

Elasticsearch权威指南 阅读笔记(2)分布式集群 数据
目录:
分布式集群
集群内部工作方式
ElasticSearch扩展的方式可以是纵向扩展(换好机器)和横向扩展(加机器),纵向扩展还是有一定的局限性的,真正的扩展应该是横向的,通过增加节点来分摊负载和增加可靠性
空集群
一个节点就是一个ElasticSearch实例,而一个集群由一个或多个节点组成,他们具有相同的cluster.name
集群内节点协同工作,分享数据和负载,当新加入一个节点时或者删除一个节点时,集群会感知并平衡数据。
集群内部会选举一个节点为主节点(master),负责管理集群级别的一些变更,例如新建或删除索引,增加或移除节点。主节点不参与文档级别的变更和搜索,这样在流量增长时主节点不会成为集群瓶颈。
作为用户,我们可以与集群的任意一个节点通信,每个节点都知道文档存储在哪个节点,它可以将请求转发到对应节点,我们访问的节点负责收集节点返回的数据,最后一并返回给客户端
集群健康
集群健康有三种状态,green,yellow和red
GET /_cluster/health
对一个集群查询的返回信息
{
"active_shards_percent_as_number": 50,
"task_max_waiting_in_queue_millis": 0,
"number_of_in_flight_fetch": 0,
"number_of_pending_tasks": 0,
"delayed_unassigned_shards": 0,
"unassigned_shards": 5,
"initializing_shards": 0,
"cluster_name": "elasticsearch",
"status": "yellow",
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 5,
"active_shards": 5,
"relocating_shards": 0
}
我们更关注一个status字段
status字段提供一个集群的综合指标来表示集群的状态
- green 所有主要分片和复制分片都可用
- yellow 所有主要分片可用,但是不是所有复制分片都可用
- red 不是所有主要分片都可用
添加索引
添加数据到Es中需要索引,索引是一个用来指向一个或多个分片的逻辑命名空间
一个分片(shards)是最小级别的工作单元,只保存了索引的一部分数据,每一个分片就是一个lucene实例,所以本身就是一个完整的搜索引擎。文档存储在分片中,并在分片中被索引,应用程序不会与它们之间通信,而是与索引交互
分片也是Es集群中数据分发的工具,文档存储在分片,分片再分配到集群节点上,当集群扩容或者缩容,Es会在节点间迁移分片,使集群保持平衡
分片可以是主分片(primary shard)也可以是复制分片(replica shard),每个文档属于一个单独的主分片,所以主分片数量决定了索引最多存储多少数据。理论上主分片存储没有限制,分片的最大容量取决于硬件存储,文档大小和复杂程度,如何索引和查询文档以及期望的响应时间
复制分片是主分片的一个副本,可防止硬件故障导致的数据丢失,同时可以提供读请求,比如搜索或者从别的分片取回文档
当索引创建完成,主分片的数量就固定了,但是复制分片可以随时调整,默认情况下一个索引配置5个主分片
示例创建一个3个主分片,1个复制分片(每个主分片有一个复制分片)
PUT /blogs
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
返回结果
{
"index": "blogs",
"shards_acknowledged": true,
"acknowledged": true
}
这时如果查看集群状态,可以看到为yellow,但是三个主分片已经创建启动和运行,而复制分片是不能和主分片在一个节点的,所以复制分片为unassigned状态,未分配节点
增加故障转移
可以以相同的方式启动第二个节点,第二个节点与第一个节点有相同的cluster.name,启动后新增的第二个节点会自动发现并加入到集群
新的节点加入集群后,三个复制分片也已经被分配了,意味着丢失任意一个节点的情况,依然可以保持数据完整性
横向扩展
当启动第三个节点的时候,集群会重新组织自己。
分片本身就是一个完整的搜索引擎,可以使用节点100%的资源,所以6个分片最多扩展为6个节点
继续扩展
主分片或者复制分片都可以处理读请求——搜索或文档检索,所以数据的冗余越多,我们能处理的搜索吞吐量就越大。复制分片的数量可以在运行中的集群中动态地变更,这允许我们可以根据需求扩大或者缩小规模。
复制分片的数量从原来的1增加到2
PUT /blogs/_settings
{
"number_of_replicas" : 2
}
返回结果
{
"acknowledged": true
}
在同样数量的节点上增加更多的复制分片并不能提高性能,因为这样做的话平均每个分片的所占有的硬件资源就减少了(大部分请求都聚集到了分片少的节点,导致一个节点吞吐量太大,反而降低性能),你需要增加硬件来提高吞吐量
不过这些额外的复制节点使我们有更多的冗余,使更多的节点故障而不丢失数据。
应对故障
关闭一个节点,如果是主节点,集群会选举出一个主节点,来保障功能正常。关闭节点后会有部分主分片不能正常工作,为red状态,主节点会将复制分片升级为主分片,恢复为yellow状态,这个过程是瞬间的过程。
如果再次启动对应的节点,节点上依旧有旧分片的拷贝,但是数据不是很完整,会从主分片复制在故障期间有数据变更的一部分
数据
数据吞吐
在Es中,每个字段数据都是默认被索引的,就是说每个字段专门有一个反向索引用于快速检索,与其他数据库不同,Es可以在同一个查询中利用这些所有的反向索引来返回结果
文档
什么是文档
包含键值对的JSON对象,键(key)是字段(field)或属性(property)的名字,值(value)可以是字符串、数字、布尔类型、另一个对象、值数组或者其他特殊类型,比如表示日期的字符串或者表示地理位置的对象。
示例文档
{
"name": "John Smith",
"age": 42,
"confirmed": true,
"join_date": "2014-06-01",
"home": {
"lat": 51.5,
"lon": 0.1
},
"accounts": [
{
"type": "facebook",
"id": "johnsmith"
},
{
"type": "twitter",
"id": "johnsmith"
}
]
}
文档和对象通常是等价相通的,对象是一个json结构体,而对象中可以包含对象,而文档是指最顶层结构或者跟对象序列化的json数据(以唯一Id存储在Es中)
文档元数据
文档必须包含的三个元数据
_index文档存储地方,_index类似于数据库中databases,用于存储和索引关联的数据,但是事实上数据存在在分片上,索引是把一个个分片组在一起的逻辑空间。另外索引是全部小写,不能以下划线开头,不能包含逗号,更多的在《索引》章节讲_type文档代表的对象的类,表示一类事物,定义了属性与对象关联的数据,user类可能包含姓名,性别,年龄和Email地址,对于关系型数据库就是一个table,在Es中就是type了,因为数据结构也是相同的,没有类型有自己的映射(mapping)或者结构定义,就像关系型数据库中的列一样,所有类型下的文档被存储在一个索引下,但是类型的映射(mapping)会告诉Es不同类型文档如何被索引_id文档的唯一标识,与_index和_type组合可以在Es中生成一个以为的文档标识
还有其他元数据,在《映射》中讲
索引
索引一个文档(使用自己的ID)
用法
PUT /{index}/{type}/{id}
{
"field": "value",
...
}
示例操作
curl -XPUT 'http://127.0.0.1:9200/website/blog/123' -H 'Content-type: application/json;charset=utf-8' -d '
{
"title": "My first blog entry",
"text": "Just trying this out...",
"date": "2014/01/01"
}' 2>/dev/null | jq .
响应结果
{
"_primary_term": 1,
"_seq_no": 0,
"_shards": {
"failed": 0,
"successful": 1,
"total": 2
},
"result": "created",
"_version": 1,
"_id": "123",
"_type": "blog",
"_index": "website"
}
_version是Es中文档的版本号,每当文档变化(包括删除)都会使_version增加。_version确保的是程序一部分不会覆盖另一个部分所作的修改。
索引一个文档(使用自动生成的ID)
使用Post方法即可
自动生成的ID有22个字符长
获取
检索文档
使用同样的_index、_type、_id,但是HTTP方法改为GET
GET /website/blog/123?pretty
响应结果
{
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 1,
"found" : true,
"_source" : {
"title": "My first blog entry",
"text": "Just trying this out...",
"date": "2014/01/01"
}
}
响应包含了熟悉的元数据节点,增加了_source字段,包含创建索引时的原始文档
pretty
pretty参数会让Es美化输出(pertty-print)Json响应以便更容易阅读
响应
GET请求会有{"found": true}意味文档找到了,响应状态码为200 Ok如果请求一个不存在的文档,found的值为false,响应的状态码为404 Not Found,检查文档是否存在可以先判断这个found的值。
检索文档的一部分
请求个别字段可以使用_source参数。多个字段可以使用逗号分隔:
GET /website/blog/123?_source=title,text
响应结果
{
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 1,
"exists" : true,
"_source" : {
"title": "My first blog entry" ,
"text": "Just trying this out..."
}
}
如果只要返回_source字段
GET /website/blog/123/_source
响应结果
{
"title": "My first blog entry",
"text": "Just trying this out...",
"date": "2014/01/01"
}
更新
Elasticsearch中文档是不可变的,如果需要更新已有的文档,可以重建索引或者替换文档
PUT /website/blog/123
{
"title": "My first blog entry",
"text": "I am starting to get the hang of this...",
"date": "2014/01/02"
}
响应结果
{
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 2,
"result": "update"
}
对于老的2.x版本是返回的"created": false
- created标识为false因为同索引、同类型下已经存在同ID的文档
- Es内部标记旧文档为删除并添加了一个完整的新文档,旧版本文档不会立即消失,但你也不能去访问它。Elasticsearch会在你继续索引更多数据时清理被删除的文档。
update API允许修改文档局部但是还是遵循上一条的流程
- 从旧文档中检索
- 修改文档
- 删除旧文档
- 索引新文档
唯一不同的是,update API自动完成这一过程,只需要Client的一个请求,不再需要GET和INDEX请求
创建
使用POST创建
_index、_type、_id三者唯一确定一个文档。所以要想保证文档是新加入的,最简单的方式是使用POST方法让Elasticsearch自动生成唯一_id
POST /website/blog/
使用PUT创建
对于PUT,可以自定义_id,如果文档存在就会造成就修改,可以使用参数的方式来保证文档是新加入的
PUT /website/blog/123?op_type=create
或者
PUT /website/blog/123/_create
如果请求成功就会创建一个新文档,返回正常的元数据并且响应码为201 Created
如果请求失败则会返回
{
"error" : "DocumentAlreadyExistsException[[website][4] [blog][123]:
document already exists]",
"status" : 409
}
删除
DELETE /website/blog/123
如果有对应文档,Es将会返回200 OK状态码和以下响应体
{
"found" : true,
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 3
}
_version已经发生了改变
如果文档没有找到,Es将会返回404 Not Found的状态码和以下响应体
{
"found" : false,
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 4
}
注意_version也发生了变化,这是内部记录的一部分,确保在多节点间不同操作可以有正确的顺序
删除一个文档也不会立即从磁盘上移除,它只是被标记成已删除。Elasticsearch将会在你之后添加更多索引的时候才会在后台进行删除内容的清理。
版本控制
产生冲突
当使用index的api更新文档的时候,读取原始文档,做修改,然后将整个文档一次性重新索引,最近的索引请求会生效,如果其他人同时也修改了就会不生效。
但是示例一个库存的案例,每当销售一个商品的时候,Es中的库存就要减一,但是如果多台机器操作Es,两者同时操作,就会出现修改两次但是只生效一次。
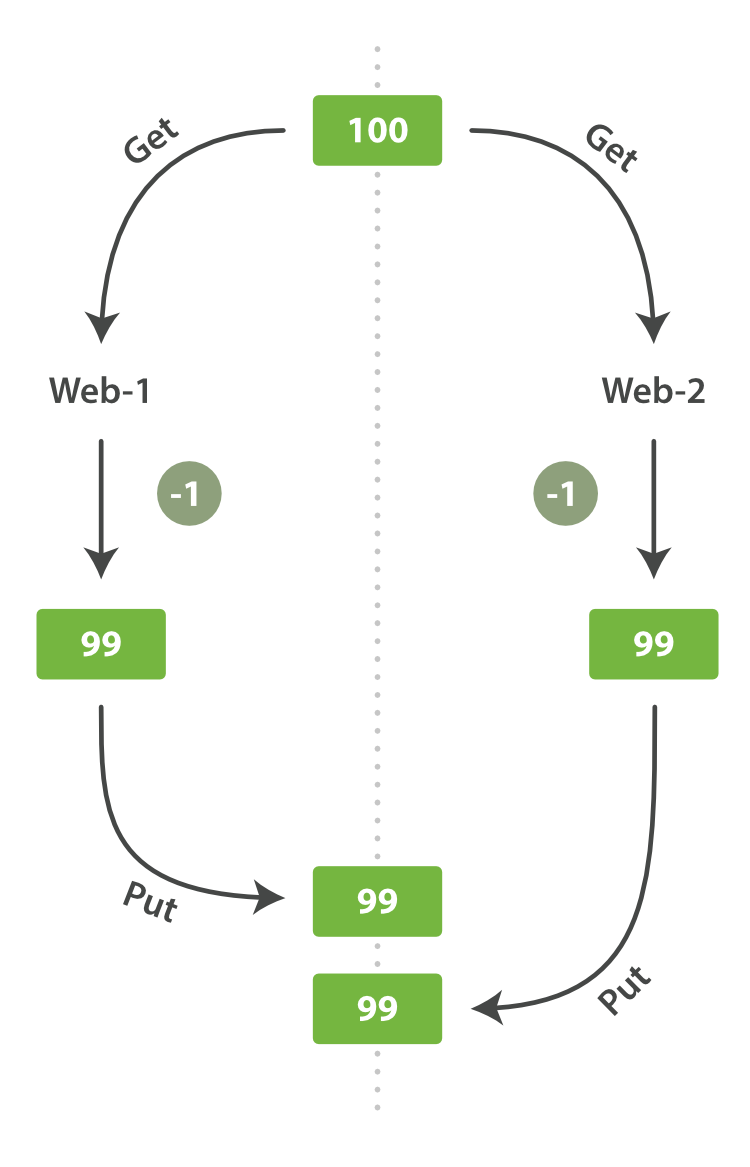
Web-1取到数据后,会减一后更新了stock_count,Web-2没有察觉到stock_count的拷贝已经过期,在Web-1更新前就拿到了数据,但是数据已经过期,也将减一后更新了stock_count,但是Web-2和Web-1的更新后结果是一样的,所以造成了实际卖出去2件变为了1件,就会认为还有更多的商品,最后顾客没有买到东西。
我们称这种情况为幻读。
悲观并发控制
假设冲突的更改经常发生,为了解决冲突我们把访问区块化。在读一行数据前锁定这行,然后确保只有加锁的那个线程可以修改这行数据。这在关系型数据库中被广泛的使用。
乐观并发控制
假设冲突不经常发生,也不区块化访问,然而,如果在读写过程中数据发生了变化,更新操作将失败。这时候由程序决定在失败后如何解决冲突。实际情况中,可以重新尝试更新,刷新数据(重新读取)或者直接反馈给用户。Elasticsearch使用的为这种情况。
对于分布式的Es,文档被创建,更新和删除,新版本都会被复制到集群的其他节点。
对于文档复制请求是平行发送,并且无需的,Es通过_version保证所有的修改都被正确排序,当一个旧版本出现在新版本之前,会被忽略
PUT /website/blog/1?version=1
{
"title": "My first blog entry",
"text": "Starting to get the hang of this..."
}
指定只在版本为1的时候更新才生效,在请求成功后_version增加到2
{
"_index": "website",
"_type": "blog",
"_id": "1",
"_version": 2
"created": false
}
如果再度执行会返回409 Conflict状态码的HTTP响应
{
"_index": "website",
"_type": "blog",
"_id": "1",
"_version": 2
"created": false
}
使用外部版本控制系统
指定外部版本号,version_type=external来使用这些版本号。版本号必须是整数,大于零小于9.2e+18——Java中的正的long。
PUT /website/blog/2?version=5&version_type=external
{
"title": "My first external blog entry",
"text": "Starting to get the hang of this..."
}
局部更新
文档局部更新
对于文档,不能被更改,只能是被替换,update API必须遵循相同的规则,处理流程依然为检索,修改,重建索引的过程
最简单的update请求表单接受一个局部文档参数doc,它会合并到现有文档中——对象合并在一起,存在的标量字段被覆盖,新字段被添加。举个例子,我们可以使用以下请求为博客添加一个tags字段和一个views字段:
POST /website/blog/1/_update
{
"doc" : {
"tags" : [ "testing" ],
"views": 0
}
}
响应
{
"_index" : "website",
"_id" : "1",
"_type" : "blog",
"_version" : 3
}
使用脚本进行局部更新
使用Groovy脚本
默认脚本语言为Groovy,一个快速且功能丰富的脚本语言,语法类似于Javascript。它在一个沙盒(sandbox)中运行,以防止恶意用户毁坏Elasticsearch或攻击服务器。
脚本能够使用update API改变_source字段的内容,它在脚本内部以ctx._source表示。例如,我们可以使用脚本增加博客的views数量
POST /website/blog/1/_update
{
"script" : "ctx._source.views+=1"
}
我们还可以使用脚本增加一个新标签到tags数组中。在这个例子中,我们定义了一个新标签做为参数而不是硬编码在脚本里。这允许Elasticsearch未来可以重复利用脚本,而不是在想要增加新标签时必须每次编译新脚本
POST /website/blog/1/_update
{
"script" : "ctx._source.tags+=new_tag",
"params" : {
"new_tag" : "search"
}
}
更新和冲突
为了避免丢失数据,update API在检索(retrieve)阶段检索文档的当前_version,然后在重建索引(reindex)阶段通过index请求提交。如果其他进程在检索(retrieve)和重建索引(reindex)阶段修改了文档,_version将不能被匹配,然后更新失败。
如果冲突了需要我们手动重试,也可以设置retry_on_conflict参数设置重试次数来自动完成,这样update操作将会在发生错误前重试——这个值默认为0。
POST /website/pageviews/1/_update?retry_on_conflict=5
{
"script" : "ctx._source.views+=1",
"upsert": {
"views": 0
}
}
对于计数操作可以使用这个。
Mget
检索多个文档
合并多个请求可以避免每个请求单独的网络开销。
mget API参数是一个docs数组,数组的每个节点定义一个文档的_index、_type、_id元数据。如果你只想检索一个或几个确定的字段,也可以定义一个_source参数:
POST /_mget
{
"docs" : [
{
"_index" : "website",
"_type" : "blog",
"_id" : 2
},
{
"_index" : "website",
"_type" : "pageviews",
"_id" : 1,
"_source": "views"
}
]
}
响应体也包含一个docs数组,每个文档包含一个响应,按照请求定义的顺序进行排列。
{
"docs" : [
{
"_index" : "website",
"_id" : "2",
"_type" : "blog",
"found" : true,
"_source" : {
"text" : "This is a piece of cake...",
"title" : "My first external blog entry"
},
"_version" : 10
},
{
"_index" : "website",
"_id" : "1",
"_type" : "pageviews",
"found" : true,
"_version" : 2,
"_source" : {
"views" : 2
}
}
]
}
如果在同一个_index甚至同一个_type可以在url中写入
POST /website/blog/_mget
{
"docs" : [
{ "_id" : 2 },
{ "_type" : "pageviews", "_id" : 1 }
]
}
这样还可以搜索_type为pageviews的文档,如果所有检索的文档都有相同的_index和_type,可以用数组ids来代替完整的docs
POST /website/blog/_mget
{
"ids" : [ "2", "1" ]
}
对于检索的文档由不存在的情况,并不会影响整体的搜索结果,每个检索都是独立的。
{
"docs" : [
{
"_index" : "website",
"_type" : "blog",
"_id" : "2",
"_version" : 10,
"found" : true,
"_source" : {
"title": "My first external blog entry",
"text": "This is a piece of cake..."
}
},
{
"_index" : "website",
"_type" : "blog",
"_id" : "1",
"found" : false <1>
}
]
}
状态码为200,因为Mget的请求完成了,即使所有的文档都没有检索到,需要检查返回的found字段
批量
更新时的批量操作
bulk API允许我们使用单一请求来实现多个文档的create、index、update或delete
bulk请求体如下
{ action: { metadata }}\n
{ request body }\n
{ action: { metadata }}\n
{ request body }\n
...
格式是用"\n"符号连接起来的一行一行的JSON文档流(stream)
注意点:
- 每行必须以"\n"符号结尾,包括最后一行。这些都是作为每行有效的分离而做的标记。
- 每一行的数据不能包含未被转义的换行符,它们会干扰分析——这意味着JSON不能被美化打印。
- action只能是create(创建文档),index(创建或更新文档),update(局部更新)和delete(删除文档)
示例删除操作
{ "delete": { "_index": "website", "_type": "blog", "_id": "123" }}
删除是不需要请求体的,create,index和update需要
index的
{ "index": { "_index": "website", "_type": "blog" }}
{ "title": "My second blog post" }
create的
{ "create": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "title": "My first blog post" }
放在一起的bluk请求
POST /_bulk
{ "delete": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "create": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "title": "My first blog post" }
{ "index": { "_index": "website", "_type": "blog" }}
{ "title": "My second blog post" }
{ "update": { "_index": "website", "_type": "blog", "_id": "123", "_retry_on_conflict" : 3} }
{ "doc" : {"title" : "My updated blog post"} }
对于所有请求都成功
{
"took": 4,
"errors": false, <1>
"items": [
{ "delete": {
"_index": "website",
"_type": "blog",
"_id": "123",
"_version": 2,
"status": 200,
"found": true
}},
{ "create": {
"_index": "website",
"_type": "blog",
"_id": "123",
"_version": 3,
"status": 201
}},
{ "create": {
"_index": "website",
"_type": "blog",
"_id": "EiwfApScQiiy7TIKFxRCTw",
"_version": 1,
"status": 201
}},
{ "update": {
"_index": "website",
"_type": "blog",
"_id": "123",
"_version": 4,
"status": 200
}}
]
}}
error为false证明所有子请求都成功
对于有请求失败
POST /_bulk
{ "create": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "title": "Cannot create - it already exists" }
{ "index": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "title": "But we can update it" }
返回结果
{
"took": 3,
"errors": true,
"items": [
{ "create": {
"_index": "website",
"_type": "blog",
"_id": "123",
"status": 409,
"error": "DocumentAlreadyExistsException
[[website][4] [blog][123]:
document already exists]"
}},
{ "index": {
"_index": "website",
"_type": "blog",
"_id": "123",
"_version": 5,
"status": 200
}}
]
}
errors为true证明存在错误,status为409 CONFLICT证明
bulk请求不是原子操作——它们不能实现事务。每个请求操作时分开的,所以每个请求的成功与否不干扰其它操作。
如果在同一个_index甚至同一个_type也是支持的
POST /website/log/_bulk
{ "index": {}}
{ "event": "User logged in" }
{ "index": { "_type": "blog" }}
{ "title": "Overriding the default type" }
整个批量请求需要被加载到接受我们请求节点的内存里,所以请求越大,给其它请求可用的内存就越小。有一个最佳的bulk请求大小。超过这个大小,性能不再提升而且可能降低。
最佳大小,当然并不是一个固定的数字。它完全取决于你的硬件、你文档的大小和复杂度以及索引和搜索的负载。幸运的是,这个最佳点(sweetspot)还是容易找到的:试着批量索引标准的文档,随着大小的增长,当性能开始降低,说明你每个批次的大小太大了。开始的数量可以在1000~5000个文档之间,如果你的文档非常大,可以使用较小的批次。通常着眼于你请求批次的物理大小是非常有用的。一千个1kB的文档和一千个1MB的文档大不相同。一个好的批次最好保持在5-15MB大小间。

