

HTTP权威指南阅读笔记 第四部分 实体,编码和国际化(第十五章到第十七章)
目录:
15 实体和编码
15.1 报文是箱子,实体是货物
简单的实体,封装在HTTP响应报文
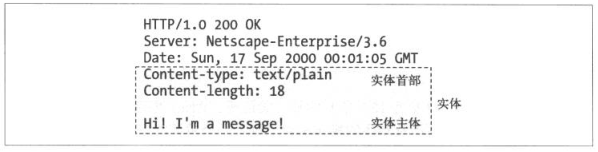
实体首部指出这是一个纯文档(Content-Type: text/plain),它只有18个字节长(Content-Length: 18),一个空白行(CRLF)把首部字段和主体部分分割开来。
HTTP/1.1定义了10个基本首部
- Content-Type 实体对象类型
- Content-Length 实体主体的长度和大小
- Content-Language 对象的语言
- Content-Encoding 对象数据所作的任意变换(例如压缩)
- Content-Location 一个备用位置,请求时可以通过它获得对象
- Content-Range 如果是部分实体,用于声明是整体的那个位置
- Content-MD5 实体主体内容的校验和
- Last-Modified 实体在服务器上创建和最后修改时间
- Expires 实体数据的失效时间
- Allow 该资源所允许的各种方法,例如GET和HEAD
- Etag 实体的唯一验证码
- Cache-Control 如何缓存实体
实体主体就是原始数据,实体首部就是用来描述数据。首部字段以一个空白的CRLF行结束,最后就是实体主体
15.2 Control-Length: 实体的大小
15.2.1 检测截尾
Client需要区分报文是否传递完成,来关闭连接
15.2.2 错误的Content-Length
错误的Content-Length比缺少Content-Length还要糟,
15.2.3 Content-Length与持久连接
Client通过Content-Length首部来判断报文的结束,和下一条报文的开始,但是持续连接,Client无法依赖连接关闭而判断报文结束
15.2.4 内容编码
HTTP允许对实体主体进行编码,例如可以进行压缩,Control-Length是编码后的长度
15.2.5 确定实体长度的规则
- 报文中如果没有主体,就没有Control-Length首部,当然HEAD请求等价与GET请求,但是不会返回实体主体,实体首部是会返回的,1XX,204以及304响应也可以有Control-Length首部,但是没有实体主体
- 如果报文中包含描述传输编码的Transfer-Encoding首部(不采用默认的HTTP恒等编码),那么实体就是由一个称为零字节块的特殊模式结束
- 如果报文有主体,没有非恒等的Transfer-Encoding首部,Control-Length就是实体主体的长度
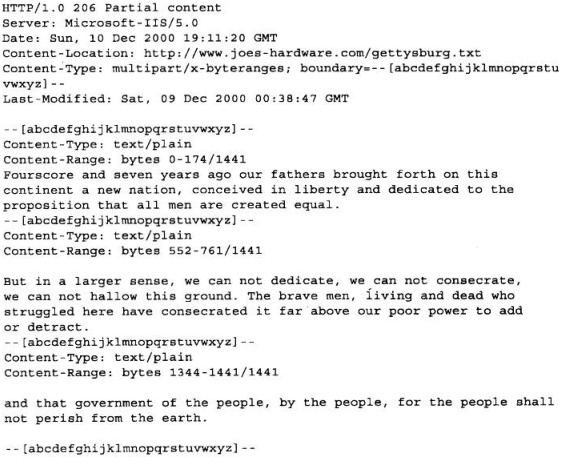
- 如果报文使用了multipart/byteranges(多部分/字节范围)媒体类型,并且没有用Control-length首部指出实际主体的长度,那么多部分报文中的每个部分都要说明其大小
- 如果上边的规则都不匹配,实体在连接关闭时结束
15.3 实体摘要
Control-MD5首部是经过内容编码而没有经过传输编码的主体
缓存和中间代理不添加或修改Content-MD5首部首部
为了验证报文,Client需要对传输编码进行解码,然后获得了未进行传输编码的实体主体
15.4 媒体类型和字符集
Content-Type首部字段说明了主体的MIME类型,是进行编码之前的类型,Client通过MIME类型来解释和处理内容
15.4.1 文本的字符编码
Control-Type: text/html; charset=iso-8859-4
charset字符集参数,作为Control-Type的可选参数,可以进一步说明内容类型
15.4.2 多部分媒体类型
MIME中multipart(多部分)电子邮件报文中包含多个报文,合在一起作为单一的复杂报文发送,每一部分都是独立的,有各自的描述其内容集,不同的部分之间用分界字符串连接在一起。
HTTP也支持多部分主体,通常用在:
- 提交填写好的表格
- 作为承载若干文档片段的响应范围
15.4.3 多部分表格提交
当提交HTTP表格时,变长的文本字段和上传对象都作为多部分主体里面独立的部分发送,这样表格就能填写不同类型和长度的值。
HTTP使用Content-Type: multipart/form-data或Content-Type: multipart/mixed这样的首部和多部分主体来发送这种请求
Control-Type: multipart/form-data; boundary=[abcdefghijklmnopqrstuvwxyz]
boundary参数说明了分割主体使用的不同字符串
<form action="http://server.com/cgi/handle" enctype="multipart/form-data" method="post">
<p>
What is your name?
<input type="text" name="submit-name"><br>
What files are you sending?
<input type="file" name="files"><br>
<input type="submit" value="Send">
如果用户在文本输入中输入Why,并选择了文本文件essayfile.txt
Content-Type: multipart/form-data; boundary=AaB03x
--AaB03x
Content-Disposition: form-data; name="submit-name"
Why
--AaB03x
Content-Disposition: form-data; name="file"; filename="essayfile.txt"
Content-Type: text/plain
...contents of essayfile.txt...
--AaB03x--
15.4.4 多部分范围响应
HTTP对范围请求也可以是多部分的,这样响应中有Content-Type: multipart/byteranges首部和带有不同范围的多部分主体
15.5 内容编码
HTTP应用程序需要在发送数据之前对内容进行编码,例如压缩,可以减少传输时间和带宽,或者内容加密等等
15.5.1 内容编码过程
- 生成原始响应报文,其中包括Content-Type和Content-Length首部
- 内容编码,在报文中添加Content-Encoding首部,和内容编码完的数据
15.5.2 内容编码类型
HTTP定义了一些标准的内容编码类型,并允许扩展编码的形式增添编码
常用内容编码代号
- gzip 表明实体采用GNU zip编码
- compress 表明实体采用Unix文件压缩程序
- deflate 表明实体采用zlib的格式进行压缩
- identity 表明没有对实体进行编码,没有Content-Encoding首部默认为这种情况
15.5.3 Accept-Encoding首部
为了防止Server使用了Client不支持,Client可以把自己支持的内容编码方式列表放到Accept-Encoding首部发送出去,如果没有该首部,Server认为Client可以接受任何编码方式(等价于Accept-Encoding: *)
Accept-Encoding: *
Accept-Encoding: gzip, compress
Accept-Encoding: gzip; q=1, compress; q=0.5, *; q=0
每种编码附带的Q质量值参数说明编码的优先级,范围从0.0到1.0,1.0表明最希望的编码
15.6 传输编码和分块编码
传输编码的作用也是在实体上做可逆变换,使用传输编码改变的是报文在数据网络上的传输方式

15.6.1 可靠传输
在其他协议中会有传输编码来保证报文经过网络时的可靠传输,但是在http协议中,底层传输设施已经标准并且容错性好,只有一些少数情况,传输的报文主体会引发问题
- 未知的尺寸
- 安全性
15.6.2 Transfer-Encoding首部
HTTP协议定义了两个首部描述和控制传输编码
- Transfer-Encoding 告知接收方为了可靠地传输报文,对其进行了何种编码
- TE 用在请求首部,告知Server可以用那些传输编码进行扩展
示例请求首部
TE: trailers, chunked
另外TE也可以用Q来声明优先级
示例响应
Transfer-Encoding: chunked
在这个首部之后,报文结构会发生改变
15.6.3 分块编码
分块编码把报文分割为若干个大小已知的块,块是紧挨着发送的,也就不需要知道整个报文的大小了
分块编码是一种传输编码,因此是报文的属性,而不是主体属性

15.6.4 内容编码和传输编码的结合
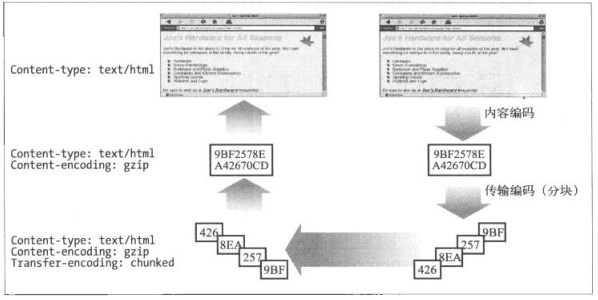
15.6.5 传输编码的规则
- 传输编码集合中必须包含分块
- 最后作用于报文主体
- 分块传输编码不能多次作用到一个报文主体上
如果传输的服务器无法理解经过的传输编码报文,应该返回501 Unimplemented
15.7 随时间变化的实例
略
15.8 验证码和新鲜度
略,参考第二部分的缓存
15.9 范围请求
HTTP允许请求文档的一部分,可能我们请求了一般的数据,而因为网络原因连接中断,如果从新下载可能要消耗更多的时间。HTTP可以通过请求曾经获取失败的实体的一个范围,来就恢复下载该实体,但是有一个嵌套,就是该对象没有改变过
Range: bytes=4000-
示例是请求文档开头4000字节之后的部分
Server也可以通过Accept-Ranges首部说明支持范围请求
Accept-Ranges: bytes
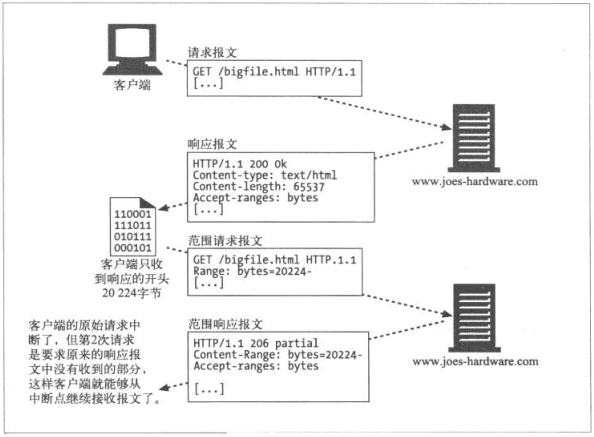
Range首部广泛应用于点对点(P2P)
15.10 差异编码
Web页面会进行更新,如果Client有一个已经过期的副本,就要请求页面的最新页面,这样就需要再次获得完成的页面
如果改动比较小,Server其实可以只发送改变的部分,这样就可以更快的获得最新的页面。
差异编码是HTTP协议的一个扩展,通过交换对象的改变部分而不是完整对象来优化传输性能
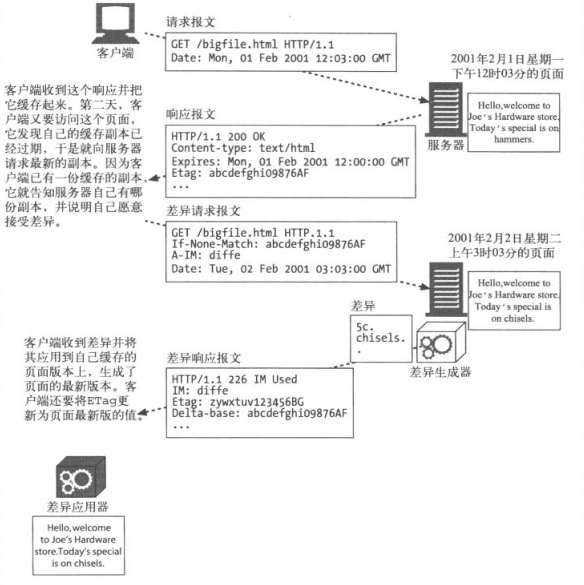
- Client需要告知Server,它有页面的哪个版本,If-None-Match首部中使用的是页面版本的唯一标识,这个值是当时Server发送的Etag, 并且愿意接受差异,使用发送A-IM首部证明愿意接收差异,懂得那些差异应用于现有版本的算法(实例操作类型)。
- Server要是否有这个页面的Client版本,才能计算Client现有版本和最新版本的差异,发送给Client,并说明发送的为差异内容,最新版本页面的Etag,状态码为
226 IM Used,IM首部用于说明差异性算法。
实例操作类型
- vcdiff 用vcdiff算法计算差异
- diffe Unix系统的diff-e命令计算差异
- gdiff 用gdiff算法计算差异
- gzip 用gzip算法压缩
- deflact 用deflact算法压缩
- range 在Server响应中,说明响应时范围选择得到
- indentity 用在Client请求,说明愿意接收恒等实例操作
vdiff可以对二进制进行操作,而diffe不行
由于差异的问题,必须保留原来的版本,进而增加磁盘
16 国际化
国际化的主要问题是字符集编码和语言标记
16.1 HTTP对国际性内容的支持
HTTP报文中可以承载任何语言的内容,甚至是二进制,但是Server需要让不同的Client根据自己的语言和字母表进行转换,将文档中的信息解包为字符内容呈现
- Server通过Content-Type首部的charset和Content-Language首部告知Client文档的字母表和语言
- Client需要Accept-CharSet首部和Accept-Language首部告知Server,理解的字符集编码算法和语言以及其中的优先顺序
Accept-Language: fr, en; q=0.8
Accept-CharSet: iso-8859-1, utf-8
说明Client需要法语和英语,Client支持iso-8859-1西欧字符, utf-8,Q还是质量因子,默认为1.0
16.2 字符集和HTTP
16.2.1 字符集是把字符转换为二进制码的编码
HTTP字符集的值是说明如何把实体内容的二进制码转换为特定字母表中的字符。每个字符集都包含了一种把二进制编码转换为字符的算法
Content-Type: text/html; charset=iso-8859-6
响应首部告知使用iso-8859-6阿拉伯字符集的解码算法将二进制转换为字符
16.2.2 字符集和编码如何工作
- 将二进制码转化为字符代码,代表特定编码字符集中某个特定标号的字符
- 字符代码从编码的字符集中选择特定的元素
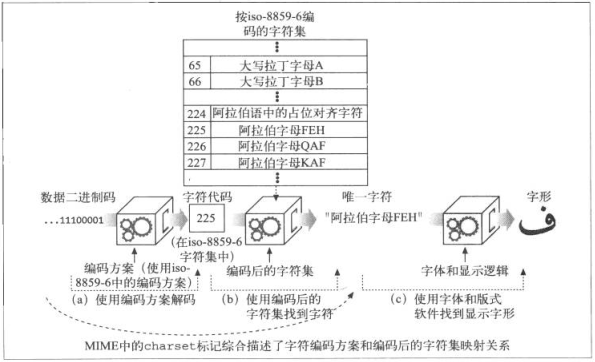
16.2.3 字符集不对,字符就不对
对于同一二进制不同字符集获取的字符会不一样
16.2.4 标准化的MIME charset值
略
16.2.5 Content-Type首部和Charset首部以及META标志
对于没有首部表明字符集的,接收方可能需要从文档内容获取字符集
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=iso-2202-jp">
16.2.6 Accept-Charset首部
略
16.3 多语言字符编码入门
略
16.4 语言标记与HTTP
16.4.1 Content-Language首部
略
16.4.2 Accept-Language首部
略
16.4.3 语言标记类型
- 一般的语言分类(es代表西班牙语)
- 特定国家的语言(en-GB代表英国英语)
- 语言的方言(no-bok指挪威的书面语)
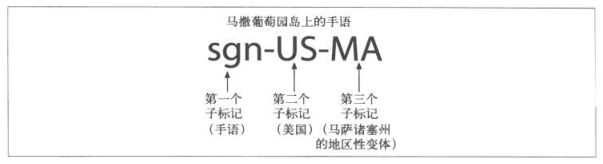
- 地区性语言(sgn-US-MA代表美国马撒葡萄园岛上的手语)
- 标准化的非变种语言(i-navajo)
- 非标准的语言(x-snowboarder-slang)
16.4.4 子标记
- 第一个子标记称为主子标记,其值是标准化的
- 第二个字标记是可选的,遵循自己的命名标准
- 其他尾随的子标记都是未注册的
16.4.5 大小写
标记不区分大小写
16.4.6 IANA语言标记注册
略
16.4.7 第一个子标记——名字空间
略
16.4.8 第二个子标记——名字空间
略
16.4.9 其余子标记——名字空间
略
16.5 国际化的URL
URI如今还是由US-ASCII字符的一个子集组成
16.5.1 全球性的可转抄能力与有意义的字符集的较量
略
16.5.2 URI字符合集
URI中允许出现的US-ASCII字符的子集可以被分为保留,未保留以及转义字符
- 未保留
[A-Za-z0-9]|"-"|"_"|"."|"!"|"~"|"*"|"'"|("|") - 保留
";"|"/"|"?"|":"|"@"|"&"|"="|"$"|"," - 转义
"%"<HEX><HEX>
16.5.3 转义与反转义
URI转义提供了一种安全的方法,可以在URI内部插入保留字符以及原本不支持的字符(比如空白字符),每个转义字符是一组三个字符序列,由"%"后边跟两个十六进制数字的字符,这两个十六进制数数字代表一个US-ASCII字符的代码
%20就是32的16进制的标识,代表一个空白字符
在内部处理时,HTTP在传输和转发URI的时候保持转义不变,尽在需要数据的时候进行转义,并且确保不会被转义两次或反转义两次
16.5.4 转义国际化字符
对于US-ASCII,只有(0~127有字符),扩展的字符范围在(128~255)的会产生错误的
16.5.5 URI的模态转换
略
16.6 其他需要考虑的问题
16.6.1 首部和不合规范的数据
略,参考转义国际化字符
16.6.2 日期
略
16.6.3 域名
略
17 内容协商与转码
17.1 内容协商技术
| 技术 | 工作原理 | 优点 | 缺点 |
|---|---|---|---|
| Client驱动 | Client发起请求,Server发送可选择列表,Client进行选择 | 在Server端实现容易 | 增加时延,为了获得正确内容,至少发送两次请求 |
| Server驱动 | Server检查Client请求首部并觉定返回那个版本页面 | 比Client端实现快 | 如果首部中的需求的Server端没有就需要Server猜测并发送数据 |
| 透明 | 有个中间代理等进行协商 | 免除Server端协商的开销和Client驱动的协商要快 | 没有透明协商的正式规范 |
17.2 客户端驱动的协商
Server在收到Client请求,回应的过程中列出可用页面,让Client决定要哪个。
列出可用页面有两种方法
- 发送回一个HTML文档,里面该页面的各种版本的链接和版本信息,Client收到这种响应会显示一个带有链接的页面
- 使用300 Multiple Choices响应代码,Client会弹出弹窗由用户选择
17.3 服务端驱动的协商
- 检查内容协商首部集,Server查看Client发送的Accept首部集,设法有与之匹配的响应首部匹配
- 根据其他非协商内容进行变通,例如User-agent
17.3.1 内容协商首部集
- Accept 告诉Server发送何种媒体类型,对应相应首部Connet-Type
- Accept-Language 告知Server发送何种语言,对应相应首部Connet-Language
- Accept-Charset 告知Server发送何种字符集,对应相应首部Connet-Type
- Accept-Encoding 告知Server发送何种编码,对应相应首部Connet-Encoding
17.3.2 内容协商首部中的质量值
略
17.3.3
略
17.3.4 Apache中的内容协商
略
17.3.5 服务端扩展
略
17.4 透明协商
透明协商目的是去除Server驱动时Server的负载,并通过代理代表Server与Client的报文进行报文交换最小化。
为了支持透明代理,Server需要告知Proxy需要检查哪些首部,以便Client进行匹配,通过Vary首部告知。
17.4.1 进行缓存和备用候选
对内容进行缓存是假设内容以后还可以重用。为了确保对Client请求的回送是正确的已缓存响应,Cache必须应用Server在回送响应时所用到的大部分决策逻辑
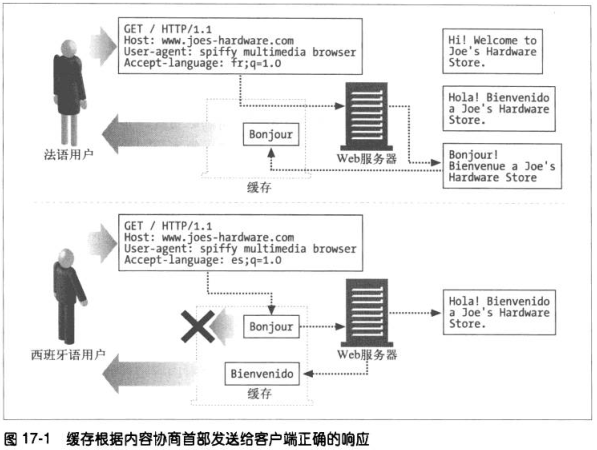
- Cache在获取第一个请求转发到Server,并存储其响应。
- 对第二个请求,Cache根据URL找到匹配的文档,但是是法语的,而Client需求的是西班牙语,就也将请求发给Server并保存响应,这个响应就是候选响应或者变体
17.4.2 Vary首部
协商可以是根据其他规则,可以是Vary首部的内容
17.5 转码
可以让Client从某个URL的系列文档中获取最合适Client的文档,实现的前提是,存在一些满足Client的文档。
如果Server不能满足Client需求的文档,Server可以给出一个错误响应,但是理论上,Server可以将现存文档转换为某种Client可以用的文档,被称为转码
| 转换之前 | 转换之后 |
|---|---|
| HTML文档 | WML文档 |
| 高分辨率图像 | 低分辨率图像 |
| 彩色图像 | 黑白图像 |
| 多个框架的复杂页面 | 没有框架的简单页面 |
17.5.1 格式转换
将数据格式转换,使其可以被Client查看,例如HTML转换为WML,无线设备就可以反问通常需要提供桌面客户端查看的文档等等
17.5.2 信息综合
根据小节标题生成文档大纲,或者从页面删除广告和商标
17.5.3 内容注入
自动生成广告,用户追踪
17.5.4 转码与静态预生成的对比
略

