

linux系统调优
目录:
概念
进程调度
在没有操作系统的时候,是通过调用硬件规格实现。
在有了操作系统后,OS将cpu虚拟,OS本身对硬件进行抽象,我们不需要直接面对硬件,即通过系统调用方法(system call)实现,大概是300~400系统调用方法。
操作系统将cpu和内存虚拟出来,在操作系统的一个进程监视器的管理下,这些进程在运行在资源不多的cpu和内存上。由于现在的计算机计算能力强,可以几乎模拟出同时完成的现象,是并行运行的假象。
CPU通过时间片的方式进行调度,而获取CPU使用依靠优先级来实现。
进程优先级
进程通过分配到cpu的时间片实现同时运行,而优先级可以决定时间片结束之后那个进程先进入时间片,例如内核级别进行运行。
调度器也需要运行,是由进程调度子系统提供的程序,也需要时间片,所以这个调度器的效率也决定了其他进程可运行的时间。
- CFS:完全公平,当然还有很多。
- O(1)调度:和进程数无关,直接对优先级进行排队,从0~139,,140个队列,然后扫描队列首部,优先级进程高的队列中取进程放入到cpu,时间复杂度恒定。
优先级有实时优先级,0~99,静态优先级,静态优先级用过用户指定,即100~139之间nice值。而内核在根据进程使用cpu的时长调度优先级,即动态优先级。
内存
在操作系统,内存分为两部分,内核空间和用户空间。
进程看到的内存也是操作系统虚拟后的结果,只不过每个地址空间也都被分为内核空间和用户空间。
以前32位系统,PAE(物理地址扩展)架构新增了4位地址,内核启用了PAE支持,进而物理内存寻址的空间扩展到了64G内存,不过单个进程依然最多只能调用4G内存的线性地址空间,其中内核要用1G,不过解决了很多内存方面的问题。实例MySQL单进程多线程模式,但是由于32位系统限制,可用内存也不过2.7G。
对于进程需要把虚拟地址空间映射到物理地址空间,就需要对物理地址空间进行分页,为了按需调度页数据到页框中(,也就是物理地址空间中的内存被划分成了页面),每个进程可以被调入调出都被组织成页数据,所以在每个进程的线性地址空间中,只要数据可以被组织成页面形式,就从线性地址空间映射到物理地址空间的页面,而不能被页面化的数据就只能在线性地址空间,无法做线性地址空间到内存的映射,这部分被称为常驻内存集(就是只能放在内存中的),即RSS。
这些在启动的时候必须在物理内存中,而可以页面化的数据,如果页框不足时不经常使用的页就会存储到swap中,而再次使用的时候,就会产生页寻址错误——大异常和小异常。
- 大异常,这个内容不在内存,就需要从磁盘调度到内存,并返回新的内存空间,并重新建立映射关系,返回新的寻址空间。
- 小异常是动态连接的共享库的问题,进程启动的时候加载共享库到内存,而新的进程启动的也在内存中加载了这些,可能被内存删除掉了,寻址的时候没找到,在内存中发现其他进程加载到内存的共享库,重新建立寻址映射。
中断
进程在发起系统调用的时候,就触发软中断,进入内核态,进行系统调用,结束后退出后恢复用户态,这个过程会耗时,所以系统发生的系统调用越少越好,例如写日志需要写到磁盘,这需要进行系统调用,然后写入前要获取系统时间,就是系统调用。可以通过strace进行追踪。甚至可以修改源代码进行编译,减少系统调用,提高性能。
进程地址空间
对于用户
- 代码段(指令段)
- 数据段(初始化变量等,未初始化)(可能会是打开文件,先读到到内核内存,然后复制到进程内存,进而完成IO)
- 环境变量(BSS)
- 堆内存(低地址空间)
- 栈内存(高地址空间)。对于java,堆一般存放类,对象等,栈一般存放变量。
对于进程写入磁盘,需要进行系统调用,进入内核态调用内核写入然后返回才算完成,对于单进程就会堵塞(没有使用异步),只有写入完成才能。而可以优化为写入到内存就返回成功,进而由内存在内核空闲的时候写入到磁盘。不过这样内核就需要维护一个buffer和cache。
对于读取磁盘,频繁读取到内存的数据,就会缓存,进而减少了读取磁盘。
对于代码段,进程的运行就是从指令段取出,即取指,解码,运行,然后继续下一个流程。在这个过程中,cpu寄存器,在执行当前指令时,指向了下一指令的地址。因为程序就是指令和数据,对于频繁访问的数据就会存储到cpu缓存。
cpu缓存
包括一级缓存(指令集和数据缓存),一级缓存不存在,找二级缓存,二级缓存不存在就三级缓存,进而是内存。虽然cpu频率越大越好,但是一级二级缓存也至关重要。至强系列CPU就是缓存大。
内存管理单元mmu
cpu例如在完成add指令,需要两个值,这两个值是两个虚拟地址,而cpu需要转化为物理地址空间。这个转化的时候通过保存在内核态的映射关系查找,通过一级目录,二级目录,最后算偏移量,获取对应物理地址空间,这个一级目录,二级目录,偏移量的就是mmu。
转换检测缓冲区TLB
为了提高寻址速率,转换检测缓冲区(TLB)缓存mmu,这个TLB空间有限,但是如果这个命中率提高就可以提供性能,否则就会被LRU规则替换,如果不能频繁命中,反而会降低性能。对于小程序,肯定都会被命中,而对于MySQL就不一定了,一个页框4k,可能会有很多条目。所以需要加大页框,进而实现减少内存的申请,分配,条目也少了。
磁盘刷写
对于磁盘刷写频率越低性能越好,但是程序崩溃的时候,丢失的数据就越多,没有完美的优化,必须进行妥协折中,权衡来做。更多的就是时间换空间,空间换时间。
swap
swap是磁盘,在内存使用大概60%,内核就会启动swap,所有最好确保内存基本都使用了再启用swap,甚至不使用swap。禁用swap,一旦内存泄漏,就会出现很大问题。
NUMA非一致内存访问
对于多核cpu,访问内存的时候,只有一个可以写,其他可以读,意味着内存是需要加锁的,就会降低内存的性能,NUMA结构则是每个CPU有专属的内存,也尽可能访问自己的内存,毕竟效率快,但是也可以访问其他cpu的专属内存。而进程也可以通过亲缘性绑定cpu,进而提高实现cpu对进程的一级缓存二级缓存的命中率(三级缓存是共享的),进程数据载入本地内存,减少上下文切换等等。
透明大叶就是可以根据运行状态判断自动调大页框。
cpu亲缘性
对于nginx,例如8核4G,对于CPU在启动的时候就指定,系统进程只运行在其中两个,余下6个不会被调度其他进程,只跑nginx进程,硬中断也需要运行在那两个cpu上,即硬中断从那6个cpu剥离。
cpu的优化
1. 亲缘性
命令为taskset -p mask(掩码或者-c指定哪个) pid如果还需要本地内存的分配,可以使用numacat
taskset -p -c 0,1 12212
然后可以通过ps axo psr,comm,pid查看
2. cpu独享
/etc/grub.conf的kernel中添加isolcpus=2,3
3. 中断和IRQ调节
中断请求是由硬件发出,经ISR调度到每个cpu,可以参考/proc/interrupts文件,可以看到默认更多会发给cpu0。
调节直接修改/proc/irq/中断号/smp_affinity。不过不多见这种配置。
参考红帽企业版Linux6性能调节指南。
4. cpu调度算法
用户空间程序,动态优先级,使用cfs(完全公平调度)
实时进程,0-99的可以使用不同的进程调度算法,对于同一进程,适用的调度器很多,会由优先级较高的进程调度
- SCHED_FIFO先进先出用于1~99,99为优先级最大
- SCHED_RR轮询同一优先级使用也用于0~99
- SCHED_NORMAL用于100~139,100为优先级最大
- SCHED_other用于100~139
nice和renice就是调整的是动态优先级
实时优先级通过用于FIFO的chrt -f [1-99] /path/to/program arg,对于RR则使用-r参数。
例如搜索服务,建立索引的时候会消耗大量的cpu,内核根据惩罚机制会降低其优先级,但是我们要保证优先级,就可以放入实时优先级
检测性能工具
负载进程调度
- sar -p
- htop
- w
- uptime
- vmstat
cpu
- mpstat
- sar -p ALL 1 2
- iostat -c 1 2
- /proc/stat
- dstat -c
- glances
- sysdig
需要整理,原理都是/proc,/sys等接口的二次封装
内存优化
对于寻址
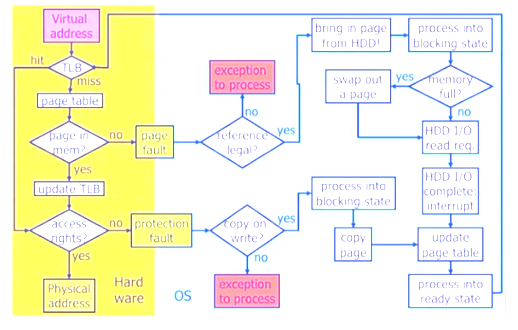
- 先查TLB,TLB命中后(hit),直接寻址
- 先查TLB,TLB未命中(miss),去查页表,判断页表是否在内存中,如果页表在内存中(yes),更新TLB,然后进行寻址
- 先查TLB,TLB未命中(miss),去查页表,判断页表是否在内存中,如果页表不在内存中(no),发生缺页异常,然后判断异常是否合法,如果不合法(no)则请求异常
- 先查TLB,TLB未命中(miss),去查页表,判断页表是否在内存中,如果页表不在内存中(no),发生缺页异常,然后判断异常是否合法,如果合法(yes)则请求异常,从硬盘加载数据到内存,进程进入堵塞状态,判断内存是否完全使用,如果内存没有空间,则交换部分内存的数据到swap中,进而写入内存,如果内存有空间,则直接写入内存,产生中断,更新页表,然后重新请求TLB
- 寻址后,获取数据是否有更改权限,触发保护异常,判断是否支持写时复制,支持则进行写时复制,然后更新页表,重新请求TLB
最后一条是因为,子进程产生的时候是复制的父进程的线性地址空间,但是没有写权限,需要写时要进行写时复制。
共享库
对于使用共享库的程序,指向的都是同一内存地址空间。
DMA
CPU和外部设备进行交互。
poll: 轮询,忙等待 中断: DMA: 用于存放同一主机对同一时间的请求,通过硬件直接连接到地址总线
大页面和透明大叶页面
内存是由块设备管理,一个页面有4096字节,1MB内存等于256个页面,1G内存为256000个页面,CPU内置内存管理单元,这些单元中包含页面列表。
增大页面可以有效的提高页面,可以使用有限的内存管理单元管理更多的内存,不过大页面只有2MB和1GB的选项,而透明大叶面可以自动创建,管理进而改善内存性能。
Valgrind简要描述内存使用
valgrind用于检测内存使用的工具,还有systemtab,oprofile
内存容量使用
内存与swap的方式
/proc/sys/vm/overcommit_memory
- 0: 默认设置,内核执行启发式内存过量使用处理,方法是估算可用内存量,并拒绝明显无效的请求,遗憾的是因为内存是使用启发式而非准确算法计算并进行部署并造成系统的可用内存超载。
- 1:内核执行无内存过量使用处理,使用这个设置会增大内存超载的可能性,但是也可以增强大量使用内存任务的性能(openstack用于超配可能就可以用这个)
- 2:内存拒绝等于或大于总可用swap大小以及overcommit_ratio指定的物理RAM比例的内存请求,这个配置用于减小内存过度使用(一般swap大于物理内存的时候推荐,不过现在哪有用swap的了)
可用内存
/proc/sys/vm/overcommit_ratio
- overcommit_memory设定为2的时候,指定考虑的物理RAM比例,默认为50
获取到的可用内存为swap+RAM*overcommit_ratio/100,例如使用4G swap和2G RAM,可用内存为5G。
内存页的数量
/proc/sys/vm/nr_hugepages
内核中超大内存页的数量,默认值为0,在调整为其他值的时候,只有在系统中有足够连续可用页时可分配的内存时才能生效。
信息队列中任意信息的最大大小
/proc/sys/kernel/msgmax
信息队列中任意信息的最大大小,默认为65535字节,即64KB
信息队列的长度最大值
/proc/sys/kernel/msgmnb
信息队列的长度最大值,默认为65535字节,即64KB
信息队列识别符的最大数量
/proc/sys/kernel/msgmni
信息队列识别符的最大数量,即维护的队列数量,64位系统默认为1985,多进程的系统就可以调高该值,例如orecle。
共享内存
/proc/sys/kernel/shmall
共享内存,64位架构下为4294967296
内核范围最大共享内存
/proc/sys/kernel/shmax
内核范围最大共享内存,64位为68719476736字节,即64G
系统范围允许使用最大共享内存片段
/proc/sys/kernel/shmin
系统范围允许使用最大共享内存片段,默认4096个
一次内核使用的最大线程(任务)数
/proc/sys/kernel/threads-max
一次内核使用的最大线程(任务)数,默认值与max_threads相同,最小为20
内核文件句柄的最大值
/proc/sys/fs/file-max
内核文件句柄的最大值,默认为8192
异步IO上下文中可以允许的最多事件数
aio-max-nr
异步IO上下文中可以允许的最多事件数,默认为65535,对于请求量高的nginx可以开启
kill进程优先级
/proc/sys/vm/panic_on_oom
在内存耗尽的时候,系统会kill掉使用内存较大的服务,而占用内存大的正是我们主要的进程。在/proc/pid目录下,有oom_adj,可通过定义-16~15的值来进行判断是否会kill掉该进程,值越大就越容易被kill,而-17就会被禁止被kill
使用swap的比率
/proc/sys/vm/swappiness
使用swap的比率,默认为60,设置为0可以基本禁用,配合/proc/sys/vm/overcommit_memory为1
写下脏数据比例
/proc/sys/vm/dirty_ratio
当脏数据占用了系统内存总数百分比值之后开始写下脏数据(写入内存而没有写入到磁盘的数据),默认为20,即磁盘刷写,过程是pdflush的内核线程完成刷写,每个磁盘启动一个该线程。越大性能越好,但是可能丢失的数据就越大。
/proc/sys/vm/dirty_background_ratio
当脏数据占用了系统内存总数百分比值之后开始写下脏数据,默认10
区别在于,dirty_ratio是单个进程,dirty_background_ratio操作系统所有进程。
缓存清除
/proc/sys/vm/drop_caches
- 1 系统无效并释放所有页缓冲内存
- 2 释放所有未使用的slab内存
- 3 释放所有页缓存和slab内存
通常情况我们生产环境是不释放内存的,最多释放第一类,而slb释放后,查找文件需要查找到文件的目录,文件,目录的inode和数据块,并建立映射关系,进行找到文件,另外这些并不能进行系统的提升,并且还会影响系统性能。
slb是一种内核的内存类型,例如文件打开的时候,文件的大小,时间戳,inode等数据(inode为128字节),不足4k一个页框,都存放在slb中,slb就是内核把页框分划成的数据结构,起到避免内存内碎片的机制。
这就是buddy system和slb system中的slb
可以参考cat /proc/slabinfo
buddy system是为了避免内存的外碎片,就是防止内存页面中每个页面之间是不连续的,导致了想要获取一块连续的内存空间时不能正常的获取到。当一些内存被频繁使用并释放,buddy会将内存合并为一个连续的内存空间,进而方式出现单独空闲的一个页框的等情况出现。
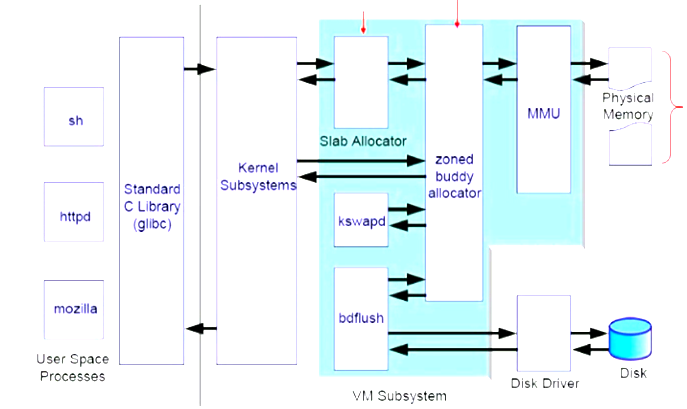
竖线分割的是左侧为用户空间,右侧为内核空间。
应用程序会提供lib库和内核进行交互,也可以直接与内核交互,slab是工作在buddy之上,内存中的脏数据通过pdflush线程调用disk驱动刷写到磁盘上,buddy借助mmu将进程的线性地址到物理地址的转换,kswapd用来实现swap功能,用于换进换出内存中的数据。
pdflush线程通过block layer的I/O scheduler(I/O调度器,负责将相同磁道或者方向上的数据进行写入,这是对于机械磁盘,而固态硬盘则是电信号,调度反而费了更多的CPU调度)
- CFQ(Completely Fair Queue),完全公平队列,为默认值
- Deadline,每一次I/O请求都设定最后写入期限,在最后写入期限前都必须写入,进而完成了每一个请求都不会被饿死
- Antiipatory,最低期望,对数据写入完后会进行等待,不过用起来并不好
- Noop,不做调度,先到先得
调度器对磁盘的写入效果微乎其微,换个固态硬盘啥的效果三四倍的提升。
IO压力测试工具
例如
- aio-stress
- iozone
- fio等
随机IO,顺序IO,随机读,随机写,顺序读,顺序写,还有不同写入类型,不过目前支持的都还不错
vmstat查看系统性能,例如,si(换入),so(换出),bi(块级别进入),bo(块级别外出),wa(io等待)
调度策略的配置在/sys/block/devices/queue/schduler,然后对于每种调度器有不同的调度参数。
cgroup则是将跟组进行划分为子组进行。
用户对于读写操作感知较多的是读请求。
可以参考cat /proc/buddyinfo
磁盘IO系统
通过内核的系统调用write(),任何写入的数据都会发往VFS file system layer文件系统层,每个被打开的文件都会在VFS中内存空间被缓存,被缓存在页缓存(page cache)中,这些页缓存,然后被BIO层接管,
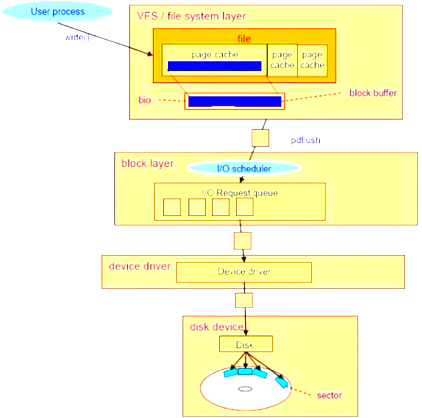
文件系统
VFS可以将底层所有文件系统包括网络文件系统进行兼容,调用的时候都只需要对VFS进行操作。
每个文件系统包括
super block,块组描述符,数据块位图,Inode位图,Inode表
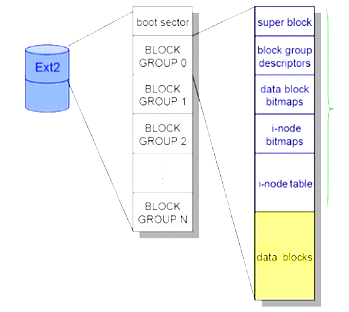
每个进程在访问文件时要先打开一个文件对象,在内存中为维持一个数据结构,通过Tnode来维持打开的文件信息,即文件描述符,每个文件都会在内存中有一个dentry object(目录项对象),每个文件文件名都需要映射到Inode上,而文件名是保存在目录之上。
对于文件在创建的时候被分配8个block的,为预留,所以一般不会产生碎片,可以通过filefrag -v file来查看文件是否被碎片化。对于文件系统中是否有碎片可以用dumpe2fs /dev/drivers实现
文件系统调优
格式化选项
- 指定块大小
- 外部日志,日志放在其他设备或专有设备上,不过丢失外部日志可能会造成文件系统死机
挂载选项
- 写入barriers,写入时内核机制,用于保证永久存储中正确写入并排列文件系统元数据信息的机制,可以保证断电的时候进行所有的数据传输,当然启动会影响一些使用fsync()的程序,例如mysql,使用nobarrier挂载选项可以进行进行barrier
- noatime,在读取的时候会更新atime,对于web服务等频繁读虽然缓存但是也需要更新atime,noatime会消除这些更新,对于relatime,会在写的时候更新atime。
- 预读支持,预读可以通过先将附加数据读取内存,提高文件的访问速度,涉及大量连续I/O的操作可以设置,这个设置对云主机是否生效呢?
blockdev -getra device和blockdev -setra N device
文件系统
ext4
- 初始化比例,-o init_itable=n,则初始化时间为1/n,默认为10
- auto-fsync行为,-o noauto da alloc
- 日志优先权,正常日志为3,普通IO为4,有效范围0~7,-o journal_ioprio=n
xfs,配置等相对ext4强
- 对于多TB的文件系统,使用inode64挂载选项
- 一般xfs格式化的时候配置就非常好了
网络系统
CP/IP协议栈模型
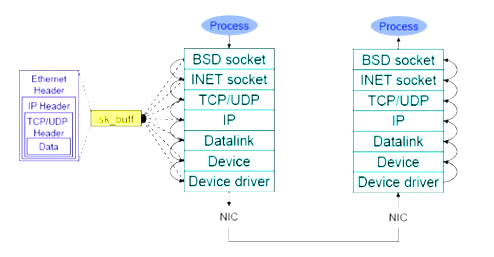
任何一个报文在网络传输都包含以太网帧,IP首部,TCP/UDP首部和数据。
发送的时候有sk_buffer,对于TCP和UDP都要基于套接字监听,通过网络来发送,socket有BSD socket和INET socket,通过TCP/UDP协议,进过IP报文。
内核参数
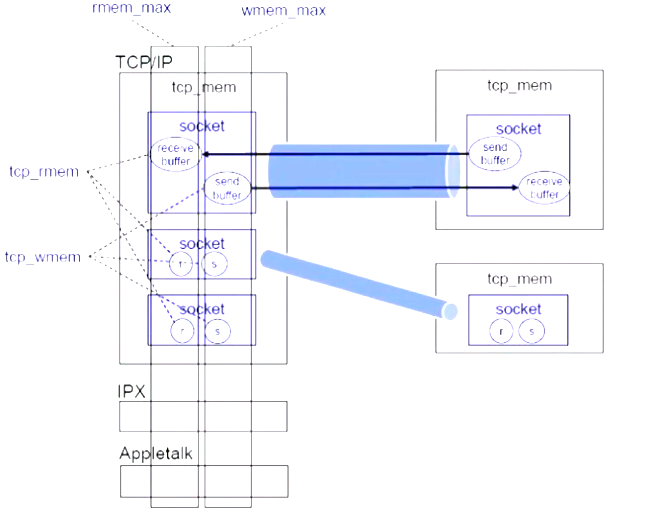
rmem_max 接收缓冲的内存空间 wmem_max 发送缓冲的内存空间 tcp_rmem receive_buffer的总和 tcp_wmem send_buffer的总和
TCP的状态
- Client端发送SYN请求,Client端为SYN_SENT状态
- Server端接收SYN请求前为LISTEN状态,接收到SYN请求会回复SYN+ACK,进而状态变为SYN_RECY
- Client端接收到SYN+ACK的包后进入ESTABLISHEN状态,并发送ACK包给Server端
- Server端接收到ACk包后会进入ESTABLISHEN状态
断开连接可以是Client端,也可是Server端
接收数据包操作(RPS)
接收流程操控
数据包接收
流程硬件缓冲NIC hardware buffer,产生内核级别的硬中断,然后出发软中断,CPU激活内核,内核找内核内存空间,把报文数据从NIC复制到socker buffer,然后通过中断复制到对应socket,进而到达应用程序。
NIC对于云主机肯定是忽略不计了。
buffer大小一般等于带宽大小延迟时间(到网关或者数据来源) 例如2Mb/s,50ms延迟,就是210的6次方5010的负三次方,为10的五次方b
man 7 socket可以看到好多好多参数
参数优化
缓冲区
- /proc/sys/net/core/rmem_default 接收缓冲默认大小
/proc/sys/net/core/rmem_max
/proc/sys/net/core/wmem_default 发送缓冲默认大小
- /proc/sys/net/core/wmem_max
TCP滑动窗口
- /proc/sys/net/core/tcp_window_scaling TCP滑动窗口,开启即可
针对TCP协议
- /proc/sys/net/ipv4/tcp_mem其下三个参数,min,default和max
分片重组缓冲大小
分片重组缓冲大小,因为mtu值不同可能会进行数据包分分片或者重组
/proc/sys/net/ipv4/ipfrag_high_thresh,用于TCP分片重组的最大值 /proc/sys/net/ipv4/ipfrag_low_thresh /proc/sys/net/ipv4/ipfrag_time 等待超时时长,默认30s完全没有问题
netstat -s或者cat /proc/net/snmp | grep '^Ip:' | cut -f17 -d ''
重用TCP连接队列
/proc/sys/net/ipv4/tcp_tw_reuse 是否允许重用TIME_WAIT状态的socket连接处理请求,用于大量TCP连接时迅速响应
syn队列
tcp_syncookies 当syn队列溢出并且backlog队列溢出时,发送syncookies
TCP孤儿进程数
tcp_max_orphans tcp孤儿进程能出现的最多值,tcp套接字打开但没能在内核申请到文件描述符的情况,用于防御dos攻击而来不及打开文件的情况
FIN-WAIT-2的时长
tcp_fin_timeout 处于FIN-WAIT-2的时长,一般是keepalived的情况下,出现这个情况,防止长时间收到fin报文,可以为1s。
TIME_WAIT状态套接字数量
tcp_max_tw_buckets 内核中允许持有TIME_WAIT状态的套接字数量,增大也可以防止dos
listen状态的backlog队列
net/core/somaxconn 处于listen状态的backlog队列,一般不用调整
网卡配置
netdev_max_backlog 网卡配置,一般也不用调整
用于响应的端口范围
ip_local_port_range 用于响应的端口范围,每一个用于请求连接都需要一个连接套接字来响应请求。可设1024 65000
端口预留
net.ipv4.ip_local_reserved_ports = 8012,11211-11220 与上面一致,但是在那个基础上进行预留
TIME_WAIT快速回收
tcp_tw_recycle TIME_WAIT快速回收
TCP时间戳
tcp_timestamps 将TCP连接的时间戳取消,防止32位序列号进行卷绕,下载服务器等有大量数据传输,可调整为0
syn包重试次数
tcp_synack_retries synack包重试次数,可设置为1,可以防止syn攻击
TCP会话保持时间
tcp_keepalived_time 保持时间,不建议调整
更多可以参考红帽企业版Linux6性能调节指南

