

prometheus监控kubernetes原理解析
目录:
prometheus
本文参考Prometheus 入门与实践
prometheus简介
Prometheus是一套开源的系统监控报警框架
特点:
- 强大的多维度数据模型:
- 时间序列数据通过metric名和键值对来区分
- 所有的metrics都可以设置任意的多维标签
- 数据模型更随意,不需要刻意设置为以点分隔的字符串
- 可以对数据模型进行聚合,切割和切片操作
- 支持双精度浮点类型,标签可以设为全unicode
- 灵活而强大的查询语句(PromQL):在同一个查询语句,可以对多个 metrics 进行乘法、加法、连接、取分数位等操作
- 易于管理: Prometheus server 是一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储
- 高效:平均每个采样点仅占
3.5 bytes,且一个Prometheus server可以处理数百万的metrics - 使用pull模式采集时间序列数据,这样不仅有利于本机测试而且可以避免有问题的服务器推送坏的metrics
- 可以采用
push gateway的方式把时间序列数据推送至Prometheus server端 - 可以通过服务发现或者静态配置去获取监控的targets
- 有多种可视化图形界面
- 易于伸缩
需要指出的是,由于数据采集可能会有丢失,所以 Prometheus 不适用对采集数据要 100% 准确的情形。但如果用于记录时间序列数据,Prometheus 具有很大的查询优势,此外,Prometheus 适用于微服务的体系架构。
Prometheus组成及架构
Prometheus生态圈中包含了多个组件,其中许多组件是可选的:
- Prometheus Server: 用于收集和存储时间序列数据。
- Client Library: 客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
- Push Gateway: 主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus server 端推送它们的 metrics。这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。
- Exporters: 用于暴露已有的第三方服务的 metrics 给 Prometheus。
- Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook 等。
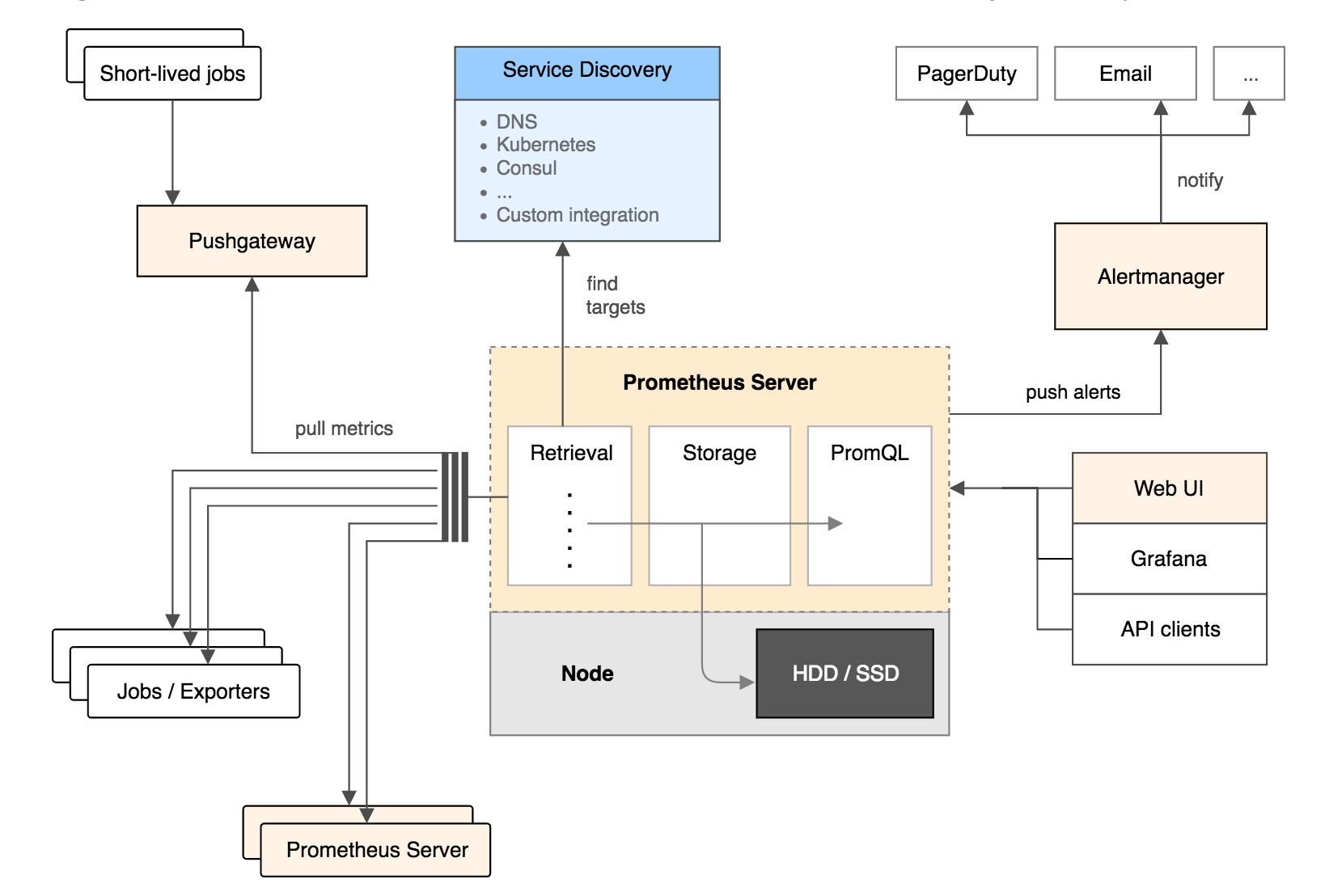
Prometheus的主要模块包括:Prometheus server, exporters, Pushgateway, PromQL, Alertmanager 以及图形界面。
其大概的工作流程是:
- Prometheus server 定期从配置好的 jobs 或者 exporters 中拉 metrics,或者接收来自 Pushgateway 发过来的 metrics,或者从其他的 Prometheus server 中拉 metrics。
- Prometheus server 在本地存储收集到的 metrics,并运行已定义好的 alert.rules,记录新的时间序列或者向 Alertmanager 推送警报。
- Alertmanager 根据配置文件,对接收到的警报进行处理,发出告警。
- 在图形界面中,可视化采集数据。
Prometheus相关概念
数据模型
Prometheus中存储的数据为时间序列,是由 metric 的名字和一系列的标签(键值对)唯一标识的,不同的标签则代表不同的时间序列。
- metric名字:该名字应该具有语义,一般用于表示 metric 的功能,例如:http_requests_total, 表示 http 请求的总数。其中,metric 名字由 ASCII 字符,数字,下划线,以及冒号组成,且必须满足正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]*。
- 标签:使同一个时间序列有了不同维度的识别。例如
http_requests_total{method="Get"}表示所有http请求中的Get请求。当 method="post" 时,则为新的一个metric。标签中的键由ASCII字符,数字,以及下划线组成,且必须满足正则表达式[a-zA-Z_:][a-zA-Z0-9_:]*。 - 样本:实际的时间序列,每个序列包括一个float64的值和一个毫秒级的时间戳。
- 格式:
<metric name>{<label name>=<label value>, …},例如:http_requests_total{method="POST",endpoint="/api/tracks"}。
四种 Metric 类型
Prometheus 客户端库主要提供四种主要的 metric 类型
Counter
- 一种累加的metric,典型的应用如:请求的个数,结束的任务数,出现的错误数等等。
例如,查询http_requests_total{method="get", job="Prometheus", handler="query"}返回8,10秒后,再次查询,则返回14
Gauge
- 一种常规的 metric,典型的应用如:温度,运行的 goroutines 的个数。
- 可以任意加减。
例如:go_goroutines{instance="172.17.0.2", job="Prometheus"}返回值 147,10 秒后返回 124。
Histogram
- 可以理解为柱状图,典型的应用如:请求持续时间,响应大小。
- 可以对观察结果采样,分组及统计。
例如,查询http_request_duration_microseconds_sum{job="Prometheus", handler="query"}时
Summary
- 类似于 Histogram, 典型的应用如:请求持续时间,响应大小。
- 提供观测值的 count 和 sum 功能。
- 提供百分位的功能,即可以按百分比划分跟踪结果。
instance 和 jobs
- instance: 一个单独 scrape 的目标, 一般对应于一个进程。
- jobs: 一组同种类型的 instances(主要用于保证可扩展性和可靠性),例如:
Node exporter
Node exporter主要用于暴露metrics给Prometheus,其中 metrics 包括:cpu 的负载,内存的使用情况,网络等,一般使用9100端口
Prometheus 安装和配置
Prometheus的配置文件prometheus.yml 内容为
global: # 全局设置,可以被覆盖
scrape_interval: 15s # 默认值为 15s,用于设置每次数据收集的间隔
external_labels: # 所有时间序列和警告与外部通信时用的外部标签
monitor: 'codelab-monitor'
rule_files: # 警告规则设置文件
- '/etc/prometheus/alert.rules'
# 用于配置 scrape 的 endpoint 配置需要 scrape 的 targets 以及相应的参数
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus' # 一定要全局唯一, 采集 Prometheus 自身的 metrics
# 覆盖全局的 scrape_interval
scrape_interval: 5s
static_configs: # 静态目标的配置
- targets: ['172.17.0.2:9090']
- job_name: 'node' # 一定要全局唯一, 采集本机的 metrics,需要在本机安装 node_exporter
scrape_interval: 10s
static_configs:
- targets: ['10.0.2.15:9100'] # 本机 node_exporter 的 endpoint
alert配置文件alert.rules内容为
# Alert for any instance that is unreachable for >5 minutes.
ALERT InstanceDown # alert 名字
IF up == 0 # 判断条件
FOR 5m # 条件保持 5m 才会发出 alert
LABELS { severity = "critical" } # 设置 alert 的标签
ANNOTATIONS { # alert 的其他标签,但不用于标识 alert
summary = "Instance {{ $labels.instance }} down",
description = "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes.",
}
Alertmanager
当接收到Prometheus端发送过来的alerts时,Alertmanager会对alerts进行去重复,分组,路由到对应集成的接受端,包括:slack,电子邮件,pagerduty,hitchat,webhook
Alermanager中config.yml
global:
resolve_timeout: 5m
route:
receiver: 'default-receiver'
group_wait: 30s
group_interval: 1m
repeat_interval: 1m
group_by: ['alertname']
routes:
- match:
severity: critical
receiver: my-slack
receivers:
- name: 'my-slack'
slack_configs:
- send_resolved: true
api_url: https://hooks.slack.com/services/***
channel: '#alertmanager-critical'
text: "{{ .CommonAnnotations.description }}"
- name: 'default-receiver'
slack_configs:
- send_resolved: true
api_url: https://hooks.slack.com/services/***
channel: '#alertmanager-default'
text: "{{ .CommonAnnotations.description }}"
一般监听9093端口
参考文档
prometheus监控kubernetes集群
先从coreos/kube-prometheus入手
daemonsets类型的kube-prometheus-exporter-node
$ kubectl get daemonsets kube-prometheus-exporter-node --namespace=monitoring -o yaml
可以看到镜像和启动参数为
labels:
app: exporter-node
chart: exporter-node-0.4.6
component: node-exporter
heritage: Tiller
release: kube-prometheus
...
containers:
- args:
- --web.listen-address=0.0.0.0:9100
- --path.procfs=/host/proc
- --path.sysfs=/host/sys
image: quay.io/prometheus/node-exporter:v0.15.2
imagePullPolicy: IfNotPresent
name: node-exporter
ports:
- containerPort: 9100
hostPort: 9100
name: metrics
protocol: TCP
...
volumes:
- hostPath:
path: /proc
type: ""
name: proc
- hostPath:
path: /sys
type: ""
name: sys
启动的容器时使用的node-exporter的镜像,挂载了本机的/proc和/sys目录,就是简单的获取这两个目录下的系统信息进行收集了,实际命令为/bin/node_exporter --web.listen-address=0.0.0.0:9100 --path.procfs=/host/proc --path.sysfs=/host/sys,在host上也是启动了9100端口
可以直接请求node的9100端口,例如:http://127.0.0.1:9100/metrics
# HELP node_cpu Seconds the cpus spent in each mode.
# TYPE node_cpu counter
node_cpu{cpu="cpu0",mode="guest"} 0
node_cpu{cpu="cpu0",mode="guest_nice"} 0
node_cpu{cpu="cpu0",mode="idle"} 87762.87
node_cpu{cpu="cpu0",mode="iowait"} 247.51
node_cpu{cpu="cpu0",mode="irq"} 0
node_cpu{cpu="cpu0",mode="nice"} 13.08
node_cpu{cpu="cpu0",mode="softirq"} 38.34
node_cpu{cpu="cpu0",mode="steal"} 0
node_cpu{cpu="cpu0",mode="system"} 1781.67
node_cpu{cpu="cpu0",mode="user"} 3175.27
node_cpu{cpu="cpu1",mode="guest"} 0
node_cpu{cpu="cpu1",mode="guest_nice"} 0
node_cpu{cpu="cpu1",mode="idle"} 87744.35
node_cpu{cpu="cpu1",mode="iowait"} 257.78
node_cpu{cpu="cpu1",mode="irq"} 0
node_cpu{cpu="cpu1",mode="nice"} 13.08
node_cpu{cpu="cpu1",mode="softirq"} 45.83
node_cpu{cpu="cpu1",mode="steal"} 0
node_cpu{cpu="cpu1",mode="system"} 1771.99
node_cpu{cpu="cpu1",mode="user"} 3188.85
监控对应的service
$ kubectl get service kube-prometheus-exporter-node --namespace=monitoring -o yaml
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2018-12-25T10:06:29Z"
labels:
app: exporter-node
chart: exporter-node-0.4.6
component: node-exporter
heritage: Tiller
release: kube-prometheus
name: kube-prometheus-exporter-node
namespace: monitoring
resourceVersion: "38981"
selfLink: /api/v1/namespaces/monitoring/services/kube-prometheus-exporter-node
uid: bf70b172-082c-11e9-bbfd-525400e51d99
spec:
clusterIP: 10.97.180.154
ports:
- name: metrics
port: 9100
protocol: TCP
targetPort: metrics
selector:
app: kube-prometheus-exporter-node
component: node-exporter
release: kube-prometheus
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
使用Service的selector选择各个部署的Pod作为其endpoint
监控对应的ServiceMonitor
$ kubectl get ServiceMonitor --namespace=monitoring kube-prometheus-exporter-node -o yaml
kind: ServiceMonitor
metadata:
creationTimestamp: "2018-12-25T10:06:30Z"
generation: 1
labels:
app: exporter-node
chart: exporter-node-0.4.6
component: node-exporter
heritage: Tiller
prometheus: kube-prometheus
release: kube-prometheus
name: kube-prometheus-exporter-node
namespace: monitoring
resourceVersion: "39076"
selfLink: /apis/monitoring.coreos.com/v1/namespaces/monitoring/servicemonitors/kube-prometheus-exporter-node
uid: bfdcd910-082c-11e9-bbfd-525400e51d99
spec:
endpoints:
- interval: 15s
port: metrics
jobLabel: component
namespaceSelector:
matchNames:
- monitoring
selector:
matchLabels:
app: exporter-node
component: node-exporter
ServiceMonitor,使用和service一样的selector并且定义收集metrics的端口
获取的lable就是刚才的Daemon的Pod,监控间隔为15s,这边Port: metrics
Prometheus Operator
Prometheus Operator是一个处于alpha阶段的解决方案,它通过定义新的ServiceMonitor和Prometheus将资源和Prometheus进行动态连接
kubectl get Prometheus prometheus --namespace=monitoring -o yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
creationTimestamp: "2018-12-25T10:05:11Z"
generation: 1
labels:
app: prometheus
chart: prometheus-0.0.51
heritage: Tiller
prometheus: prometheus
release: prometheus
name: prometheus
namespace: monitoring
resourceVersion: "38697"
selfLink: /apis/monitoring.coreos.com/v1/namespaces/monitoring/prometheuses/prometheus
uid: 90d75bfe-082c-11e9-bbfd-525400e51d99
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchLabels:
app: prometheus
prometheus: prometheus
topologyKey: kubernetes.io/hostname
weight: 100
alerting:
alertmanagers:
- name: prometheus-alertmanager
namespace: monitoring
port: http
baseImage: quay.io/prometheus/prometheus
externalUrl: http://prometheus.monitoring:9090
imagePullSecrets: []
logLevel: info
paused: false
replicas: 1
resources: {}
retention: 24h
routePrefix: /
ruleSelector:
matchLabels:
prometheus: prometheus
serviceAccountName: prometheus
serviceMonitorSelector:
app: prometheus
version: v2.2.1
Prometheus CDR并且通过serviceMonitorSelector选择之前建立的ServiceMonitor作为监控目标
Prometheus Operator会对Prometheus CDR
$ kubectl get ConfigMap prometheus-operator --namespace=monitoring -o yaml
apiVersion: v1
data:
servicemonitor-operator.yaml: |-
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app: prometheus-operator
chart: "prometheus-operator-0.0.29"
heritage: "Tiller"
release: "prometheus-operator"
prometheus: prometheus-operator
name: prometheus-operator
spec:
jobLabel: prometheus-operator
selector:
matchLabels:
operated-prometheus: "true"
namespaceSelector:
matchNames:
- "monitoring"
endpoints:
- port: http
interval: 30s
honorLabels: true
kind: ConfigMap
metadata:
creationTimestamp: "2018-12-25T07:16:37Z"
name: prometheus-operator
namespace: monitoring
resourceVersion: "24445"
selfLink: /api/v1/namespaces/monitoring/configmaps/prometheus-operator
uid: 04a1b3ea-0815-11e9-bbfd-525400e51d99
在集群内部是通过一下命令启动的
/bin/operator --kubelet-service=kube-system/kubelet --prometheus-config-reloader=quay.io/coreos/prometheus-config-reloader:v0.20.0 --config-reloader-image=quay.io/coreos/configmap-reload:v0.0.1
对应配置在node节点上启动了quay.io/coreos/prometheus-config-reloader实现的配置的获取
容器启动的方式这次是指定的配置文件
/bin/prometheus-config-reloader --reload-url=http://localhost:9090/-/reload --config-file=/etc/prometheus/config/prometheus.yaml --config-envsubst-file=/etc/prometheus/config_out/prometheus.env.yaml
prometheus instance的service来将prometheus服务对外暴露,便于查看UI
总计架构为一下所示
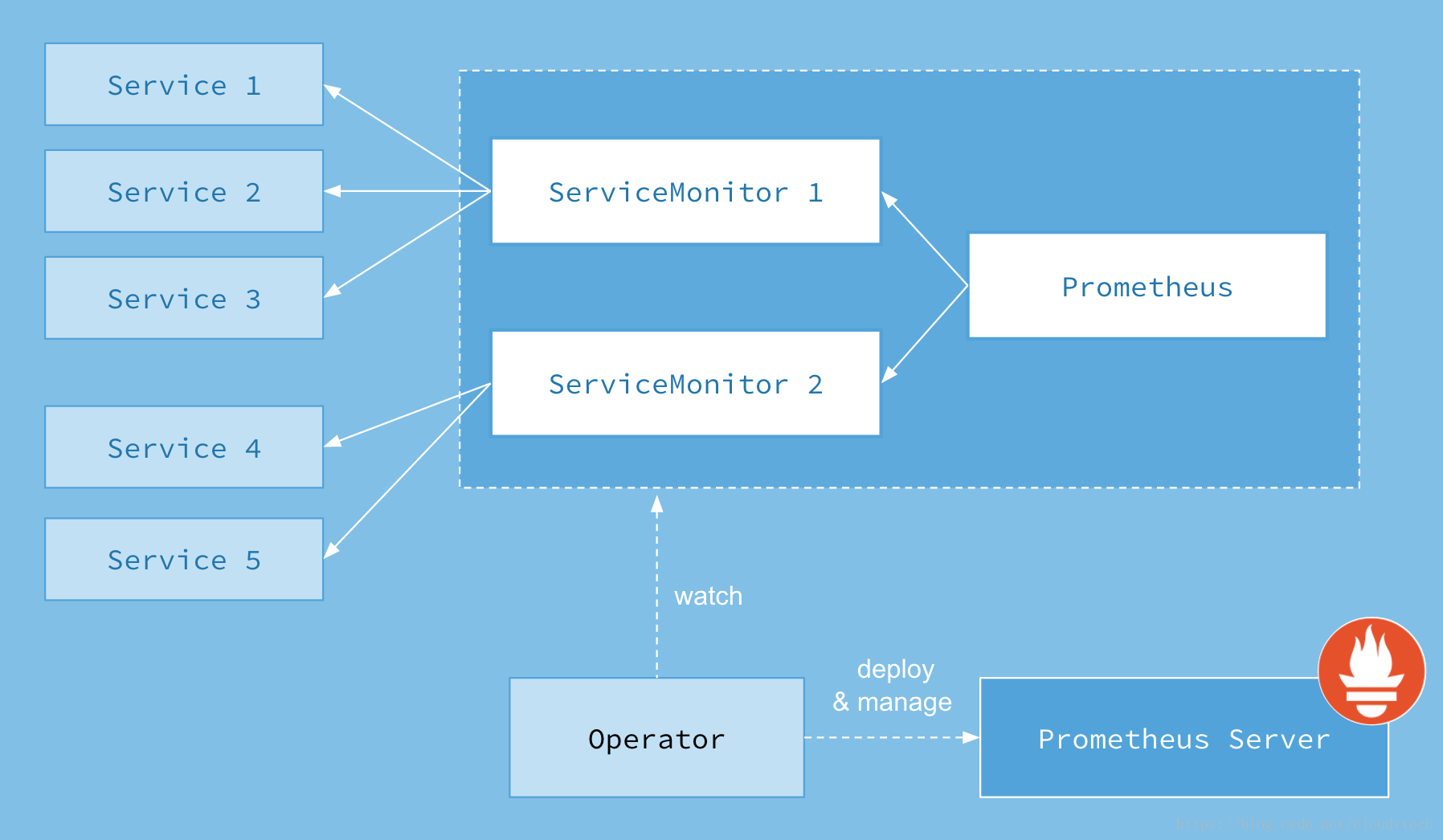
这边集群是有两套prometheus的
集群报警
kubernetes中定义了Alertmanager的kind
$ kubectl get --namespace=monitoring alertmanagers alertmanager -o yaml
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager
metadata:
creationTimestamp: "2018-12-25T10:05:23Z"
generation: 1
labels:
alertmanager: alertmanager
app: alertmanager
chart: alertmanager-0.1.7
heritage: Tiller
release: alertmanager
name: alertmanager
namespace: monitoring
resourceVersion: "38743"
selfLink: /apis/monitoring.coreos.com/v1/namespaces/monitoring/alertmanagers/alertmanager
uid: 97dfa6e6-082c-11e9-bbfd-525400e51d99
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchLabels:
alertmanager: alertmanager
app: alertmanager
topologyKey: kubernetes.io/hostname
weight: 100
baseImage: quay.io/prometheus/alertmanager
externalUrl: http://alertmanager.monitoring:9093
imagePullSecrets: []
paused: false
replicas: 1
resources: {}
version: v0.15.1
这个也是通过prometheus的kind中通过alerting指定的
可以直接通过集群对应的服务进行配置
grafana数据可视化
只需要将database的URL配置为对应的prometheus的URL即可正常显示了
参考文档

