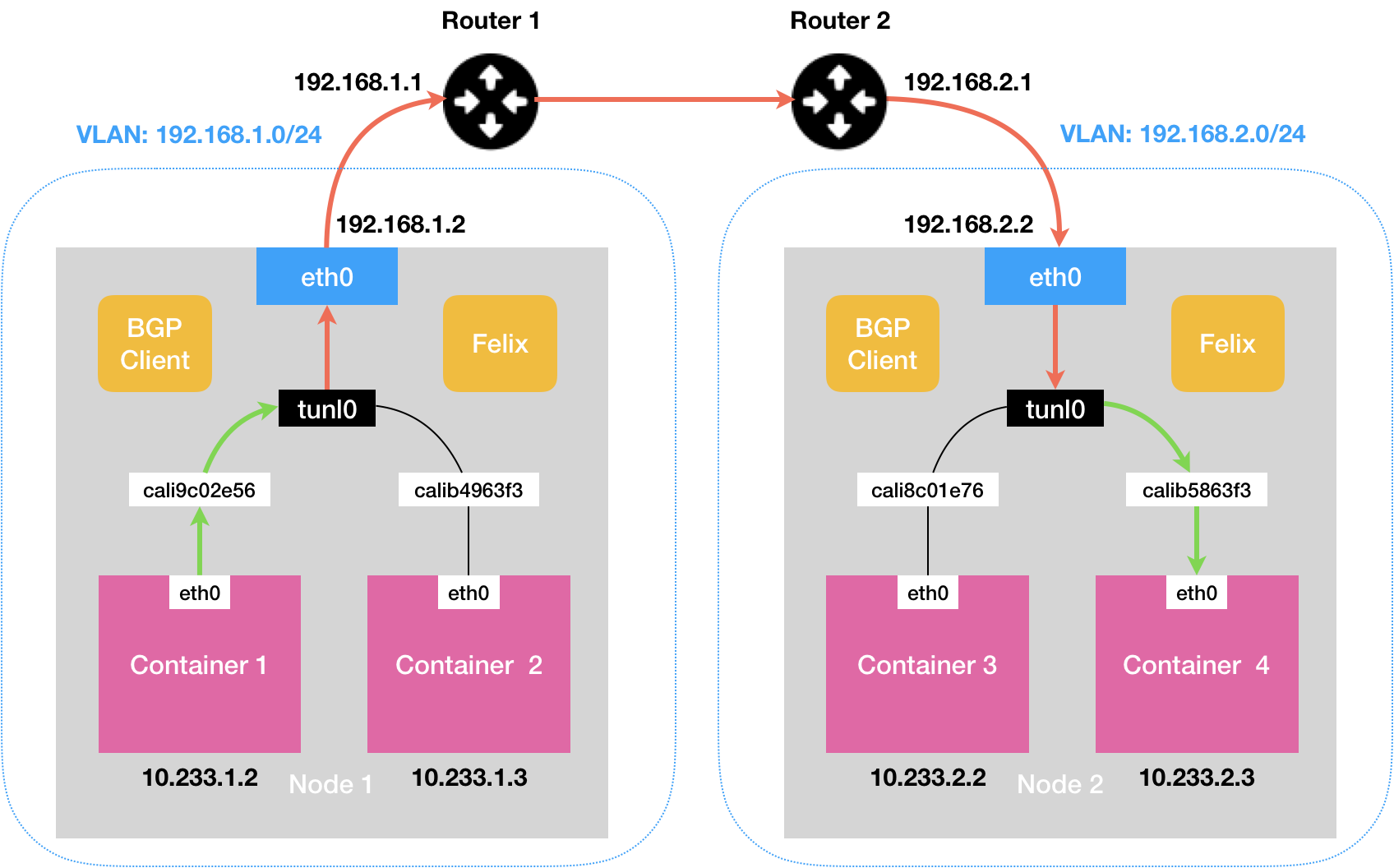
主机上会启动一个tun0设备用于创建IP隧道,数据包进入IP隧道设备就会由内核的IPIP驱动接管,将IP数据包封装在宿主机的IP包,如下所示
接收得到这个数据包的主机内核栈通过IPIP解包然后就能通过路由规则到容器内部了
如果使用了IPIP模式,就增加了封包和解包过程,就会和Flannel的隧道模式一样性能损耗很大
如果可以Calico能够直接让宿主机之间的网关可以通过BGP学习路由规则,就可以解决IPIP性能损耗了,但是公有云不支持
还有方案
- 第一种方案是每个宿主机都和宿主机网关建立BGP Peer模式,需要宿主机网关支持Dynamic Neighbors配置模式,还需要维护宿主机与网关的联系,非常复杂
- 第二种方案是由Route Reflector模式代理的方式,与宿主机网关沟通
这些组件的工作原理就是WATCH Etcd中宿主机和对应网段的变化信息,然后通过BGP协议分发就行
36 | 为什么说Kubernetes只有soft multi-tenancy?
kubernetes的网络隔离是通过NetworkPolicy对象实现
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
- Egress
ingress:
- from:
- ipBlock:
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978
默认情况下Pod是允许所有的,即允许访问进入,也允许访问外部
podSelector定义了规则的应用范围,这个配置中是default Namespace中的role=db的Pod
spec:
podSelector: {}
这个配置代表Namespace下的所有Pod
一旦Pod被NetworkPolicy选中,那么这个Pod就是默认拒绝所有,只有白名单内的操作被允许
- ingress代表流入的请求,有from和ports字段,from允许有三种并列情况ipBlock,NamespaceSelector和PodSelector
- egress代表流出的请求,有to和ports字段,to允许也是那三种
所以上述配置
- 对default namespace下具有role=db的Pod生效
- Pod拒绝请求,除非请求符合白名单规则
- default namespace下role=fronted的Pod的请求或任何Namespace下具有project=myproject的Pod的请求或任何源地址为172.17.0.0/16网段但不属于172.17.1.0/24网段的请求
- 请求目的地址为10.0.0.0/24,TCP协议的5978端口
需要注意以下配置
...
ingress:
- from:
- namespaceSelector:
matchLabels:
user: alice
- podSelector:
matchLabels:
role: client
...
这种配置为或的关系
...
ingress:
- from:
- namespaceSelector:
matchLabels:
user: alice
podSelector:
matchLabels:
role: client
..
这种配置为与的关系
支持NetworkPolicy的CNI插件都维护了一个NetworkPolicy Controller,通过对NetworkPolicy对象的变化修改宿主机的iptables
不过flannel不支持,需要安装flannel+Calico,文档
Controller的原理
对Pod的允许
for dstIP := range 所有被 networkpolicy.spec.podSelector 选中的 Pod 的 IP 地址
for srcIP := range 所有被 ingress.from.podSelector 选中的 Pod 的 IP 地址
for port, protocol := range ingress.ports {
iptables -A KUBE-NWPLCY-CHAIN -s $srcIP -d $dstIP -p $protocol -m $protocol --dport $port -j ACCEPT
}
}
}
KUBE-NWPLCY-CHAIN规则为当IP包的源地址是srcIP、目的地址是dstIP、协议是protocol、目的端口是port的时候,就允许它通过(ACCEPT)。
对Pod的隔离
for pod := range 该 Node 上的所有 Pod {
if pod 是 networkpolicy.spec.podSelector 选中的 {
iptables -A FORWARD -d $podIP -m physdev --physdev-is-bridged -j KUBE-POD-SPECIFIC-FW-CHAIN
iptables -A FORWARD -d $podIP -j KUBE-POD-SPECIFIC-FW-CHAIN
...
}
}
iptables操作的就是Linux内核的Netfilter子系统,是内核挡在网卡和用户进程之间的防火墙
至于为什么是FORWARD链,因为我们请求的时候再转发到网桥的时候需要先经过FORWARD链
- 第一种规则是防止本机的请求,--physdev-is-bridged就是本机网桥上的设备
- 第二种规则是防止跨主机的请求
这些都指定到KUBE-POD-SPECIFIC-FW-CHAIN规则
iptables -A KUBE-POD-SPECIFIC-FW-CHAIN -j KUBE-NWPLCY-CHAIN
iptables -A KUBE-POD-SPECIFIC-FW-CHAIN -j REJECT --reject-with icmp-port-unreachable
第一条规则直接转发到了KUBE-NWPLCY-CHAIN判断是否允许,如果不允许,就会被REJECT
37 | 找到容器不容易:Service、DNS与服务发现
Service
一个典型的Service定义
apiVersion: v1
kind: Service
metadata:
name: hostnames
spec:
selector:
app: hostnames
ports:
- name: default
protocol: TCP
port: 80
targetPort: 9376
通过selector查找app=hostname的Pod,应用80端口转发到Pod的9376端口
对应的Deployment配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: hostnames
spec:
selector:
matchLabels:
app: hostnames
replicas: 3
template:
metadata:
labels:
app: hostnames
spec:
containers:
- name: hostnames
image: k8s.gcr.io/serve_hostname
ports:
- containerPort: 9376
protocol: TCP
被Service选中的Pod为Endpoint
$ kubectl get endpoints hostnames
NAME ENDPOINTS
hostnames 10.244.0.5:9376,10.244.0.6:9376,10.244.0.7:9376
只有处于Running并且通过readinessProde的Pod才会出现在Endpoint中
这样就通过Service进行RR轮序的负载方式了
实现的方式是kube-proxy和iptables实现
kube-proxy通过Service的Informer感知Service对象的创建,然后在宿主机创建iptables规则
-A KUBE-SERVICES -d 10.0.1.175/32 -p tcp -m comment --comment "default/hostnames: cluster IP" -m tcp --dport 80 -j KUBE-SVC-NWV5X2332I4OT4T3
对于这些VIP的请求转发到KUBE-SVC-NWV5X2332I4OT4T3规则,可以看到并不存在这个IP,所以ping没有反应
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-WNBA2IHDGP2BOBGZ
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-X3P2623AGDH6CDF3
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -j KUBE-SEP-57KPRZ3JQVENLNBR
对于请求以1/3的概率发送达到不同的规则
-A KUBE-SEP-57KPRZ3JQVENLNBR -s 10.244.3.6/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-57KPRZ3JQVENLNBR -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.3.6:9376
-A KUBE-SEP-WNBA2IHDGP2BOBGZ -s 10.244.1.7/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-WNBA2IHDGP2BOBGZ -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.1.7:9376
-A KUBE-SEP-X3P2623AGDH6CDF3 -s 10.244.2.3/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-X3P2623AGDH6CDF3 -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.2.3:9376
在DNAT的之后先加上–set-xmark,然后发往对应Pod的IP和端口
kube-proxy还支持IPVS模式,为了解决大量Pod的时候iptables刷新消耗CPU资源
IPVS下创建了Service就会在本地创建虚拟网卡
# ip addr
...
73:kube-ipvs0:<BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 1a:ce:f5:5f:c1:4d brd ff:ff:ff:ff:ff:ff
inet 10.0.1.175/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
然后通过IPVS模块为这个VIP地址设置三个IPVS虚拟主机,使用RR轮询方式
# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.102.128.4:80 rr
-> 10.244.3.6:9376 Masq 1 0 0
-> 10.244.1.7:9376 Masq 1 0 0
-> 10.244.2.3:9376 Masq 1 0 0
由于IPVS模式下,在内核中还是使用NAT的方式转发,所以传输性能并没有提高,降低的维护规则的代价,将操作放入内核态是提升性能的重要手段
DNS
- ClusterIP模式的Service,A记录为
..svc.cluster.local,解析的时候获取的是VIP地址,pod的记录格式为..pod.cluster.local - clusterIP=None的Headless Service模式的Service,A记录为
..svc.cluster.local,解析的时候获取的是Pod的IP地址的集合,pod的记录格式为..svc.cluster.local
对于Headless Service模式,如果pod指定了hostname和subdomain就会变为<hostname>.<subdomain>.svc.cluster.local
38 | 从外界连通Service与Service调试“三板斧”
连通
第一种NodePort
apiVersion: v1
kind: Service
metadata:
name: my-nginx
labels:
run: my-nginx
spec:
type: NodePort
ports:
- nodePort: 8080
targetPort: 80
protocol: TCP
name: http
- nodePort: 443
protocol: TCP
name: https
selector:
run: my-nginx
nodePort的8080端口代理Pod的80端口,443端口代理Pod的443端口
如果不指定NodePort,就会使用默认的30000~32767,可以通过kube-apiserver的–service-node-port-range参数修改
NodePort的工作原理就是加上一个iptables规则
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/my-nginx: nodePort" -m tcp --dport 8080 -j KUBE-SVC-67RL4FN6JRUPOJYM
也是指向了Service的规则
对于NodePort还会加入SNAT操作
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -m mark --mark 0x4000/0x4000 -j MASQUERADE
将IP包的源地址替换,因为对于Client请求会在接收请求的Node上做DNAT
可以将Service的spec.externalTrafficPolicy设置为local,但是如果访问的node上没对应的Pod,请求就会被DROP
第二种是云平台提供的LoadBalancer
第三种是ExternalName
调试
如果是Service无法通过dns访问,一种可能是DNS有问题,一种是Service配置,可以先检查master节点的DNS
# 在一个 Pod 里执行
$ nslookup kubernetes.default
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes.default
Address 1: 10.0.0.1 kubernetes.default.svc.cluster.local
如果正常就去查看Service的配置
如果是Service不能通过ClusterIP访问,先检查是否有Endpoint
$ kubectl get endpoints hostnames
NAME ENDPOINTS
hostnames 10.244.0.5:9376,10.244.0.6:9376,10.244.0.7:9376
Endpoint正常就可以查看kube-proxy是否正常,正常可以看到Setting endpoint和Adding new service的日志
kube-proxy正常就可以查看iptables规则
- KUBE-SERVICES或者KUBE-NODEPORTS规则是否和VIP或者Service NodePort端口一致
- KUBE-SEP-(hash)规则对应的DNAT链是否和Endpoint一致
- KUBE-SVC-(hash)规则对应的负载均衡链是否和Endpoint数量一致
- 对于NodePort还需要检查SNAT链
对于Pod通过Service访问自己,可以配置kubelet的hairpin-mode设置为hairpin-veth或者promiscuous-bridge
hairpin-veth是将CNI0网桥的hairpin-mode设置为1
$ for d in /sys/devices/virtual/net/cni0/brif/veth*/hairpin_mode; do echo "$d = $(cat $d)"; done
/sys/devices/virtual/net/cni0/brif/veth4bfbfe74/hairpin_mode = 1
/sys/devices/virtual/net/cni0/brif/vethfc2a18c5/hairpin_mode = 1
promiscuous-bridge是开启CNI网卡的混杂模式
$ ifconfig cni0 |grep PROMISC
UP BROADCAST RUNNING PROMISC MULTICAST MTU:1460 Metric:1
39 | 谈谈Service与Ingress
Ingress通过rule将请求转发到不同的Service
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: cafe-ingress
spec:
tls:
- hosts:
- cafe.example.com
secretName: cafe-secret
rules:
- host: cafe.example.com
http:
paths:
- path: /tea
backend:
serviceName: tea-svc
servicePort: 80
- path: /coffee
backend:
serviceName: coffee-svc
servicePort: 80
这个配置,对于cafe.example.com下/tea的请求转发给tea-svc的service,而/coffee的请求转发给coffee-svc的service
这就是反向代理的一种抽象,需要部署一个具体的Ingress Controller,可以是nginx,haproxy等等
示例部署一个nginx ingress
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/mandatory.yaml
官方维护的nginx Crontrol定义
Controller会根据Ingress对象的变化创建和变更nginx的conf,使用的nginx lua实现nginx的upstream的动态配置,还支持ConfigMap对nginx的配置自定义配置
Ingress都需要的ssl证书和密钥通过Secret对象定义
如果没有规则会返回nginx的默认404页面,可以通过Pod启动的时候指定–default-backend-service参数指定一个Service来提供这个页面
40 | Kubernetes的资源模型与资源管理
资源限制
Pod是kubernetes的调度的最小单位,所以资源限制都是Pod的字段
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: db
image: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "password"
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- name: wp
image: wordpress
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
CPU是一种可压缩资源,资源匮乏只会饥饿,Pod不会退出,而内存是一种不可压缩资源,资源匮乏会被OOM而kill
Pod的资源配额就是Pod内所有Container的累加值
CPU单位是CPU个数,Kubernetes只负责保证Pod能够使用到1个CPU的计算能力,允许CPU限额设置为分数,或者例子中的500m(500 millicpu),也就是0.5个CPU
内存的单位是bytes,支持你使用Ei、Pi、Ti、Gi、Mi、Ki(或者 E、P、T、G、M、K)的方式来作为bytes的值。这里要注意区分 MiB(mebibyte)和 MB(megabyte)的区别
- 1Mi=1024*1024
- 1M=1000*1000
kubernetes限制容器可以为
spec.containers[].resources.limits.cpu
spec.containers[].resources.limits.memory
spec.containers[].resources.requests.cpu
spec.containers[].resources.requests.memory
在调度的时候,kube-scheduler只会按照requests的值进行计算。而在真正设置Cgroups限制的时候,kubelet则会按照limits的值来进行设置
- 对于CPU指定了requests.cpu=250m,Ggroup的cpu.shares的值设置为
(250/1000)*1024,而如果没有设置默认为1024,当limits.cpu=500m,Cgroups的cpu.cfs_quota_us的值设置为(500/1000)*100ms - 对于Mem指定了limits.memory=128Mi,相当于将Cgroups的
memory.limit_in_bytes设置为128 * 1024 * 1024
requests+limits可以声明一个相对较小的requests值供调度器使用,而Kubernetes真正设置给容器Cgroups的,则是相对较大的limits值
QoS模型
- Pod里的每一个Container都同时设置了requests和limits,并且requests和limits值相等的时候,就属于Guaranteed类别,当Pod仅设置了limits而没有设置requests字段,会被自动化添加为与limit相同的request值
- Pod不满足Guaranteed的条件,但至少有一个Container设置requests,就属于Burstable类别
- Pod如果requests也没有设置,就属于BestEffort类别
QoS模型用于资源匮乏时kubelet对Pod进行Eviction(即资源回收)
不可压缩资源短缺的时候才会触发Eviction,例如内存和磁盘等
默认阈值
memory.available<100Mi
nodefs.available<10%
nodefs.inodesFree<5%
imagefs.available<15%
可以在kubelet配置
kubelet --eviction-hard=imagefs.available<10%,memory.available<500Mi,nodefs.available<5%,nodefs.inodesFree<5% --eviction-soft=imagefs.available<30%,nodefs.available<10% --eviction-soft-grace-period=imagefs.available=2m,nodefs.available=2m --eviction-max-pod-grace-period=600
可以看到是区分Soft和Hard模式的
Soft允许设置时间,例如imagefs.available=2m,当imagefs不足达到2min才会进行Eviction
数据来源为Cgroups读取的值或者cAdvisor监控的数据
当进行Eviction处理的时候后会进入MemoryPressure或DiskPressure状态,从而避免Pod被调度到这个主机
Eviction的时候删除Pod的依据
- BestEffort类别的Pod。
- 其次是Burstable类别并且发生“饥饿”的资源使用量已经超出了requests的Pod
- 最后是Guaranteed类别并且Pod的资源使用量超过了其limits的限制,或者宿主机本身正处于Memory Pressure状态时
cpuset
cpuset将容器绑定到CPU核上
Pod必须requests和limits为相同整数,Pod就会直接被绑定到独占的CPU核,具体由kubelet分配
41 | 十字路口上的Kubernetes默认调度器
kubernetes的默认调度器完成的功能是
- 从所有的节点根据调度算法挑选合适的Node节点
- 从第一步的结果中挑选一个最符合的节点
第一阶段为Predicate,计算完成为符合条件的Node的节点集合,Priority阶段为每个Pod打分,得分最高的node就是最终的节点
对于Pod的调度成功,就是spec.nodeName字段添加上调度的节点名称
调度机制的示意图为
核心为两个调度循环Informer Path和Scheduling Path
Informer Path是启动一个Informer,来WATCH在Etcd中的Pod,Node和Service等资源的变化,当一个Pod被创建就会通过Pod的Informer的Handler加入到调度队列,这个调度队列是一个PriorityQueue优先级队列,设计为了抢占和调度优先级考虑,并且维护了一个调度器缓存scheduler cache,用来提高Predicate和Priority调度算法的执行效率
Scheduling Path负责选取合适的Node进行bind操作,这个操作就是为Pod的nodeName字段添加对应的node,并更新scheduler cache,这个过程为Assume
Assume之后会创建一个Goroutine异步的向APIServer发起更新Pod请求,在Pod被调度到Node上的时候kubelet还会进行Admit的操作来检查Pod是否能运行在这个Node上
kubernetes的默认调度器是无锁化的,只有在对调度队列和 cheduler Cache进行操作时,才需要加锁,但是并不影响Scheduling Path的运行
目前kubernetes的很多组件都能自定义扩展,下一步就是默认调度器了
42 | Kubernetes默认调度器调度策略解析
Predicates
Predicates的过程可以理解为Filter
一般有四种调度类型
- GeneralPredicates,基础调度策略,PodFitsResources检查Pod需要的资源,PodFitsHost宿主机的名字是否跟Pod的spec.nodeName一致,PodFitsHostPorts的宿主机端口是否冲突
- Volume相关的过滤规则,MaxPDVolumeCountPredicate检查节点上的持久化存储是否超过了一定数量等
- 宿主机相关的过滤规则,PodToleratesNodeTaints用于检查Toleration和Taint,NodeMemoryPressurePredicate检查节点资源
- Pod相关的过滤规则,PodAffinityPredicate用于检查亲密性规则
当开始调度的时候会启动16个Goroutine并发计算合适的Node节点,返回Node列表
Priorities
Priorities给Node打分,范围在0~10分
常用的打分规则为LeastRequestedPriority,公式简化就是
score = (cpu((capacity-sum(requested))10/capacity) + memory((capacity-sum(requested))10/capacity))/2
选择空闲资源CPU和MEM最多的主机
还有就是BalancedResourceAllocation,公式简化就是
score = 10 - variance(cpuFraction,memoryFraction,volumeFraction)*10
用于计算Pod上两种资源的距离,选择距小的Node
BalancedResourceAllocation选择的是节点资源分配最平衡的节点,避免CPU大量分配,内存大量剩余
还有NodeAffinityPriority、TaintTolerationPriority 和 InterPodAffinityPriority等,这些规则的匹配字段越多打分越高
43 | Kubernetes默认调度器的优先级与抢占机制
kubernetes的优先级与抢占机制针对的是Pod调度失败怎么办
当Pod调度失败后,它就会被暂时搁置起来,直到Pod更新再会重新被调度
而我们希望,一个高优先级Pod调度失败,该Pod并不会被搁置,而是挤走Node上的低优先级的Pod,这样保证高优先级Pod的调度成功
特性在v1.10可用
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for high priority service pods only."
定义一个high-priority的PriorityClass,值为100万
kubernetes规定优先级为一个32bit的整数,最大不超过10亿,值越大代表优先级越大,超过10亿的值被kubernetes系统Pod使用,保证系统Pod不会被用户Pod抢占
如果globalDefault这是为true,则使用系统的默认值,为false就使用设置的值,没有声明PriorityClass的Pod,优先级为0
Pod使用PriorityClass
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
声明了priorityClassName的Pod,kubernetes的PriorityAdmissionController就会将Pod的spec.priority字段设置为1000000
调度器中维护的调度队列,高优先级的Pod会先出队列,尽快完成调度
当一个高优先级的pod调度失败,调度器就会在当前集群寻找节点,使该节点上一个或多个低优先级的Pod删除,将这个高优先级的Pod调度到这个节点。
在这个过程中不会立刻被调度,而是将spec.nominatedNodeName设置为被抢占的Node,然后重新进入调度周期,这样也不会保证一定会分配到被抢占的Node
被抢占的Pod是被delete API删除的,会通过Controller重新加入调度队列进行部署的
并且被抢占Pod也会有释放资源的过程,其他节点的资源也在变化,因此放入调度队列重新调度是非常合理的
调度队列中有两个不同的队列
一个是activeQ,在这个队列的Pod,都是下一个调度周期需要被调度的对象,创建的新Pod就会加入这个队列
另一个是unschedulableQ,用于存放被调度失败的容器,当这些容器被更新之后就重新移动到activeQ队列
所以一个高优先级的Pod在调度失败后的操作
- 检查失败原因,来确定是否需要抢占,因为很多可能抢占解决不了问题
- 确定可以发生抢占,调度器缓存一份节点信息的复制模拟抢占过程,逐一删除低优先级的Pod,然后检查是否能运行该高优先级Pod,如果可以了就记录下Node和被删除的Pod列表,然后判断尽量减少抢占造成的影响
- 开始抢占操作,清理Pod所携带的nominatedNodeName字段,把抢占者的nominatedNodeName字设置为对应Node,调度器开启Goroutine删除牺牲者
- 然后抢占者Pod就可以重新调度,被牺牲的Pod也会由Controller重新加入调度队列进行部署的
还有就是当一个Pod被更新,调度器会将和这Pod有Affinity/Anti-affinity关系重新移动到activeQ中,再度尝试调度
44 | Kubernetes GPU管理与Device Plugin机制
在Pod的yaml中声明需要的GPU个数即可
以NVIDIA的GPU,当容器被创建,就必须出现两种设备和目录
- GPU设备,例如/dev/nvidia0
- GPU驱动目录,例如/usr/local/nvidia/*
GPU设备路径应该是容器启动时的Devices参数,而驱动目录则是该容器启动时的Volume参数,kubernetes的GPU支持中,kubelet将这两部分设置在容器的CRI参数中了
apiVersion: v1
kind: Pod
metadata:
name: cuda-vector-add
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
image: "k8s.gcr.io/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1
kubernetes并没有明确的特殊字段负责gpu
kube-scheduler并不关心这些字段的含义,在计算的时候直接在资源可用量里减去Pod申请的量即可,这个Extended Resource字段就是kubernetes对用户自定义资源的一种扩展
这些自定义资源可以在node的status字段添加
apiVersion: v1
kind: Node
metadata:
name: node-1
...
Status:
Capacity:
cpu: 2
memory: 2049008Ki
可以通过patch API来更新Node
# 启动 Kubernetes 的客户端 proxy,这样你就可以直接使用 curl 来跟 Kubernetes 的 API Server 进行交互了
$ kubectl proxy
# 执行 PACTH 操作
$ curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "add", "path": "/status/capacity/nvidia.com/gpu", "value": "1"}]' \
http://localhost:8001/api/v1/nodes/<your-node-name>/status
patch完的Node
apiVersion: v1
kind: Node
...
Status:
Capacity:
cpu: 2
memory: 2049008Ki
nvidia.com/gpu: 1
在GPU的支持方案中,有一种Device Plugin的插件来负责,就包括了对硬件的Extended Resource字段上报
硬件设备都有一种对应的Device Plugin的插件管理,通过gRPC的方式与kubelet连接,通过ListAndWatch的API定期上报数据,对于GPU上报的是GPU的ID列表
- 当Pod申请了GPU,就会从kubernetes的调度器的缓存寻找合适的Node,将Node和Pod绑定,缓存的GPU数量减1
- kubelet对Pod进行调度的时候,在持有的GPU列表中为容器分配GPU,然后向Device Plugin插件发起Allocate()请求,参数为对应的设备ID
- Device Plugin插件收到请求会找到对应的设备和驱动信息返回为kubelet
- kubelet收到之后就完成为容器分配GPU的操作,将这些发送给Docker来创建相应的容器
其他硬件也需要遵循这个流程
service DevicePlugin {
// ListAndWatch returns a stream of List of Devices
// Whenever a Device state change or a Device disappears, ListAndWatch
// returns the new list
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
// Allocate is called during container creation so that the Device
// Plugin can run device specific operations and instruct Kubelet
// of the steps to make the Device available in the container
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
}
kubernetes实现了很多插件,包括FPGA,SRIOV和RDMA等等
45 | 幕后英雄:SIG-Node与CRI
kubelet和容器运行时都属于SIG-Node的范畴
kubelet的工作流程为
可以看到也是一个工作循环,SyncLoop
驱动循环的事件有Pod更新,Pod生命周期变换,kubelet本身的执行周期和定期清理事件
和其他控制器类似,第一件事就是Listers,注册关心的事件的Informer,这些都是SyncLoop的数据来源
除此之外,kubelet还维护了很多子系统循环,例如Volume Manager,Image Manager, Node Status Manager等等
kubelet通过WATCH的方式监听与自己相关的Pod的变化,过滤条件就是nodeName字段与自己相同,然后将这些Pod信息都缓存在自己的内存
当一个Pod完成调度与一个Node绑定,这个Pod的变化就会触发kubelet在控制循环中的Handler,就是HandlerPods部分,检查Pod在kubelet内存的状态,判断是新调度的Pod,进而触发Handler的ADD事件完成对应的处理,在具体的处理过程中会启动一个Pod Update Worker的单独的Goroutine来完成对Pod的处理工作,如果是ADD就检查需要的资源等是否准备好且可用,然后调用容器运行时来完成创建容器
这里调用的时候不会直接调用Docker的API,而是CRI容器运行时接口的gRPC来间接执行,在v1.6版本之前是使用docker等容器API的
kubelet的每次更新都需要考虑Docker和rkt两种运行场景情况,SNG-Node就为了解决这个问题,把kubelet对容器的操作抽象为一个接口,kubelet只需要与这个接口打交道即可,然后容器服务提供这个gRPC给kubelet服务
在有了CRI后,kubelet和kubernetes的架构变为了如下图所示
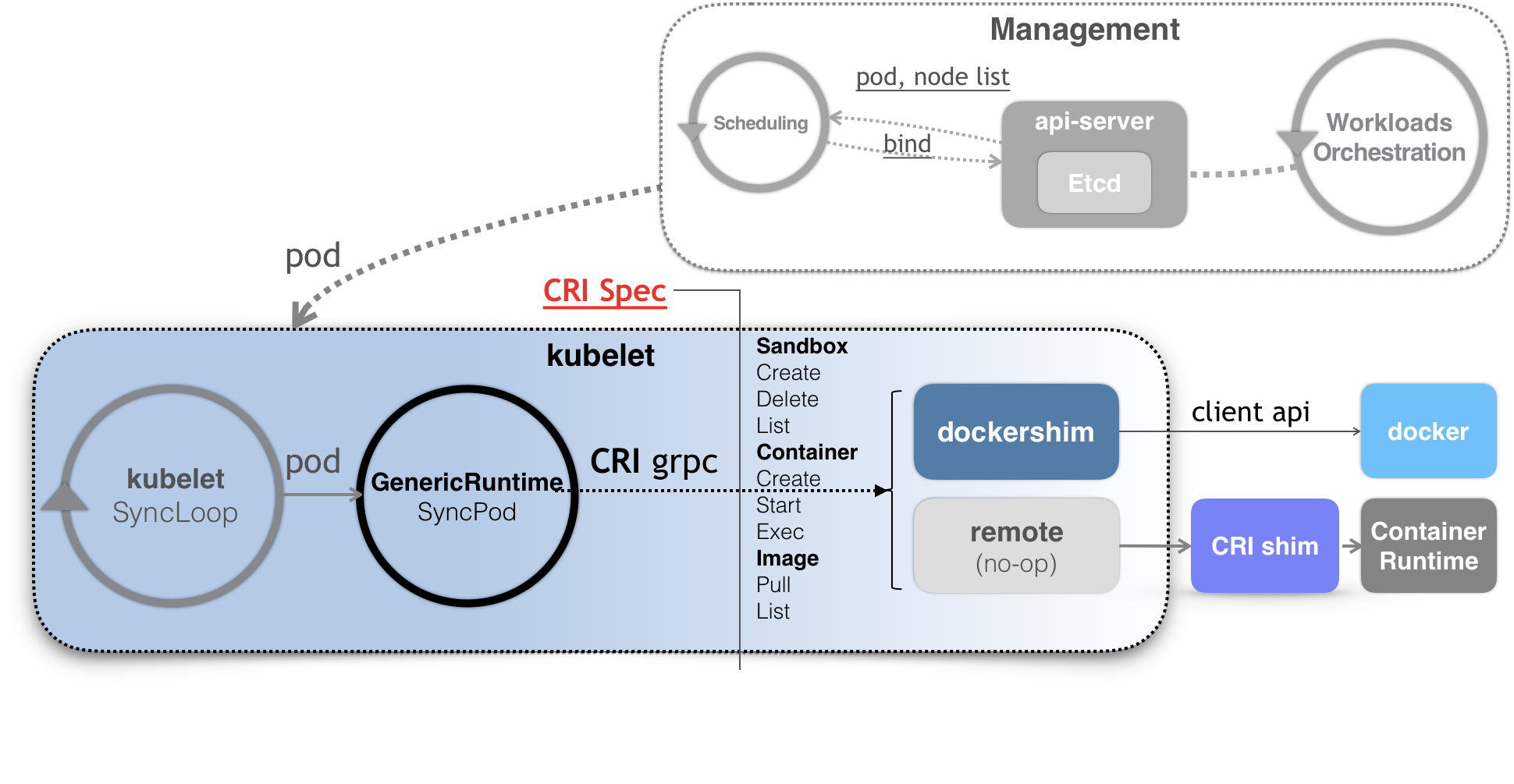
kubelet就可以直接调用一个GenericRuntime的通用组件来调用创建Pod的CRI请求了
对于Docker是封装在了一个dockershim的组件,然后将请求内容组成DockerAPI发送给Docker Daemon
46 | 解读 CRI 与 容器运行时
每个容器都可以实现一个CRI shim,自行对CRI请求进行处理,这样kubernetes就有一个统一的容器抽象层,可以使下层容器运行时自由的接入到kubernetes
CRI待实现的接口如下
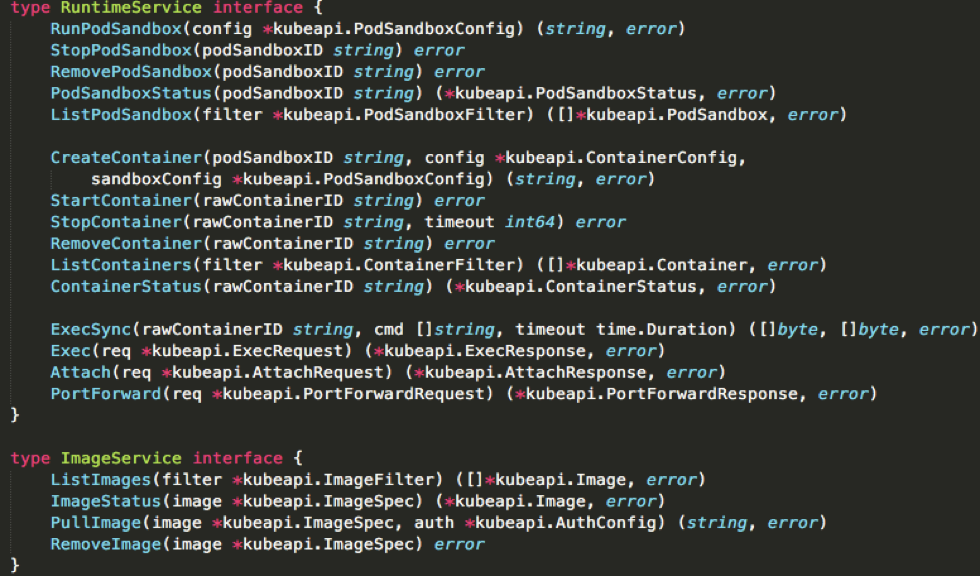
可以看到CRI已经被分为两组
- 第一组是RuntimeService,提供的接口主要是和容器相关的操作,比如容器的创建,删除,执行exec等
- 第二组是ImageService,提供的接口主要是和镜像相关的操作,比如镜像的拉取,删除等
CRI的设计原则是接口只关注容器,而不关注Pod,原因主要是Pod是kubernetes的编排概念,而不是容器运行时的概念,如果引入Pod概念,Pod的API字段发生变化那么CRI就需要变更
CRI中有一组RunPodSandbox的接口,是抽取了Pod的一部分与容器运行时先关的字段,比如Hostname,DnsConfig等,也是描述容器运行层面的字段
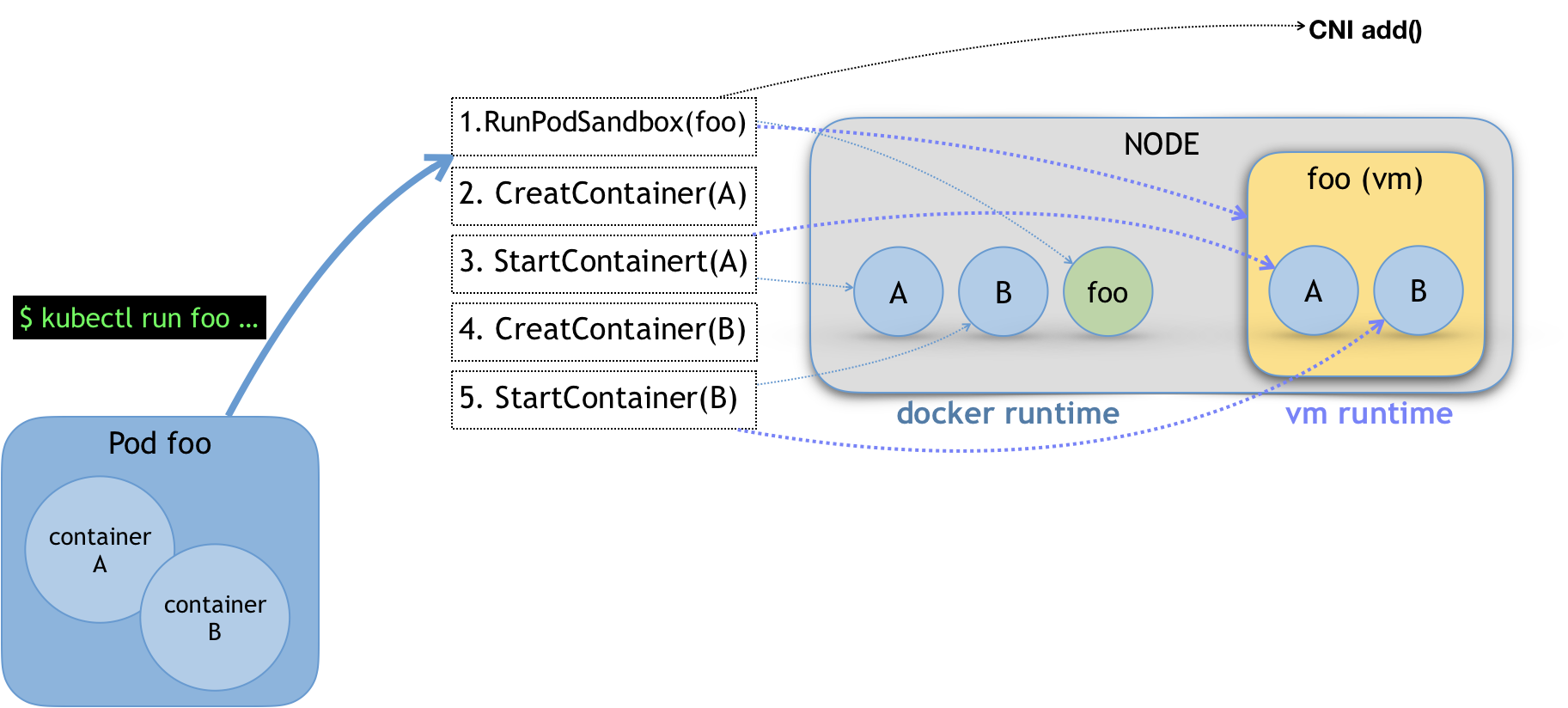
当创建一个Pod的时候,对于Docker,dockershim就会创建一个Infra的容器用来hold住整个Pod的NetWorkNamespace,而如果是kata Container项目CRI就会创建一个轻量级虚拟机来充当Pod
在RunPodSandbox这个接口的实现中,你还需要调用NetworkPlugin.SetUpPod方法来为这个Sandbox设置网络,实际上就是调用CNI插件的add方法
然后继续调用CreateContainer和StartContainer接口来创建和启动容器A和B,然后宿主机上就会出现三个Docker容器组成的Pod,如果是kata Container项目就是两个容器运行在一个轻量级虚拟机
除了生命周期,shim还需要支持exec和log操作,这些操作需要kubelet来维护一个gRPC调用的长连接来传输数据,这被称为Streaming API,依赖于Streaming Server
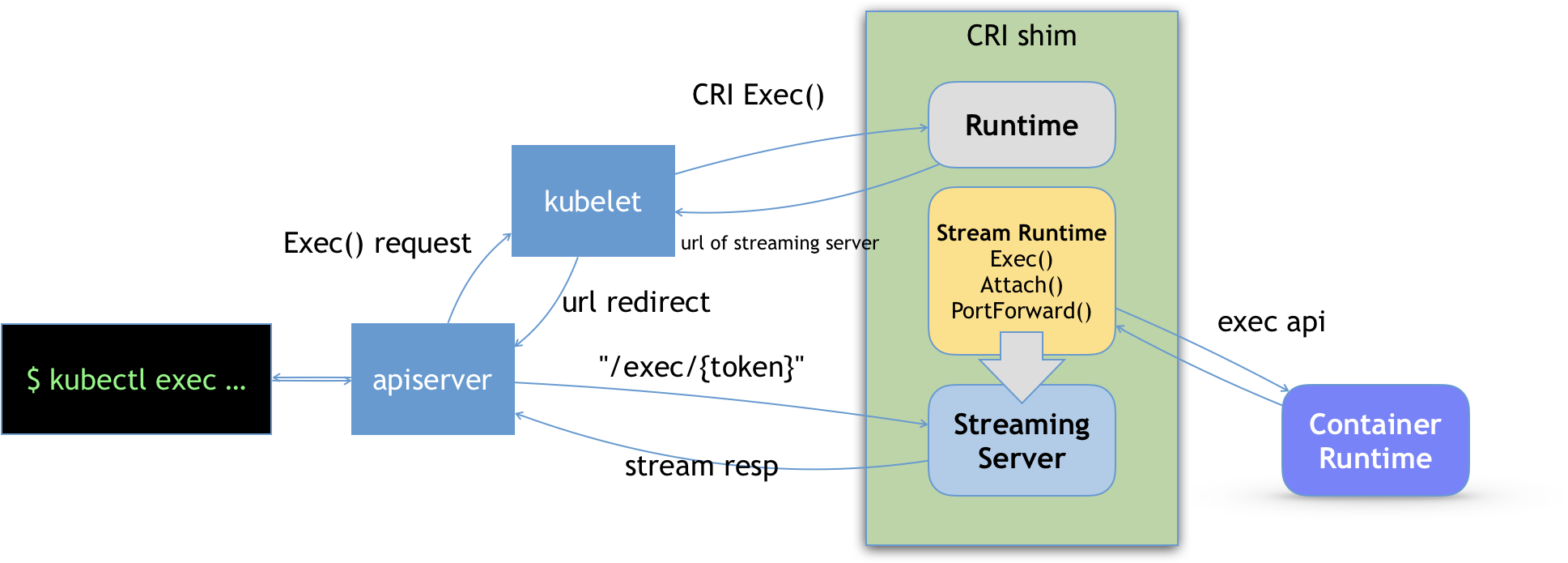
当指定exec操作的时候会将其交给APIServer,先后APIServer调用对应Node的kubelet的Exec API,然后kubelet会调用CRI的Exec接口,响应这个接口的就是CRI shim,返回的是一个URL给kubelet,及时CRI shim对应的Streaming Server的地址和端口,kubelet再将这个URL以Redirect的方式返回给APIServer,请求就会重定向到到对应Streaming Server上发起exec请求,并维护长链
47 | 绝不仅仅是安全:Kata Containers 与 gVisor
docker项目发布后,google尝试创建了novm项目使用常规的虚拟化技术运行Docker镜像,不过开源不久就失败,最后还是有类似开源项目,最合并为Kata Containers,后来18年google发布了gVisor项目
两者都是给进程分配了一个独立的操作系统内核,避免容器共享宿主机内核
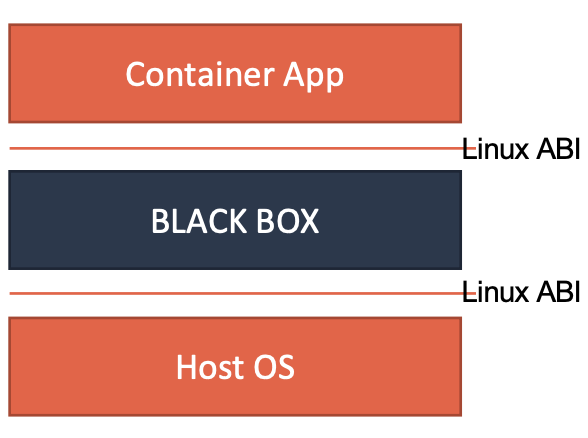
Kata Containers通过虚拟硬件模拟了小型的虚拟机,gVisor则是通过go语言模拟出了一个运行在用户态的操作系统内核
更细节的略过,这样还是性能降低了
48 | Prometheus、Metrics Server与Kubernetes监控体系
Prometheus的工作方式如下
工作的核心就是通过Pull方式搜集被监控对象的Metric数据,然后将数据保存在TSDB时间序列数据库,例如OpenTSDB,InfluxDB等,余下的组件就围绕着这套机制运行
- Pushgateway可以允许被监控对象以Push的方式向Prometheus推送Metrics数据
- Alertmanager可以根据Metrics进行报警
- Granafa是常用来暴露服务的灵活配置的监控数据的可视化界面
对于kubernetes的监控可以来自几个部分
第一种是宿主机的监控数据,借助了Prometheus维护的Node Exporter工具,一般会以DaemonSet的方式运行在宿主机上,暴露监控到的数据给Prometheus,包括的监控项
第二种是来源于kubernetes的API Service,kubelet等组件的metrics的API,包括了各个组件的核心监控指标,例如Controller的工作队列长度,请求的QPS和延迟数据
第三种是kubernetes相关的监控数据,包括Pod,Node,容器,Service等重要数据
容器相关的监控来自kubelet的cAdvisor也随之启动,核心监控数据由扩展的Metrics Server提供,通过标准的kubernetes的API暴露出来,用户直接通过API访问
http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/namespaces/
返回的是一个Pod的监控数据,这些数据是从kubelet的Summary API(<kubelet_ip>:<kubelet_port>/stats/summary)获取的
Metries Server并不是kube-apiserver的一部分,而是通过Aggregator机制在独立部署的情况下由kube-apiserver统一提供服务
Aggregator APIServer的工作原理如下图
kube-apiserver只是提供了代理的功能
如果是用的kubeadm或者kube-up.sh,默认是开启的,如果是DIY的就需要在kube-apiserver的参数加上以下配置
--requestheader-client-ca-file=<path to aggregator CA cert>
--requestheader-allowed-names=front-proxy-client
--requestheader-extra-headers-prefix=X-Remote-Extra-
--requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
--proxy-client-cert-file=<path to aggregator proxy cert>
--proxy-client-key-file=<path to aggregator proxy key>
具体的需要参考官方文档
Metrics Server可以直接通过yaml部署
$ git clone https://github.com/kubernetes-incubator/metrics-server
$ cd metrics-server
$ kubectl create -f deploy/1.8+/
49 | Custom Metrics: 让Auto Scaling不再“食之无味”
kubernetes实现了Horizontal Pod Autoscaler自动扩展器组件,可以依赖Custom Metrics来执行用户的调度策略
Custom Metrics也是通过Aggregator实现的,在Prometheus中就是Adaptor
要实现一个根据指定Pod收到的HTTP请求数量来进行Auto Scaling的Custom Metrics,这个Metrics就可以通过访问如下所示的自定义监控URL获取到
https://<apiserver_ip>/apis/custom-metrics.metrics.k8s.io/v1beta1/namespaces/default/pods/sample-metrics-app/http_requests
工作原理是当访问这个URL,Custom Metrics APIServer就会去Prometheus里查询名叫sample-metrics-app这个Pod的http_requests指标的值,然后按照固定的格式返回给访问者
http_requests这个指标需要Pod应用本身暴露一个metrics的API,从Pod上采集HPA只需要定时去访问监控的URL即可,然后根据这些值判断是否需要Scaling
获取这个代码https://github.com/resouer/kubeadm-workshop
部署Prometheus
$ kubectl apply -f demos/monitoring/prometheus-operator.yaml
clusterrole "prometheus-operator" created
serviceaccount "prometheus-operator" created
clusterrolebinding "prometheus-operator" created
deployment "prometheus-operator" created
$ kubectl apply -f demos/monitoring/sample-prometheus-instance.yaml
clusterrole "prometheus" created
serviceaccount "prometheus" created
clusterrolebinding "prometheus" created
prometheus "sample-metrics-prom" created
service "sample-metrics-prom" created
部署Custom Metrics APIServer
$ kubectl apply -f demos/monitoring/custom-metrics.yaml
namespace "custom-metrics" created
serviceaccount "custom-metrics-apiserver" created
clusterrolebinding "custom-metrics:system:auth-delegator" created
rolebinding "custom-metrics-auth-reader" created
clusterrole "custom-metrics-read" created
clusterrolebinding "custom-metrics-read" created
deployment "custom-metrics-apiserver" created
service "api" created
apiservice "v1beta1.custom-metrics.metrics.k8s.io" created
clusterrole "custom-metrics-server-resources" created
clusterrolebinding "hpa-controller-custom-metrics" created
创建对应的ClusterRoleBinding,以便能够使用curl来直接访问Custom Metrics的API
$ kubectl create clusterrolebinding allowall-cm --clusterrole custom-metrics-server-resources --user system:anonymous
clusterrolebinding "allowall-cm" created
部署待监控系统HPA
$ kubectl apply -f demos/monitoring/sample-metrics-app.yaml
deployment "sample-metrics-app" created
service "sample-metrics-app" created
servicemonitor "sample-metrics-app" created
horizontalpodautoscaler "sample-metrics-app-hpa" created
ingress "sample-metrics-app" created
HPA的配置文件
kind: HorizontalPodAutoscaler
apiVersion: autoscaling/v2beta1
metadata:
name: sample-metrics-app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: sample-metrics-app
minReplicas: 2
maxReplicas: 10
metrics:
- type: Object
object:
target:
kind: Service
name: sample-metrics-app
metricName: http_requests
targetValue: 100
scaleTargetRef指定被监控的为Deployment类型的sample-metrics-app,它最小的实例数目是2,最大是10,进行Scale的依据是metrics字段,http_requests的
HPA请求的URL就是
https://<apiserver_ip>/apis/custom-metrics.metrics.k8s.io/v1beta1/namespaces/default/services/sample-metrics-app/http_requests
通过hey的测试工具来为我们的应用增加一些访问压力
$ # Install hey
$ docker run -it -v /usr/local/bin:/go/bin golang:1.8 go get github.com/rakyll/hey
$ export APP_ENDPOINT=$(kubectl get svc sample-metrics-app -o template --template {{.spec.clusterIP}}); echo ${APP_ENDPOINT}
$ hey -n 50000 -c 1000 http://${APP_ENDPOINT}
去访问应用Service的Custom Metircs URL,就会看到这个URL已经可以为你返回应用收到的HTTP请求数量了
$ curl -sSLk https://<apiserver_ip>/apis/custom-metrics.metrics.k8s.io/v1beta1/namespaces/default/services/sample-metrics-app/http_requests
{
"kind": "MetricValueList",
"apiVersion": "custom-metrics.metrics.k8s.io/v1beta1",
"metadata": {
"selfLink": "/apis/custom-metrics.metrics.k8s.io/v1beta1/namespaces/default/services/sample-metrics-app/http_requests"
},
"items": [
{
"describedObject": {
"kind": "Service",
"name": "sample-metrics-app",
"apiVersion": "/__internal"
},
"metricName": "http_requests",
"timestamp": "2018-11-30T20:56:34Z",
"value": "501484m"
}
]
}
需要注意的是Custom Metrics API返回的Value的格式
代码的实现是
var http = require('http');
var os = require('os');
var totalrequests = 0;
http.createServer(function(request, response) {
totalrequests += 1
response.writeHead(200);
if (request.url == "/metrics") {
response.end("# HELP http_requests_total The amount of requests served by the server in total\n# TYPE http_requests_total counter\nhttp_requests_total " + totalrequests + "\n");
return;
}
response.end("Hello! My name is " + os.hostname() + ". I have served "+ totalrequests + " requests so far.\n");
}).listen(8080)
/metrics取到的就是http_requests_total的值,也就是Prometheus存储的值
Custom Metrics APIServer收到对http_requests_total的请求就将其转为一个时间为单位的请求率,将这个值返回,501484m的格式为milli-requests,相当于过去的2min内每秒有501个请求,这样HPA就可以直接使用
而Prometheus监控的配置在
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: sample-metrics-app
labels:
service-monitor: sample-metrics-app
spec:
selector:
matchLabels:
app: sample-metrics-app
endpoints:
- port: web
ServiceMonitor对象正是Prometheus Operator定义的
Aggregator APIServer是一个有效的扩展机制,KubeBuilder可以帮助我们生成一个APIServer的完整框架
50 | 让日志无处可逃:容器日志收集与管理
容器的日志通过stdout和stderr输出的结果都被保存在宿主机的一个json文件上,kubernetes本身是不会收集这些日志的
kubernetes可以通过三种方式获取日志收集
第一种就是在node上部署logging agent,然后将日志转发到后端存储
可以参考官方文档Logging Using Elasticsearch and Kibana
但是需要应用日志都打印到stdout和stderr
第二种就是通过容器将应用存储到文件的日志读取出来输出到stdout和stderr,然后使用第一种方案
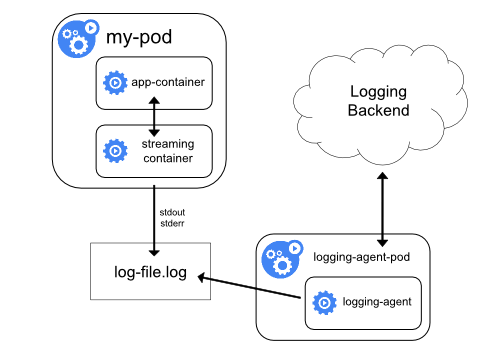
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
sidecar和主容器之间共享Volume,不过对于日志量很大打印到stdout和stderr,很容易就把系统日志配额用满
第三种就是直接通过容器将日志文件发送到远端存储
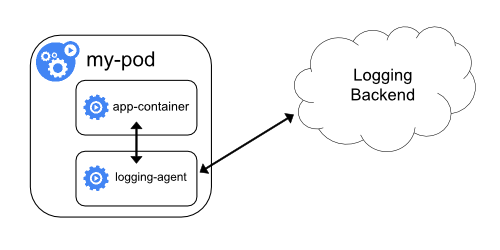
51 | 谈谈Kubernetes开源社区和未来走向
CNCF可以说是云计算领域的高度,就像apache当前在大数据领域的一样
52 | 答疑:在问题中解决问题,在思考中产生思考
整理
结束语 | Kubernetes:赢开发者赢天下
kubernetes能赢的关键是赢得了广大的开发者,用户更关心的API,项目的本质就是控制器模式,通过围绕API创建出一个新的生态

