

HTTP权威指南阅读笔记 第二部分HTTP结构(第五章到第十章)
目录:
5. Web服务器
5.1 各种形状和尺寸的Web服务器
5.1.1~5.1.4 省略
5.2 最小的Per Web服务器
省略
5.3 实际的Web服务器会做什么
- 建立连接:接收Client端的连接,或者如果不希望与Client连接则关闭
- 接收请求:从网络中读取HTTP的请求报文
- 处理请求:对请求报文进行解析,并采取行动
- 访问资源:访问报文中指定的资源
- 构建响应:创建带有正确首部的HTTP响应报文
- 发送响应:将响应回送给客户端
- 记录处理事务过程:将与已完成事务有关的内容记录到一个日志文件
5.4 第一步——接收客户端连接
如果Client已经打开了持久化连接,可以继续使用这条连接,如果没有就重新建立
5.4.1 处理新的请求
Client请求建立TCP连接的时候,Web服务器会建立连接,将ClientIP地址解析出来。
Web服务器可以拒绝和关闭任意一条连接。
5.4.2 客户端主机名识别
可以用反向DNS来对Web服务器进行配置,将ClientIP地址转换为主机名,但是事务的处理速度会降低。
5.4.3 通过ident确定客户端用户
Web服务器可以支持IETE的ident协议,获取发起HTTP请求的用户
不过有很多原因不能很好的工作
- 防火墙不允许ident流量进入
- ident协议不安全
- ident不支持虚拟IP
- ident协议使HTTP事务时延变大
- 客户端PC不支持ident协议
- 暴露客户端用户名
5.5 第二步——接收请求报文
当连接上有数据到达时,web服务器从网络中读取数据,并将请求中的报文内容解析出来
- 解析时会查找请求方法,指定资源标识符以及版本号,各项之间由一个空格分隔,并以一个CRLE回车换行序列作为行的结束。
- 读取以CRLE结尾的报文首部
- 检测到以CRLE结尾的标识首部结束的空行
- 读取请求主体
因为网络传输的时延问题,部分报文临时存储在内存中,直到收到足够进行解析的数据。
5.5.1 报文内部表示法
用便于报文操作的内部结构来存储请求报文
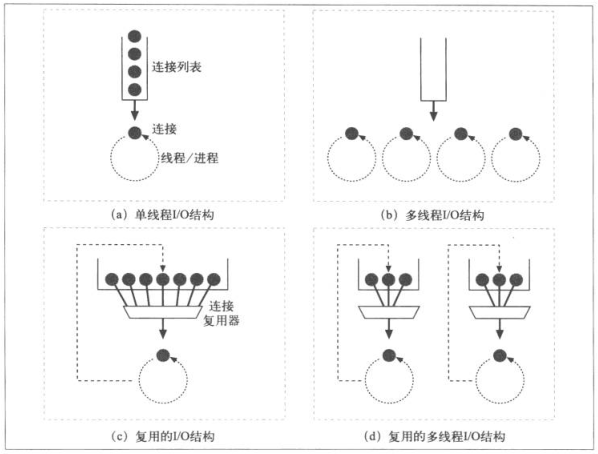
5.5.2 连接的输入/输出结构
- 单线程服务器 一次只处理一个请求,直到其请求完成为止,一个事务结束后,才会去处理下一条连接,这样会有严重的性能问题
- 多进程或者多线程服务器 根据需要或者事先创建一些线程和进程
- 复用I/O服务器 很多web服务器都采用复用结构,监视连接上的活动,当连接状态发生变化,就对连接进行处理,在处理完成后将连接返回开始连接列表中等待下次状态变化,对于空闲的连接上是不会绑定进程的
- 复用多线程Web服务器 结合多线程和复用功能,多个线程都在观察打开的连接
5.6 第三步——请求处理
根据方法,资源,首部和可选主体部分进行处理
5.7 第四步——对资源映射及访问
在web服务器将内容返回给客户端之前,将对请求报文中的URI映射为Web服务器上适当的内容或者内容生成器,识别出内容的源头
5.7.1 docroot
web内容的根目录,document root目录
服务器从请求报文中获取URI并将其附加在文档根目录后边,然后去查找资源返回给用户
一般web服务器不会允许/../这种情况,让URL推到docroot之外,将文件系统的其余部分暴露出来。
5.7.1.1 虚拟托管的docroot
web服务器会根据URL或者HOST,IP地址等识别正确的docroot,所以同样的URL由于HOST或IP不同也可能有不同的结果
5.7.1.2 用户主目录docroot
提供私人站点,以/~开始跟着用户名的URI映射为此用户的私有文档根目录
说实话工作两年没见过这个东西。
5.7.2 目录列表
web服务器可以接受目录的URI请求,路径可以被解析为一个目录,而不是一个文件,这时可以有不同的动作
- 返回一个错误,一般403
- 不返回目录,而是返回一个特殊的默认索引文件
- 扫描目录,返回一个包含目录内容的HTML页面
大多数web服务器都会去查找一个index.html或index.htm的文件来代表该目录
如果没有提供默认的索引文件,没有禁止使用目录索引,很多的web服务器都会自动返回一个html,html中会列出目录中的文件名,文件大小和修改日期和每个文件的URI链接
5.7.3 动态内容资源的映射
将URI映射为动态资源,web服务器需要提供基本的机制去识别动态资源并web服务器连接到其他应用程序上。
5.7.4 服务器端包含项
web服务端提供服务器端包含项SSI支持,如果某个资源被标识为存在服务器端支持项,服务器会在发送给Client端的时候进行处理
5.7.5 访问控制
对于请求资源时,可以ClientIP等进行控制,或者要求输入密码来访问资源
5.8 构建响应
执行请求的方法的动作后,需要返回响应报文,包括响应状态码,响应首部,还可能包含响应主体
5.8.1 响应实体
如果事务产生了响应实体,就会将内容放到响应报文中,报文中包括
- 响应主体的类型MIME类型的Content-Type首部
- 描述了响应主体长度的Content-Length首部
- 实际报文的主体内容
5.8.2 MIME类型
web服务器需要确定响应主体的MIME类型。
web服务器会为每个资源扫描一个包含所有扩展名的MIME文件,来确定MIME类型
分类方式
- Magic typing 魔法分类 直接对后缀名进行匹配MIME类型
- Explicit type 显示分类 强制指定目录或文件的MIME类型
- 类型协商
5.8.3 重定向
重定向响应并不是成功的报文,只是将请求重定向到其他地方执行。
3xx代表的重定向。
Location响应首部包含了内容的新地址或者优选地址的URL
重定向的情况
- 永久删除的资源 资源被移动到新的位置或者被重新命名,有了新的URL,就可以通过重定向让Client从新地址自获取资源,一般用301的状态码
- 临时删除的资源 资源被临时移走或者临时重命名,一般用303或者307状态码
- URL增强 服务器通过生成一个新的嵌入式状态信息的URL,将用户重定向到新的URL,一般也是303或者307
- 负载均衡 如果负载太高可以将其重定向到一个负载不太高的服务器,一般也是303或者307
- 服务器关联 web服务器上可能有某些用户的本地信息,可以重定向到包含这个Client新的服务器上,一般也是303或者307
- 规范目录名称 Client请求的URI是一个不带尾部斜线的目录时,会将Client重定向到一个加了斜线的URI上,这样连接就正常工作了
5.9 第六步——发送响应
服务器发送数据时,对于持久连接的处理要特别注意计算Content-Length首部,否则Client不能知道响应什么时候结束,对非持久连接在发送响应后应该关闭自己这一端的连接
5.10 第七步——记录日志
用来描述已执行的事务
6 代理
web代理(proxy)服务器是网络的中间实体,位于Client和Server之间,在各个端点之间传输HTTP报文
6.1 Web的中间实体
没有代理,Client就直接和Server执行对话,有了代理,Client与Proxy对话,Proxy和Server进行对话,实现事务的处理
6.1.1 私有和共享代理
某个Client专属的代理为私有代理,有些浏览器辅助的产品,和一些ISP服务等,会在PC上运行小的代理,以便扩展浏览器特性,提高性能,或为免费的ISP服务提供广告
共享代理集中式代理费效更高,容易管理,比如高速缓存服务器,会利用用户间共同的请求。
6.1.2 代理和网关的对比
代理连接是两个或多个使用相同协议的应用,而网关连接的则是两个或多个使用不同协议的端点。
网关扮演的协议转换器的协议
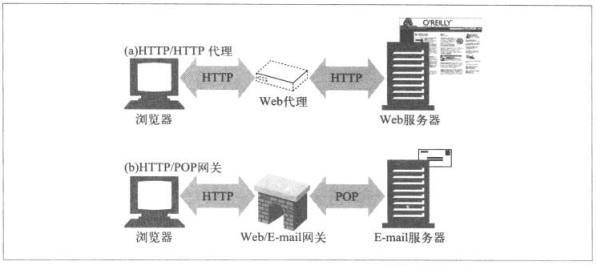
图二中间是一个HTTP/POP网关,将前台的HTTP和后端POP的E-mail连接起来了,可以将Web事务转化为POP事务,用户可以用HTTP协议读取E-mail。
由于浏览器和服务器实现的不同的版本的HTTP协议,代理也需要做一些协议转换的工作,商业化的代理服务器也会实现网关的功能来支持SSL安全协议,SOCKS防火墙,FTP访问等
6.2 为什么使用代理
改善安全性,提高性能,节省费用,由于可以接触所有流过的HTTP流量,可以监视流量并对其进行修改,以实现有用的增值web服务
- 儿童过滤器 防止儿童访问成人内容
- 文档访问控制 实现对资源访问控制策略,可以在请求时进行密码的认证等
- 安全防火墙 可以限制那些应用层协议的数据可以流入或者流出一个组织,对流量进行检查
- web缓存 维护一些常用文档的本地副本,以减少外网通信流量
- 反向代理 用于提高访问速度,去寻找最近的站点等
- 内容路由器
- 转码器 可以修改内容的主体格式,例如传输gif格式将其转化为JPEG格式,以减小尺寸,或者直接压缩等
- 匿名者 从HTTP报文中删除身份特性(例如ClientIP地址,From首部,Referer首部,cookie,URI的会话ID和User-Agent等)
6.3 代理会去往何处
6.3.1 代理服务器的部署
- 出口代理 将代理固定在本地网络出口,控制本地到因特网的流量,对外部攻击进行防护
- 入口代理 用于处理Client的聚合请求,对请求进行控制,缓存文件等
- 反向代理 网络边缘,提高网络请求心梗
- 网络交换代理 进行流量监控,需要足够处理能力的代理
6.3.2 代理的层次结构
在代理的层次结构中,报文从一个代理传给另一个代理,知道最终抵达。
代理的层次结构不一定都是静态的,可以根据多种因素将报文发送给不同的服务器,例如负载均衡,根据地理位置路由,协议路由
6.3.3 代理是如何获取流量的
- 修改客户端 浏览器支持手工或者自动配置代理服务器,Client就会将HTTP请求发送给代理而不是原始服务器
- 修改网络 在Client不知情的情况下,拦截网络流量并将其导入代理,也称透明代理
- 修改DNS的命名空间 通过DNS解析到代理的IP地址
- 修改Web服务器 将请求重定向到代理上
6.4 客户端的代理设置
- 手工配置
- 预先配置浏览器
- 代理的自动配置 提供一个URI,指向一个用JavaScript编写的代理自动配置文件,Client读取Js后运行以决定是否应该使用一个代理
- WPAD的代理发现 这个协议可以自动检测浏览器可以从哪个配置服务器下载到一个自动配置文件,这么吊的吗?
6.4.1 手动配置
略
6.4.2 PAC文件
PAC是一个小型的js程序,在"automatic configuration"(自动配置)中会提供一个URI,我是没找到。浏览器会从这个URI获取PAC文件,并用js的逻辑计算获取恰当的代理,PAC文件的后缀为.pac,MIME类型通常是application/x-ns-proxy-autoconfig,每个PAC文件需要定义一个名为FindProxyForURL(url, host)的函数,用于计算访问URI时使用的恰当的代理服务器
func FindProxyForURL(url, host) {
if (uri.substring(0, 5)) == "http:") {
return "Proxy http-proxy.mydomain.com:8080";
} else if (uri.substring(0, 4)) == "ftp:") {
return "Proxy ftp-proxy.mydomain.com:8080";
} else {
return "DIRECT"
}
}
- DIRECT 不进行代理直接连接
- Proxy host:port 应用指定的代理
- SOCKS host:port 应用指定的SOCKS服务器
6.4.3 WPAD
略,没懂
6.5 与代理请求相关的一些棘手的问题
现在对于HTTP/1.1都要求完整的URI了
6.5.5 转发过程中对URL的修改
代理如果在转发报文时修改请求URI的话需要特别的小心,对于URI的微小修改都可能给下游服务器带来互操作性问题,例如显示的使用":80"取代默认的HTTP端口等
后边更多的是讲浏览器输入不完整URI的会产生的问题,这个不是我需要考虑的
6.6 追踪报文
6.6.1 Via首部
Via首部字段列出了报文途径的每个中间节点有关信息,报文每经过一个节点,都必须将中间节点添加到Via列表的末尾
Via: 1.1 proxy1.whysdomain.com, 1.0 proxy2.whysdomain.com
上述代表报文流经了两个代理,一个是1.1协议的proxy1.whysdomain.com,第二个是1.0协议的proxy2.whysdomain.com
- Via报文用于记录报文的转发,诊断报文循环,标识请求/响应链上所有发送者的能力
- 代理也可以用Via首部来检测网络中的路由循环
6.6.1.1 语法
包含可选协议名,必选协议版本,必选节点名和可选描述性注释
- 协议名 默认为HTTP,否则要加上协议名,中间靠“
/”分隔,其他协议例如HTTPS,FTP等 - 协议版本 标准版本号,例如HTTP的1.0和1.1
- 节点名 节点主机和可选端口号,没有端口号为协议默认端口号
- 注释
6.6.1.2 请求和响应路径
请求和响应路径相反
6.6.1.3 Via和网关
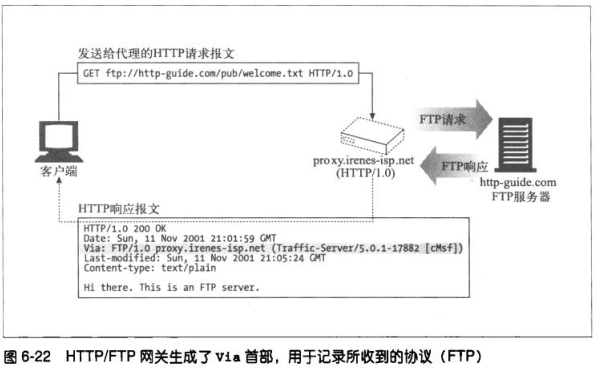
代理会为非HTTP协议的服务器提供网关的功能,Via首部可以记录协议转换,示例HTTP/FTP网关
6.6.1.4 Server和Via首部
代理转发的时候要确保没有修改Server首部,Server的首部用原始服务器的,代理只添加Via
6.6.1.5 Via隐私和安全问题
Via可以将多个代理压缩为一个
6.6.2 TRACE方法
代理服务器可以在转发报文的时候,添加删除修改首部,将主体部分转换为不同的格式。
TRACE方法可以跟踪经代理链传输的请求报文,观察报文经过了那些代理,以及每个代理对请求报文做了那些处理,一般用于调试代理流
当TRACE请求报文到达目的服务器,整条请求的报文会被封装在HTTP响应主体中返回发送端,服务端返回的Content-Type为message/http,状态码为200 OK
Max-Forwards
Max-Forwards可以限制TRACE和OPTIONS请求所经过的代理跳数,可以检测代理链是否有无限循环转发报文
该请求首部包含一个整数,如果设置为0,则接收者不是原始服务器,也必须返回TRACE报文给Client,如果代理接收到的Max-Forwards值大于0,则会在转发前对其减一,这样就可以看到每一跳代理做的处理了
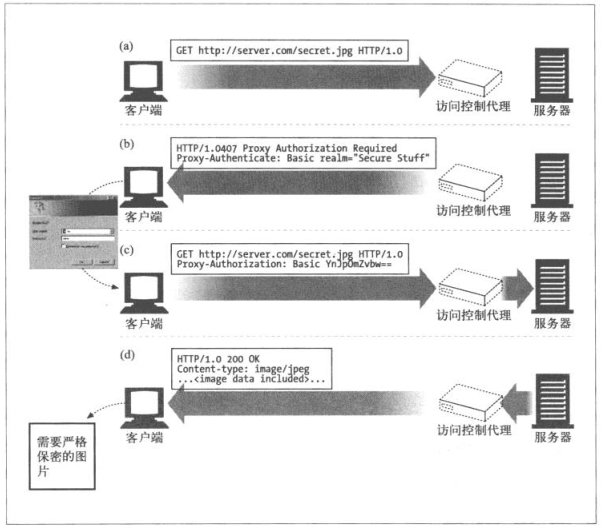
6.7 代理认证
代理认证机制可以阻止对内容的请求,直到用户提供了有效的访问权限证书
- 对受限内容请求到代理服务器,会返回407的状态码和用于描述怎样提供证书的Proxy-Authenticate首部字段
- Client接收到407响应之后,会尝试在本地数据库或提示来提供证书
- 获得证书后,Client重新发送请求,在Proxy-Authorization首部字段中提供所需证书
- 如果证书有效则将请求沿传输链路向下传输,否则再次发送407应答
如果当链路有多个代理,且每个代理都需要认证时,代理认证通常不能很好的工作
6.8 代理的互操作性
6.8.1 处理代理不支持的首部和方法
代理服务器可能不能正常支持所有经过其的首部字段,有些首部字段比代理自身还要新,其他首部可能是特定应用的独有字段。
代理服务器对不认识的首部字段进行转发,并且必须维持同名首部字段的相对顺序(报文中可能有多个同名字段,会合并为一个用逗号分隔的列表,但是顺序要保持和原来一致)
6.8.2 OPTIONS:发现对可选特性的支持
OPTIONS方法可以使Client或代理发现Server或者某些特定资源所支持的功能,Client可以在交互前确定Server支持的能力
如果请求url是个*,请求的就是整个服务器所支持的功能
OPTIONS * HTTP/1.1
如果请求是个是个的url,则是这个url支持的功能
如果请求成功,会返回包含首部字段的200 OK响应。在HTTP/1.1中会包含的指定首部字段为Allow首部,这个首部包含了Server所支持的方法
6.8.3 Allow首部
Allow实体首部字段列出了请求URI标识的资源所支持的方法和列表,例如
Allow: GET, HEAD, POST
7. 缓存
web缓存是可以自动保存常见文件副本的HTTP设备,当web请求到达缓存服务器时,如果有本地缓存,则可以直接从本地获取而不是原始Server
优点有
- 减少了冗余的数据传输,节省网络费用
- 缓解网络瓶颈,不需要使用更多的带宽就能加载页面
- 降低了对原始服务器的要求,服务器可以更好的响应
- 降低距离时延,从较远的地方加载页面会更慢一些
7.1 冗余的数据传输
对于同一热点文件,存在频繁请求原始服务器的问题,会导致原始服务器网络带宽增加,降低原始服务器性能和传输速度,如果有缓存,请求通过缓存服务器响应,就大大解决了这一问题
7.2 带宽瓶颈
对于请求资源,请求速率是该链路上最慢节点的速度访问服务器,如果能从本地链路的一个节点获取到缓存文件的副本,就可以提高性能,尤其在访问较大的文件的时候。
7.3 瞬间拥塞
缓存在破坏瞬间拥塞的时候非常重要,例如突发爆炸性新闻使大量请求访问同一个uri,就会出现瞬间拥塞,造成的过多流量峰值可能会使网络和Server产生灾难性的崩溃
7.4 距离时延
书中示例是波士顿到旧金山信号可以在15毫秒内从波士顿传送到旧金山,30毫秒一个往返。
请求一个包含20个图片的web页面,如果Client可以打开4个并行连接,并保持连接活跃状态,需要消耗240毫秒,如下图所示
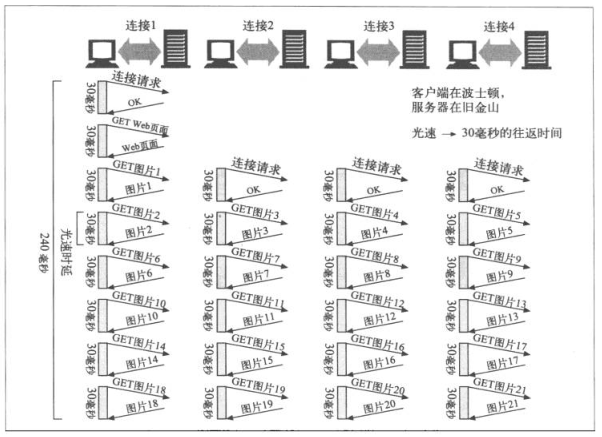
可以看到这里后三个并行连接建立的时间是在获取web页面之后。
7.5 命中与未命中
缓存无法存储所有的文档,对于缓存中有副本,被称为缓存命中,如果缓存中没有副本可用,而转发到Server,这被称为缓存未命中。
7.5.1 再验证
Server内容可能会发生变化,缓存要不时进行检测,检测他们保存的副本是否仍在服务器上的最新副本,则为再验证。
对于再验证,HTTP提供了特殊的请求,用于不从服务器中获取对象,就可以快速检测内容是否是最新的。
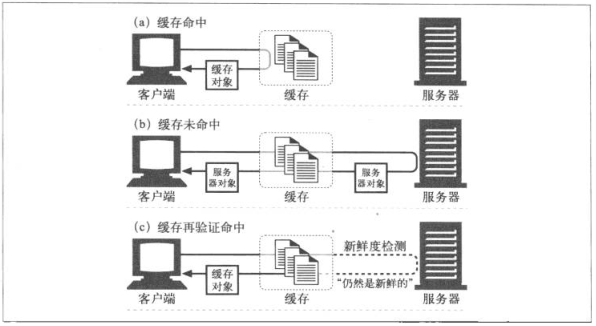
一般对于大部分缓存,只有在Client进行请求的时候并且副本旧的需验证的时候才会检测副本,向原始服务器发送在验证请求,如果内容没有变化会返回一个304 Not Modified的响应,缓存接收到后确认副本有效,并重新标识副本为新鲜的,并将副本返回给Client,这个过程就是再验证命中。
最常用的再验证工具是使用If-Modified-Since首部,通过该首部进行GET请求验证。
对于再验证出现的三种情况
- 再验证命中 如果原始Server没有进行修改的话,会返回304
- 再验证未命中 如果对象与已缓存的副本不同,则Server会向Cache发送一个完整内容的
200 OK响应 - 对象被删除 如果对象被删除,则返回
404 Not Found响应,Cache会将副本删除
7.5.2 文档命中率
由缓存服务器提供服务所占比例为缓存命中率,影响命中率的因素更多的是缓存的大小,其次就是缓存用户的兴趣点和相似性,缓存数据的变化或者个性化频率。
7.5.3 字节命中率
缓存提供的字节在传输的所有字节中所占的比例,通过这种方式可以看到节省到的流量程度。
文档命中率反应的是阻止了多少web事务,反应的是降低整体的时延,而字节命中率是阻止了多少流量到达原始Server
7.5.4 区分命中和非命中的情况
HTTP没有为Client提供响应为缓存命中还是原始Server请求到的,一些商业缓存会在Via首部添加一些额外信息。
Client可以通过Date首部,将响应中的Date首部和当前时间比较,如果响应的日期比较早,可以认为是Cache的响应;也可以通过Age首部来检测缓存的响应
7.6 缓存的拓扑
7.6.1 私有缓存
web浏览器中就有私有缓存,将文档缓存在电脑磁盘或者内存
7.6.2 公有代理缓存
公有缓存会有接收来自多个Client的访问,从本地提供文档,或者代表Client与Server进行联系。
代理缓存遵循代理的原则,可以手动指定代理或者代理自动配置文件,也可以使用浏览器为代理缓存,也可以使用拦截代理在不配置浏览器的情况下,强制HTTP请求经过缓存的传输(参见20章)
7.6.3 代理缓存的层次结构
层次化的缓存是很有意义的,在这种结构中,在较小的Cache未命中的请求会被导向较大的父缓存,由父Cache为剩下的流量的流量提供服务。
基本的思想就是在靠近Client的地方使用小型廉价的Cache,而在更高的层次,逐步采用更大功能更强的Cache来装载更多的共享文档。
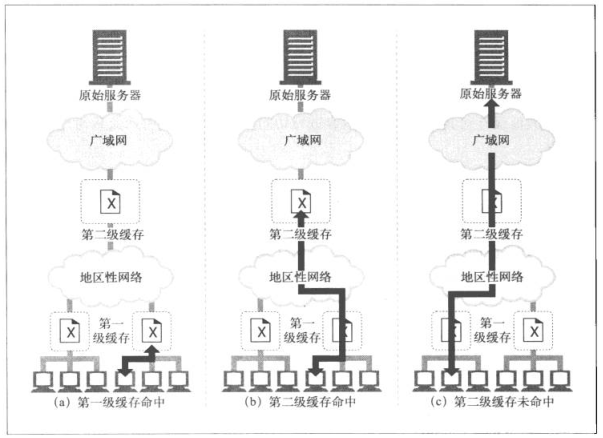
更多的时候,我们希望在附近的第一层Cache命中,如果没有命中,较大的父Cache可能能够处理他们的请求,在缓存结构很深的情况下,请求可能要穿过很长的缓存,但每个拦截代理都会添加一些性能损耗,当代理链路会变得很长的时候,这种性能损耗会很明显。
一般深度会在连续二到三个代理,而新一代代理服务器会使代理链长度变得不那么重要。
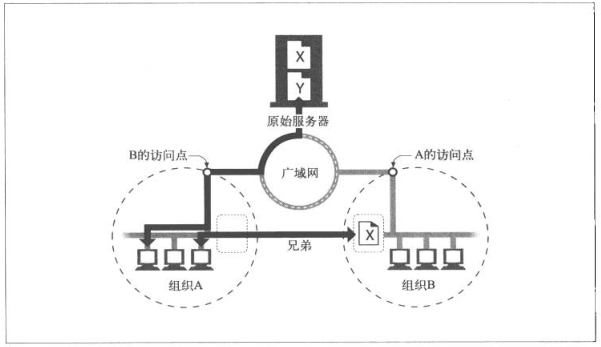
7.6.4 网状缓存、内容路由以及对等缓存
网状缓存不同于简单的缓存层次结构,会有更复杂的对话方式,做出动态缓存通信决定策略,决定与哪个父Cache进行通话,或者直接绕开Cache去直接连接原始Server
决定策略为内容路由器,需要完成的功能有
- 根据URL在父Cache或原始Server间进行动态选择
- 根据URL动态地选择一个特定的父Cache
- 前往父Cache之前,在本地缓存中搜索已缓存的副本
- 允许其他Cache对其缓存的部分内容进行访问,但不允许其他的互联网流量通过他们的Cache
Cache之间这些更复杂的关系允许不同的组织互为对等实体,被称为兄弟缓存,HTTP协议并不支持,依赖的是扩展的ICP(因特网缓存协议)和HTCP(超文本缓存协议)
7.7 缓存的处理步骤
- 接收——Cache从网络中读取抵达的请求报文
- 解析——Cache对报文进行解析,提取URL和各种首部
- 查询——Cache查看是否有本地副本可用,如果没有就获取一份副本(并将其存储在本地)
- 新鲜度检测——Cache查看已缓存的副本是否足够新鲜,如果不是就去原始Server询问是否有更新
- 创建响应——Cache会用新的首部和已缓存的主体来构建响应报文
- 发送——Cache通过网络将响应发回给Client
- 日志——Cache可选地创建一个日志条目来描述事务
7.7.1 第一步——接收
略
7.7.2 第二步——解析
略
7.7.3 第三步——查找
获取了URL后会查找本地副本,本地副本可能存储在内存中,本地磁盘甚至附近另一台服务器,如果没有对根据情况和配置到原始Server或者父Cache获取,或者返回一个错误信息。
已缓存的对象中包含了服务器响应主体和原始服务器响应首部,在Cache命中时返回正确的服务器首部,已缓存对象中还包含一些元数据,用来标记对象在缓存中停留了多久或者被用到了多少次。
7.7.4 第四步——新鲜度检测
HTTP缓存将服务器文档的副本保留一段时间,在这段时间,都认为文档是新鲜的,Cache可以在不联系Server的情况下直接提供文档,一旦已缓存时间超过新鲜度限值,就会认为缓存文档过时,Cache需要和原始Server进行确认,查看文档是否发生变化。当然Client发送给Cache的时候可以强制缓存进行再验证或者完全避免验证
7.7.5 第五步——响应
缓存对响应会根据Client的协议版本进行转换,并添加Via首部来说明请求是由代理服务器提供的。
注意的是,缓存不应该调整Date首部,Date首部是原始Server生成这个对象的日期。
7.7.6 第六步——发送
略
7.7.7 第七步——日志
除了日志之外,还可能更新缓存命中和未命中的条目的统计数据
7.7.8 缓存处理流程图
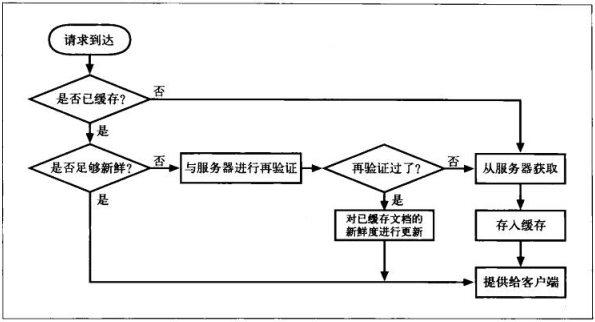
7.8 保持副本新鲜
Cache上的副本可能会与Server上的文档不一致,Server不需要知道有哪些Cache缓存了Server的那些文档,Cache通过文档过期和服务器再验证。
7.8.1 文档过期
通过特殊的HTTP Cache-Control首部和Expires首部,这些文档附加一个过期日期。
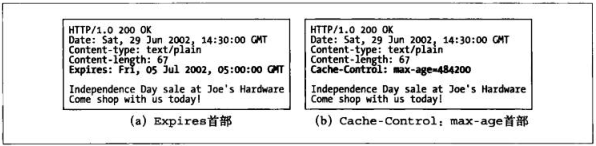
在文档过期之前,缓存可以以任意频率使用这些副本,而无需与服务器联系,文档过期的话,Cache就必须对Server进行核对,询问文档是否被修改过,如果被修改过就获取一份新的。
7.8.2 过期日期和使用期
Cache-Control是相对的时间,而Expires是一个绝对的时间,虽然Expires是1.0的首部,但是对于一些秒杀等活动,就是要要求在绝对时间进行结束的。
7.8.3 服务器再验证
缓存文档过期并不意味与原始Server的文档有实质的区别。
- 如果文档变化,Cache获取一份新的文档副本,存储在旧的文档位置,然后发送给Client
- 如果文档没有变化,Cache获取新的首部,一个新的过期时间,并对Cache中的首部进行更新
Cache只有在文档到期的时候,进行验证
HTTP协议要求缓存返回的内容满足下列内容之一:
- 足够新鲜的副本
- 与Server验证后,仍确认新鲜的副本
- 如果需要验证的Server出现故障,返回错误报文
- 附带警告信息说明内容可能不正确的已缓存副本
7.8.4 用条件方法进行再验证
再验证通过的是GET请求,HTTP定义了五个条件请求首部,对Cache有用的是If-Modified-Since和If-None-Match
7.8.5 If-Modified-Since: Date再验证
If-Modified-Since再验证请求通常被称为IMS请求,只有自某个日期之后资源发生了变化,IMS请求才会指示服务器执行请求。
- 如果到指定日期后,文档被修改,If-Modified-Since条件成立,通常GET请求就会成功执行,携带新首部的新文档会被返回给Cache,新的首部会包含一个过期日期
- 如果到指定日期后,文档没有被修改,If-Modified-Since条件不成立,会返回Client一个
304 Not Modified响应报文,为了提高有效性,不会返回文档的主体,也会发送一个包含过期日期的新的首部
If-Modified-Since首部和Last-Modified服务器响应首部配合工作,原始Server会将最后的修改日期附加到所提供的文档上,当Cache对已缓存文档进行再验证的时候,就会包含一个If-Modified-Since首部,其中携带有最后修改已缓存副本的日期。如果判断的就是If-Modified-Since首部的最后修改日期和Server上的最后修改日期是否相同。
对于一些Web服务器是将If-Modified-Since字符串而不是日期,这样就是直接判定是否两个日期是否相等,而相反的使用日期应该判定为是否在If-Modified-Since之后是否修改。
?这会造成什么影响吗
7.8.6 If-None-Match:实体标签再验证
对于最后修改日期再验证是不够的,因为可能出现以下情况
- 文档被周期性重写,但是实际上数据是一样的,但是修改日期会发生变化
- 有些文档被修改了,但是修改并不重要
- 有些服务器无法准确提供页面的最后修改日期 ?还有这种操作,貌似我们的预言环境就是这样
- 有些服务器提供的文档会在亚秒级发生变化(例如监视器),对于这些服务器,以1s为粒度的修改日期就不够用了
HTTP提供实体标签(ETag),附加到文档上。
当发布文档的时候,可以修改文档的实体标签来说明这是个新的版本。
可以在If-None-Match首部包含多个实体标签。
?怎么标记标签
7.8.7 强弱验证器
HTTP/1.1支持强弱验证器
只要是内容发生发还,强验证器就会变化,弱验证器允许对一些内容进行修改,但是内容的主要含义发生变化时通常需要变化也是会进行变化的。
服务器会通过前缀"W/"来表示弱验证器
ETag: W/"v2.6"
感觉作用并不是很大
7.8.8 什么时候该使用实体标签和最近修改日期
略
7.9 控制缓存的能力
HTTP可以通过多种方式定义缓存,缓存的优先级:
- 附加一个Cache-Control:no-Store
- 附加一个Cache-Control:no-cache
- 附加一个Cache-Control:must-revalidate
- 附加一个Cache-Control:max-age
- 附加一个Expires
- 不附加
7.9.1 no-Store和no-Cache响应首部
标识为no-Store的响应会禁止缓存响应进行复制,Cache会像非Cache服务器一样进行转发,并附带no-Store响应,并删除对象
标识为no-cache的响应实际上可以缓存在本地缓存区,在与原始Server进行新鲜度检验,Cache不能直接提供给Client使用,Pragma: no-cache可以兼容HTTP/1.0
7.9.2 max-age响应首部
Client可以认为文档处于新鲜的秒数,还有一个s-maxage首部,和max-age一样,但是仅用于共享公有缓存
也可以将其设置为0,这样每次Client也进行刷新
7.9.3 Expries响应首部
不推荐使用,因为服务器之间时钟不同步,或者不正确
7.9.4 must-revalidate响应首部
该首部告诉Cache,在事先没有和原始Server进行验证的时候,不能提供此对象,如果再验证的时候原始Server不可用,缓存就必须返回一条504 Gateway timeout错误
7.9.5 试探性过期
如果响应没有max-age首部,也没有Expires首部,Cache可以计算出一个试探性最大使用期限,可以使用任意算法,如果得到的时间大约24小时,就应该在首部加入Heuristic Expiration Warning(试探性过期警告,警告13),不过很少浏览器提供
LM-Factor算法是一种常见的算法,如果文档包含最后修改日期就可以使用此算法,算法逻辑
- 如果已缓存文档最后一次修改发生在很久以前,就可能是一份稳定的文档,可以继续保存在Cache
- 如果已缓存文档最近被修改过,则说明可能会发生频繁的变化,在对其再验证前,只应该缓存很短一段时间
通常人们可以对这个算法的结果设置上限,这样周期不会太大。
如果没有默认修改日期,就会分配一个默认的新鲜周期,
7.9.6 客户端的新鲜度检测
浏览器有Refresh刷新和Reload重载按钮可以强制对浏览器或者代理缓存中可能过期的内容进行刷新。
Refresh会发送一个带有Cache-Control请求首部的GET请求,会强制进行再验证,或者无条件直接从原始Server获取文档,当然确切行为取决于浏览器。
Client可以通过Cache-Control请求首部来强化或者放松对过期时间的限制
- Cache-Control: max-stale =
<s>Cache可以随意提供过期的文件,如果指定了时间,在这段之间内,文档不认为过期,可以放松缓存规则 - Cache-Control: min-fresh =
<s>在至少未来<s>秒内文档要保持新鲜,这就使缓存规则更加严格了,解释一下就是如果缓存时间超过该时间,就执行再验证 - Cache-Control: max-age =
<s>Cache无法返回缓存时间长于<s>秒的文档,这样使缓存规则更加严格了 - Cache-Control: no-cache 强制Cache进行资源再验证
- Cache-Control: no-store Cache应该删除该文档,因为可能包含敏感信息
- Cache-Control: only-if-cached 只有当缓存中有副本存在时,Client才会获取一份文档
7.9.7 注意事项
略
7.10 设置缓存控制
7.10.1 控制Apache的HTTP首部
略,我都好多年不用Apache了
7.10.2 通过HTTP-EQUIV控制HTML缓存
HTML2.0定义了<META HTTP-EQUIV>标签,这个标签位于HTML文档顶部。。
web服务器应该为HTML解析<META HTTP-EQUIV>标签并将获取的首部加入到HTTP响应,但是很多web服务器并不支持,而且只能用于HTML
7.11 详细算法
略过,缓存算法并不是我关注的点,我也不需要去实现这个。
7.12 缓存和广告
7.12.1 发布广告者的两难处境
略
7.12.2 发布者响应
略
7.12.3 日志迁移
略
7.12.4 命中和使用限制
略
8 集成点:网关,隧道及中继
8.1 网关
HTTP扩展和接口是用户需求驱动的,要在web上发送更复杂的资源的需求出现时,就有网关的出现了。
网关是通过HTTP协议提供其他协议或者资源。
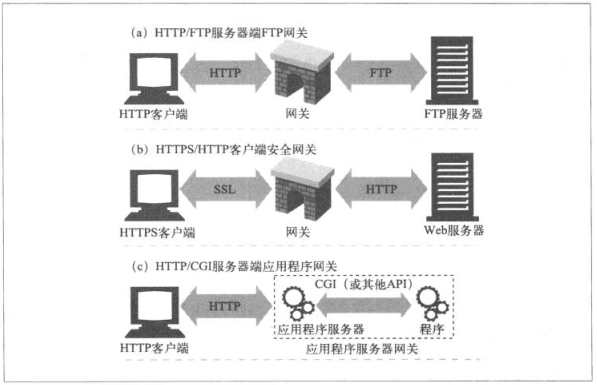
- 网关对收到的FTP url的HTTP请求,打开FTP连接并向FTP服务器发送适当的命令,将文档以HTTP协议返回
- 网关通过SSL收到一条加密的Web请求,网关进行解密像目标Server发送一个HTTP请求,腾讯云的CLB就是这个
- 网关通过应用程序服务器网关API,将HTTP请求连接到Server端的应用程序上。
web网关在一端使用HTTP协议,另一端使用其他协议,所以有了服务端网关和客户端网关
- 服务端网关是通过HTTP协议接收请求,提供其他协议与Server进行通信(HTTP/*)
- 客户端网关是通过其他协议接收请求,提供HTTP协议与Server进行通信(*/HTTP)
8.2 协议网关
8.2.1 HTTP/* 服务器端Web网关
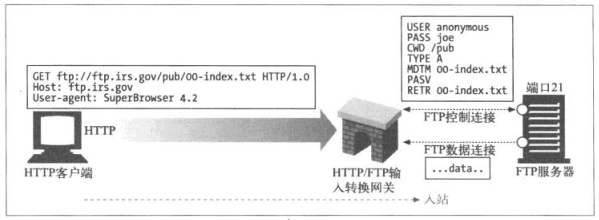
对于FTP资源的HTTP请求
ftp://ftp.irs.gov/pub/00-index.txt
网关收到请求会到原始Server的FTP端口的连接,通过FTP协议获取对象,网关会做的事情
- 发送USER和PASS命令登录到服务器
- 发送CWD命令,转移到Server上合适的目录
- 将下载类型设置为ASCII
- 用MDTM获取文档的最后修改时间
- 用PASV告诉Server将有被动数据获取请求到达
- 用RETR请求获取对象
- 打开到FTP服务器的数据连接,服务器端口由信道控制,一旦数据信道打开,就会将内容返回给网关
获取完成后会将对象放在HTTP响应中返回给Client
8.2.2 HTTP/HTTPS: 服务器端安全网关
通过网关对Web请求加密,Client使用HTTP请求Web内容,而网关对内容进行加密
8.2.3 HTTPS/HTTP: 客户端安全加速网关
接收安全的HTTPS流量,并且进行解密,并向Web服务器发送普通的HTTP请求。
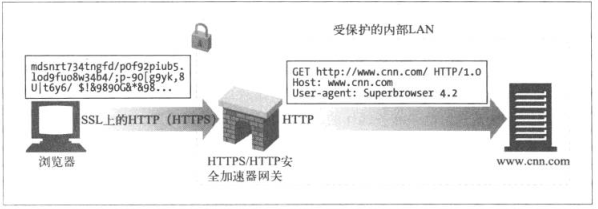
这些网关包含专用的解密硬件,比原始Server更有效的方式进行解密,减轻原始服务器负荷。
网关和原始Server之间是未加密的流量,所以要确保网关和原始服务器之间的网络是安全的。
8.3 资源网关
通过HTTP连接到应用程序服务器,但是应用程序Server并没有返回文件,而是将请求通过一个网关应用编程接口(Application Programing Interface,API)发送给服务器上的应用编程接口
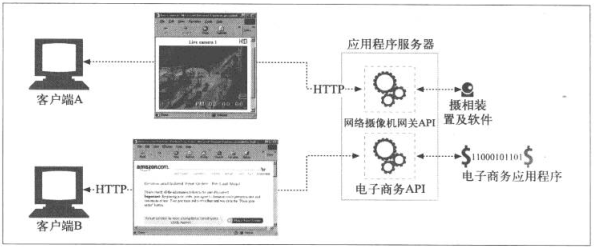
- 根据URL通过API发送给一个数码摄像机应用程序,得到的图片绑定到一条HTTP响应报文,返回给Client
- 同理与电子商务应用程序交互
8.3.1 CGI
CGI为通用网关接口,是一个标准接口集,Web服务器可以装载应用程序以响应对特定URL的HTTP请求,并将程序的输出数据放到HTTP响应中回送。
可以用于动态的HTML,数据库处理,业务处理等。
CGI应用程序独立于服务器,可以是任意语言实现的。
这种方式可以防止扩展直接与Server相连发生错误引发服务器问题,但是会造成性能的耗费,为每条CGI请求引发一个新进程的开销很高,会加重Server端的负担,所以有守护进程的CGI可以消除此消费
8.3.2 服务器扩展API
略
8.4 应用程序接口和Web服务
略,说实话没看懂啥意思
8.5 隧道
Web隧道允许用户通过HTTP连接发送非HTTP流量,可以使流量穿过只允许Web服务的防火墙
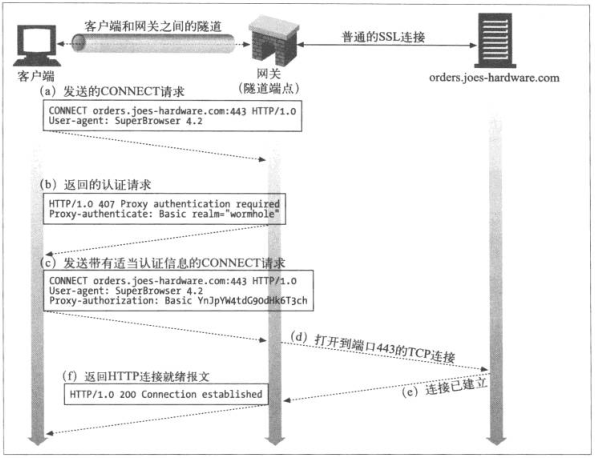
8.5.1 用CONNECT建立HTTP隧道
使用HTTP的CONNECT方法建立CONNECT方法请求隧道网关创建一条到达任意目的服务器和端口的TCP连接,并对客户端和服务器之间的后继数据进行盲转发。
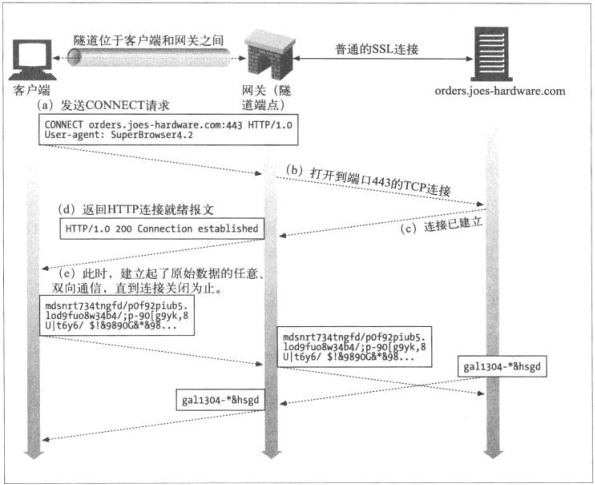
注意返回的200 Connection Established,当隧道建立起来,Client通过HTTP隧道发送的所有数据都会直接输出给TCP连接,Server返回的数据也会直接通过HTTP隧道返回给Client
- CONNECT请求
CONNECT home.netscape.com:443 HTTP/1.0
指定主机和端口即可
- CONNECT响应
HTTP/1.0 200 Connection Established
响应并不会包含Content-Type首部,连接只是对原始字节进行转接,不再是报文的承接者
8.5.2 数据隧道,定时和连接管理
管道化数据对网关是不透明的,所以网关不能对分组的排序和分组流作任何假设,一旦隧道建立起来了,数据就可以在任何时间流向任意方向。
作为一种性能优化的方法,允许Client在发送了CONNECT请求之后,接收响应之前,发送隧道数据,这样可以更快地将数据发送给Server,这就意味着网关必须能够正确的处理跟在请求之后的数据,不能假设网络I/O请求只会返回首部,网关需要在准备就绪时,将首部和数据发送给Server。在请求之后以管道的方式发送数据的Client,如果发现回送的响应是认证请求,或者其他非200但是不致命的错误状态,就必须做好重发请求数据的准备。
如果任意时刻,隧道的任意端点断开了连接,那么这个端点发出的所有未传输数据都会被传输到另一端点,之后另一端点的连接也会被隧道终止,如果还有需要传递的数据会被丢弃。
8.5.3 SSL隧道
Web隧道最开始就是为了传输SSL流量,将所有流量通过分组过滤路由器和代理服务器以隧道的方式传输,提高安全性。
加密SSL的信息是加密的,无法通过传统的代理服务器转发,隧道通过HTTP连接传输SSL流量。
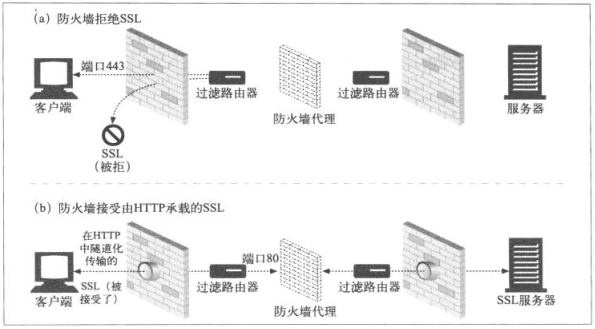
HTTP的隧道特性,可将原始的加密数据放在HTTP报文中,通过HTTP信道传输
8.5.4 SSL隧道与HTTP/HTTPS网关的对比
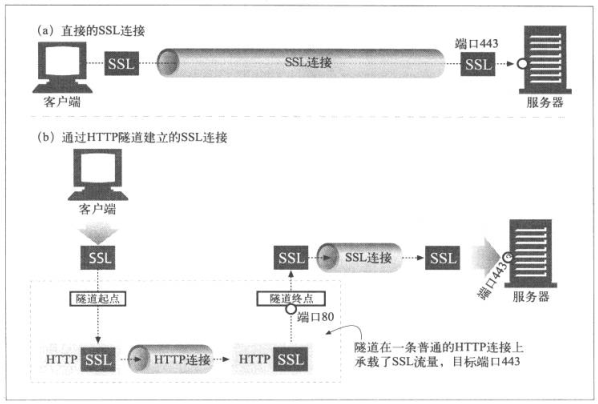
因为加密数据再HTTP报文中,所以隧道不需要实现SSL
8.5.5 隧道认证
可以将HTTP的代理认证和HTTP隧道配合
8.5.6 隧道的安全性考虑
恶意用户可以使用隧道越过防火墙传递游戏流量,甚至打开Telnet会话等,所以应该为指定端口开放隧道
8.6 中继
中继负责处理HTTP中建立连接的部分,然后对字节进行盲转发,不执行任何的首部方法和逻辑。
中继实现中存在一个问题,无法正常处理Connection首部,所以有潜在的挂起keep-alive的可能。
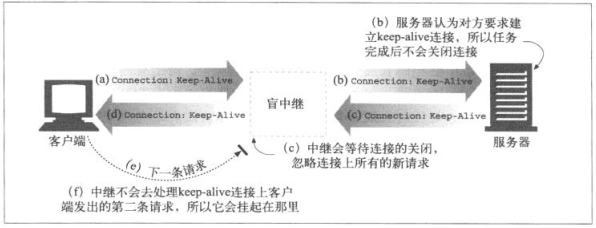
- Client向中继发送了包含
Contention: keep-alive首部的报文 - 中继直接转发
Contention: keep-alive首部的报文给Server,但是Contention是个逐跳首部,只适用于单条链路传输,而不是沿着链路传送下去 - Server接收到
Contention: keep-alive首部,认为中继需要与Server建立持久连接,所以响应了Contention: keep-alive - 中继收到之后直接转发,Client接收到
Contention: keep-alive首部,认为中继同意与Client建立持久连接 - 中继接收到Server的响应转发给Client,等待Server关闭连接,而Server在保持连接状态,也不会进行关闭
- Client接收到响应后,再度发送请求的时候会使用keep-alive的连接,中继不期待同一连接上有另一请求,浏览器会一直转圈
但是中继不是会关闭与Client的连接吗?
简化的代理都有互操作的问题,所以最好使用完全的代理
8.7 更多信息
略
9 Web机器人
Web robot
9.1 爬虫及爬行方式
Web爬虫会递归地对各种信息性web站点进行遍历,获取第一个web页面,然后获取那个页面指向的所有页面,就是HTML的超链接。
然后对碰到的文档进行拉取,处理和收集
9.1.1 从哪开始收集: 根集
起始的URL集合就是根集。
页面因为链接关系,很多页面之间是通过链接链也不能到达的,所以是一个集合
9.1.2 链接的提取以及相对链接的标准化
爬虫的时候会对HTML进行解析,将链接(相对URL转化为绝对URL)加入到需要爬行的页面列表
9.1.3 避免环路的出现
爬虫时可能链接链是个环路,需要在爬虫过程中记录抓取过哪些页面,否则会降低爬行的效率。
9.1.4 循环与复制
环路的危害
- 频繁爬一个页面,消耗带宽,并且可能无法获取别的页面
- 另一端Server也受到频繁请求,可能会造成Server不可用
- 重复页面的数据也没有用
9.1.5 面包屑留下的痕迹
因为一个站点的URL可能包含另一个站点的URL,所以可能最后爬取到整个互联网,如果这样需要使用复杂的数据结构来快速判定那些URL访问过。列表是不可能了,至少是搜索树或者散列数。
如果平均一个URL有40个字符,5亿个URL就是20GB。
确实只有数据量足够大必须需要数据结构的支持。
- 树和散列表
- 有损的存在位图 例如存在位数组(presence bit array),用散列函数将每一个URL转化为一个定长的数字,这个数字在数组中有个相关的存在位,每爬一个URL时,就将对应的存在位置位,如果存在位已经被置位,则认为已经爬取
- 检查点 将已访问的URL列表落入硬盘
- 分类 通过多个机器人分类进行爬取
9.1.6 别名和机器人环路
两个URL指向了相同的资源,两个URL互为别名
http://blog.whysdomain.com和http://blog.whysdomain.com:80,默认端口为80http://blog.whysdomain.com/~fred和http://blog.whysdomain.com/%7Ffred,%7F和~相同http://blog.whysdomain.com/x.html#early和http://blog.whysdomain.com/x.html#middle,标签并没有修改内容,或者传参等也可能是同样的资源http://blog.whysdomain.com/readme.html和http://blog.whysdomain.com/README.HTML,服务器是大小写无关的http://blog.whysdomain.com/和http://blog.whysdomain.com/index.html,默认页面为index.htmlhttp://blog.whysdomain.com/index.html和http://47.91.219.253/index.html,域名指向了47.91.219.253
9.1.7 规范化URL
消除显示别名
- 没有端口,添加默认80端口
- 所有转义字符%xx换为等价字符
- 删除#标签
这样有些别名就可以消除,其他问题就需要知道Server内部是否有这些问题
9.1.8 文件系统环路
文件系统中的符号连接会造成特定的潜在环路
9.1.9 动态虚拟Web空间
恶意的Server会有创建复杂爬虫循环来陷害爬虫。
实际不包含文件,通过虚拟的web空间将爬虫带入爱丽丝漫游仙境?
9.1.10 避免循环和重复
简单讲,没有办法避免所有环路,所以良好的爬虫需要有一组试探方式,以避免环路的出现。
另外需要一些取舍,当然这种方式有损
- 规范URL
- 广度优先的爬行 防止在一个站点跳入环路
- 节流 限制一个web站点获取的URL数量
- 限制URL大小
- URL/站点黑名单 对于发现有问题的URL或站点加入黑名单
- 模式检测 检测可能出现环路的URL重定向等问题,进行拒爬
- 内容指纹 对页面内容计算一个校验和,如果校验和存在就不再爬行
- 人工监视 需要有诊断和日志
9.2 机器人的HTTP
机器爬取需要遵循HTTP规范,所以一般机器人发出的都是HTTP/1.0请求,因为协议简单并且首部少。
9.2.1 识别请求首部
最值得提的就是User-Agent首部,这些首部可以标识机器人的能力
- User-Agent
- From 爬取的用户或者管路员E-mail
- Accept 告知Server可以发送那种媒体类型
- Referer 包含请求当前URL文档的URL
9.2.2 虚拟主机
支持Host首部,如果请求中不包含Host首部,可能会将错误和一个特定的URL关联。
9.2.3 条件请求
对时间戳或者实体标签等进行对比,判定版本没有进行升级,和缓存进行再验证机制一样
9.2.4 对首部的处理
一般都是通过GET请求来获取内容。
- 状态码 需要处理一些常见的状态码以及预期的状态码,也有些Server会返回200的状态码和描述错误的报文主体
- 实体 实体也可以通过类似http-equiv标签提供主体,所以HTTP机器人也需要进行这些标签的识别
9.2.5 User-Agent导向
很多站点会对不同的用户进行内容优化,或者对浏览器内容尽心检测等
9.3 行为不当的机器人
- 失控机器人 机器人发送请求会比正常人快很多,可能会造成Server负载升高甚至过载
- 失效的URL
- 很长的错误URL
- 爱打听的机器人 获取一些私密URL,这些私密URL不像URL
- 动态网关访问 对于动态网关的请求可能也会消耗很多Server的性能
9.4 拒绝机器人访问
1994年提出了简单的自愿约束技术,可以给管理员提供了一种控制机器人行为的机制,被称为拒绝机器人访问标准,为根目录的robots.txt
在根目录提供了一个可选的robots.txt文件,文件说明了机器人可以访问服务器的那些部分,如果机器人遵循这个自愿约束标准,就会在访问其他资源之前先获取robots.txt文件
9.4.1 拒绝机器人访问标准
版本有v0.0,v1.0和v2.0标准,一般机器人都采用v0.0和v1.0,因为v2.0要复杂,并没有得到广泛的认可。
9.4.2 Web站点和robots.txt文件
获取robots.txt
机器人采用GET方法获取robots.txt资源,如果Server上有robots.txt文件,Server会以text/plain主体中返回,如果没有,Server会返回404 Not Found。
机器人会根据返回的状态进行处理
- Server返回了一个2xx,机器人需要对其进行解析,并使用排斥规则从该站点获取内容
- Server返回了一个3xx,机器人需要跟着重定向获取robots.txt,再根据返回结果做处理
- Server返回了一个404,则认为没有任何排斥规则
- Server返回了一个503,机器人需要推迟对站点访问,直到可以获取资源为止
9.4.3 robots.txt文件的格式
简单的面向行的语法,有空行,注释行和规则行三种
每条记录都包含一组规则行,由一行空格或文件结束符终止,记录以一个或多个User-Agent行开始,后边跟着Disallow和Allow行
# this robots.txt
User-Agent: slurp
User-Agent: webcrawler
Disallow: /private
User-Agent: *
Disallow: *
示例阻止User-Agent为slurp和webcrawler的Client访问/private的URL下的所有内容,可以访问其他,并且阻止其他User-Agent访问所有内容。
- 如果机器人无法找到与之相关的User-Agent,则会认为没有限制
- 并且是匹配字符串,大小写无关,
User-Agent: bot与Bot,Robot,Bottom-Feeder都能进行匹配 - 然后在匹配的行中查找Allow和Disallow,并且是前缀匹配
9.4.4 其他有关robots.txt的知识
0.0版只支持Disallow,Allow行会被忽略
9.4.5 缓存和robots.txt过期
机器人如果在每次访问之前都获取一次robots.txt会很麻烦,并且增加Server的负载,机器人会获取robots.txt文件进行缓存,缓存也遵循HTTP协议
9.4.6 拒绝机器人访问的Perl代码
略
9.4.7 HTML的robot-control标签
在HTML文档中直接加入robot-control标签,遵循robots-control规则的机器人仍然可以获取文档,但是如果文档中有机器排斥标签,就会忽略这些文档
<META NAME="ROBOTS" CONTENT=directive-list>
对于机器人META指令
CONTENT的值有多种
- NOINDEX: 不对页面内容进行处理,忽略文档(不要再任何索引或者数据库中包含)
- NOFOLLOW: 不要爬这个页面的任何外连链接
- INDEX:可以对页面的内容进行索引
- FOLLOW:可以爬这个页面上的任何外连链接
- NOARCHIVE:不应该缓存这个页面在本地
- ALL:等价于INDEX和FOLLOW
- NONE: 等价于NOINDEX和NOFOLLOW
对于搜索引擎META标签
更多的是为搜索引擎提供信息
- DESCRIPTION 文本类型 web页面的摘要
- KEYWORDS 逗号列表 web页面的关键词
- REVISIT-AFTER 天数 应该在天数之后重新访问页面,预计那时页面会变化
9.5 机器人规范
略
9.6 搜索引擎
最广泛使用Web机器人的都是互联网的搜索引擎,爬虫为搜索引擎提供信息,并创建对应文档的索引
9.6.1 大格局
每条请求如果耗费0.5秒,对于10亿文档就是5700天
9.6.2 现代搜索引擎结构
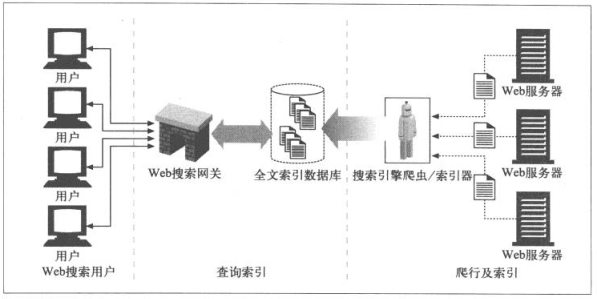
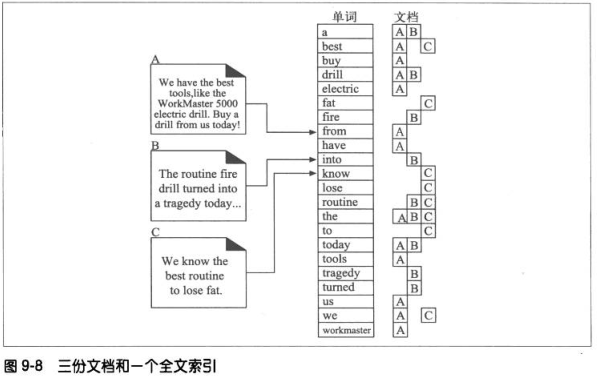
9.6.3 全文索引
全文索引就是一个数据库,给一个单词,就能提供包含该单词的文档。创建了索引就可以不对文档进行扫描
9.6.4 发布查询请求
通过在HTML页面填写form表单,将关键词传递给网关,进行查询
9.6.5 对结果进行排序,并提供查询结果
搜索结果会通过网关合并拼成结果页面返回给页面。
搜索引擎可以根据算法进行排行,将相关度最高的结果提供给用户
9.6.6 欺诈
对于Server的网关可以根据规则进行关键词优化等使站点排在前面。
当然也有搜索引擎自己进行欺诈。
10 HTTP-NG
10.1 HTTP发展中存在的问题
HTTP/1.1提供了追踪文档版本的标记和指纹,提供了一些方法来支持文档的上传和可编程网关之间的交互,还提供了对多语言内容,安全以及认证功能,降低流量的缓存功能,减小时延的管道功能,降低启动时间提高带宽使用效率的持久化连接,以及用来进行部分更新的访问范围功能支持。
局限性:
- 复杂性
- 可扩展性
- 性能 部分效率不高,很多低效特性会随着高时延,低吞吐量的无线访问技术的广泛使用而变得更严重
- 传输依赖性 围绕TCP/IP网络协议栈设计,需要更多的协议栈支持才能应用于嵌入式和无线应用程序
10.2 HTTP-NG的活动
1997年启动的下一代系统HTTP-NG,1998年12月提出了一组HTTP-NG建议
10.3 模块化及功能增强
将协议模块化为三层,而不是连接管理,报文处理,服务器处理逻辑和协议方法混在一起
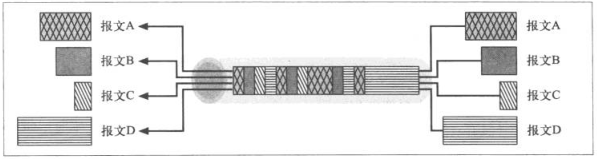
- 第一层,报文传输层 用于负责报文的高效传输和处理方面,对应为WebMUX协议
- 第二层,远程调用层 定义请求和响应功能,支持可扩展框架,本层使用二进制连接协议
- 第三层,Web应用层,提供内容管理逻辑,支持HTTP/1.1的方法,支持其他构建在远程调用基础上的服务,例如WebDAV
PNG
10.4 分布式对象
略
10.5 第一层——报文传输
只考虑报文的有效传输,不考虑报文的含义和目的,为报文传输提供API
- 对报文进行管道化和批量传化传输,降低往返时延
- 重用连接,降低时延,提高传输带宽
- 在同一条连接上并行的复用多个报文流
- 对报文进行有效分段,使报文边界确定更加容易
10.6 第二层——远程调用
提供请求/响应框架,Client通过此框架调用服务器资源
10.7 第三层——Web应用
执行语义和应用程序的逻辑
10.8 WebMUX
10.9 二进制连接协议
略,没太懂
10.10 当前状态
略

