

人生苦短,我用Python04:模块
目录:
Python模块
什么是模块
模块和函数的目的是一样的,都是为了提高程序的重复可用性。
如何导入模块
最简单的导入方式
import a #引入模块a
成功导入后就可以使用a模块中对象或方法。
更多模块导入方式
import a as b #引入模块a,并将模块a重命名为b,在调用的时候直接调用b即可
from a import b #从模块a中引入b对象,在调用a中的b对象的时候,不需要说明模块,直接使用b即可,而不是a.b
from a import * #从模块a中引入所有对象
if __name__ == "__main__"的作用
有句经典话总结了这个的作用——"Make a script both importable and executable",意思就是说让你写的脚本模块既可以导入到别的模块中用,另外该模块自己也可执行。
执行模块
[root@why ~]# vi module.py
[root@why ~]# cat module.py
def main():
print "This is %s"%__name__
if __name__ == '__main__':
main()
[root@why ~]# python module.py
This is __main__
可以看到这个main()方法被执行了,因为__name__为"__main__"
导入模块
[root@why ~]# vi testmodule.py
[root@why ~]# cat testmodule.py
import module
module.main()
[root@why ~]# python testmodule.py
This is module
在导入的时候,main没有被执行,而是用过我们执行,此时__name__为module
模块搜索路径
- 程序当前所在路径
- 标准库安装路径
- 操作系统环境变量PYTHONPATH所包含的路径
如何成为一个库
可以将功能相似的模块放在同一个文件夹(比如说this_dir)中,构成一个模块包。通过
import this_dir.module
引入this_dir文件夹中的module模块。
该文件夹中必须包含一个__init__.py的文件,提醒Python,该文件夹为一个模块包。__init__.py可以是一个空文件。
如何安装一个模块
- 把py文件直接拷贝到模块的搜索路径,当然要有py文件,并且保证版本问题
- 源码安装,需要提前安装setuptools
- easy_install或pip方式安装
常用模块
time模块
等待5s
time.sleep(5) 单位为秒
进度条
from __future__ import division
import sys,time
for i in range(31):
sys.stdout.write('\r')
sys.stdout.write('%s%% |%s' % (int(i/30*100),int(i/30*100)*'*'))
sys.stdout.flush()
time.sleep(0.2)
执行结果
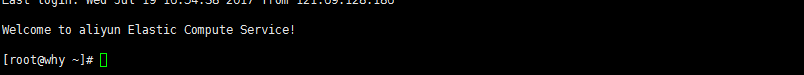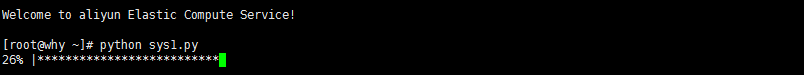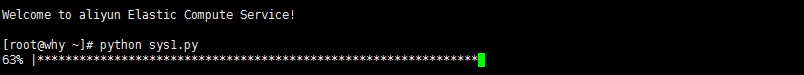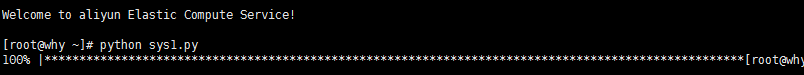
当前时间戳
>>> import time
>>> time.time()
1498313313.0996261
当前时间(由时间戳转化为时间)
>>> time.ctime()
'Sat Jun 24 22:08:39 2017'
>>> time.ctime(time.time())
'Sat Jun 24 22:09:03 2017'
>>> time.ctime(time.time()-86400)
'Fri Jun 23 22:09:10 2017'
时间戳转化为时间
>>> time.gmtime(time.time()) #转换为UTC时间
time.struct_time(tm_year=2017, tm_mon=6, tm_mday=24, tm_hour=14, tm_min=37, tm_sec=19, tm_wday=5, tm_yday=175, tm_isdst=0)
>>> time.localtime(time.time()) #转换为当前时区时间
time.struct_time(tm_year=2017, tm_mon=6, tm_mday=24, tm_hour=22, tm_min=37, tm_sec=24, tm_wday=5, tm_yday=175, tm_isdst=0)
>>> now = time.localtime(time.time())
>>> print(now.tm_year)
2017
时间转化为时间戳
>>> time.mktime(time.localtime())
1498315333.0
格式化时间
>>> time.strftime('%Y-%m-%d %H:%M:%S',time.localtime())
'2017-06-24 22:47:36'
>>> time.strptime('2017-06-24','%Y-%m-%d')
time.struct_time(tm_year=2017, tm_mon=6, tm_mday=24, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=5, tm_yday=175, tm_isdst=-1)
datetime模块
显示时间
>>> import datetime
>>> print(datetime.date.today())
2017-06-24
>>> print(datetime.date.fromtimestamp(time.time()))
2017-06-24
时间转换
>>> print(datetime.datetime.now())
2017-06-24 22:54:31.145610
>>> print(datetime.datetime.now().timetuple())
time.struct_time(tm_year=2017, tm_mon=6, tm_mday=24, tm_hour=23, tm_min=23, tm_sec=30, tm_wday=5, tm_yday=175, tm_isdst=-1)
>>> print(datetime.datetime.now().replace())
2017-06-24 23:26:09.277628
>>> print(datetime.datetime.now().replace(1994,4,16))
1994-04-16 23:26:24.975626
>>> print(datetime.datetime.strptime('16/04/1994 10:20','%d/%m/%Y %H:%M'))
1994-04-16 10:20:00
时间加减
>>> print(datetime.datetime.now() + datetime.timedelta(days=-1))
2017-07-03 19:28:49.459909
>>> print(type(datetime.datetime.now() + datetime.timedelta(days=-1)))
<type 'datetime.datetime'>
参数定义有这些可选项,默认为0
def __new__(cls, days=0, seconds=0, microseconds=0,
miliseconds=0, minutes=0, hours=0, weeks=0);
sys模块
- __name__ 对于主文件,__name__ == "__main__",对于导入的时候,__name__就是模块名
- __doc__ python文件注释
- __file__ 文件本身的路径
- __package__ 对于单独文件,为None
- __cache__ 文件缓存的内容,为python3独有,输出可以看到是pyc文件的路径。
- __builtins__ 内置函数
描述文档
>>> def func():
... """This is doc"""
... pass
...
>>> func.__doc__
'This is doc'
文件本身路径的用途
(env35) [root@why ~]# python /root/aa.py
/root
['/root', '/root/env35/lib/python35.zip', '/root/env35/lib/python3.5', '/root/env35/lib/python3.5/plat-linux', '/root/env35/lib/python3.5/lib-dynload', '/opt/python-3.5.0/lib/python3.5', '/opt/python-3.5.0/lib/python3.5/plat-linux', '/root/env35/lib/python3.5/site-packages', '/root/bin']
(env35) [root@why ~]# python aa.py
['/root', '/root/env35/lib/python35.zip', '/root/env35/lib/python3.5', '/root/env35/lib/python3.5/plat-linux', '/root/env35/lib/python3.5/lib-dynload', '/opt/python-3.5.0/lib/python3.5', '/opt/python-3.5.0/lib/python3.5/plat-linux', '/root/env35/lib/python3.5/site-packages', 'bin']
文件所在目录
>>> import re
>>> print(re.__package__)
None
传入脚本参数
sys.argv是传递进来的参数,和shell脚本参数一样。
[root@why ~]# cat test.py
import sys
print(sys.argv)
[root@why ~]# python test.py parameter1 parameter2
['test.py', 'parameter1', 'parameter2']
模块搜素目录
>>> import sys
>>> print(sys.path)
['', '/usr/lib64/python2.6/site-packages/MySQL_python-1.2.3c1-py2.6-linux-x86_64.egg', '/usr/lib/python2.6/site-packages/cloud_init-0.7.6-py2.6.egg', '/usr/lib/python2.6/site-packages/jsonpatch-1.13-py2.6.egg', '/usr/lib/python2.6/site-packages/requests-2.9.1-py2.6.egg', '/usr/lib/python2.6/site-packages/argparse-1.4.0-py2.6.egg', '/usr/lib/python2.6/site-packages/Jinja2-2.8-py2.6.egg', '/usr/lib/python2.6/site-packages/jsonpointer-1.10-py2.6.egg', '/usr/lib/python2.6/site-packages/six-1.10.0-py2.6.egg', '/usr/lib/python2.6/site-packages/AliyunUtil-0.0.1-py2.6.egg', '/usr/lib/python2.6/site-packages/pip-1.5.4-py2.6.egg', '/usr/lib64/python26.zip', '/usr/lib64/python2.6', '/usr/lib64/python2.6/plat-linux2', '/usr/lib64/python2.6/lib-tk', '/usr/lib64/python2.6/lib-old', '/usr/lib64/python2.6/lib-dynload', '/usr/lib64/python2.6/site-packages', '/usr/lib64/python2.6/site-packages/gtk-2.0', '/usr/lib/python2.6/site-packages', '/usr/lib/python2.6/site-packages/setuptools-0.6c11-py2.6.egg-info']
首位为'',代表当前目录
不过在pycharm中,pycharm会默认把项目目录也加入到模块的路径中,我就经历过pycharm中代码正常运行,而放到linux环境就因为这个问题报错
['F:\\MyPython\\testsyspath', 'F:\\MyPython', 'C:\\Windows\\system32\\python27.zip', 'C:\\Python27\\DLLs', 'C:\\Python27\\lib', 'C:\\Python27\\lib\\plat-win', 'C:\\Python27\\lib\\lib-tk', 'C:\\Python27', 'C:\\Python27\\lib\\site-packages']
添加库
>>> sys.path.append('/etc/nginx')
>>> print(sys.path)
['', '/usr/lib64/python2.6/site-packages/MySQL_python-1.2.3c1-py2.6-linux-x86_64.egg', '/usr/lib/python2.6/site-packages/cloud_init-0.7.6-py2.6.egg', '/usr/lib/python2.6/site-packages/jsonpatch-1.13-py2.6.egg', '/usr/lib/python2.6/site-packages/requests-2.9.1-py2.6.egg', '/usr/lib/python2.6/site-packages/argparse-1.4.0-py2.6.egg', '/usr/lib/python2.6/site-packages/Jinja2-2.8-py2.6.egg', '/usr/lib/python2.6/site-packages/jsonpointer-1.10-py2.6.egg', '/usr/lib/python2.6/site-packages/six-1.10.0-py2.6.egg', '/usr/lib/python2.6/site-packages/AliyunUtil-0.0.1-py2.6.egg', '/usr/lib/python2.6/site-packages/pip-1.5.4-py2.6.egg', '/usr/lib64/python26.zip', '/usr/lib64/python2.6', '/usr/lib64/python2.6/plat-linux2', '/usr/lib64/python2.6/lib-tk', '/usr/lib64/python2.6/lib-old', '/usr/lib64/python2.6/lib-dynload', '/usr/lib64/python2.6/site-packages', '/usr/lib64/python2.6/site-packages/gtk-2.0', '/usr/lib/python2.6/site-packages', '/usr/lib/python2.6/site-packages/setuptools-0.6c11-py2.6.egg-info', '/etc/nginx']
os模块
| 方法 | 描述 |
|---|---|
| os.getcwd() | 获取当前工作目录,即当前python脚本工作的目录路径 |
| os.chdir("dirname") | 改变当前脚本工作目录;相当于shell下cd |
| os.curdir | 返回当前目录: ('.') |
| os.pardir | 获取当前目录的父目录字符串名:('..') |
| os.makedirs('dir1/dir2') | 可生成多层递归目录 |
| os.removedirs('dirname1') | 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 |
| os.mkdir('dirname') | 生成单级目录;相当于shell中mkdir dirname |
| os.rmdir('dirname') | 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname |
| os.listdir('dirname') | 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 |
| os.remove() | 删除一个文件 |
| os.rename("oldname","new") | 重命名文件/目录 |
| os.stat('path/filename') | 获取文件/目录信息 |
| os.sep | 操作系统特定的路径分隔符,win下为"\",Linux下为"/" |
| os.linesep | 当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" |
| os.pathsep | 用于分割文件路径的字符串 |
| os.name | 字符串指示当前使用平台。win->'nt'; Linux->'posix' |
| os.system("bash command") | 运行shell命令,直接显示 |
| os.environ | 获取系统环境变量 |
| os.path.abspath(path) | 返回path规范化的绝对路径 |
| os.path.split(path) | 将path分割成目录和文件名二元组返回 |
| os.path.dirname(path) | 返回path的目录。其实就是os.path.split(path)的第一个元素 |
| os.path.basename(path) | 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 |
| os.path.exists(path) | 如果path存在,返回True;如果path不存在,返回False |
| os.path.isabs(path) | 如果path是绝对路径,返回True |
| os.path.isfile(path) | 如果path是一个存在的文件,返回True。否则返回False |
| os.path.isdir(path) | 如果path是一个存在的目录,则返回True。否则返回False |
| os.path.join(path1[, path2[, ...]]) | 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 |
| os.path.getatime(path) | 返回path所指向的文件或者目录的最后存取时间 |
| os.path.getmtime(path) | 返回path所指向的文件或者目录的最后修改时间 |
pickle模块
pickle模块可以将列表,数组等转换成字符串,进而存储到文件,或者从文件中读取字典,列表的字符串,将其转化为列表或字典
字典转换为字符串
import pickle
accounts={'b':2}
f = open('account.db','wb')
f.write(pickle.dumps(accounts))
f.close()
字符串转换为字典
import pickle
f = open('account.db','rb')
account_dic = pickle.loads(f.read())
f.close()
print(account_dic['b'])
更简洁的直接操作文件
import pickle
accounts={'c':3}
with open('account.db','wb') as f:
pickle.dump(accounts,f)
和
import pickle
with open('account.db','rb') as f:
account_dic = pickle.load(f)
print(account_dic['c'])
json模块
首先json模块支持上述四种dump,dumps,load和loads。
有时候可能需要进行字节的传递,在可以通过bytes处理
f.write(bytes(json.dumps(accounts),encoding='utf-8'))
和
account_dic = json.loads(f.read().decode('utf-8'))
pickle支持所有格式,但是只能在python中使用,而json格式只能处理列表,字典,但是json格式可以用于和其他语言交互
在python中,单引号是字符串,双引号也是字符串,但是在其他语言中,双引号一定是字符串,而单引号却不一定是,但是json处理字符串的时候,字符串一定要用双引号,外边是单引号,三引号都行。
浏览器返回的都是字符串,http请求的响应也都是字符串,跨平台一般都是使用json
hashlib模块
提供SHA1,SHA224,SHA256,SHA384,SHA512,MD5算法
md5加密密码
import hashlib
hash = hashlib.md5()
hash.update(bytes('123456'))
print(hash.hexdigest())
以上代码适用于python2.7,对于python3使用一下代码
import hashlib
hash = hashlib.md5()
hash.update(bytes('123456',encoding='utf-8'))
print(hash.hexdigest())
执行结果
e10adc3949ba59abbe56e057f20f883e
md5不可反解,就是说无法通过加密后的结果反推加密前,但是可以通过撞库的方式来实现,就是通过频繁的通过明文进行md5加密,然后获取明文与密文的对应关系。
不过也提供了用于加密防止撞库的方式来获取对应关系的方式
传参进行md5加密
import hashlib
hash = hashlib.md5('why')
hash.update(bytes('123456'))
print(hash.hexdigest())
执行结果
80ae50b4a97d1aac94343c1e7669801f
用于加密的hmac
python也自带一个hmac模块用于加密
import hmac
h = hmac.new('why')
h.update(bytes('123456'))
print(h.hexdigest())
执行结果
002d1aaff2b485e22f2235b104282eea
xml模块
测试代码
[root@why ~]# cat test.xml
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2023</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2026</year>
<gdppc>59900</gdppc>
<neighbor direction="N" name="Malaysia" />
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2026</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
</data>
xml解析
[root@why ~]# cat test.py
from xml.etree import ElementTree as ET
# create ElementTree object
root = ET.XML(open('test.xml','r').read())
print(root.tag)
for node in root:
print(node,type(node))
print(node.tag,node.attrib,node.find('rank').text)
[root@why ~]# python test.py
data
(<Element country at 7f5bcbc60440>, <type 'instance'>)
('country', {'name': 'Liechtenstein'}, '2')
(<Element country at 7f5bcbc605f0>, <type 'instance'>)
('country', {'name': 'Singapore'}, '5')
(<Element country at 7f5bcbc60758>, <type 'instance'>)
('country', {'name': 'Panama'}, '69')
tag获取的<>中的tag,而attrib获取的<>中的等式,返回值为字典,text获取的是<>和<>之间的内容,find则是在其子节点进行查询。
修改xml文件内容
python3中的iter()
(env35) [root@why ~]# cat test.py
from xml.etree import ElementTree as ET
tree = ET.parse("test.xml")
root = tree.getroot()
#for node in root.iter('year'):
for node in root.getiterator('year'):
new_year = int(node.text) + 1
node.text = str(new_year)
tree.write("test.xml")
(env35) [root@why ~]# python test.py
(env35) [root@why ~]# cat test.xml
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2024</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2027</year>
<gdppc>59900</gdppc>
<neighbor direction="N" name="Malaysia" />
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2027</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
python2中的getiterator()
[root@why ~]# cat test.py
from xml.etree import ElementTree as ET
tree = ET.parse("test.xml")
root = tree.getroot()
#for node in root.iter('year'):
for node in root.getiterator('year'):
new_year = int(node.text) + 1
node.text = str(new_year)
tree.write("test.xml")
[root@why ~]# python test.py
[root@why ~]# cat test.xml
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2025</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2028</year>
<gdppc>59900</gdppc>
<neighbor direction="N" name="Malaysia" />
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2028</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
</data>
python3中的getiterator()
(env35) [root@why ~]# python test.py
(env35) [root@why ~]# cat test.py
from xml.etree import ElementTree as ET
tree = ET.parse("test.xml")
root = tree.getroot()
#for node in root.iter('year'):
for node in root.getiterator('year'):
new_year = int(node.text) + 1
node.text = str(new_year)
tree.write("test.xml")
(env35) [root@why ~]# cat test.xml
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2026</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2029</year>
<gdppc>59900</gdppc>
<neighbor direction="N" name="Malaysia" />
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2029</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
</data>(env35)
xml添加内容
(env35) [root@why ~]# cat test.py
from xml.etree import ElementTree as ET
tree = ET.parse("test.xml")
root = tree.getroot()
for node in root.iter('year'):
#for node in root.getiterator('year'):
# new_year = int(node.text) + 1
# node.text = str(new_year)
node.set('name','why')
tree.write("test.xml")
(env35) [root@why ~]# python test.py
(env35) [root@why ~]# cat test.xml
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year name="why">2026</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year name="why">2029</year>
<gdppc>59900</gdppc>
<neighbor direction="N" name="Malaysia" />
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year name="why">2029</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
xml其他方法
print(dir(root))
['__class__', '__copy__', '__deepcopy__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getstate__', '__gt__', '__hash__', '__init__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setitem__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'extend', 'find', 'findall', 'findtext', 'get', 'getchildren', 'getiterator', 'insert', 'items', 'iter', 'iterfind', 'itertext', 'keys', 'makeelement', 'remove', 'set']
random
生成验证码
import random
temp = ''
for i in range(6):
num = random.randrange(0,4)
if num >= 2:
rad2 = random.randrange(0,10)
temp = temp + str(rad2)
else:
rad1 = random.randrange(65,91)
c1 = chr(rad1)
temp = temp + c1
print(temp)
生成随机id
def get_id(cls, title="rid", length=8):
"""
生成固定长度随机字符串。
:param title:
字符串头
:param length:
字符串长度。
:return:
string
"""
str = "abcdefghijklmnopqrstuvwxyz0123456789"
return title + '-' + ''.join(random.sample(str, length))
configparser
configparser是一个读写固定格式的配置文件的方法
首先要注意的是配置文件中获取出来的都是字符串格式
(env35) [root@why ~]# cat test.ini
# 注释
; 注释
[why] #节点
name = wanghongyu
age : 23
[pqt] #节点
name = panqiutong
获取所有节点
(env35) [root@why ~]# cat testconf.py
# -*- coding:utf-8 -*-
import configparser
con = configparser.ConfigParser()
con.read("test.ini")
a = []
result = con.sections()
print(result)
(env35) [root@why ~]# python testconf.py
['why', 'pqt']
获取所有key
(env35) [root@why ~]# vi testconf.py
# -*- coding:utf-8 -*-
import configparser
con = configparser.ConfigParser()
con.read("test.ini")
a = []
ret = con.options("why")
print(ret)
执行结果
(env35) [root@why ~]# python testconf.py
['name', 'age']
获取所有键值对
ret = con.items("why")
print(ret)
执行结果
[('name', 'wanghongyu'), ('age', '23')]
获取指定配置
ret = con.get("why","age")
print(ret,type(ret))
执行结果
23 <class 'str'>
监测section是否存在
ret = con.has_section("why")
print(ret)
执行结果
True
添加section
con.add_section("mb")
con.write(open("test.ini","w"))
(env35) [root@why ~]# python testconf.py
(env35) [root@why ~]# cat test.ini
[why]
name = wanghongyu
age = 23
[pqt]
name = panqiutong
[mb]
可以看到注释已经没有
删除section
con.remove_section("mb")
con.write(open("test.ini","w"))
对内部配置处理的
config.has_option('section', 'k1') #检查
remove_option('section', 'k1') #删除
set('section', 'k10', "123") #设置
requests模块
logging模块
import logging
logging.basicConfig(filename='test.log',
format='%(asctime)s - %(name)s - %(levelname)s - %(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
level=10,
)
logging.error("This is test error!")
执行结果
2017-07-05 19:04:51 PM - root - ERROR - testlogging: This is test error!
logging.basicConfig函数各参数:
- filename: 指定日志文件名
- filemode: 和file函数意义相同,指定日志文件的打开模式,'w'或'a'
- format: 指定输出的格式和内容
- datefmt: 指定时间格式,同time.strftime()
- level: 设置日志级别,默认为logging.WARNING
- stream: 指定将日志的输出流,可以指定输出到sys.stderr,sys.stdout或者文件,默认输出到sys.stderr,当stream和filename同时指定时,stream被忽略
format可以输出很多有用信息,如上例所示:
- %(levelno)s: 打印日志级别的数值
- %(levelname)s: 打印日志级别名称
- %(pathname)s: 打印当前执行程序的路径,其实就是sys.argv[0]
- %(filename)s: 打印当前执行程序名
- %(funcName)s: 打印日志的当前函数
- %(lineno)d: 打印日志的当前行号
- %(asctime)s: 打印日志的时间
- %(thread)d: 打印线程ID
- %(threadName)s: 打印线程名称
- %(process)d: 打印进程ID
- %(message)s: 打印日志信息
各个级别代表的值
- CRITICAL = 50
- FATAL = CRITICAL
- ERROR = 40
- WARNING = 30
- WARN = WARNING
- INFO = 20
- DEBUG = 10
- NOTSET = 0
shutil
拷贝文件内容
import shutil
shutil.copyfileobj(open('old.xml','r'), open('new.xml', 'w'))
拷贝文件
shutil.copyfile('f1.log', 'f2.log')
拷贝文件的内容,组,用户不变
shutil.copymode('f1.log', 'f2.log')
拷贝权限
shutil.copystat('f1.log', 'f2.log')
拷贝文件和权限
shutil.copy(src, dst)
递归拷贝文件夹
shutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc', 'tmp*'))
ignore=shutil.ignore_patterns('*.pyc', 'tmp*')代表忽略*.pyc和tmp*文件
递归删除文件夹
shutil.rmtree('folder1')
递归移动文件或文件夹(等效linux的mv)
shutil.move('folder1', 'folder3')
创建压缩包
import shutil
ret = shutil.make_archive("/home/why/whytest", 'gztar', root_dir='/home/why/test')
base_name,format,root_dir,还有owner,group和logger
format是压缩的种类,有zip,tar,bztar和gztar
实质调用的是
import zipfile
# 压缩
z = zipfile.ZipFile('why.zip', 'w')
z.write('a.log')
z.write('data.data')
z.close()
# 解压
z = zipfile.ZipFile('why.zip', 'r')
z.extractall()
z.close()
和
import tarfile
# 压缩
tar = tarfile.open('your.tar','w')
tar.add('/Users/wupeiqi/PycharmProjects/bbs2.log', arcname='bbs2.log')
tar.add('/Users/wupeiqi/PycharmProjects/cmdb.log', arcname='cmdb.log')
tar.close()
# 解压
tar = tarfile.open('your.tar','r')
tar.extractall() # 可设置解压地址
tar.close()
zipfile还有namelist显示压缩包内容,extract解压出来单独文件的操作
paramiko
paramiko是一个远程控制模块,fabric和ansible内部就是通过paramiko来实现的
连接远程执行命令
#!/usr/bin/env python
#coding:utf-8
import paramiko
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect('192.168.1.108', 22, 'why', '123')
stdin, stdout, stderr = ssh.exec_command('df')
print stdout.read()
ssh.close();
通过私钥方式
import paramiko
private_key_path = '/home/auto/.ssh/id_rsa'
key = paramiko.RSAKey.from_private_key_file(private_key_path)
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect('主机名 ', 端口, '用户名', key)
stdin, stdout, stderr = ssh.exec_command('df')
print stdout.read()
ssh.close()
上传下载文件
上传
import os,sys
import paramiko
t = paramiko.Transport(('182.92.219.86',22))
t.connect(username='wupeiqi',password='123')
sftp = paramiko.SFTPClient.from_transport(t)
sftp.put('/tmp/test.py','/tmp/test.py')
t.close()
下载
import os,sys
import paramiko
t = paramiko.Transport(('182.92.219.86',22))
t.connect(username='wupeiqi',password='123')
sftp = paramiko.SFTPClient.from_transport(t)
sftp.get('/tmp/test.py','/tmp/test2.py')
t.close()
通过私钥方式上传和下载文件
上传
import paramiko
pravie_key_path = '/home/auto/.ssh/id_rsa'
key = paramiko.RSAKey.from_private_key_file(pravie_key_path)
t = paramiko.Transport(('182.92.219.86',22))
t.connect(username='wupeiqi',pkey=key)
sftp = paramiko.SFTPClient.from_transport(t)
sftp.put('/tmp/test3.py','/tmp/test3.py')
t.close()
下载
import paramiko
pravie_key_path = '/home/auto/.ssh/id_rsa'
key = paramiko.RSAKey.from_private_key_file(pravie_key_path)
t = paramiko.Transport(('182.92.219.86',22))
t.connect(username='wupeiqi',pkey=key)
sftp = paramiko.SFTPClient.from_transport(t)
sftp.get('/tmp/test3.py','/tmp/test4.py')
t.close()

