

Elasticsearch权威指南 阅读笔记(3)分布式增删改查,搜索,映射和分析
目录:
分布式增删改查
路由文档到分片
索引一个文档,它被存储在单独一个主分片上,Es通过算法进行决定
shard = hash(routing) % number_of_primary_shards
routing值是一个任意字符串,它默认是_id但也可以自定义。这个routing字符串通过哈希函数生成一个数字,然后除以主切片的数量得到一个余数(remainder),余数的范围永远是0到number_of_primary_shards - 1,这个数字就是特定文档所在的分片。
这也解释了为什么主分片的数量只能在创建索引时定义且不能修改:如果主分片的数量在未来改变了,所有先前的路由值就失效了,文档也就永远找不到了。
所有的文档API(get、index、delete、bulk、update、mget)都接收一个routing参数,它用来自定义文档到分片的映射。自定义路由值可以确保所有相关文档——例如属于同一个人的文档——被保存在同一分片上。
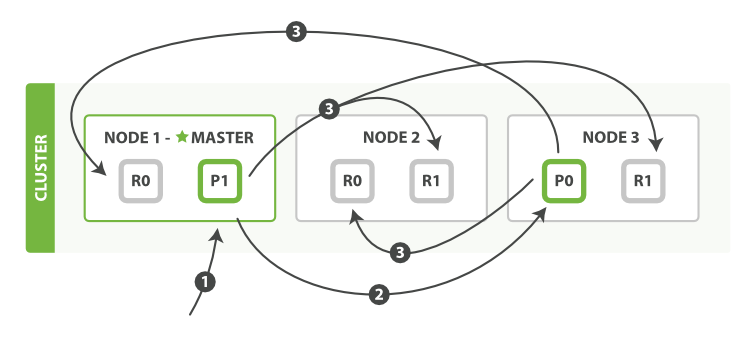
主分片和复制分片如何交互
发送请求给集群中任意一个节点。每个节点都有能力处理任意请求。每个节点都知道任意文档所在的节点,所以也可以将请求转发到需要的节点。
新建,索引和删除文档
新建、索引和删除请求都是写(write)操作,它们必须在主分片上成功完成才能复制到相关的复制分片上。
顺序步骤
- Client给Node1发送请求
- Node1确定文档
_id属于分片0。它转发请求到Node 3,分片0位于这个节点上 - Node3在主分片上执行请求,如果成功,就会将请求结果发送给Node1和Node2的复制节点上,当复制节点返回成功,Node3报告成功到请求节点Node1,Node1返回给Client
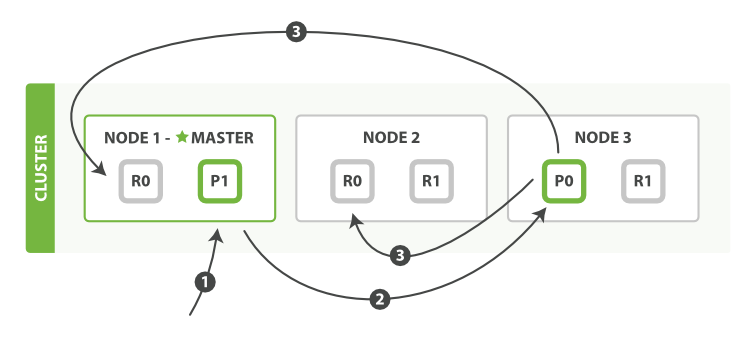
当Client接收到成功响应,文档已经创建或者修改应用在所有的主分片和复制分片上了,但是也有参数可以修改该流程,但是会牺牲一些安全性,这一选项很少使用,因为Es已经足够快了
replication
默认复制的时候使用的sync,这将导致主分片得到复制分片的响应成功之后才会返回
如果设置了replication为aysnc,请求在主分片上被执行后就会返回给Client,然后依旧会转发请求给复制节点,但是Client就无法知晓复制节点请求的成功与否。
这个配置不建议使用,因为sync允许Es强制返回传输,而async可能会因为在不等待其他分片就绪的情况下发送过多的请求而使Es过载
consistency
默认主分片在尝试写入规定数量的时候或过半分片是可用的,防止数据写入错的网络分区
规定的数量计算公式
int( (primary + number_of_replicas) / 2 ) + 1
consistency允许的值为one(只有一个主分片),all(所有主分片和复制分片)或者默认的quorum或过半分片。
number_of_replicas是在索引中的的设置,如果活动分片数量不够是无法索引或删除任何文档的
timeout
当分片副本不足时会怎样,Elasticsearch会等待更多的分片出现。默认等待一分钟。如果需要,你可以设置timeout参数让它终止的更早:100表示100毫秒,30s表示30秒。
检索文档
文档能够从主分片或任意一个复制分片被检索。
检索一个文档必要的顺序步骤:
- Client向Node1发送Get请求
- Node1节点使用文档的
_id确认文档属于分片0,分片0对应的复制分片在三个节点上都有,此时,它转发请求到Node2 - Node2返回文档给Node1然后返回给客户端
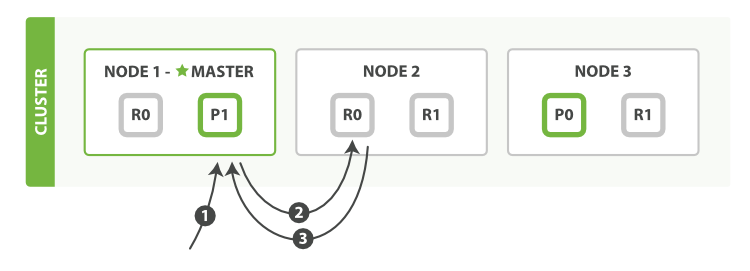
对于读请求,为了平衡负载,请求节点会为每个请求选择不同的分片——它会循环所有分片副本。
可能的情况是,一个被索引的文档已经存在于主分片上却还没来得及同步到复制分片上。这时复制分片会报告文档未找到,主分片会成功返回文档。一旦索引请求成功返回给用户,文档则在主分片和复制分片都是可用的。
局部更新文档
更新是update
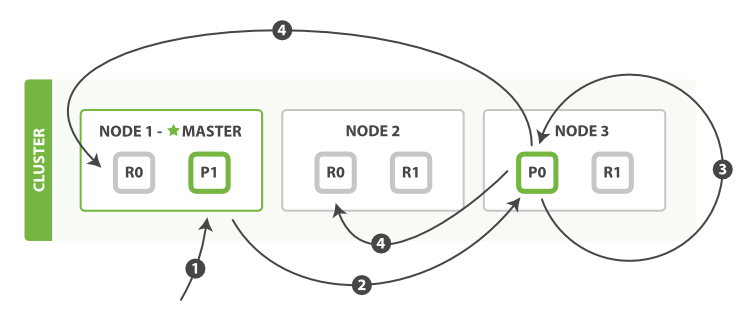
顺序步骤:
- Client给Node1发送更新请求
- Node1将转发请求到主分片所在节点Node3
- Node3从主分片检索出文档,修改
_source字段的JSON,在主分片上重建索引,如果其他进程修改了文档,会以retry_on_conflict的形式重试,都未成功则放弃 - 如果Node3更新成功,会转发新文档(这是个索引新版的请求,而不是一个更新请求)到Node1和Node2节点重建索引,当所有复制节点报告成功,Node3返回给Node1,再由Node1返回给Client
多文档模式
mget和bulk的处理和单独请求类似,差别是单独请求的时候请求节点知道每个文档所在的分片,而多文档模式不知道。
对于多文档默认,请求会被拆分为每个分片的对文档请求,然后转发每个参与的节点。
mget请求
mget请求检索多个文档的顺序步骤:
- Client向Node1发送mget请求
- Node1为每个分片构建一个多条数据检索请求,然后转发到这些请求所需的主分片或者复制分片上,当接收到所有回复,Node1构建响应返回给Client
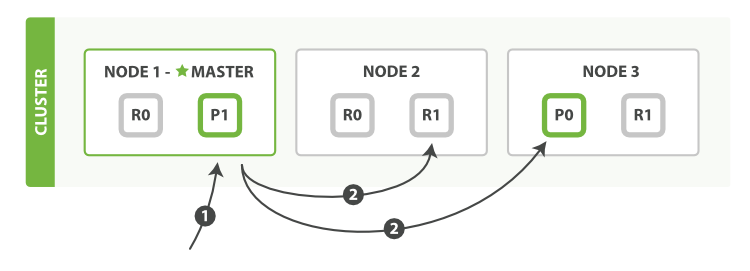
routing参数可以被docs中的每个文档设置
bulk请求
bulk执行多个create、index、delete和update请求的顺序步骤:
- Client向Node1发送bulk请求
- Node1为每个分片构建批量请求,然后转发到这些请求所需的主分片上。
- 主分片一个接一个的按序执行操作。当一个操作执行完,主分片转发新文档(或者删除部分)给对应的复制节点,然后执行下一个操作。一旦所有复制节点报告所有操作已成功完成,节点就报告success给请求节点,后者Node1整理响应并返回给Client
批量请求的格式
bulk使用换行符,而mget使用Json数组。
因为每个引用的文档属于不同的主分片,每个分片可能被分布于集群中的某个节点上,批量中的每个操作需要被转发到对应的分片和节点上
如果单独的请求被包在Json数组
- 解析Json数组
- 检查请求在那个分片
- 为每个分片创建请求数组
- 序列化数组为内部传输格式
- 发送请求到分片
但是需要大量的RAM和JVM回收,对于Es是从文件缓冲区一行一行读取数据,可以直接辨识和解析action/metadata行,然后决定哪个分片处理这个请求,然后这些行请求直接转发到对应分片,没做冗余的复制和多余的数组结构
搜索
每个文档里的字段都会被索引并被查询,并且Es可以使用所有的索引
搜索可以完成的功能
- 类似传统数据库根据字段进行结构化查询,通过字段排序
- 根据匹配关键字,进行关联性排序返回结果
- 或者结合上边的两点
空搜索
GET /_search
- hits total字段来表示匹配到的文档总数,数组还包含了匹配到的前10条数据
- took 请求耗时
- shards total字段参与查询的分片数,successful有多少成功,failed有多少失败
timeout参数可以设定查询是否超时,如果响应时间比请求结果重要可以使用这一参数
GET /_search?timeout=10ms
Es会返回请求超时前收集到的结果,但是不会终止查询
多索引和多分类
Es可以跨索引搜索
/_search在所有索引的所有类型中搜索/gb/_search在索引gd的所有类型中搜索/gb,us/_search在索引gd和us的所有类型中搜索/g*,u*/_search在索引以g或u开头的所有类型中搜索/gb/user/_search在索引gd的user类型中搜索/gb,us/user,tweet/_search在索引gb和us的类型为user和tweet中搜索/_all/user,tweet/_search在所有索引的user和tweet中搜索
分页
Elasticsearch接受from和size参数
- size: 结果数,默认10
- from: 跳过开始的结果数,默认0
每页显示5个结果,页码从1到3
GET /_search?size=5
GET /_search?size=5&from=5
GET /_search?size=5&from=10
结果在返回前会被排序的,一个搜索请求常常涉及多个分片。每个分片生成自己排好序的结果,它们接着需要集中起来排序以确保整体排序正确。
在集群系统中深度分页
假设在一个有5个主分片的索引中搜索。
当我们请求结果的第一页(结果1到10)时,每个分片产生自己最顶端10个结果然后返回它们给请求节点(requesting node),它再排序这所有的50个结果以选出顶端的10个结果。
现在假设我们请求第1000页——结果10001到10010。工作方式都相同,不同的是每个分片都必须产生顶端的10010个结果。然后请求节点排序这50050个结果并丢弃50040个!
你可以看到在分布式系统中,排序结果的花费随着分页的深入而成倍增长。这也是为什么网络搜索引擎中任何语句不能返回多于1000个结果的原因。
查询字符串
查询所有类型为tweet并在tweet字段中包含elasticsearch字符的文档
GET /_all/tweet/_search?q=tweet:elasticsearch
查找name字段中包含"john"和tweet字段包含"mary"的结果
GET /_search?q=%2Bname%3Ajohn+%2Btweet%3Amary
是指上是+name:john+tweet:mary的urlencode形式。
"+"前缀表示语句匹配条件必须被满足。类似的"-"前缀表示条件必须不被满足。所有条件如果没有+或-表示是可选的——匹配越多,相关的文档就越多。
_all字段
当索引一个文档,Es会把所有的字符串字段值连接在一起放在一个大的字符串中,创建一个字段_all
示例被索引文档
{
"tweet": "However did I manage before Elasticsearch?",
"date": "2014-09-14",
"name": "Mary Jones",
"user_id": 1
}
_all字段为"However did I manage before Elasticsearch? 2014-09-14 Mary Jones 1"
若没有指定字段,查询字符串搜索(即q=xxx)使用_all字段搜索。
更复杂的搜索
- name字段包含"mary"或"john"
- date晚于2014-09-10
- _all字段包含"aggregations"或"geo"
+name:(mary john)+date:>2014-09-10 +(aggregations geo)
编码之后就是
?q=%2Bname%3A(mary+john)+%2Bdate%3A%3E2014-09-10+%2B(aggregations+geo)
不过生产上一般不会这么用,因为搜索一些特殊字符会有问题
映射和分析
- 映射(mapping)机制用于进行字段类型确认,将每个字段匹配为一种确定的数据类型(string, number, booleans, date等)。
- 分析(analysis)机制用于进行全文文本(Full Text)的分词,以建立供搜索用的反向索引。
数据类型的差异
在索引中有12个tweets都有2014-09-15内容,但是其中一个是日期2014-09-15
GET /_search?q=2014 # 12 个结果
GET /_search?q=2014-09-15 # 还是 12 个结果 !
GET /_search?q=date:2014-09-15 # 1 一个结果
GET /_search?q=date:2014 # 0 个结果 !
针对date字段进行年度查询一个都没有返回,数据在_all字段的索引方式和在date字段的索引方式不同
获取文档结构
GET /gb/_mapping/tweet
响应结果
{
"gb": {
"mappings": {
"tweet": {
"properties": {
"date": {
"type": "date",
"format": "dateOptionalTime"
},
"name": {
"type": "string"
},
"tweet": {
"type": "string"
},
"user_id": {
"type": "long"
}
}
}
}
}
}
Es会根据字段类型进行猜测,动态的生成了字段和类型的映射关系,date类型的字段和string类型的字段的索引方式是不同的,因此导致查询结果的不同。
确切值和全文文本
Es中的数据分为确切值和全文文本
- 确切值是确定的,"Foo"和"foo"就并不相同。确切值2014和2014-09-15也不相同
- 全文文本是文本化的数据
May is fun but June bores me.
这个May是月份还是人名呢?
对于确切值,是很容易查询的,因为结果是二进制的,只有匹配和不匹配,而对于全文数据,会有文档和查询的匹配程度如何
- 一个针对"UK"的查询将返回涉及"United Kingdom"的文档
- 一个针对"jump"的查询同时能够匹配"jumped", "jumps", "jumping"甚至"leap"
- "johnny walker"也能匹配"Johnnie Walker", "johnnie depp"及"Johnny Depp"
- "fox news hunting"能返回有关hunting on Fox News的故事,而"fox hunting news"也能返回关于fox hunting的新闻故事。
为了方便在全文文本字段中进行这些类型的查询,Elasticsearch首先对文本分析(analyzes),然后使用结果建立一个倒排索引。
倒排索引
Elasticsearch使用一种叫做倒排索引(inverted index)的结构来做快速的全文搜索。倒排索引由在文档中出现的唯一的单词列表,以及对于每个单词在文档中的位置组成。
例如,我们有两个文档,每个文档content字段包含
- The quick brown fox jumped over the lazy dog
- Quick brown foxes leap over lazy dogs in summer
首先切分每个文档的content字段为单独的单词,把所有的唯一词放入列表并排序,结果是这个样子的
| Term | Doc_1 |
Doc_2 |
|---|---|---|
| Quick | X | |
| The | X | |
| brown | x | X |
| dog | x | |
| dogs | X | |
| fox | x | |
| foxes | X | |
| in | X | |
| jumped | x | |
| lazy | x | X |
| leap | X | |
| over | x | X |
| quick | x | |
| summer | X | |
| the | x |
如果我们想搜索"quick brown",我们只需要找到每个词在哪个文档中出现即可
| Term | Doc_1 |
Doc_2 |
|---|---|---|
| brown | x | x |
| quick | x | |
| Total | 2 | 1 |
两个文档都匹配,但是第一个比第二个有更多的匹配项。使用简单的相似度算法(similarity algorithm),计算匹配单词的数目,第一个文档比第二个匹配度更高——对于我们的查询具有更多相关性
但是还是会有问题
- "Quick"和"quick"被认为是不同的单词,但是用户可能认为它们是相同的。
- "fox"和"foxes"很相似,就像"dog"和"dogs"——它们都是同根词。
- "jumped"和"leap"不是同根词,但意思相似——它们是同义词。
搜索"+Quick +fox"不会匹配任何文档,因为+标识必须匹配到,而只有"Quick"和"fox"都在同一文档中才可以匹配查询,第一个文档包含"quick fox"且第二个文档包含"Quick foxes"。
如果我们将词为统一为标准格式,这样就可以找到不是确切匹配查询,但是足以相似从而可以关联的文档。例如:
- "Quick"可以转为小写成为"quick"。
- "foxes"可以被转为根形式"fox"。同理"dogs"可以被转为"dog"。
- "jumped"和"leap"同义就可以只索引为单个词"jump"
之后索引就变为了
| Term | Doc_1 |
Doc_2 |
|---|---|---|
| brown | X | X |
| dog | X | X |
| fox | X | X |
| in | X | |
| jump | X | X |
| lazy | X | X |
| over | X | X |
| quick | X | X |
| summer | X | |
| the | X | X |
查询将变成"+quick +fox",这样就可以匹配到两个文档。
索引文本和查询字符串都要标准化为相同的形式,这个标记化和标准化的过程叫做分词(analysis)
分析和分析器
分析(analysis)是这样一个过程:
- 标记化一个文本块为适用于倒排索引单独的词(term)
- 然后标准化这些词为标准形式,提高它们的“可搜索性”或“查全率”
字符过滤器
首先字符串经过字符过滤器(character filter),它们的工作是在标记化前处理字符串。字符过滤器能够去除HTML标记,或者转换"&"为"and"。
分词器
分词器(tokenizer)被标记化成独立的词。一个简单的分词器(tokenizer)可以根据空格或逗号将单词分开,在中文中并不是适用
标记过滤
最后,每个词都通过所有标记过滤(token filters),它可以修改词(例如将"Quick"转为小写),去掉词(例如停用词像"a"、"and"、"the"等等),或者增加词(例如同义词像"jump"和"leap")
Elasticsearch提供很多开箱即用的字符过滤器,分词器和标记过滤器。这些可以组合来创建自定义的分析器以应对不同的需求。
内建的分析器
Elasticsearch还附带了一些预装的分析器,你可以直接使用它们。
示例处理以下语句
"Set the shape to semi-transparent by calling set_trans(5)"
标准分析器
标准分析器是Elasticsearch默认使用的分析器。对于文本分析,它对于任何语言都是最佳选择(译者注:就是没啥特殊需求,对于任何一个国家的语言,这个分析器就够用了)。它根据Unicode Consortium的定义的单词边界(word boundaries)来切分文本,然后去掉大部分标点符号。最后,把所有词转为小写。产生的结果为:
set, the, shape, to, semi, transparent, by, calling, set_trans, 5
简单分析器
简单分析器将非单个字母的文本切分,然后把每个词转为小写。产生的结果为:
set, the, shape, to, semi, transparent, by, calling, set, trans
空格分析器
空格分析器依据空格切分文本。它不转换小写。产生结果为:
Set, the, shape, to, semi-transparent, by, calling, set_trans(5)
语言分析器
特定语言分析器适用于很多语言。它们能够考虑到特定语言的特性。例如,english分析器自带一套英语停用词库——像and或the这些与语义无关的通用词。这些词被移除后,因为语法规则的存在,英语单词的主体含义依旧能被理解(译者注:stem English words这句不知道该如何翻译,查了字典,我理解的大概意思应该是将英语语句比作一株植物,去掉无用的枝叶,主干依旧存在,停用词好比枝叶,存在与否并不影响对这句话的理解。)。
english分析器将会产生以下结果:
set, shape, semi, transpar, call, set_tran, 5
注意"transparent"、"calling"和"set_trans"是如何转为词干的。
当分析器被使用
当我们索引(index)一个文档,全文字段会被分析为单独的词来创建倒排索引。不过,当我们在全文字段搜索(search)时,我们要让查询字符串经过同样的分析流程处理,以确保这些词在索引中存在。
全文查询我们将在稍后讨论,理解每个字段是如何定义的,这样才可以让它们做正确的事:
- 当你查询全文(full text)字段,查询将使用相同的分析器来分析查询字符串,以产生正确的词列表。
- 当你查询一个确切值(exact value)字段,查询将不分析查询字符串,但是你可以自己指定。
现在你可以明白为什么《映射和分析》的开头会产生那种结果:
date字段包含一个确切值:单独的一个词"2014-09-15"。 _all字段是一个全文字段,所以分析过程将日期转为三个词:"2014"、"09"和"15"。 当我们在_all字段查询2014,它一个匹配到12条推文,因为这些推文都包含词2014:
GET /_search?q=2014 # 12 results
当我们在_all字段中查询2014-09-15,首先分析查询字符串,产生匹配任一词2014、09或15的查询语句,它依旧匹配12个推文,因为它们都包含词2014。
GET /_search?q=2014-09-15 # 12 results !
当我们在date字段中查询2014-09-15,它查询一个确切的日期,然后只找到一条推文:
GET /_search?q=date:2014-09-15 # 1 result
当我们在date字段中查询2014,没有找到文档,因为没有文档包含那个确切的日期:
GET /_search?q=date:2014 # 0 results !
测试分析器
尤其当你是Elasticsearch新手时,对于如何分词以及存储到索引中理解起来比较困难。为了更好的理解如何进行,你可以使用analyze API来查看文本是如何被分析的。在查询字符串参数中指定要使用的分析器,被分析的文本做为请求体:
GET /_analyze?analyzer=standard&text=Text to analyze
结果中每个节点在代表一个词:
{
"tokens": [
{
"token": "text",
"start_offset": 0,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "to",
"start_offset": 5,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "analyze",
"start_offset": 8,
"end_offset": 15,
"type": "<ALPHANUM>",
"position": 3
}
]
}
token是一个实际被存储在索引中的词。position指明词在原文本中是第几个出现的。start_offset和end_offset表示词在原文本中占据的位置。
analyze API 对于理解Elasticsearch索引的内在细节是个非常有用的工具,随着内容的推进,我们将继续讨论它。
指定分析器
当Elasticsearch在你的文档中探测到一个新的字符串字段,它将自动设置它为全文string字段并用standard分析器分析。
你不可能总是想要这样做。也许你想使用一个更适合这个数据的语言分析器。或者,你只想把字符串字段当作一个普通的字段——不做任何分析,只存储确切值,就像字符串类型的用户ID或者内部状态字段或者标签。
为了达到这种效果,我们必须通过映射(mapping)人工设置这些字段。
映射
字段类型
Es使用映射(mapping)存储类型和字段的信息,每个索引都有一个类型(type),每个类型有自己的mapping或者(shema dafinition)
包含string, byte, short, integer, long, float, double, boolean, date基本字段
如果索引中没有对应的字段,Es会根据JSON的基本数据类型动态匹配规则猜测字段类型
| JSON type | Field type |
|---|---|
| Boolean: true or false | "boolean" |
| Whole number: 123 | "long" |
| Floating point: 123.45 | "double" |
| String, valid date: "2014-09-15" | "date" |
| String: "foo bar" | "string" |
"123"将被映射为"string"类型,而不是"long"类型。然而,如果字段已经被映射为"long"类型,Elasticsearch将尝试转换字符串为long,并在转换失败时会抛出异常。
查看映射
使用_mapping后缀来查看Elasticsearch中的映射
GET /gb/_mapping/tweet
响应结果
{
"gb": {
"mappings": {
"tweet": {
"properties": {
"date": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
},
"name": {
"type": "string"
},
"tweet": {
"type": "string"
},
"user_id": {
"type": "long"
}
}
}
}
}
}
自定义字段映射
映射中最重要的字段参数是type
{
"number_of_clicks": {
"type": "integer"
}
}
需要注意的点
- 区分全文(full text)字符串字段和准确字符串字段(译者注:就是分词与不分词,全文的一般要分词,准确的就不需要分词,比如『中国』这个词。全文会分成『中』和『国』,但作为一个国家标识的时候我们是不需要分词的,所以它就应该是一个准确的字符串字段)。
- 使用特定语言的分析器(译者注:例如中文、英文、阿拉伯语,不同文字的断字、断词方式的差异)
- 优化部分匹配字段
- 指定自定义日期格式(译者注:这个比较好理解,例如英文的 Feb,12,2016 和 中文的 2016年2月12日)
index字段
- analyzed 首先分析这个字符串,然后索引。换言之,以全文形式索引此字段。
- not_analyzed 索引这个字段,使之可以被搜索,但是索引内容和指定值一样。不分析此字段。
- no 不索引这个字段。这个字段不能为搜索到。
其他简单类型(long、double、date等等)也接受index参数,但相应的值只能是no和not_analyzed,它们的值不能被分析。
分析
对于analyzed类型的字符串字段,使用analyzer参数来指定哪一种分析器将在搜索和索引的时候使用。默认的,Elasticsearch使用standard分析器,但是你可以通过指定一个内建的分析器来更改它,例如whitespace、simple或english。
{
"tweet": {
"type": "string",
"analyzer": "english"
}
}
更新映射
可以在第一次创建索引的时候指定映射的类型或者对新的字段增加映射,但是不能对已有字段进行
DELETE /gb
PUT /gb
{
"mappings": {
"tweet" : {
"properties" : {
"tweet" : {
"type" : "string",
"analyzer": "english"
},
"date" : {
"type" : "date"
},
"name" : {
"type" : "string"
},
"user_id" : {
"type" : "long"
}
}
}
}
}
在tweet的映射中增加一个新的not_analyzed类型的文本字段,叫做tag
PUT /gb/_mapping/tweet
{
"properties" : {
"tag" : {
"type" : "string",
"index": "not_analyzed"
}
}
}
新字段已经被合并至存在的那个映射中
测试映射
可以通过名字使用analyze API测试字符串字段的映射。对比这两个请求的输出
GET /gb/_analyze?field=tweet&text=Black-cats
和
GET /gb/_analyze?field=tag&text=Black-cats
tweet字段产生两个词,"black"和"cat",tag字段产生单独的一个词"Black-cats"。换言之,我们的映射工作正常。
复合核心字段类型
除了符合标量类型,Json还有null值,数组和对象
多值字段
索引一个标签数组来代替单一字符串
{ "tag": [ "search", "nosql" ]}
- 对于数组不需要特殊的映射。任何一个字段可以包含零个、一个或多个值,同样对于全文字段将被分析并产生多个词。
- 并且数组中所有值必须为同一类型。
- 数组是做为多值字段被索引的,它们没有顺序。在搜索阶段你不能指定“第一个值”或者“最后一个值”。倒不如把数组当作一个值集合(bag of values)
空字段
数组可以是空的。这等价于有零个值
事实上,Lucene没法存放null值,所以一个null值的字段被认为是空字段。
"empty_string": "",
"null_value": null,
"empty_array": [],
"array_with_null_value": [ null ]
以上四个字段都被识别为空字段而不被索引
多层对象
一个自然JSON数据类型是对象(object)
内部对象(inner objects)经常用于在另一个对象中嵌入一个实体或对象。例如,做为在tweet文档中user_name和user_id的替代,我们可以这样写
{
"tweet": "Elasticsearch is very flexible",
"user": {
"id": "@johnsmith",
"gender": "male",
"age": 26,
"name": {
"full": "John Smith",
"first": "John",
"last": "Smith"
}
}
}
内部对象的映射
{
"gb": {
"tweet": {
"properties": {
"tweet": { "type": "string" },
"user": {
"type": "object",
"properties": {
"id": { "type": "string" },
"gender": { "type": "string" },
"age": { "type": "long" },
"name": {
"type": "object",
"properties": {
"full": { "type": "string" },
"first": { "type": "string" },
"last": { "type": "string" }
}
}
}
}
}
}
}
}
上述对应的映射
内部对象是怎样被索引的
Lucene并不了解内部对象
对应的扁平化为key-value的形式
{
"tweet": [elasticsearch, flexible, very],
"user.id": [@johnsmith],
"user.gender": [male],
"user.age": [26],
"user.name.full": [john, smith],
"user.name.first": [john],
"user.name.last": [smith]
}
在以上扁平化文件中,并没有栏位叫作user也没有栏位叫作user.name。 Lucene 只索引阶层或简单的值,而不会索引复杂的资料结构
内部对象数组
{
"followers": [
{ "age": 35, "name": "Mary White"},
{ "age": 26, "name": "Alex Jones"},
{ "age": 19, "name": "Lisa Smith"}
]
}
扁平化之后为
{
"followers.age": [19, 26, 35],
"followers.name": [alex, jones, lisa, smith, mary, white]
}
这样{age: 35}与{name: Mary White}的关联关系就会取消,而为了解决这种情况需要使用嵌套对象。

